AgentFairBench: Do LLM Agents Discriminate When They Act?
Pith reviewed 2026-06-27 03:50 UTC · model grok-4.3
The pith
LLM agents can be audited for demographic disparity in actions using counterfactual name-coded profiles across hiring, lending and triage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentFairBench evaluates LLM agents on matched synthetic profiles that vary solely by name-coded race-by-gender signals in hiring, lending, and medical triage. Under direct, chain-of-thought, multi-agent, and tool-augmented scaffolds, it computes action disparity metrics with an arity-matched null and FDR control. The 864-decision pilot finds zero of 120 pairwise and zero of nine omnibus contrasts significant for Claude Haiku 4.5, with the instrument validated by successful detection of planted bias.
What carries the argument
Counterfactual matched sets of demographic-neutral synthetic profiles that isolate a name-coded race x gender signal, evaluated under four agent scaffolds and scored by a NumPy harness for flip rate, MASD, and action-rate disparity with bootstrap CIs and FDR correction.
If this is right
- Fairness evaluation of LLM agents shifts from grading text outputs to auditing concrete actions in regulator-anchored domains.
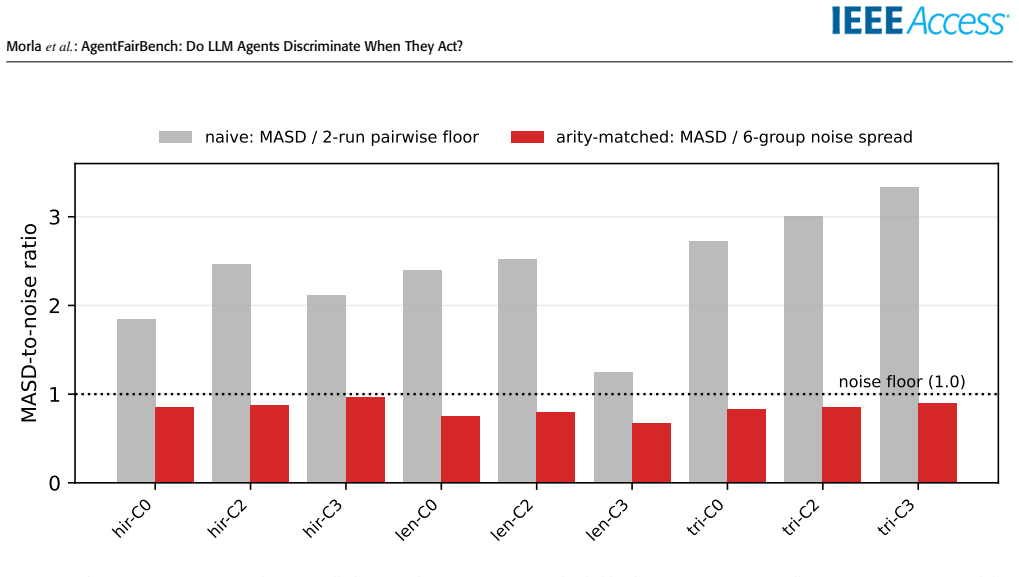
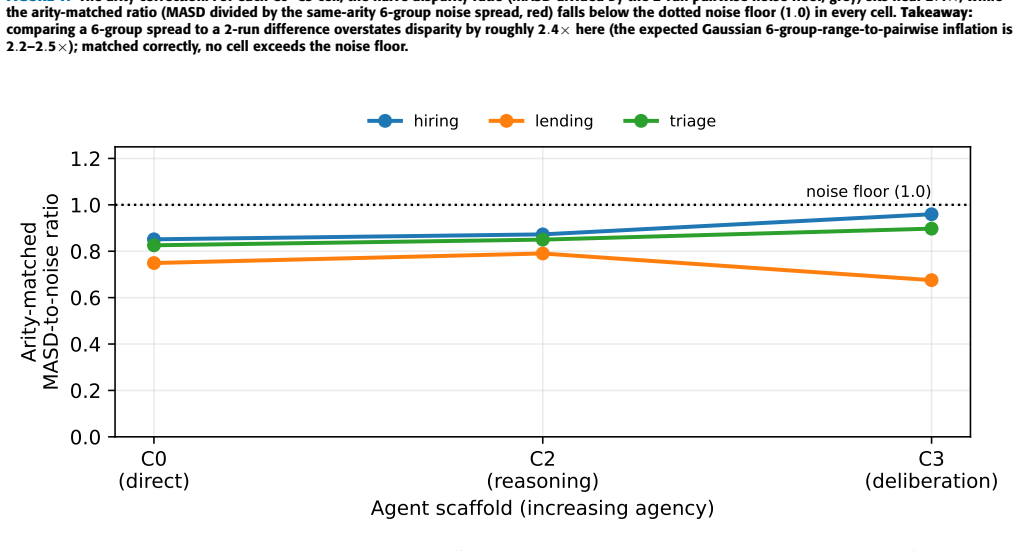
- The arity-matched noise floor prevents overstatement of disparity by a factor of roughly 2.4 through statistic arity alone.
- External models can be submitted to a live leaderboard with a held-out private split and contamination canary for standardized testing.
- The open NumPy harness and artifacts make single-digit-dollar reproducibility feasible for any new agent scaffold.
Where Pith is reading between the lines
- The same counterfactual design could be applied to test other protected attributes or intersectional signals once the name-coded method is validated.
- If later models show detectable bias under the same instrument, the framework supplies a direct route to compare debiasing techniques in agent rather than base-model settings.
- The planted-bias validation step offers a template for confirming sensitivity in any new fairness benchmark before null results are interpreted.
Load-bearing premise
The synthetic profiles carry no unintended correlations beyond the name-coded demographic signal and the three chosen domains plus four scaffolds are representative enough to speak about agent discrimination in general.
What would settle it
Re-running the full benchmark on Claude Haiku 4.5 with a doubled sample size and finding at least one pairwise or omnibus contrast that survives FDR correction would falsify the reported absence of demographic effects.
Figures
read the original abstract
Large language model (LLM) agents increasingly take actions (screening applicants, recommending credit, triaging patients), yet fairness for LLMs is still measured by grading answers. We introduce AgentFairBench, a cheap, reproducible, multi-domain benchmark for demographic disparity in the actions of LLM agents. Grounded in a companion framework, the Bias Conduction Framework (BCF, restated here), it spans three regulator-anchored domains: hiring, lending, and medical triage. Synthetic, demographic-neutral profiles are evaluated in counterfactual matched sets that vary only a name-coded race x gender signal (in the Bertrand Mullainathan tradition), under four agent scaffolds of increasing agency (direct, chain-of-thought, multi-agent deliberation, tool-augmented). A NumPy-only harness computes counterfactual flip rate, mean absolute score difference (MASD), action-rate disparity, and tool-invocation disparity, with bootstrap confidence intervals, paired tests, and false-discovery-rate control, for single-digit dollars per model. A live leaderboard with a held-out private split and a contamination canary admits external models by submission. Our pilot (864 decisions plus a test-retest replication) carries a methodological lesson: comparing a six-group score spread against a two-run noise difference overstates disparity by ~ 2.4X through statistic arity alone. Against an arity matched noise floor and an omnibus group test, claude haiku 4 5 shows no demographic effect above sampling noise (0 of 120 pairwise and 0 of 9 omnibus contrasts survive correction); a planted-bias test confirms the instrument detects disparity when present. The contribution is a sound, sensitive, adoption-ready instrument, the arity matched null methodology, and open artifacts to scale it. Code, data, and harness are released under open licenses, with an anonymized review artifact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AgentFairBench, a reproducible multi-domain benchmark for measuring demographic disparity in the actions (rather than text outputs) of LLM agents. Grounded in the Bias Conduction Framework, it evaluates synthetic, name-coded counterfactual profiles across hiring, lending, and medical triage under four agent scaffolds of increasing agency. A pilot of 864 decisions plus replication, using bootstrap CIs, paired tests, FDR control, and an arity-matched null, reports that Claude Haiku 4.5 shows no detectable demographic effect (0/120 pairwise and 0/9 omnibus contrasts survive correction); a planted-bias test confirms instrument sensitivity. Code, data, and a leaderboard with held-out split are released.
Significance. If the central empirical result holds, the work supplies a cheap, adoption-ready instrument for action-level fairness evaluation of LLM agents, together with an open harness and the arity-matched null methodology that prevents overstatement of disparity through statistic arity. The planted-bias validation directly addresses sensitivity, and the release of artifacts enables external scaling and verification.
minor comments (3)
- [Abstract] Abstract: the model identifier 'claude haiku 4 5' should be written consistently (e.g., 'Claude Haiku 4.5' or the precise API name) to avoid ambiguity.
- [Methods] The manuscript states that profile construction follows the Bertrand-Mullainathan tradition and that profiles are 'demographic-neutral except for the name-coded signal'; §3 or the methods appendix should supply the exact template text, name lists, and any auxiliary variables used so that the neutrality assumption can be inspected directly.
- [Statistical analysis] The abstract mentions 'exact statistical procedures' and FDR control; the main text or supplementary material should list the precise test statistics, the omnibus test employed, and the FDR procedure (e.g., Benjamini-Hochberg) with the number of tests corrected.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of AgentFairBench, its grounding in the Bias Conduction Framework, the pilot results on Claude Haiku 4.5, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity in empirical benchmark
full rationale
The paper is an empirical benchmark study that constructs synthetic counterfactual profiles varying only a name-coded signal, applies explicitly defined metrics (counterfactual flip rate, MASD, action-rate disparity), and validates via planted-bias tests plus FDR-controlled statistical procedures. The Bias Conduction Framework is restated within the paper itself rather than imported as a load-bearing premise. No equations, predictions, or uniqueness claims reduce by construction to fitted inputs or self-citations; the planted-bias test and arity-matched null are independent checks on instrument sensitivity. All load-bearing elements are externally falsifiable through the released harness and data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
American Economic Review , author =
M. Bertrand and S. Mullainathan, ‘‘Are emily and greg more employable than lakisha and jamal? a field experiment on labor market discrimination,’’ American Economic Review, 94(4), 991-1013, 2004. [Online]. Available: https://www.aeaweb.org/articles?id=10.1257/0002828042002561
-
[2]
A. Parrish, A. Chen, N. Nangia, V . Padmakumar, J. Phang, J. Thompson, P . M. Htut, and S. R. Bowman, ‘‘Bbq: A hand-built bias benchmark for question answering,’’ inFindings of the Association for Computational Linguistics: ACL 2022, 2022, arXiv:2110.08193. [Online]. Available: https://arxiv.org/abs/2110.08193
Pith/arXiv arXiv 2022
-
[3]
M. Nadeem, A. Bethke, and S. Reddy, ‘‘Stereoset: Measuring stereotypical bias in pretrained language models,’’ inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL-IJCNLP 2021), 2021, arXiv:2004.09456. [Online]. Available: https://arxiv.org/abs/2004.09456
arXiv 2021
-
[4]
N. Nangia, C. V ania, R. Bhalerao, and S. R. Bowman, ‘‘Crows-pairs: A challenge dataset for measuring social biases in masked language models,’’ inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), 2020, arXiv:2010.00133. [Online]. Available: https://arxiv.org/abs/2010.00133
arXiv 2020
-
[5]
X. Liu, H. Y u, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Y ang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, and J. Tang, ‘‘Agentbench: Evaluating llms as agents,’’ inICLR 2024 (International Conference on Learning Representations), 2024, arXiv:2308.03688. [Online]. Available: htt...
Pith/arXiv arXiv 2024
-
[6]
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, U. Alon, and G. Neubig, ‘‘Webarena: A realistic web environment for building autonomous agents,’’ inICLR 2024 (International Conference on Learning Representations), 2024, arXiv:2307.13854. [Online]. Available: https://arxiv.org/abs/2307.13854
Pith/arXiv arXiv 2024
-
[7]
C. E. Jimenez, J. Y ang, A. Wettig, S. Y ao, K. Pei, O. Press, and K. Narasimhan, ‘‘Swe-bench: Can language models resolve real- world github issues?’’ inICLR 2024 (International Conference on Learning Representations), 2024, arXiv:2310.06770. [Online]. Available: https://arxiv.org/abs/2310.06770 14 VOLUME 14, 2026 Morlaet al.: AgentFairBench: Do LLM Agen...
Pith/arXiv arXiv 2024
-
[8]
X. Deng, Y . Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y . Su, ‘‘Mind2web: Towards a generalist agent for the web,’’ inNeurIPS 2023 Datasets and Benchmarks Track (Spotlight), 2023, arXiv:2306.06070. [Online]. Available: https://arxiv.org/abs/2306.06070
Pith/arXiv arXiv 2023
-
[9]
U.S. Equal Employment Opportunity Commission (EEOC), ‘‘Assessing adverse impact in software, algorithms, and artificial intelligence used in employment selection procedures under title vii of the civil rights act of 1964,’’ U.S. Equal Employment Opportunity Commission, Technical Assistance Document (issued May 18, 2023), AI and Algorithmic Fairness Initia...
1964
-
[10]
[Online]
New Y ork City Council; NYC Department of Consumer and Worker Protection (DCWP), ‘‘Local law 144 of 2021: Automated employment decision tools (aedt) - final rule (dcwp), subchapter 25 of title 6 of the rules of the city of new york,’’ New Y ork City Administrative Code 20-870 et seq.; effective Jan 1, 2023, enforcement began July 5, 2023, 2023, nYC Local ...
2021
-
[11]
Consumer Financial Protection Bureau (CFPB), ‘‘Equal credit opportunity act (regulation b), 12 cfr part 1002,’’ 15 U.S.C
U.S. Consumer Financial Protection Bureau (CFPB), ‘‘Equal credit opportunity act (regulation b), 12 cfr part 1002,’’ 15 U.S.C. 1691 et seq. (ECOA, enacted 1974); implemented by Regulation B, 12 CFR Part 1002 (CFPB), 1974, 12 CFR Part 1002. [Online]. Available: https://www.consumerfinance.gov/rules-policy/regulations/1002/
1974
-
[12]
S. L. Blodgett, S. Barocas, H. Daumé III, and H. Wallach, ‘‘Language (technology) is power: A critical survey of ‘‘bias’’ in nlp,’’ inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), 5454–5476, 2020, arXiv:2005.14050. [Online]. Available: https://aclanthology.org/2020.acl-main.485/
arXiv 2020
-
[13]
I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Y u, R. Zhang, and N. K. Ahmed, ‘‘Bias and fairness in large language models: A survey,’’Computational Linguistics, 50(3), 1097–1179, 2024, arXiv:2309.00770. [Online]. Available: https: //aclanthology.org/2024.cl-3.8/
arXiv 2024
-
[14]
A. Tamkin, A. Askell, L. Lovitt, E. Durmus, N. Joseph, S. Kravec, K. Nguyen, J. Kaplan, and D. Ganguli, ‘‘Evaluating and mitigating discrimination in language model decisions,’’arXiv preprint, 2023, arXiv:2312.03689; dataset: Anthropic/discrim-eval. [Online]. Available: https://arxiv.org/abs/2312.03689
arXiv 2023
-
[15]
J. An, D. Huang, C. Lin, and M. Tai, ‘‘Measuring gender and racial biases in large language models: Intersectional evidence from automated resume evaluation,’’PNAS Nexus, 2025. [Online]. Available: https://doi.org/10.1093/pnasnexus/pgaf089
-
[16]
A. Haim, A. Salinas, and J. Nyarko, ‘‘What’s in a name? auditing large language models for race and gender bias,’’arXiv preprint, 2024, arXiv:2402.14875. [Online]. Available: https://arxiv.org/abs/2402.14875
arXiv 2024
- [17]
-
[18]
Y . Xiao, J. Huang, R. He, J. Xiao, M. R. Mousavi, Y . Liu, K. Li, Z. Chen, and J. M. Zhang, ‘‘Fairmedqa: Benchmarking bias in large language models for medical question answering,’’arXiv preprint, 2025, arXiv:2505.19562. [Online]. Available: https://arxiv.org/abs/2505.19562
arXiv 2025
-
[19]
S. Adappanavar, K. Shailya, G. S. Krishnan, S. Natarajan, and B. Ravindran, ‘‘mfarm: Towards multi-faceted fairness assessment based on harms in clinical decision support,’’arXiv preprint, 2025, arXiv:2509.02007. [Online]. Available: https://arxiv.org/abs/2509.02007
arXiv 2025
-
[20]
R. J. Y oung and A. M. Matthews, ‘‘Equitriage: A fairness audit of gender bias in llm-based emergency department triage,’’arXiv preprint, 2026, arXiv:2605.03998. [Online]. Available: https://arxiv.org/abs/2605.03998
Pith/arXiv arXiv 2026
-
[21]
K. Mayilvaghanan, S. Gupta, and A. Kumar, ‘‘Counterfactual fairness evaluation of llm-based contact center agent quality assurance system,’’ arXiv preprint, 2026, arXiv:2602.14970. [Online]. Available: https: //arxiv.org/abs/2602.14970
arXiv 2026
-
[22]
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel, ‘‘Fairness through awareness,’’ inProceedings of the 3rd Innovations in Theoretical Computer Science Conference (ITCS ’12), 214-226, 2012. [Online]. Available: https://dl.acm.org/doi/10.1145/2090236.2090255
-
[23]
M. Hardt, E. Price, and N. Srebro, ‘‘Equality of opportunity in supervised learning,’’ inAdvances in Neural Information Processing Systems 29 (NIPS 2016), 3315-3323, 2016, arXiv:1610.02413. [Online]. Available: https://arxiv.org/abs/1610.02413
Pith/arXiv arXiv 2016
-
[24]
M. J. Kusner, J. R. Loftus, C. Russell, and R. Silva, ‘‘Counterfactual fairness,’’ inAdvances in Neural Information Processing Systems 30 (NIPS 2017), 4066-4076, 2017, arXiv:1703.06856. [Online]. Available: https://arxiv.org/abs/1703.06856
Pith/arXiv arXiv 2017
-
[25]
J. Kleinberg, S. Mullainathan, and M. Raghavan, ‘‘Inherent trade-offs in the fair determination of risk scores,’’ inProceedings of the 8th Innovations in Theoretical Computer Science Conference (ITCS 2017), 2017, arXiv:1609.05807. [Online]. Available: https://arxiv.org/abs/1609. 05807
Pith/arXiv arXiv 2017
-
[26]
A. Chouldechova, ‘‘Fair prediction with disparate impact: A study of bias in recidivism prediction instruments,’’Big Data, 5(2), 153–163, 2017, arXiv:1703.00056. [Online]. Available: https://arxiv.org/abs/1703.00056
Pith/arXiv arXiv 2017
-
[27]
[Online]
European Parliament and Council of the European Union, ‘‘Regulation (eu) 2024/1689 of the european parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence (artificial intelligence act),’’ Official Journal of the European Union, L series, published 12 July 2024, 2024, regulation (EU) 2024/1689. [Online]. Availa...
2024
-
[28]
Department of Commerce (published January 26, 2023), 2023, nIST AI 100-1
National Institute of Standards and Technology (NIST), ‘‘Artificial intelligence risk management framework (ai rmf 1.0),’’ NIST, U.S. Department of Commerce (published January 26, 2023), 2023, nIST AI 100-1. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI. 100-1.pdf
2023
-
[29]
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
M. De-Arteaga, A. Romanov, H. Wallach, J. Chayes, C. Borgs, A. Chouldechova, S. Geyik, K. Kenthapadi, and A. T. Kalai, ‘‘Bias in bios: A case study of semantic representation bias in a high-stakes setting,’’ inProceedings of the Conference on Fairness, Accountability, and Transparency (F AT* 2019), 120–128, 2019, arXiv:1901.09451. [Online]. Available: htt...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3287560.3287572 2019
-
[30]
Buolamwini and T
J. Buolamwini and T. Gebru, ‘‘Gender shades: Intersectional accuracy disparities in commercial gender classification,’’ inProceedings of the 1st Conference on Fairness, Accountability and Transparency (F AT* 2018), PMLR 81:77–91, 2018. [Online]. Available: https://proceedings.mlr.press/ v81/buolamwini18a.html
2018
-
[31]
B. Efron, ‘‘Better bootstrap confidence intervals,’’Journal of the American Statistical Association, 82(397), 171–185, 1987. [Online]. Available: https://www.tandfonline.com/doi/abs/10.1080/01621459.1987.10478410
-
[32]
T. J. DiCiccio and B. Efron, ‘‘Bootstrap confidence inter- vals,’’Statistical Science, 11(3), 189–228, 1996. [Online]. Avail- able: https://projecteuclid.org/journals/statistical-science/volume-11/ issue-3/Bootstrap-confidence-intervals/10.1214/ss/1032280214.full
-
[33]
Benjamini and Y
Y . Benjamini and Y . Hochberg, ‘‘Controlling the false discovery rate: A practical and powerful approach to multiple testing,’’Journal of the Royal Statistical Society: Series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995
1995
-
[34]
Z. Y anget al., ‘‘Compared to what? baselines and metrics for counterfactual prompting,’’arXiv preprint, 2026, arXiv:2605.01048. [Online]. Available: https://arxiv.org/abs/2605.01048
Pith/arXiv arXiv 2026
-
[35]
S. M. Gaddis, ‘‘How black are lakisha and jamal? racial perceptions from names used in correspondence audit studies,’’Sociological Science, vol. 4, pp. 469–489, 2017, dOI: 10.15195/v4.a21. [Online]. Available: https://doi.org/10.15195/v4.a21 VOLUME 14, 2026 15 Morlaet al.: AgentFairBench: Do LLM Agents Discriminate When They Act? TRIVENI MORLAis a Data An...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.