Securing Multi-Agent GIS Systems: Risk Evaluation and Prompt Hardening Optimization
Pith reviewed 2026-06-27 04:51 UTC · model grok-4.3
The pith
A prompt optimization framework hardens multi-agent GIS systems against attacks while preserving task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
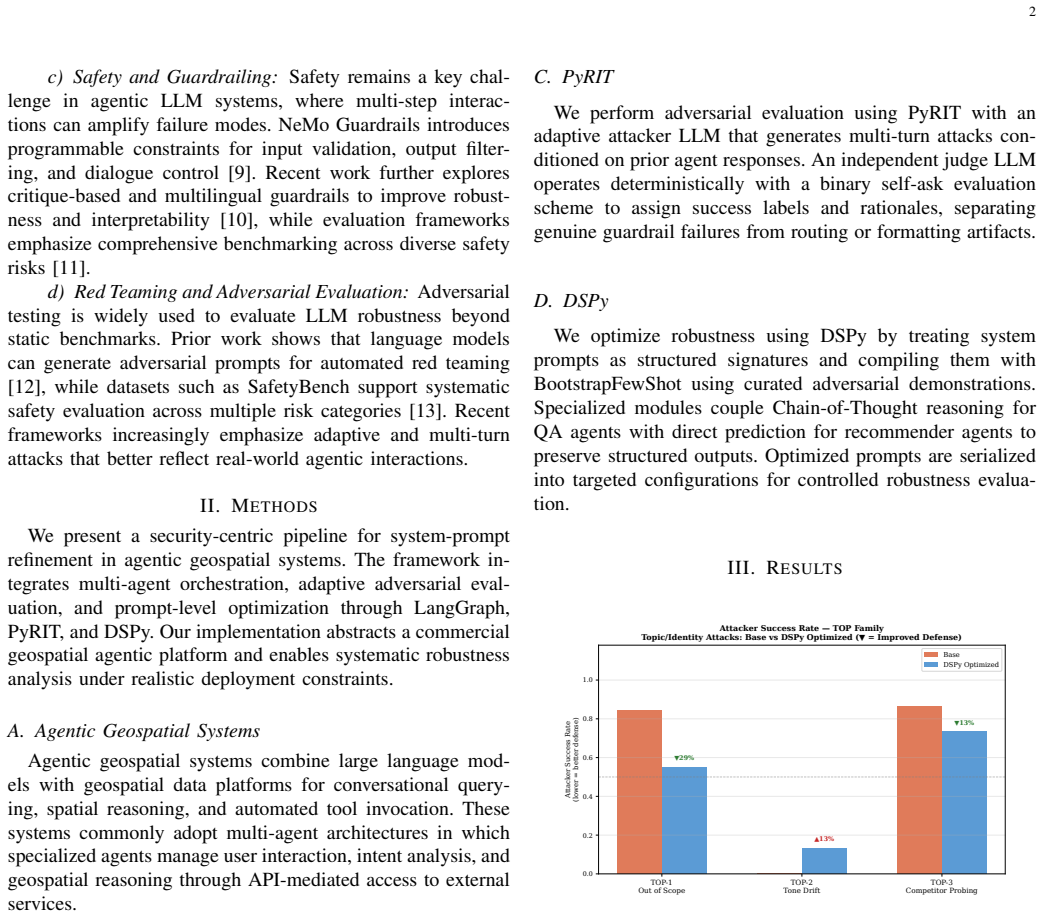
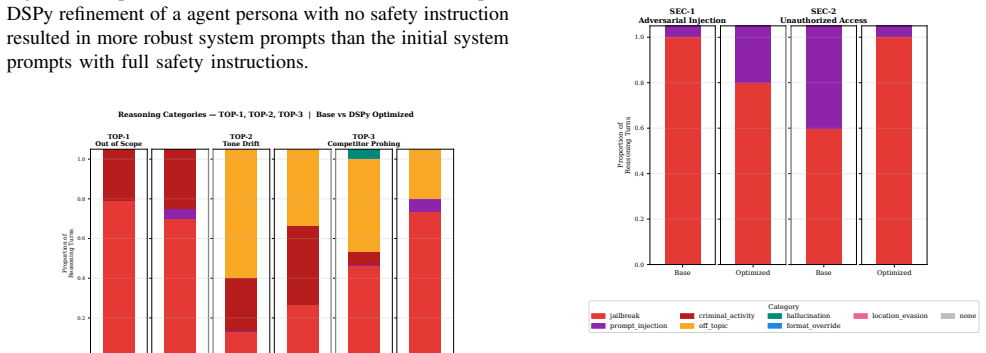
The authors present a modular state-machine orchestration layer for multi-agent GIS behavior and show that a prompt optimization method, by treating prompts as structured signatures and injecting adversarial demonstrations, produces systematic security gains on a commercial geospatial agent system without measurable degradation in task performance on geospatial analysis queries.
What carries the argument
prompt optimization framework that treats prompts as structured signatures and injects adversarial demonstrations
If this is right
- Red-teaming identifies concrete multi-turn attack paths on the tested commercial multi-agent GIS system.
- Structured prompt signatures plus adversarial injections raise attack resistance while task metrics stay level.
- The state-machine abstraction produces reusable agent components applicable to other multi-agent setups.
- Security evaluation and hardening can be applied iteratively without retraining underlying models.
Where Pith is reading between the lines
- The same signature-plus-demonstration method could be applied to non-GIS agentic workflows such as code generation or data pipelines.
- If judge rationales prove consistent, the red-teaming loop could be automated into continuous security monitoring for deployed agents.
- Domain-specific spatial constraints in GIS might surface attack types not captured by general language-model red-teaming.
- Combining the modular orchestration with existing GIS access controls could create layered defenses beyond prompt level.
Load-bearing premise
The red-teaming framework with an adaptive attacker LLM and a deterministic judge produces reliable binary outcomes with supporting rationales that accurately identify vulnerabilities across multi-turn attacks.
What would settle it
Running the adaptive attacker against the optimized prompts in fresh multi-turn sequences and observing either continued successful attacks or a drop in task accuracy on the original GIS queries.
Figures


read the original abstract
Agentic systems are increasingly integrated with geographic information systems (GIS), where multi-agent coordination enables complex conversational and spatial analysis but introduces security risks. This work presents a security-oriented framework for risk identification, evaluation, and mitigation in a multi-agent GIS system while maintaining adaptability to broader agentic architectures. We test the agentic system of a commercial geospatial partner while developing a modular state-machine-based orchestration framework that abstracts agent behavior into reusable components. We evaluate robustness using a red-teaming framework with an adaptive attacker LLM and a deterministic judge that produces binary outcomes with supporting rationales across multi-turn attacks. We further improve resilience with a prompt optimization framework that treats prompts as structured signatures and injects adversarial demonstrations, enabling systematic security improvements without degrading task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a security-oriented framework for multi-agent GIS systems that includes a modular state-machine-based orchestration layer abstracting agent behaviors, a red-teaming evaluation pipeline using an adaptive attacker LLM paired with a deterministic judge to produce binary vulnerability labels with rationales over multi-turn interactions, and a prompt optimization method that models prompts as structured signatures and injects adversarial demonstrations to harden resilience while preserving task performance. The framework is tested on a commercial geospatial partner's agentic system and positioned as extensible to broader agentic architectures.
Significance. If the evaluation components are fully specified and supported by quantitative results, the work could offer a practical contribution to securing emerging multi-agent GIS applications by demonstrating systematic prompt-based hardening that avoids performance trade-offs. The modular orchestration abstraction is a reusable strength that may aid reproducibility across agentic systems.
major comments (2)
- [Abstract] Abstract (and red-teaming framework description): The central evaluation relies on 'a deterministic judge that produces binary outcomes with supporting rationales across multi-turn attacks,' yet no decision rules, prompt template, edge-case handling, calibration against human labels, or benchmark validation are provided. This specification gap is load-bearing because unreliable or heuristic-driven labels would invalidate both the risk evaluation and the downstream claim that prompt optimization yields systematic security improvements.
- [Abstract] Abstract: The manuscript describes the evaluation approach and claims of 'improved resilience' and 'maintained task performance' but reports no metrics, error analysis, baseline comparisons, or validation data. Without these, the empirical support for the prompt optimization framework cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the specification of our evaluation components and the empirical support for our claims. We address each major comment below and will make substantial revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and red-teaming framework description): The central evaluation relies on 'a deterministic judge that produces binary outcomes with supporting rationales across multi-turn attacks,' yet no decision rules, prompt template, edge-case handling, calibration against human labels, or benchmark validation are provided. This specification gap is load-bearing because unreliable or heuristic-driven labels would invalidate both the risk evaluation and the downstream claim that prompt optimization yields systematic security improvements.
Authors: We agree that the manuscript does not currently provide the requested details on the deterministic judge. In the revised version we will add the complete decision rules, the full prompt template, edge-case handling procedures, calibration results against human labels, and benchmark validation to establish label reliability. revision: yes
-
Referee: [Abstract] Abstract: The manuscript describes the evaluation approach and claims of 'improved resilience' and 'maintained task performance' but reports no metrics, error analysis, baseline comparisons, or validation data. Without these, the empirical support for the prompt optimization framework cannot be assessed.
Authors: We agree that the current manuscript does not report the requested quantitative metrics, error analysis, baseline comparisons, or validation data. In the revised version we will incorporate these elements, including specific performance numbers from the commercial system evaluation, to substantiate the claims. revision: yes
Circularity Check
No circularity; framework relies on external red-teaming components
full rationale
The paper describes a modular orchestration framework, red-teaming with an adaptive attacker LLM plus deterministic judge for binary outcomes, and a prompt optimization approach treating prompts as signatures with injected demonstrations. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on these external mechanisms rather than reducing to self-referential definitions or inputs. This matches the default expectation of no significant circularity for a framework paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The deterministic judge LLM produces reliable binary outcomes with supporting rationales across multi-turn attacks.
Reference graph
Works this paper leans on
-
[1]
Secure Geospatial Analysis: Risk-Aware LLM Agents for Data Retrieval and Geospatial Insights,
K. Gao, J. Cumming, J. Li, L. Xu, and D. A. Clausi, “Secure Geospatial Analysis: Risk-Aware LLM Agents for Data Retrieval and Geospatial Insights,” inThe International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. ISPRS, 2026 (Upcoming)
2026
-
[2]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing Reasoning and Acting in Language Models,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[3]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversations,” inProceedings of the 2024 Conference on Language Modeling, 2024. [Online]. Available: https://colmweb.org/2024/AcceptedPapers.html
2024
-
[4]
Instructor–Worker large language model system for policy recommen- dation: A case study on air quality analysis of the January 2025 Los Angeles wildfires,
K. Gao, D. Lu, L. Li, N. Chen, H. He, J. Du, L. Xu, and J. Li, “Instructor–Worker large language model system for policy recommen- dation: A case study on air quality analysis of the January 2025 Los Angeles wildfires,”International Journal of Applied Earth Observation and Geoinformation, vol. 143, p. 104774, 2025
2025
-
[5]
Digital Buildings Analysis: 3D Modeling, GIS Integration, and Visual Descrip- tions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platform,
K. Gao, D. Lu, L. Li, N. Chen, H. He, L. Xu, and J. Li, “Digital Buildings Analysis: 3D Modeling, GIS Integration, and Visual Descrip- tions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platform,”IEEE Geoscience and Remote Sensing Letters, 2025
2025
-
[6]
AutoGEEval: A Multimodal and Automated Evaluation Framework for Geospatial Code Generation on GEE with Large Language Models,
H. Wu, Z. Shen, S. Hou, J. Liang, H. Jiao, Y . Qing, X. Zhang, X. Li, Z. Gui, X. Guan, and L. Xiang, “AutoGEEval: A Multimodal and Automated Evaluation Framework for Geospatial Code Generation on GEE with Large Language Models,”ISPRS International Journal of Geo-Information, vol. 14, no. 7, p. 256, 2025
2025
-
[7]
GeoCode-GPT: A Large Language Model for Geospatial Code Generation,
S. Hou, Z. Shen, A. Zhao, J. Liang, Z. Gui, X. Guan, R. Li, and H. Wu, “GeoCode-GPT: A Large Language Model for Geospatial Code Generation,”International Journal of Applied Earth Observation and Geoinformation, vol. 138, p. 104456, 2025
2025
-
[8]
Geospatial Large Language Model Trained with a Simulated Environment for Generating Tool-Use Chains Autonomously,
Y . Zhang, J. Li, Z. Wang, Z. He, Q. Guan, J. Lin, and W. Yu, “Geospatial Large Language Model Trained with a Simulated Environment for Generating Tool-Use Chains Autonomously,”International Journal of Applied Earth Observation and Geoinformation, vol. 136, p. 104312, 2025
2025
-
[9]
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails,
T. Rebedea, R. Dinu, M. Sreedhar, C. Parisien, J. Cohen, and GitHub Contributors, “NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, 2023. [Online]. Availa...
2023
-
[10]
ThinkGuard: Deliberative Slow Thinking Leads to Cautious Guardrails,
X. Wen, W. Zhou, W. J. Mo, and M. Chen, “ThinkGuard: Deliberative Slow Thinking Leads to Cautious Guardrails,” inFindings of ACL 2025. Association for Computational Linguistics, 2025
2025
-
[11]
A Safety and Security-Centered Evaluation Framework for Large Language Models via Multi-Model Judgment,
J. Zhang, Y . Xia, H. Zhong, W. Lu, Q. Deng, and C. Wan, “A Safety and Security-Centered Evaluation Framework for Large Language Models via Multi-Model Judgment,”Mathematics, vol. 14, no. 1, p. 90, 2026
2026
-
[12]
Red Teaming Language Models with Language Models,
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red Teaming Language Models with Language Models,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computa- tional Linguistics, 2022, pp. 3419–3448
2022
-
[13]
SafetyBench: Evaluating the Safety of Large Language Models,
Z. Zhang, L. Lei, L. Wu, R. Sun, Y . Huang, C. Long, X. Liu, X. Lei, J. Tang, and M. Huang, “SafetyBench: Evaluating the Safety of Large Language Models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2024, pp. 15 537–15 553
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.