Spatio-Temporal Fusion Model for Standard View Classification of Echocardiographic Videos
Pith reviewed 2026-06-27 02:09 UTC · model grok-4.3
The pith
A dual-stream CNN-LSTM uses uncertainty-aware sampling during training and evidence-based fusion at inference to classify echocardiographic views more robustly despite similar appearances and uneven frame quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The STFM framework jointly captures spatial anatomical structures and temporal cardiac dynamics through a dual-stream CNN-LSTM, leveraging uncertainty-aware learning to preferentially sample representative video segments during training and evidence-based fusion during inference, improving robustness to variations in frame quality across echocardiographic videos and achieving competitive performance across diverse video classification models.
What carries the argument
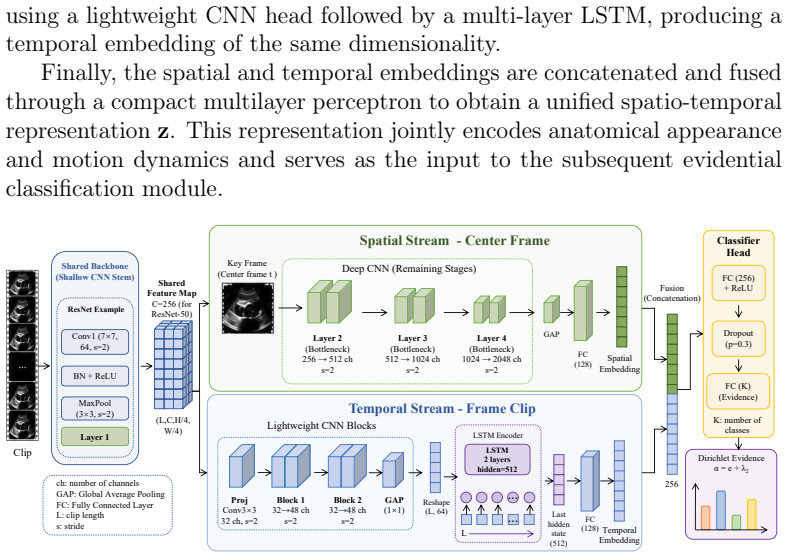
The Spatio-Temporal Fusion Model (STFM), a dual-stream CNN-LSTM that performs uncertainty-aware segment sampling in training and evidence-based fusion at inference to combine spatial and temporal features.
If this is right
- The EV9V dataset supplies a scale and view coverage that allows systematic comparison of video architectures previously underexplored for echocardiography.
- Uncertainty-aware segment selection during training reduces the impact of low-quality frames that otherwise degrade temporal fusion.
- Evidence-based fusion at inference time produces more stable predictions when individual frames within a video differ sharply in clarity.
- The same dual-stream design can be applied to other video classification backbones while retaining the uncertainty mechanisms.
Where Pith is reading between the lines
- The sampling strategy might transfer to other medical video domains where acquisition quality fluctuates, such as fetal ultrasound or endoscopic sequences.
- If uncertainty estimates prove reliable, the model could flag videos that still require human review rather than forcing an automated label.
- Testing the same mechanisms on datasets with fewer than nine views would clarify whether the benefit scales with task difficulty.
Load-bearing premise
That the uncertainty-aware sampling and evidence-based fusion steps, rather than dataset scale or standard CNN-LSTM capacity alone, are what drive the reported robustness gains.
What would settle it
A controlled comparison on EV9V in which a plain CNN-LSTM without the uncertainty mechanisms reaches equal or higher accuracy would show the added components are not necessary for the claimed improvement.
Figures
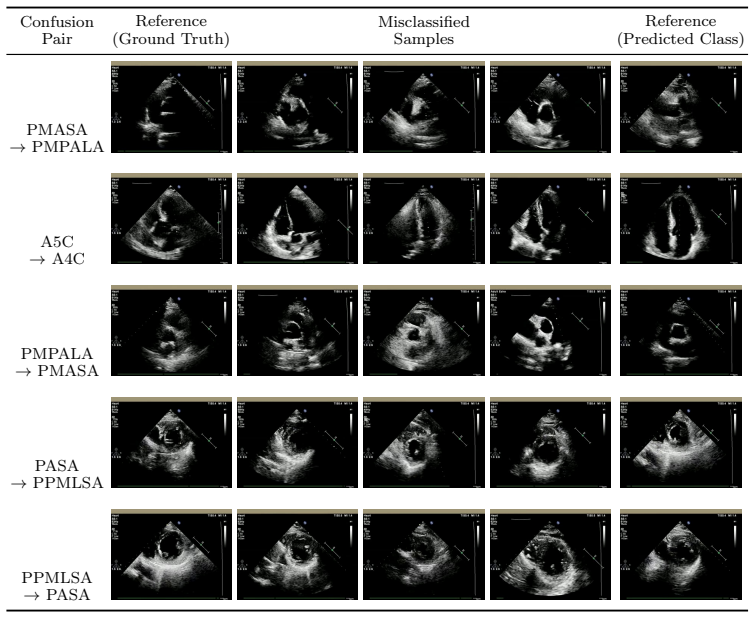
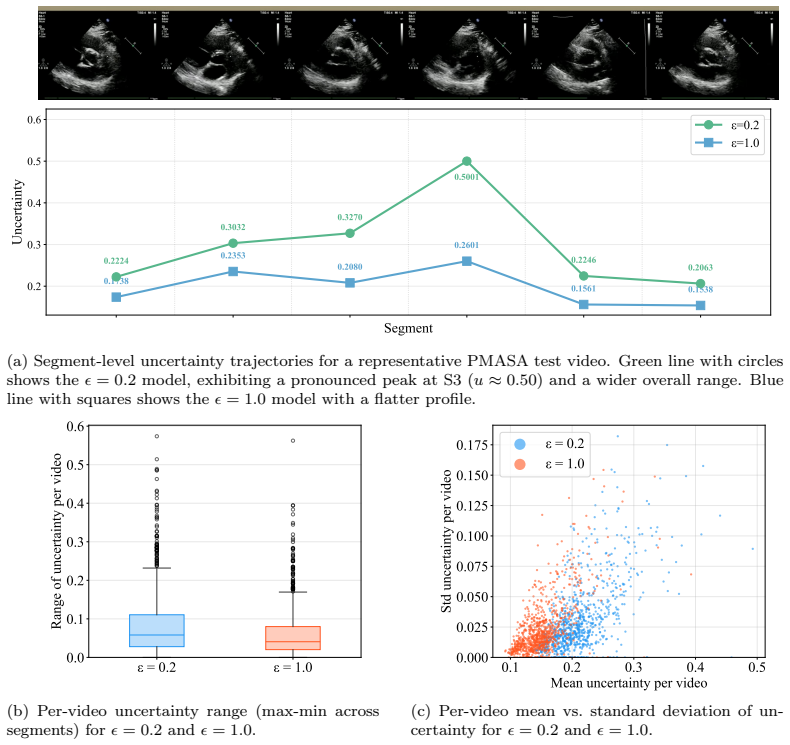
read the original abstract
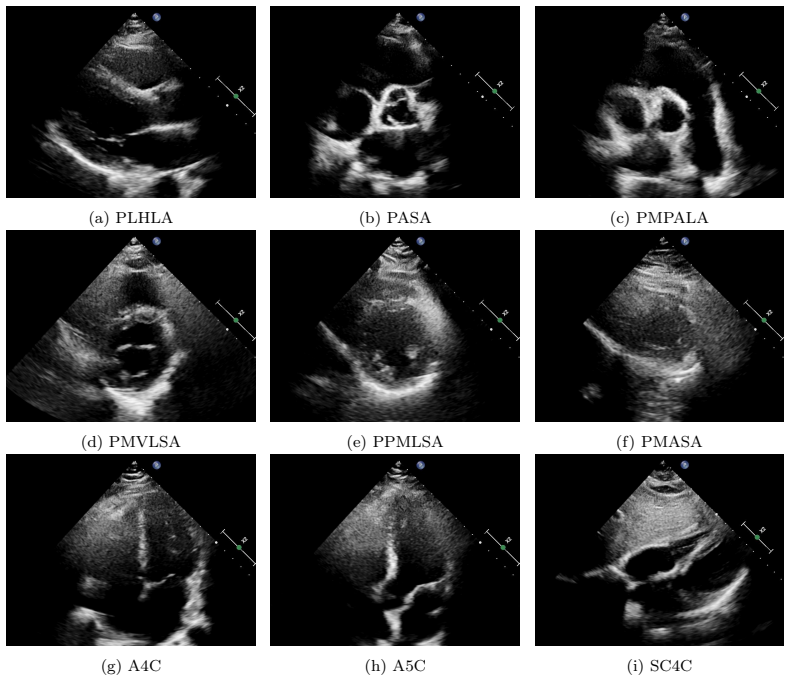
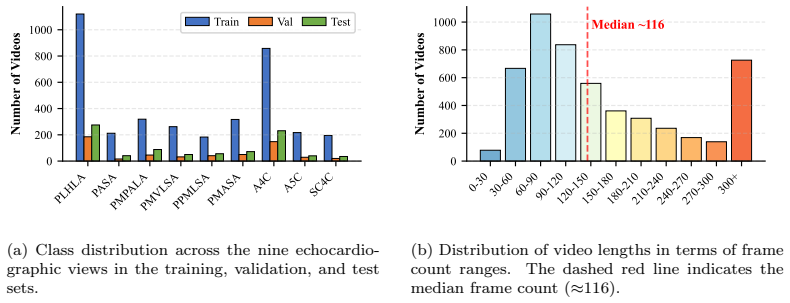
Automated classification of standard echocardiographic views is crucial for efficient clinical workflow but faces three main challenges. First, publicly available datasets are scarce and limited in scale and view coverage. Second, the performance of some modern video-level architectures for echocardiographic view classification remains underexplored. Third, some view categories exhibit highly similar spatial appearances, making single-frame features insufficient for discrimination, while heterogeneous frame quality complicates robust temporal information fusion. To address these challenges, we release the Echocardiographic Videos of Nine Views (EV9V) dataset, comprising 5,138 videos, 910,579 frames, and 9 standard views, which is, to the best of our knowledge, the largest publicly available echocardiography video dataset. Using EV9V, we systematically benchmark representative video classification architectures, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformers. Furthermore, we propose a Spatio-Temporal Fusion Model (STFM), an efficient dual-stream CNN-LSTM (Long Short-Term Memory) framework that jointly captures spatial anatomical structures and temporal cardiac dynamics. The proposed framework leverages uncertainty-aware learning to preferentially sample representative video segments during training and evidence-based fusion during inference, improving robustness to variations in frame quality across echocardiographic videos. Extensive experiments demonstrate that our method achieves competitive performance across diverse video classification models, validating the effectiveness of uncertainty-aware spatio-temporal learning for echocardiographic view classification. The code is available at https://github.com/bgx666/stfm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper releases the EV9V dataset (5,138 videos, 910,579 frames, 9 standard views), benchmarks CNN, RNN, and Transformer video classifiers on it, and proposes STFM, a dual-stream CNN-LSTM that uses uncertainty-aware segment sampling during training and evidence-based fusion at inference to improve robustness to similar spatial appearances and heterogeneous frame quality, claiming competitive performance across models.
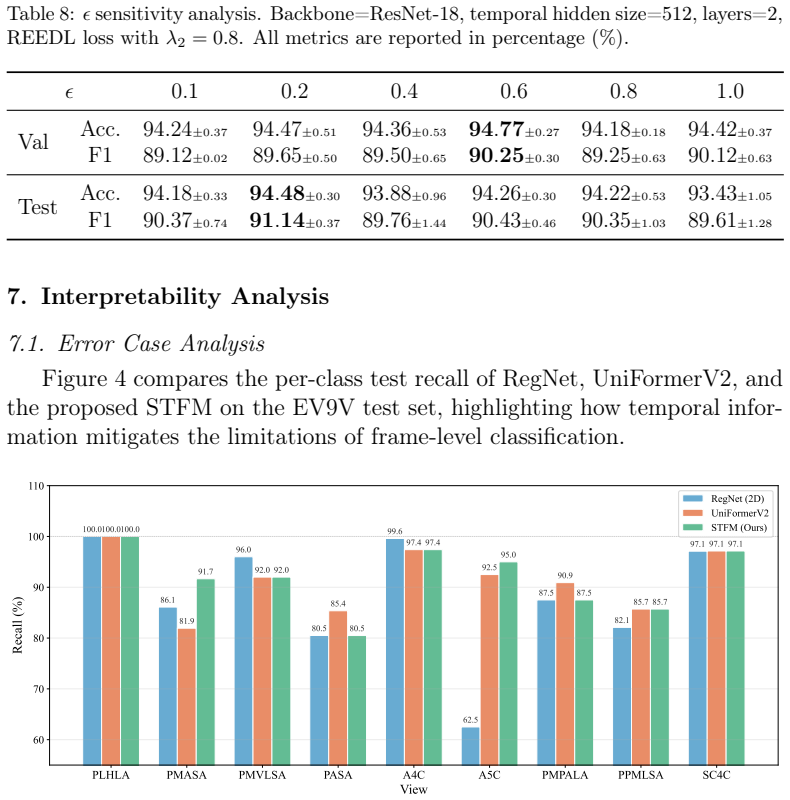
Significance. Release of the largest public echocardiography video dataset would be a clear contribution, enabling systematic benchmarking in a domain where data scarcity has been a bottleneck. If the uncertainty-aware components are shown via controlled experiments to drive the claimed robustness gains beyond the base CNN-LSTM capacity, the STFM framework could offer a practical, efficient approach for clinical view classification; the public code release further strengthens reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that STFM 'achieves competitive performance' and 'validates the effectiveness of uncertainty-aware spatio-temporal learning' is unsupported because the abstract supplies no quantitative metrics, baselines, error bars, or ablation results.
- [Abstract / Experiments] The central attribution of robustness gains to uncertainty-aware sampling and evidence-based fusion (rather than dataset size or standard CNN-LSTM capacity) requires an ablation that removes these two mechanisms while holding the dual-stream architecture and EV9V training data fixed; no such controlled experiment is described.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract would benefit from quantitative support and that a targeted ablation would strengthen attribution of the uncertainty-aware components. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that STFM 'achieves competitive performance' and 'validates the effectiveness of uncertainty-aware spatio-temporal learning' is unsupported because the abstract supplies no quantitative metrics, baselines, error bars, or ablation results.
Authors: We agree. The abstract currently states results qualitatively. In revision we will add concrete metrics (e.g., accuracy/F1 on EV9V), baseline comparisons, and reference to ablation findings to support the claims. revision: yes
-
Referee: [Abstract / Experiments] The central attribution of robustness gains to uncertainty-aware sampling and evidence-based fusion (rather than dataset size or standard CNN-LSTM capacity) requires an ablation that removes these two mechanisms while holding the dual-stream architecture and EV9V training data fixed; no such controlled experiment is described.
Authors: We acknowledge the need for this specific controlled ablation. While the manuscript reports benchmarks of multiple architectures (including dual-stream CNN-LSTM variants) on EV9V, it does not isolate the uncertainty-aware sampling and evidence-based fusion by removing only those components. We will run and report the requested ablation in the revised manuscript. revision: yes
Circularity Check
Empirical dataset and benchmarking paper; no derivation chain present
full rationale
The paper releases the EV9V dataset and benchmarks video classification architectures, proposing an STFM dual-stream CNN-LSTM that incorporates uncertainty-aware sampling and evidence-based fusion. All claims rest on experimental results and end-to-end performance comparisons rather than any mathematical derivation, equation, or theoretical chain. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central performance assertions are externally falsifiable via the released dataset and code, satisfying the criteria for a self-contained empirical result with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CNNs extract useful spatial anatomical features and LSTMs capture cardiac temporal dynamics from echocardiographic videos.
Reference graph
Works this paper leans on
-
[1]
J. P. Barrios, M. U. Ansari, J. E. Olgin, S. Abreau, J. Delfrate, E. L. Langlais, R. Avram, G. H. Tison, Multiview deep learning improves detection of major cardiac conditions from echocardiography, Nature Cardiovascular Research 5 (3) (2026) 234–245
2026
-
[2]
S. K. Zhou, J. H. Park, B. Georgescu, D. Comaniciu, C. Simopoulos, J. Otsuki, Image-based multiclass boosting and echocardiographic view classification, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Vol. 2, 2006, pp. 1559–1565
2006
-
[3]
Khamis, G
H. Khamis, G. Zurakhov, V. Azar, A. Raz, Z. Friedman, D. Adam, Au- tomatic apical view classification of echocardiograms using a discrimi- native learning dictionary, Medical image analysis 36 (2017) 15–21
2017
-
[4]
Kusunose, A
K. Kusunose, A. Haga, M. Inoue, D. Fukuda, H. Yamada, M. Sata, Clinically feasible and accurate view classification of echocardiographic images using deep learning, Biomolecules 10 (5) (2020) 665
2020
-
[5]
Y. Gao, Y. Zhu, B. Liu, Y. Hu, G. Yu, Y. Guo, Automated recognition of ultrasound cardiac views based on deep learning with graph constraint, Diagnostics 11 (7) (2021) 1177
2021
-
[6]
X. Gao, W. Li, M. Loomes, L. Wang, A fused deep learning architecture for viewpoint classification of echocardiography, Information fusion 36 (2017) 103–113
2017
-
[7]
Madani, R
A. Madani, R. Arnaout, M. Mofrad, R. Arnaout, Fast and accurate view classification of echocardiograms using deep learning, NPJ digital medicine 1 (1) (2018) 6
2018
-
[8]
J. P. Howard, J. Tan, M. J. Shun-Shin, D. Mahdi, A. N. Nowbar, A. D. Arnold, Y. Ahmad, P. McCartney, M. Zolgharni, N. W. Linton, et al., 30 Improving ultrasound video classification: an evaluation of novel deep learning methods in echocardiography, Journal of medical artificial in- telligence 3 (2020) 4
2020
-
[9]
Østvik, E
A. Østvik, E. Smistad, S. A. Aase, B. O. Haugen, L. Lovstakken, Real- time standard view classification in transthoracic echocardiography us- ing convolutional neural networks, Ultrasound in medicine & biology 45 (2) (2019) 374–384
2019
-
[10]
Szegedy, V
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethink- ing the inception architecture for computer vision, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2016, pp. 2818–2826
2016
-
[11]
J. A. Naser, E. Lee, S. V. Pislaru, G. Tsaban, J. G. Malins, J. I. Jack- son, D. Anisuzzaman, B. Rostami, F. Lopez-Jimenez, P. A. Friedman, et al., Artificial intelligence-based classification of echocardiographic views, European heart journal-digital health 5 (3) (2024) 260–269
2024
-
[12]
Mohammadi, A
M. Mohammadi, A. Talebpoura, A. Hosseinsabetb, Presenting effective methods in classification of echocardiographic views using deep learning, International journal of engineering, transactions B: applications 37 (11) (2024) 2150–61
2024
-
[13]
Cheng, Z
H. Cheng, Z. Shi, Z. Qi, X. Wang, G. Guo, A. Fang, Z. Jin, C. Shan, R. Chen, Y. Du, et al., Deep learning-based video-level view classifi- cation of two-dimensional transthoracic echocardiography, Biomedical physics & engineering express 11 (2) (2025) 025038
2025
-
[14]
Azarmehr, X
N. Azarmehr, X. Ye, J. P. Howard, E. S. Lane, R. Labs, M. J. Shun-Shin, G. D. Cole, L. Bidaut, D. P. Francis, M. Zolgharni, Neural architecture search of echocardiography view classifiers, Journal of medical imaging 8 (3) (2021) 034002–034002
2021
-
[15]
H. Elmekki, A. Alagha, H. Sami, A. Spilkin, A. M. Zanuttini, E. Zakeri, J. Bentahar, L. Kadem, W.-F. Xie, P. Pibarot, R. Mizouni, H. Otrok, S. Singh, A. Mourad, Cactus: An open dataset and framework for auto- mated cardiac assessment and classification of ultrasound images using deep transfer learning (2025). arXiv:2503.05604. 31
arXiv 2025
-
[16]
D. Tran, L. Bourdev, R. Fergus, L. Torresani, M. Paluri, Learning spa- tiotemporal features with 3d convolutional networks, in: 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 4489– 4497
2015
-
[17]
Carreira, A
J. Carreira, A. Zisserman, Quo vadis, action recognition? a new model and the kinetics dataset, in: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
2017
-
[18]
Simonyan, A
K. Simonyan, A. Zisserman, Two-stream convolutional networks for ac- tion recognition in videos, Advances in neural information processing systems (NeurIPS) 27 (2014)
2014
-
[19]
Simonyan, A
K. Simonyan, A. Zisserman, Very deep convolutional networks for large- scale image recognition, in: Proceedings of the international conference on learning representations (ICLR), 2015
2015
-
[20]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2016, pp. 770–778
2016
-
[21]
Huang, Z
G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely con- nected convolutional networks, in: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition (CVPR), 2017, pp. 4700–4708
2017
-
[22]
Koonce, MobileNetV3, Apress, Berkeley, CA, 2021, pp
B. Koonce, MobileNetV3, Apress, Berkeley, CA, 2021, pp. 125–144
2021
-
[23]
M. Tan, Q. Le, Efficientnet: Rethinking model scaling for convolutional neural networks, in: Proceedings of the International conference on ma- chine learning (ICML), 2019, pp. 6105–6114
2019
-
[24]
M. Tan, Q. Le, Efficientnetv2: Smaller models and faster training, in: Proceedings of the International conference on machine learning (ICML), 2021, pp. 10096–10106
2021
-
[25]
Radosavovic, R
I. Radosavovic, R. P. Kosaraju, R. Girshick, K. He, P. Dollár, Designing network design spaces, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020, pp. 10428– 10436. 32
2020
-
[26]
Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, S. Xie, A con- vnetforthe2020s, in: ProceedingsoftheIEEE/CVFconferenceoncom- puter vision and pattern recognition (CVPR), 2022, pp. 11976–11986
2022
-
[27]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: transformers for image recognition at scale, in: Proceedings of the international conference on learning repre- sentations (ICLR)
-
[28]
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition (CVPR), 2021, pp. 10012–10022
2021
-
[29]
Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, et al., Swin transformer v2: Scaling up capacity and resolution, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2022, pp. 12009–12019
2022
-
[30]
Z. Tu, H. Talebi, H. Zhang, F. Yang, P. Milanfar, A. Bovik, Y. Li, Maxvit: Multi-axis vision transformer, in: Proceedings of the European conference on computer vision (ECCV), 2022, pp. 459–479
2022
-
[31]
L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, L. Van Gool, Temporal segment networks: Towards good practices for deep action recognition, in: European conference on computer vision, Springer, 2016, pp. 20–36
2016
-
[32]
J. Lin, C. Gan, S. Han, Tsm: Temporal shift module for efficient video understanding, in: Proceedings of the IEEE/CVF international confer- ence on computer vision, 2019, pp. 7083–7093
2019
-
[33]
Z. Liu, L. Wang, W. Wu, C. Qian, T. Lu, Tam: Temporal adaptive module for video recognition, in: Proceedings of the IEEE/CVF inter- national conference on computer vision, 2021, pp. 13708–13718
2021
-
[34]
H. Shao, S. Qian, Y. Liu, Temporal interlacing network, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 2020, pp. 11966–11973. 33
2020
-
[35]
D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, M. Paluri, A closer look at spatiotemporal convolutions for action recognition, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (2017) 6450–6459
2018
-
[36]
X. Wang, R. Girshick, A. Gupta, K. He, Non-local neural networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7794–7803
2018
-
[37]
Feichtenhofer, H
C. Feichtenhofer, H. Fan, J. Malik, K. He, Slowfast networks for video recognition, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211
2019
-
[38]
C. Yang, Y. Xu, J. Shi, B. Dai, B. Zhou, Temporal pyramid network for actionrecognition, in: ProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition (CVPR), 2020
2020
-
[39]
Bertasius, H
G. Bertasius, H. Wang, L. Torresani, Is space-time attention all you need for video understanding?, in: Icml, Vol. 2, 2021, p. 4
2021
-
[40]
Li, C.-Y
Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, C. Feicht- enhofer, Mvitv2: Improved multiscale vision transformers for classifi- cation and detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 4804–4814
2022
-
[41]
Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, H. Hu, Video swin transformer, arXiv preprint arXiv:2106.13230 (2021)
arXiv 2021
-
[42]
K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, L. Wang, Y. Qiao, Uniformerv2: Spatiotemporal learning by arming image vits with video uniformer, arXiv preprint arXiv:2211.09552 (2022)
arXiv 2022
-
[43]
S. Kim, P. Jin, S. Song, C. Chen, Y. Li, H. Ren, X. Li, T. Liu, Q. Li, Echofm: Foundation model for generalizable echocardiogram analysis, IEEE transactions on medical imaging (2025)
2025
-
[44]
Mitchell, P
C. Mitchell, P. S. Rahko, L. A. Blauwet, B. Canaday, J. A. Fin- stuen, M. C. Foster, K. Horton, K. O. Ogunyankin, R. A. Palma, E. J. Velazquez, Guidelines for performing a comprehensive transtho- racic echocardiographic examination in adults: recommendations from 34 the american society of echocardiography, Journal of the American So- ciety of Echocardiog...
2019
-
[45]
Leclerc, E
S. Leclerc, E. Smistad, J. Pedrosa, A. Østvik, F. Cervenansky, F. Es- pinosa, T. Espeland, E. A. R. Berg, P.-M. Jodoin, T. Grenier, et al., Deep learning for segmentation using an open large-scale dataset in 2d echocardiography, IEEE transactions on medical imaging 38 (9) (2019) 2198–2210
2019
-
[46]
Huang, G
Z. Huang, G. Long, B. Wessler, M. C. Hughes, Tmed 2: a dataset for semi-supervised classification of echocardiograms, in: DataPerf: Bench- marking Data for Data-Centric AI Workshop, Vol. 5, 2022, p. 15
2022
-
[47]
S.Wen, B.Peng, X.Wei, J.Luo, J.Jiang, Convolutionalneuralnetwork- based speckle tracking for ultrasound strain elastography: An unsu- pervised learning approach, IEEE Transactions on Ultrasonics, Ferro- electrics, and Frequency Control 70 (5) (2023) 354–367
2023
-
[48]
Meunier, M
J. Meunier, M. Bertrand, Echographic image mean gray level changes with tissue dynamics: a system-based model study, IEEE Transactions on Biomedical Engineering 42 (4) (2002) 403–410
2002
-
[49]
M. Chen, J. Gao, C. Xu, Revisiting essential and nonessential settings of evidential deep learning, IEEE Transactions on Pattern Analysis and Machine Intelligence 47 (10) (2025) 8658–8673
2025
-
[50]
Contributors, Openmmlab’s next generation video understand- ing toolbox and benchmark,https://github.com/open-mmlab/ mmaction2(2020)
M. Contributors, Openmmlab’s next generation video understand- ing toolbox and benchmark,https://github.com/open-mmlab/ mmaction2(2020). 35
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.