Koshur Diacritizer: A Byte-Level Sequence-to-Sequence Model for Kashmiri Diacritic Restoration
Pith reviewed 2026-06-27 04:08 UTC · model grok-4.3
The pith
A byte-level sequence-to-sequence model restores diacritics in Kashmiri text using a released dataset of 23.7k aligned sentences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Koshur Diacritizer is a ByT5-small byte-level sequence-to-sequence model that restores diacritics in Kashmiri while keeping the original base-letter sequence intact. It combines script-aware normalization, alignment validation, and skeleton-preserving inference, and is trained on the released set of 23.7k aligned sentence pairs. The model attains a DERm of 0.2012 and WER of 0.2159 on a held-out test set, together with 77.5 percent mean accuracy according to native-speaker expert review.
What carries the argument
Byte-level sequence-to-sequence model (ByT5-small) augmented with script-aware normalization, alignment validation, and skeleton-preserving inference to restore diacritics without altering base letters.
If this is right
- The public 23.7k-pair dataset supplies training and evaluation material for any future Kashmiri diacritization system.
- Skeleton-preserving inference guarantees that the output never changes the sequence of base letters present in the input.
- Reported error rates and expert accuracy establish a concrete performance baseline for Kashmiri diacritic restoration.
- The released model, dataset, and code enable direct replication and incremental improvement by other researchers.
Where Pith is reading between the lines
- The same byte-level approach and normalization steps could be applied to diacritic restoration in other Perso-Arabic-script languages that also omit marks in digital text.
- The skeleton-preserving mechanism offers a template for orthographic normalization tasks that must leave core letter identity unchanged.
- An accuracy of 77.5 percent under expert review indicates that larger or more diverse training data would be needed before the model could serve as a fully reliable production tool.
- Embedding the diacritizer as a preprocessing step could raise accuracy on downstream Kashmiri tasks such as machine translation or named-entity recognition.
Load-bearing premise
The 23.7k aligned sentence pairs represent typical real-world Kashmiri usage and the single native expert review sufficiently confirms output correctness.
What would settle it
Performance measured on an independently gathered test collection of several thousand Kashmiri sentences whose restored forms are judged by multiple native speakers rather than one expert.
Figures

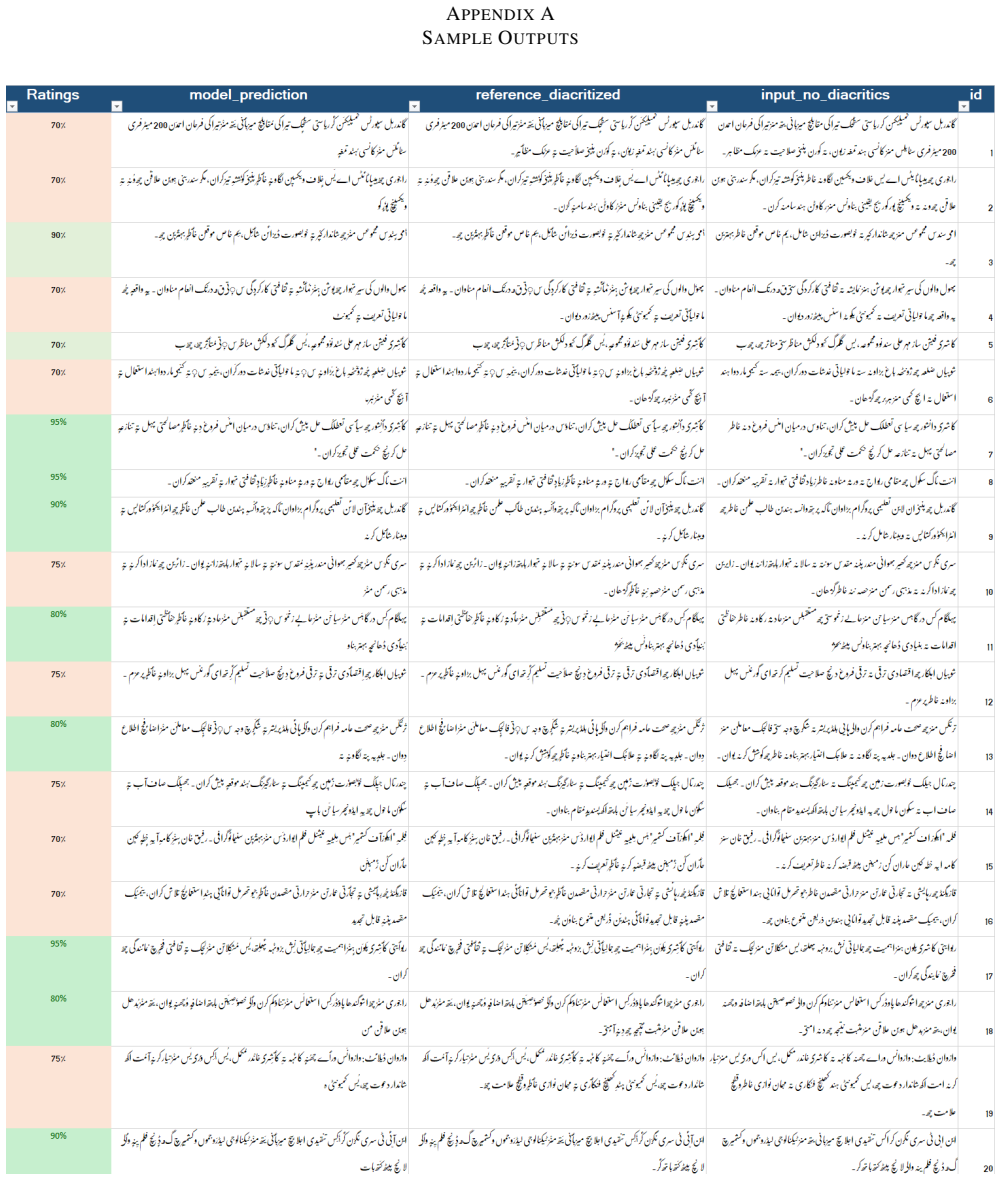
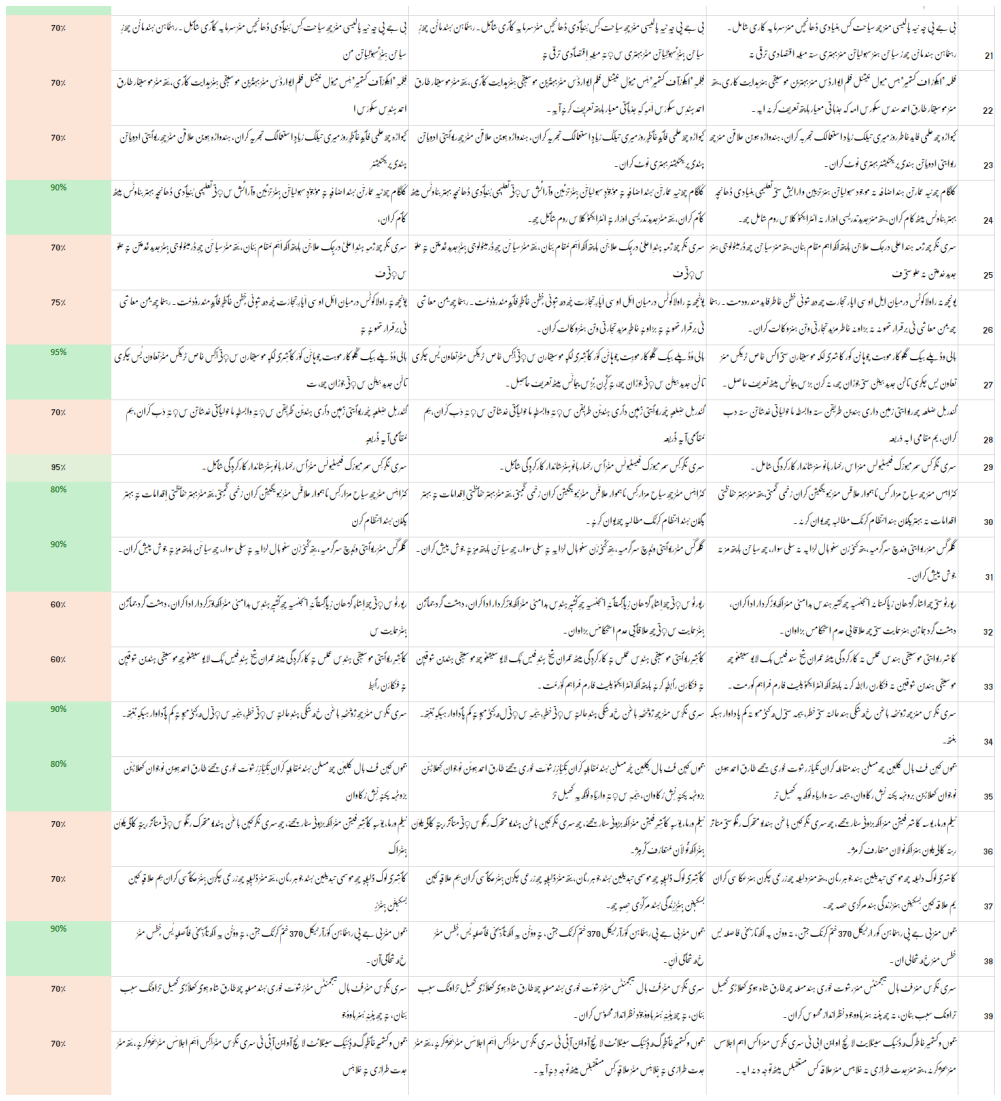
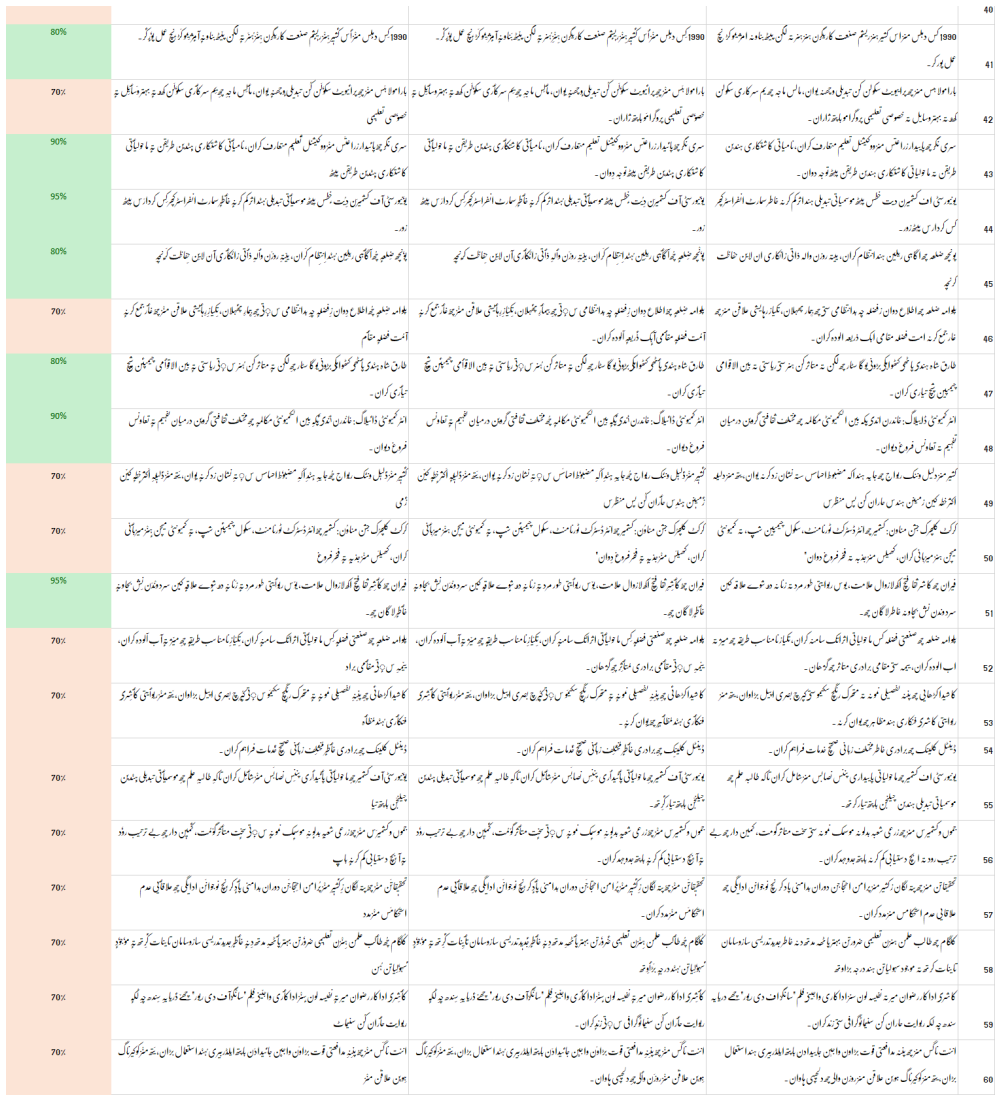
read the original abstract
Kashmiri, an Indo-Aryan language written in a modified Perso-Arabic script, frequently omits diacritic marks in digital text, creating ambiguity and challenging downstream NLP applications. We present Koshur Diacritizer, a ByT5-small byte-level sequence-to-sequence model for restoring diacritics in Kashmiri text. To support this task, we release a publicly available dataset of 23.7k aligned undiacritized diacritized Kashmiri sentence pairs. The proposed framework combines script-aware normalization, alignment validation, and skeleton-preserving inference to ensure reliable restoration while maintaining the original base-letter sequence. Experimental results on a held-out test set achieve a DERm of 0.2012 and a WER of 0.2159. Additionally, evaluation by a native Kashmiri linguistic expert yields a mean accuracy of 77.5%. The dataset, model, and source code are publicly released to provide a reproducible baseline for Kashmiri diacritic restoration and future low-resource language research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Koshur Diacritizer, a ByT5-small byte-level sequence-to-sequence model for diacritic restoration in Kashmiri text written in modified Perso-Arabic script. It releases a new public dataset of 23.7k aligned undiacritized-diacritized sentence pairs constructed via script-aware normalization and alignment validation, and reports held-out test performance of DERm 0.2012 and WER 0.2159 together with 77.5% mean accuracy from evaluation by a native Kashmiri linguistic expert. The dataset, model, and code are released to support future low-resource language work.
Significance. If the empirical results hold under more detailed validation, the work supplies a reproducible baseline and the first public aligned corpus for Kashmiri diacritic restoration, an under-served Indo-Aryan language. The public release of the 23.7k-pair dataset, trained model, and source code is a concrete contribution that lowers the barrier for subsequent research on byte-level models for low-resource script normalization tasks.
major comments (2)
- [Dataset] Dataset section: the 23.7k aligned sentence pairs are described only as 'aligned' with 'alignment validation' and 'script-aware normalization'; no sourcing details, corpus provenance, diversity statistics, or explicit validation protocol are provided. This directly affects the claim that the held-out test set (and the reported DERm/WER) demonstrates generalization to real-world Kashmiri usage.
- [Evaluation] Evaluation section: the native-expert result of 77.5% mean accuracy is obtained from a single linguistic expert; the manuscript supplies neither the number of evaluated sentences, the evaluation protocol, nor any agreement metric. Because this figure is presented as additional evidence of correctness alongside the automatic metrics, the missing protocol details are load-bearing for the central generalization claim.
minor comments (2)
- [Abstract] Abstract and §4: the training procedure, hyperparameter search, error analysis, and statistical significance tests for the reported DERm and WER are not described; adding these would improve reproducibility without altering the central claims.
- [Related Work] The paper does not compare against any prior Kashmiri or related-language diacritizer baselines; a brief related-work paragraph would help situate the 0.2012 DERm result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to supply the requested details on dataset construction and evaluation procedures.
read point-by-point responses
-
Referee: [Dataset] Dataset section: the 23.7k aligned sentence pairs are described only as 'aligned' with 'alignment validation' and 'script-aware normalization'; no sourcing details, corpus provenance, diversity statistics, or explicit validation protocol are provided. This directly affects the claim that the held-out test set (and the reported DERm/WER) demonstrates generalization to real-world Kashmiri usage.
Authors: We agree that the manuscript would benefit from expanded documentation. In the revision we will add sourcing information for the original Kashmiri texts, corpus provenance, diversity statistics (sentence-length distribution and lexical coverage), and a more explicit account of the alignment-validation steps. These additions will be placed in the Dataset section and will better support the generalization claims for the held-out test set. revision: yes
-
Referee: [Evaluation] Evaluation section: the native-expert result of 77.5% mean accuracy is obtained from a single linguistic expert; the manuscript supplies neither the number of evaluated sentences, the evaluation protocol, nor any agreement metric. Because this figure is presented as additional evidence of correctness alongside the automatic metrics, the missing protocol details are load-bearing for the central generalization claim.
Authors: We acknowledge the need for greater transparency. The revision will state the number of sentences evaluated by the expert, describe the evaluation protocol (including the exact instructions and scoring method), and note that inter-annotator agreement could not be computed with a single evaluator. The result will be presented more explicitly as supplementary evidence, with the limitation discussed in the text. revision: yes
Circularity Check
No significant circularity; empirical evaluation on held-out data is self-contained
full rationale
The paper trains a ByT5 model on a released dataset of 23.7k aligned sentence pairs and reports standard held-out metrics (DERm 0.2012, WER 0.2159) plus a separate expert review (77.5%). These are direct empirical measurements, not quantities derived by construction from fitted parameters or self-citations. No mathematical derivation chain, ansatz, or uniqueness theorem is invoked; the central claims rest on external test-set performance rather than reducing to the training inputs by definition. Data creation steps (normalization, alignment) are described procedurally but do not create circularity in the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Byte-level tokenization and standard cross-entropy training suffice for diacritic restoration in modified Perso-Arabic script.
Forward citations
Cited by 1 Pith paper
-
Koshur Pixel: a large-scale synthetic ocr dataset for kashmiri
Koshur Pixel is the first large-scale synthetic OCR dataset for Kashmiri with 613,078 image-text pairs generated via SynthOCR-Gen from the KS-PRET-5M corpus across multiple fonts and granularities with 25+ augmentations.
Reference graph
Works this paper leans on
-
[1]
Maximum entropy based restoration of Arabic diacritics,
I. Zitouni, J. S. Sorensen, and R. Sarikaya, “Maximum entropy based restoration of Arabic diacritics,” inProc. 21st Int. Conf. Computational Linguistics and 44th Annual Meeting of the ACL, 2006, pp. 577–584. Fig. 3. Representative sample outputs from the Koshur Diacritizer system, part 2. Fig. 4. Representative sample outputs from the Koshur Diacritizer s...
2006
-
[2]
Automatic diacritization of Arabic text using recurrent neural networks,
G. A. Abandah, A. Graves, B. Al-Shagoor, A. Arabiyat, F. Jamour, and M. Al-Taee, “Automatic diacritization of Arabic text using recurrent neural networks,”Int. J. Document Analysis and Recognition, vol. 18, no. 2, pp. 183–197, 2015
2015
-
[3]
Arabic text diacritization using deep neural networks,
A. Fadel, I. Tuffaha, B. Al-Jawarneh, and M. Al-Ayyoub, “Arabic text diacritization using deep neural networks,” inProc. 2nd Int. Conf. Natural Language and Speech Processing (ICNLSP), 2019, pp. 1–8
2019
-
[4]
Nakdan: Professional Hebrew diacritizer,
A. Shmidman, S. Katz, Y . Goldberg, and R. Tsarfaty, “Nakdan: Professional Hebrew diacritizer,” inProc. 58th Annual Meeting of the ACL: System Demonstrations, 2020, pp. 197–203
2020
-
[5]
Pointwise approach for Vietnamese diacritics restoration,
A. T. Luu and S. Yamamoto, “Pointwise approach for Vietnamese diacritics restoration,” inProc. 26th Pacific Asia Conf. Language, Information and Computation, 2012, pp. 295–302
2012
-
[6]
ByT5: Towards a token-free future with pre-trained byte-to-byte models,
L. Xue, A. Barua, N. Constant, R. Al-Rfou, S. Narang, M. Kale, A. Roberts, and C. Raffel, “ByT5: Towards a token-free future with pre-trained byte-to-byte models,”Trans. Assoc. Computational Linguistics, vol. 10, pp. 291–306, 2022
2022
-
[7]
CANINE: Pre-training an efficient tokenization-free encoder for language representation,
J. H. Clark, D. Garrette, I. Turc, and J. Wieting, “CANINE: Pre-training an efficient tokenization-free encoder for language representation,”Trans. Assoc. Computational Linguistics, vol. 10, pp. 73–91, 2022
2022
-
[8]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”J. Machine Learning Research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[9]
KS-LIT-3M: A literary corpus for Kashmiri language technology,
H. N. Malik, “KS-LIT-3M: A literary corpus for Kashmiri language technology,” 2025, Hugging Face dataset. [Online]. Available: https://arxiv.org/abs/ 2601.01091
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.