MLLP-VRAIN UPV system for the IWSLT 2026 Simultaneous Speech Translation task
Pith reviewed 2026-06-27 03:08 UTC · model grok-4.3
The pith
Cascaded Parakeet-Qwen system with adaptive policies raises En-De SimulST quality by 5.82 XCOMET-XL points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The submission achieves a +5.82 XCOMET-XL quality improvement on the MCIF En→De test set compared to the previous year through the use of Parakeet and Qwen 3.5 models in a cascaded setup with adaptive black-box policies, and a further +1.03 with context track processing using ASR word-boosting and RAG.
What carries the argument
Adaptive black-box policies that relax constraints to improve quality-latency trade-offs in the cascaded Parakeet-Qwen pipeline, augmented by ASR word-boosting and RAG of offline pre-translated exemplars for the context track.
If this is right
- The same pipeline can be applied to all language directions in the task rather than only En→De.
- Relaxing the black-box policies produces measurable improvements in the quality-latency operating point.
- Context processing that mixes word-boosting with retrieved exemplars adds a further 1.03 XCOMET-XL on the tested directions.
- A full latency breakdown of the cascaded system is supplied for the reported configurations.
Where Pith is reading between the lines
- Similar context mechanisms could be tested on language pairs without dedicated offline exemplars to check whether gains generalize.
- The absence of component ablations leaves open the question of whether model updates alone could explain part of the 5.82-point jump.
- The approach of combining online ASR with retrieved offline translations may reduce the need for full end-to-end training on long-form data.
Load-bearing premise
That the reported quality gains are caused by the adaptive policies, word-boosting, and RAG rather than other changes in models or data.
What would settle it
An ablation that disables the adaptive policies or the RAG component and re-measures XCOMET-XL on the identical MCIF En→De test set.
Figures

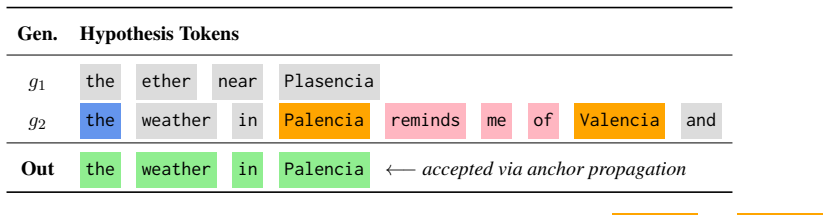
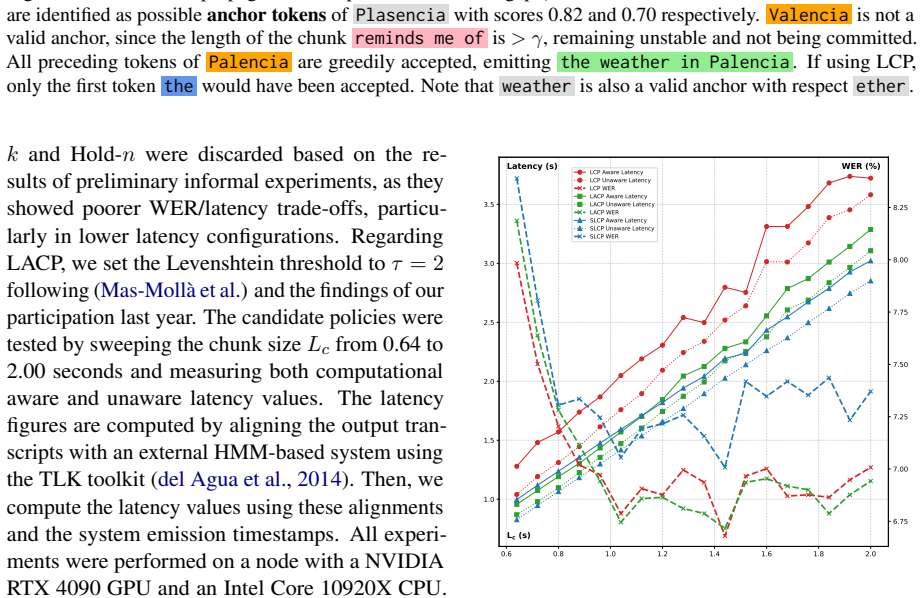
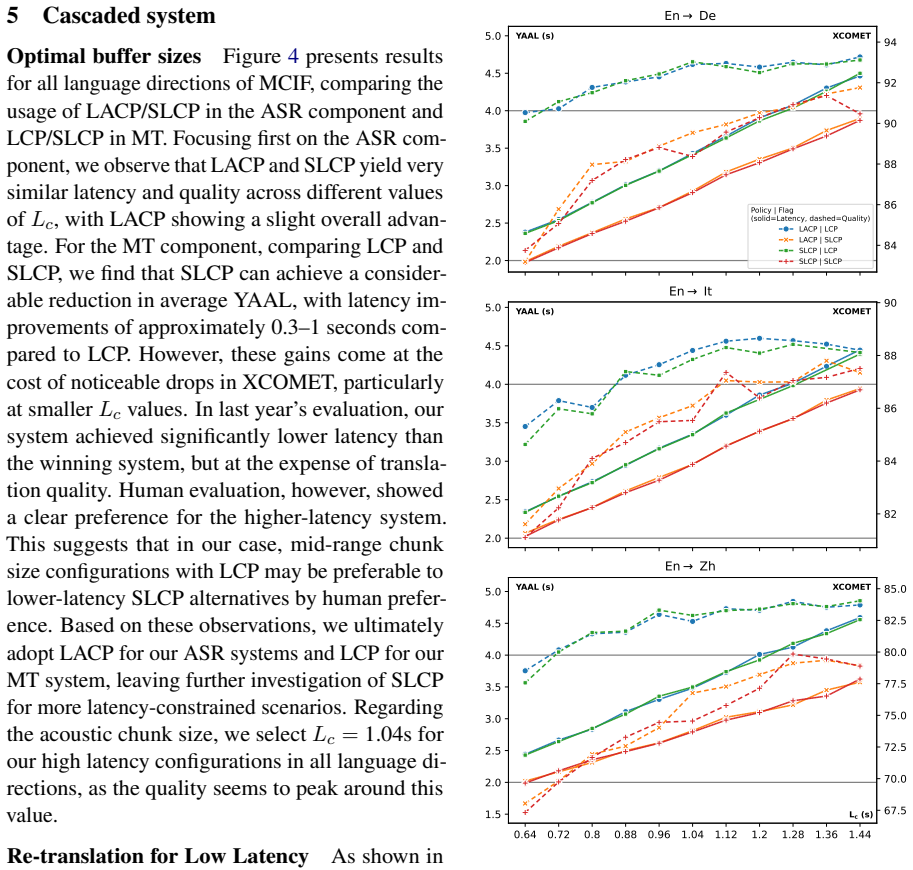
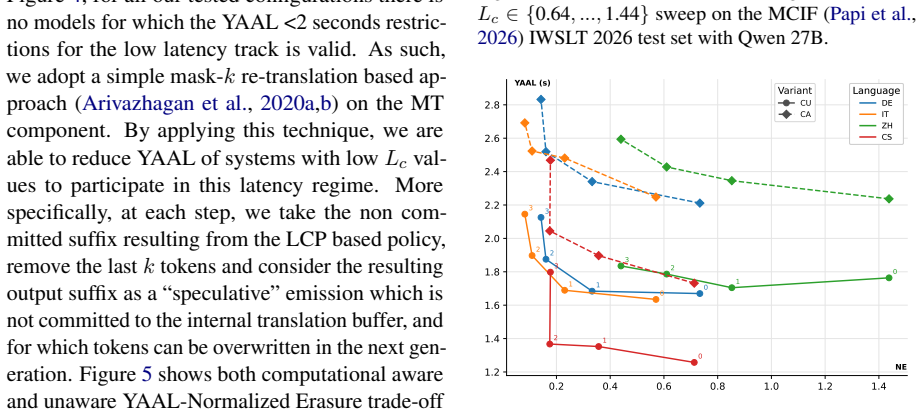
read the original abstract
This work describes the participation of the MLLP-VRAIN research group in the shared task of the IWSLT 2026 Simultaneous Speech Translation track. Our submission utilizes the recently released Parakeet and Qwen 3.5 models to create a robust, cascaded solution for long-form SimulST through the use of adaptive "black-box" policies. We explore relaxations of these policies to achieve better quality-latency trade-offs. Compared to last year, we participate on all language directions. In addition to this, for the En$\rightarrow${De, It, Zh} directions we also participate in this year's new context track employing a combination of ASR word-boosting and a RAG mechanism of offline pre-translated exemplars to guide generation and enrich our system with domain-specific context. Finally, we provide a detailed latency analysis of our system. Compared to last year, results on the MCIF En$\rightarrow$De test set shows a substantial quality improvement of +5.82 XCOMET-XL. Our context track processing further improves performance by +1.03.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the MLLP-VRAIN UPV participation in the IWSLT 2026 Simultaneous Speech Translation shared task. It describes a cascaded system based on Parakeet for speech recognition and Qwen 3.5 for translation, employing adaptive black-box policies to manage quality-latency trade-offs in long-form simultaneous translation. For En→De, En→It, and En→Zh, it additionally enters the context track by incorporating ASR word-boosting and a RAG mechanism using offline pre-translated exemplars. The paper reports a +5.82 XCOMET-XL improvement over the prior year on the MCIF En→De test set and a further +1.03 gain from the context track, along with a latency analysis.
Significance. If the reported gains can be substantiated with controlled evaluations, the work would demonstrate practical value in combining recent foundation models with adaptive policies and retrieval-based context for simultaneous speech translation. Multi-directional coverage and the new context track add empirical results to the shared task, while the latency analysis may offer guidance on trade-offs.
major comments (2)
- [Abstract] Abstract: The claim of a +5.82 XCOMET-XL quality improvement compared to last year on the MCIF En→De test set is presented without evaluation details, baselines, error bars, ablation results, or confirmation that prior-year conditions were matched, so the data cannot support the central claim as stated.
- [Abstract] Abstract: The additional +1.03 improvement attributed to context track processing (ASR word-boosting and RAG of offline pre-translated exemplars) lacks any ablation studies or controlled comparisons isolating these components from other changes such as the switch to Parakeet + Qwen 3.5, preventing causal attribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our IWSLT 2026 submission description. We address the two major comments on the abstract below. Both points can be clarified by reference to the shared-task evaluation protocol and by modest revisions that make the comparisons explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a +5.82 XCOMET-XL quality improvement compared to last year on the MCIF En→De test set is presented without evaluation details, baselines, error bars, ablation results, or confirmation that prior-year conditions were matched, so the data cannot support the central claim as stated.
Authors: The +5.82 XCOMET-XL figure is the difference between the official XCOMET-XL score returned by the IWSLT 2026 organizers for our 2026 primary submission and the corresponding official score for the best En→De system (or our own 2025 submission) on the identical MCIF test set. Because the metric, test set, and evaluation pipeline are fixed by the shared task, the comparison already uses matched conditions. The body of the paper describes the system (Parakeet + Qwen 3.5 + adaptive policies) that produced the new score; we did not recompute last year’s numbers ourselves. We acknowledge that the abstract is terse and will revise it to state explicitly that the delta uses the organizers’ official scores on the same test set and metric. revision: yes
-
Referee: [Abstract] Abstract: The additional +1.03 improvement attributed to context track processing (ASR word-boosting and RAG of offline pre-translated exemplars) lacks any ablation studies or controlled comparisons isolating these components from other changes such as the switch to Parakeet + Qwen 3.5, preventing causal attribution.
Authors: The +1.03 XCOMET-XL gain is measured between our two 2026 submissions on the same test set: the context-track entry (which adds ASR word-boosting and RAG) versus our primary non-context entry. Both submissions use identical Parakeet ASR, Qwen 3.5 MT, and adaptive black-box policies; the only difference is the context-track components. This within-year contrast therefore isolates the contribution of word-boosting and RAG. We will revise the abstract to make this within-system comparison explicit. revision: yes
Circularity Check
No circularity; factual participation report with direct benchmark scores
full rationale
The paper is a system description for the IWSLT 2026 shared task. It reports implementation choices (Parakeet, Qwen 3.5, adaptive policies, ASR word-boosting, RAG) and measured XCOMET-XL scores on the MCIF En→De test set, with direct year-over-year deltas. No equations, parameter fits, predictive derivations, or self-citation chains appear. The +5.82 and +1.03 deltas are presented as observed outcomes on external benchmarks rather than outputs of any internal model that reduces to its own inputs. The document contains no load-bearing self-referential steps of the enumerated kinds and is self-contained against the task's public test sets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Idris Abdulmumin, Victor Agostinelli, Tanel Alum \"a e, Antonios Anastasopoulos, Luisa Bentivogli, Ond r ej Bojar, Claudia Borg, Fethi Bougares, Roldano Cattoni, Mauro Cettolo, Lizhong Chen, William Chen, Raj Dabre, Yannick Est \`e ve, Marcello Federico, Mark Fishel, Marco Gaido, D \'a vid Javorsk \'y , Marek Kasztelnik, and 33 others. 2025. https://doi.o...
-
[2]
David Ifeoluwa Adelani, Victor Agostinelli, Antonios Anastasopoulos, Luisa Bentivogli, Ond r ej Bojar, Sebastien Brati \`e res, Marine Carpuat, Roldano Cattoni, Mauro Cettolo, Lizhong Chen, Marcello Federico, Marco Gaido, Mahendra Gupta, HyoJung Han, Ali Hatami, David Javorsk \'y , Yejin Jeon, Marek Kasztelnik, Antoine Laurent, and 33 others. 2026. Speech...
2026
-
[3]
Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. 2023. https://doi.org/10.18653/v1/2023.findings-acl.564 In-context examples selection for machine translation . In Findings of the Association for Computational Linguistics: ACL 2023, pages 8857--8873, Toronto, Canada. Association for Computational Linguistics
-
[4]
Andrei Andrusenko, Vladimir Bataev, Lilit Grigoryan, Vitaly Lavrukhin, and Boris Ginsburg. 2025. https://doi.org/10.1109/ASRU65441.2025.11434614 Turbobias: Universal asr context-biasing powered by gpu-accelerated phrase-boosting tree . In 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1--7
-
[5]
Naveen Arivazhagan, Colin Cherry, Te I, Wolfgang Macherey, Pallavi Baljekar, and George F. Foster. 2020 a . https://doi.org/10.1109/ICASSP40776.2020.9054585 Re-translation strategies for long form, simultaneous, spoken language translation . In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, Ma...
-
[6]
Naveen Arivazhagan, Colin Cherry, Wolfgang Macherey, and George Foster. 2020 b . https://doi.org/10.18653/v1/2020.iwslt-1.27 Re-translation versus streaming for simultaneous translation . In Proceedings of the 17th International Conference on Spoken Language Translation, pages 220--227, Online. Association for Computational Linguistics
-
[7]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. https://doi.org/10.21437/INTERSPEECH.2023-78 Whisperx: Time-accurate speech transcription of long-form audio . In 24th Annual Conference of the International Speech Communication Association, Interspeech 2023, Dublin, Ireland, August 20-24, 2023, pages 4489--4493
-
[8]
Shanbo Cheng, Yu Bao, Zhichao Huang, Yu Lu, Ningxin Peng, Lu Xu, Runsheng Yu, Rong Cao, Yujiao Du, Ting Han, Yuxiang Hu, Zeyang Li, Sitong Liu, Shengtao Ma, Shiguang Pan, Jiongchen Xiao, Nuo Xu, Meng Yang, Rong Ye, and 9 others. 2025. https://doi.org/10.48550/ARXIV.2507.17527 Seed liveinterpret 2.0: End-to-end simultaneous speech-to-speech translation wit...
-
[9]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. https://doi.org/10.18653/v1/2020.acl-main.747 Unsupervised cross-lingual representation learning at scale . In Proceedings of the 58th Annual Meeting of the Association for Comp...
-
[10]
No Language Left Behind: Scaling Human-Centered Machine Translation
Marta R. Costa - juss \` a , James Cross, Onur C elebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Y. Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Lo \" c Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, and 19 others. 2022. https://doi.org/10.48550/AR...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.04672 2022
-
[11]
Hiroyuki Deguchi, Yusuke Sakai, Hidetaka Kamigaito, and Taro Watanabe. 2024. https://doi.org/10.18653/v1/2024.emnlp-demo.37 mbrs: A library for minimum B ayes risk decoding . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 351--362, Miami, Florida, USA. Association for Computational L...
-
[12]
M. A. del Agua, A. Giménez, N. Serrano, J. Andrés-Ferrer, J. Civera, A. Sanchis, and A. Juan. 2014. http://www.mllp.upv.es/wp-content/uploads/2015/04/IberSpeech2014-TLK-camready1.pdf The translectures-upv toolkit . In Proc. of VIII Jornadas en Tecnología del Habla and IV Iberian SLTech Workshop (IberSpeech 2014), Las Palmas de Gran Canaria (Spain)
2014
-
[13]
John DeNero, David Chiang, and Kevin Knight. 2009. https://aclanthology.org/P09-1064/ Fast consensus decoding over translation forests . In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pages 567--575, Suntec, Singapore. Association for Com...
2009
-
[14]
Bryan Eikema and Wilker Aziz. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.754 Sampling-based approximations to minimum B ayes risk decoding for neural machine translation . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10978--10993, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[15]
Mara Finkelstein, Isaac Caswell, Tobias Domhan, Jan - Thorsten Peter, Juraj Juraska, Parker Riley, Daniel Deutsch, Geza Kovacs, Cole Dilanni, Colin Cherry, Eleftheria Briakou, Elizabeth Nielsen, Jiaming Luo, Kat Black, Ryan Mullins, Sweta Agrawal, Wenda Xu, Erin Kats, Stephane Jaskiewicz, and 2 others. 2026. https://doi.org/10.48550/ARXIV.2601.09012 Trans...
-
[16]
Markus Freitag, Behrooz Ghorbani, and Patrick Fernandes. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.617 Epsilon sampling rocks: Investigating sampling strategies for minimum B ayes risk decoding for machine translation . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9198--9209, Singapore. Association for Comput...
-
[17]
Vaibhava Goel and William J. Byrne. 2000. https://doi.org/10.1006/CSLA.2000.0138 Minimum bayes-risk automatic speech recognition . Comput. Speech Lang., 14(2):115--135
-
[18]
Lilit Grigoryan, Vladimir Bataev, Andrei Andrusenko, Hainan Xu, Vitaly Lavrukhin, and Boris Ginsburg. 2025. https://doi.org/10.21437/INTERSPEECH.2025-1388 Pushing the limits of beam search decoding for transducer-based ASR models . In 26th Annual Conference of the International Speech Communication Association, Interspeech 2025, Rotterdam, The Netherlands...
-
[19]
Maarten Grootendorst. 2020. https://doi.org/10.5281/zenodo.4461265 Keybert: Minimal keyword extraction with bert
-
[20]
Nuno Miguel Guerreiro, Ricardo Rei, Daan van Stigt, Lu \' sa Coheur, Pierre Colombo, and Andr \' e F. T. Martins. 2024. https://doi.org/10.1162/TACL\_A\_00683 xcomet : Transparent machine translation evaluation through fine-grained error detection . Trans. Assoc. Comput. Linguistics, 12:979--995
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[21]
Shoutao Guo, Shaolei Zhang, Zhengrui Ma, Min Zhang, and Yang Feng. 2025. https://doi.org/10.1109/TASLPRO.2025.3566220 Agent-simt: Agent-assisted simultaneous translation with large language models . IEEE Transactions on Audio, Speech and Language Processing, 33:2074--2083
-
[22]
John Hewitt, Christopher Manning, and Percy Liang. 2022. https://doi.org/10.18653/v1/2022.findings-emnlp.249 Truncation sampling as language model desmoothing . In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 3414--3427, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[23]
Javier Iranzo-S \'a nchez, Jorge Iranzo-S \'a nchez, Adri \`a Gim \'e nez, Jorge Civera, and Alfons Juan. 2024. https://doi.org/10.1162/tacl_a_00691 Segmentation-free streaming machine translation . Transactions of the Association for Computational Linguistics, 12:1104--1121
-
[24]
Jorge Iranzo-S \'a nchez, Javier Iranzo-S \'a nchez, Adri \`a Gim \'e nez, and Jorge Civera. 2025 a . https://doi.org/10.18653/v1/2025.findings-acl.937 Going beyond your expectations in latency metrics for simultaneous speech translation . In Findings of the Association for Computational Linguistics: ACL 2025, pages 18205--18228, Vienna, Austria. Associat...
-
[25]
Jorge Iranzo-S \'a nchez, Javier Iranzo-Sanchez, Adri \`a Gim \'e nez Pastor, Jorge Civera Saiz, and Alfons Juan. 2025 b . https://doi.org/10.18653/v1/2025.iwslt-1.35 MLLP - VRAIN UPV system for the IWSLT 2025 simultaneous speech translation translation task . In Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025),...
-
[26]
Masoud Jalili Sabet, Philipp Dufter, Fran c ois Yvon, and Hinrich Sch \"u tze. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.147 S im A lign: High quality word alignments without parallel training data using static and contextualized embeddings . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1627--1643, Online. As...
-
[27]
Yuu Jinnai. 2025. https://doi.org/10.48550/ARXIV.2510.19471 Re-evaluating minimum bayes risk decoding for automatic speech recognition . CoRR, abs/2510.19471
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.19471 2025
-
[28]
Tom Kocmi, Ekaterina Artemova, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Konstantin Dranch, Anton Dvorkovich, Sergey Dukanov, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Howard Lakougna, Jessica Lundin, Christof Monz, Kenton Murray, and 10 others. 2025. https://doi.org/10.18653...
-
[29]
Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Benjamin Marie, Christof Monz, Kenton Murray, Masaaki Nagata, Martin Popel, Maja Popovi \'c , and 3 others. 2024. https://doi.org/10.18653/v1/...
-
[30]
Roman Koshkin, Katsuhito Sudoh, and Satoshi Nakamura. 2024 a . https://doi.org/10.18653/v1/2024.emnlp-main.69 LLM s are zero-shot context-aware simultaneous translators . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1192--1207, Miami, Florida, USA. Association for Computational Linguistics
-
[31]
Roman Koshkin, Katsuhito Sudoh, and Satoshi Nakamura. 2024 b . https://doi.org/10.18653/v1/2024.findings-emnlp.27 T rans LL a M a: LLM -based simultaneous translation system . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 461--476, Miami, Florida, USA. Association for Computational Linguistics
-
[32]
Shankar Kumar and William Byrne. 2004. https://aclanthology.org/N04-1022/ Minimum B ayes-risk decoding for statistical machine translation . In Proceedings of the Human Language Technology Conference of the North A merican Chapter of the Association for Computational Linguistics: HLT - NAACL 2004 , pages 169--176, Boston, Massachusetts, USA. Association f...
2004
-
[33]
Daniil Larionov, Mikhail Seleznyov, Vasiliy Viskov, Alexander Panchenko, and Steffen Eger. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1223 x COMET -lite: Bridging the gap between efficiency and quality in learned MT evaluation metrics . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21934--21949, Mi...
-
[34]
Xintong Li, Guanlin Li, Lemao Liu, Max Meng, and Shuming Shi. 2019. https://doi.org/10.18653/v1/P19-1124 On the word alignment from neural machine translation . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1293--1303, Florence, Italy. Association for Computational Linguistics
-
[35]
Zhaolin Li, Yining Liu, Danni Liu, Tuan Nam Nguyen, Enes Yavuz Ugan, Tu Anh Dinh, Carlos Mullov, Alexander Waibel, and Jan Niehues. 2025. https://doi.org/10.18653/v1/2025.iwslt-1.20 KIT ' s low-resource speech translation systems for IWSLT 2025: System enhancement with synthetic data and model regularization . In Proceedings of the 22nd International Conf...
-
[37]
Danni Liu, Gerasimos Spanakis, and Jan Niehues. 2020 b . https://doi.org/10.21437/Interspeech.2020-2897 Low-Latency Sequence-to-Sequence Speech Recognition and Translation by Partial Hypothesis Selection . In Interspeech 2020 , pages 3620--3624
-
[38]
Jiaxuan Luo, Siqi Ouyang, and Lei Li. 2026. https://arxiv.org/abs/2601.22777 Rasst: Fast cross-modal retrieval-augmented simultaneous speech translation . Preprint, arXiv:2601.22777
arXiv 2026
-
[39]
Xing Han Lù. 2024. https://arxiv.org/abs/2407.03618 Bm25s: Orders of magnitude faster lexical search via eager sparse scoring . Preprint, arXiv:2407.03618
arXiv 2024
-
[40]
Mingbo Ma, Liang Huang, Hao Xiong, Renjie Zheng, Kaibo Liu, Baigong Zheng, Chuanqiang Zhang, Zhongjun He, Hairong Liu, Xing Li, Hua Wu, and Haifeng Wang. 2019. https://doi.org/10.18653/v1/P19-1289 STACL : Simultaneous translation with implicit anticipation and controllable latency using prefix-to-prefix framework . In Proceedings of the 57th Annual Meetin...
-
[41]
Dominik Mach \'a c ek, Ond r ej Bojar, and Raj Dabre. 2023. https://doi.org/10.18653/v1/2023.iwslt-1.12 MT metrics correlate with human ratings of simultaneous speech translation . In Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023), pages 169--179, Toronto, Canada (in-person and online). Association for Computa...
-
[42]
Dominik Mach \'a c ek and Peter Pol \'a k. 2025. https://doi.org/10.18653/v1/2025.iwslt-1.41 Simultaneous translation with offline speech and LLM models in CUNI submission to IWSLT 2025 . In Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 389--398, Vienna, Austria (in-person and online). Association for ...
-
[43]
Zhuoyuan Mao and Yen Yu. 2024. https://doi.org/10.18653/v1/2024.loresmt-1.1 Tuning LLM s with contrastive alignment instructions for machine translation in unseen, low-resource languages . In Proceedings of the Seventh Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2024), pages 1--25, Bangkok, Thailand. Association for...
-
[44]
Improving streaming ASR with foundation models using emission policies
Gerard Mas-Mollà, Albert Sanchis, and Alfons Juan. Improving streaming ASR with foundation models using emission policies. Submitted to Interspeech 2026
2026
-
[45]
Kenton Murray and David Chiang. 2018. https://doi.org/10.18653/v1/W18-6322 Correcting length bias in neural machine translation . In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 212--223, Brussels, Belgium. Association for Computational Linguistics
-
[46]
Gállego, Jorge Iranzo-Sánchez, Ahrii Kim, Dominik Macháček, Patricia Schmidtova, and Maike Züfle
Sara Papi, Javier Garcia Gilabert, Zachary Hopton, Vilém Zouhar, Carlos Escolano, Gerard I. Gállego, Jorge Iranzo-Sánchez, Ahrii Kim, Dominik Macháček, Patricia Schmidtova, and Maike Züfle. 2025. https://arxiv.org/abs/2512.16378 Hearing to translate: The effectiveness of speech modality integration into llms . Preprint, arXiv:2512.16378
Pith/arXiv arXiv 2025
-
[47]
Sara Papi, Maike Z \"u fle, Marco Gaido, Beatrice Savoldi, Danni Liu, Ioannis Douros, Luisa Bentivogli, and Jan Niehues. 2026. https://openreview.net/forum?id=PtPYZYfa0h MCIF : Multimodal crosslingual instruction-following benchmark from scientific talks . In The Fourteenth International Conference on Learning Representations
2026
-
[48]
Peter Pol \'a k, Danni Liu, Ngoc-Quan Pham, Jan Niehues, Alexander Waibel, and Ond r ej Bojar. 2023. https://doi.org/10.18653/v1/2023.iwslt-1.37 Towards efficient simultaneous speech translation: CUNI - KIT system for simultaneous track at IWSLT 2023 . In Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023), pages 3...
-
[49]
Peter Pol \'a k, Ngoc-Quan Pham, Tuan Nam Nguyen, Danni Liu, Carlos Mullov, Jan Niehues, Ond r ej Bojar, and Alexander Waibel. 2022. https://doi.org/10.18653/v1/2022.iwslt-1.24 CUNI - KIT system for simultaneous speech translation task at IWSLT 2022 . In Proceedings of the 19th International Conference on Spoken Language Translation (IWSLT 2022), pages 27...
-
[50]
Peter Polák, Sara Papi, Luisa Bentivogli, and Ondřej Bojar. 2026. https://arxiv.org/abs/2509.17349 Better late than never: Meta-evaluation of latency metrics for simultaneous speech-to-text translation . Preprint, arXiv:2509.17349
arXiv 2026
-
[51]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395, Lisbon, Portugal. Association for Computational Linguistics
-
[52]
Maja Popovi \'c . 2017. https://doi.org/10.18653/v1/W17-4770 chr F ++: words helping character n-grams . In Proceedings of the Second Conference on Machine Translation, pages 612--618, Copenhagen, Denmark. Association for Computational Linguistics
-
[53]
Matt Post. 2018. https://doi.org/10.18653/v1/W18-6319 A call for clarity in reporting BLEU scores . In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 186--191, Brussels, Belgium. Association for Computational Linguistics
-
[54]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5 : Towards native multimodal agents
2026
-
[55]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. https://proceedings.mlr.press/v202/radford23a.html Robust speech recognition via large-scale weak supervision . In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , pages 28492--28518
2023
-
[56]
Matthew Raffel, Victor Agostinelli, and Lizhong Chen. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1017 Simultaneous masking, not prompting optimization: A paradigm shift in fine-tuning LLM s for simultaneous translation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18302--18314, Miami, Florida, US...
-
[57]
Miguel Moura Ramos, Duarte M. Alves, Hippolyte Gisserot-Boukhlef, João Alves, Pedro Henrique Martins, Patrick Fernandes, José Pombal, Nuno M. Guerreiro, Ricardo Rei, Nicolas Boizard, Amin Farajian, Mateusz Klimaszewski, José G. C. de Souza, Barry Haddow, François Yvon, Pierre Colombo, Alexandra Birch, and André F. T. Martins. 2026. https://arxiv.org/abs/2...
arXiv 2026
-
[58]
John W Ratcliff, David E Metzener, and 1 others. 1988. Pattern matching: The gestalt approach. Dr. Dobb’s Journal, 13(7):46
1988
-
[59]
Amin Farajian, and Andr \' e F
Ricardo Rei, Nuno Miguel Guerreiro, Jos \' e Pombal, Jo \ a o Alves, Pedro Teixeirinha, M. Amin Farajian, and Andr \' e F. T. Martins. 2025. https://doi.org/10.48550/ARXIV.2506.17080 Tower+: Bridging generality and translation specialization in multilingual llms . CoRR, abs/2506.17080
-
[60]
Monica Sekoyan, Nithin Rao Koluguri, Nune Tadevosyan, Piotr Zelasko, Travis Bartley, Nikolay Karpov, Jagadeesh Balam, and Boris Ginsburg. 2025. https://arxiv.org/abs/2509.14128 Canary-1b-v2 & parakeet-tdt-0.6b-v3: Efficient and high-performance models for multilingual asr and ast . Preprint, arXiv:2509.14128
arXiv 2025
-
[61]
Vaibhav Srivastav, Steven Zheng, Eric Bezzam, Eustache Le Bihan, Nithin Koluguri, Piotr Żelasko, Somshubra Majumdar, Adel Moumen, and Sanchit Gandhi. 2026. https://arxiv.org/abs/2510.06961 Open asr leaderboard: Towards reproducible and transparent multilingual and long-form speech recognition evaluation . Preprint, arXiv:2510.06961
arXiv 2026
-
[62]
Jannis Vamvas and Rico Sennrich. 2024. https://doi.org/10.18653/v1/2024.acl-short.71 Linear-time minimum B ayes risk decoding with reference aggregation . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 790--801, Bangkok, Thailand. Association for Computational Linguistics
-
[63]
Francesco Verdini, Pierfrancesco Melucci, Stefano Perna, Francesco Cariaggi, Marco Gaido, Sara Papi, Szymon Mazurek, Marek Kasztelnik, Luisa Bentivogli, Sebastien Bratières, Paolo Merialdo, and Simone Scardapane. 2025. https://doi.org/10.21437/Interspeech.2025-2245 How to Connect Speech Foundation Models and Large Language Models? What Matters and What Do...
-
[64]
Wenxuan Wang, Yingxin Zhang, Yifan Jin, Binbin Du, and Yuke Li. 2025. https://doi.org/10.18653/v1/2025.iwslt-1.19 NYA ' s offline speech translation system for IWSLT 2025 . In Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 206--211, Vienna, Austria (in-person and online). Association for Computational L...
-
[65]
Yilin Yang, Liang Huang, and Mingbo Ma. 2018. https://doi.org/10.18653/v1/D18-1342 Breaking the beam search curse: A study of (re-)scoring methods and stopping criteria for neural machine translation . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3054--3059, Brussels, Belgium. Association for Computation...
-
[66]
Mao Zheng, Zheng Li, Tao Chen, Mingyang Song, and Di Wang. 2025. https://arxiv.org/abs/2512.24092 Hy-mt1.5 technical report . Preprint, arXiv:2512.24092
arXiv 2025
-
[67]
Vil \'e m Zouhar, Maike Z \"u fle, Beni Egressy, Julius Cheng, Mrinmaya Sachan, and Jan Niehues. 2026. https://doi.org/10.18653/v1/2026.eacl-long.4 Early-exit and instant confidence translation quality estimation . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers) , p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.