WeaveLA: Event Driven Cross-Subtask Latent Memory Weaving for Repetitive Robot Manipulation
Pith reviewed 2026-06-27 02:01 UTC · model grok-4.3
The pith
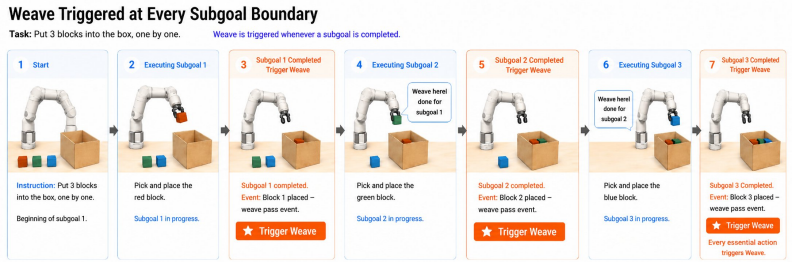
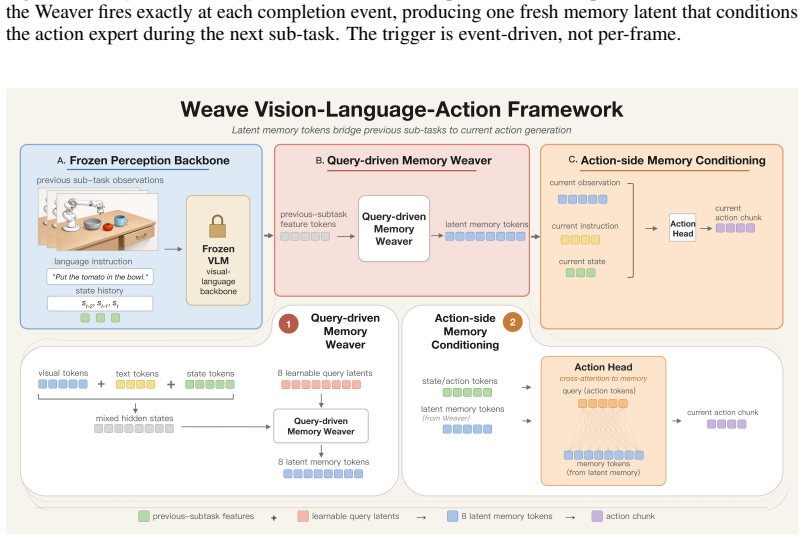
WeaveLA adds an event-triggered latent memory channel to frozen VLA policies that compresses each completed sub-task segment into tokens and routes them directly into the next sub-task's action expert.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
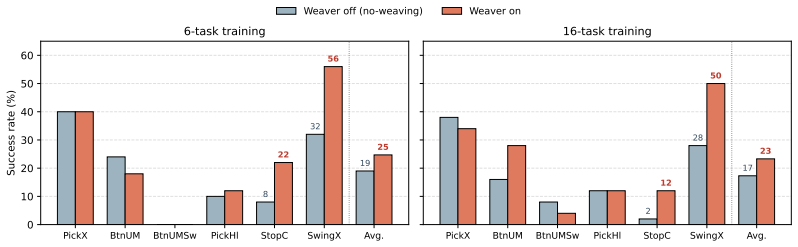
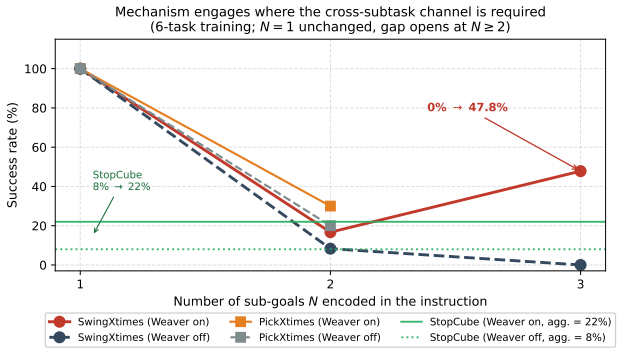
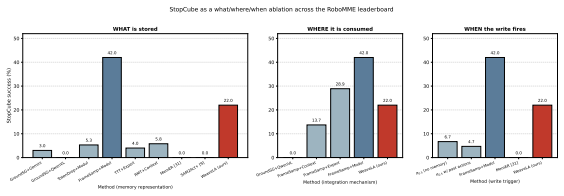
WeaveLA is a cross-subtask memory interface that, on top of a frozen VLA backbone, compresses each completed segment into latent tokens via query-driven attention pooling and routes them directly into the action-generation path of the next sub-task. This event-triggered, action-side design preserves the base policy's short-window interface while adding a lightweight cross-subtask channel. Through stratified evaluation on RoboMME with a π0.5 backbone, success on the hardest repetition slice (SwingXtimes, N=3) rises from 0% to 47.8%, while single-execution episodes remain unchanged. Per-episode paired analysis confirms the gains are confined to tasks whose causal structure requires cross-subta
What carries the argument
The event-triggered cross-subtask memory interface that uses query-driven attention pooling to produce latent tokens for hand-off into the action expert of the subsequent sub-task.
If this is right
- Success rates rise on the hardest repetition tasks while single-execution tasks stay the same.
- Gains appear only on tasks whose causal structure requires cross-subtask information.
- The base policy's short-window interface and overall behavior on non-repetitive episodes are preserved.
- The added channel remains lightweight because it activates only at sub-goal events rather than every frame.
Where Pith is reading between the lines
- The same event-triggered hand-off pattern could be tested on sequential tasks outside robot manipulation where prior-step information must reach later actions.
- Replacing the query-driven pooling with other compression methods would isolate whether the attention mechanism itself is load-bearing.
- Placing the memory tokens on the observation side instead of the action side could be compared to measure the effect of routing choice.
Load-bearing premise
The sub-goal completion event is the natural temporal unit for cross-subtask memory hand-off and the latent tokens it produces are useful when fed into the action expert of the next sub-task.
What would settle it
Adding the memory-weaving channel would leave success rates on repetition-heavy tasks such as SwingXtimes N=3 unchanged or would degrade performance on single-execution episodes.
Figures


read the original abstract
Vision-Language-Action (VLA) policies have achieved remarkable single-step manipulation, yet they remain brittle precisely where each stage depends on what was just completed. The core issue is structural: short-window VLAs lack an explicit channel for rouxting information across sub-task boundaries, and existing memory-augmented variants either write at every frame, retrieve from demonstration-time stages, or fire at sub-goal events without performing an explicit sub-task-to-sub-task hand-off into the action expert. We identify the sub-goal completion event as the natural temporal unit for cross-subtask memory hand-off, and present WeaveLA (Weave Latent memory for Vision-Language-Action policies), a cross-subtask memory interface that, on top of a frozen VLA backbone, compresses each completed segment into latent tokens via query-driven attention pooling and routes them directly into the action-generation path of the next sub-task. This event-triggered, action-side design preserves the base policy's short-window interface while adding a lightweight cross-subtask channel. Through stratified evaluation on RoboMME with a $\pi_{0.5}$ backbone, WeaveLA's gains land exactly where the channel is needed: on the hardest repetition slice (SwingXtimes, $N{=}3$), success rises from $0\%$ to $47.8\%$, while single-execution episodes remain unchanged. Per-episode paired analysis confirms the gains are confined to tasks whose causal structure requires cross-subtask information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WeaveLA, an event-driven cross-subtask latent memory interface for frozen VLA backbones. Sub-goal completion events trigger query-driven attention pooling to compress completed segments into latent tokens that are routed directly into the action expert of the subsequent sub-task. On the RoboMME benchmark with a π0.5 backbone, the method reports large gains precisely on the hardest repetition slice (SwingXtimes, N=3: 0% → 47.8% success) while leaving single-execution episodes unchanged; per-episode analysis is used to argue that improvements are confined to tasks whose causal structure requires cross-subtask information.
Significance. If the central result holds, the work supplies a lightweight, action-side memory channel that preserves the short-window interface of existing VLAs while addressing brittleness at sub-task boundaries. The stratified evaluation design and the claim that gains appear only where cross-subtask state is required constitute a falsifiable prediction that strengthens the contribution. The approach is compatible with frozen backbones, which is practically relevant.
major comments (3)
- [Experiments section] Experiments section (stratified evaluation on RoboMME): the headline 0%→47.8% lift on SwingXtimes (N=3) is attributed to the event-triggered hand-off of query-driven pooled latents, yet no ablation keeps the sub-goal event trigger and routing fixed while replacing the pooled tokens with uninformative content (zero vectors, random vectors, or tokens from a different operator). Without this control, the observed gain cannot be credited specifically to the cross-subtask channel rather than to the mere presence of an event-driven interface.
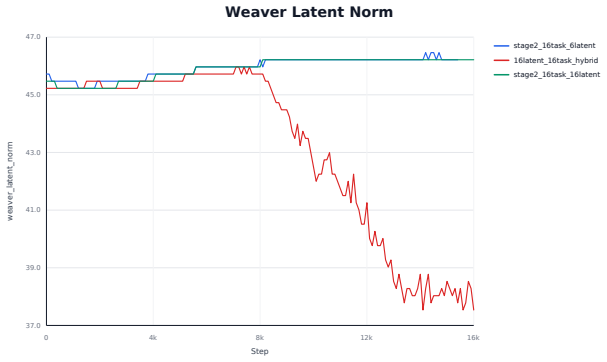
- [Methods] Methods, query-driven attention pooling paragraph: the description states that each completed segment is compressed into latent tokens via query-driven attention pooling and routed into the action-generation path, but does not specify how the queries are constructed (learned parameters, fixed templates, or derived from the VLA's own embeddings) or whether the pooling operator is trained. This detail is load-bearing for the claim that the tokens carry usable cross-subtask state into the frozen π0.5 action expert.
- [Experiments section] Evaluation protocol: success rates are reported without error bars, number of evaluation seeds, or statistical tests. Given that the central claim rests on a large relative improvement on a single slice (SwingXtimes N=3), the absence of these quantities makes it impossible to assess whether the reported 47.8% is robust or could be explained by evaluation variance.
minor comments (2)
- [Abstract] The abstract and introduction use the non-standard spelling 'rouxting'; this should be corrected to 'routing'.
- [Throughout] Notation for the backbone is written as both π0.5 and π_{0.5}; adopt a single consistent form throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that directly strengthen the experimental controls and reporting.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (stratified evaluation on RoboMME): the headline 0%→47.8% lift on SwingXtimes (N=3) is attributed to the event-triggered hand-off of query-driven pooled latents, yet no ablation keeps the sub-goal event trigger and routing fixed while replacing the pooled tokens with uninformative content (zero vectors, random vectors, or tokens from a different operator). Without this control, the observed gain cannot be credited specifically to the cross-subtask channel rather than to the mere presence of an event-driven interface.
Authors: We agree that the current experiments lack a control that isolates the informational content of the pooled latents. We will add an ablation that retains the sub-goal event trigger and routing mechanism but substitutes the pooled tokens with zero vectors (and separately with random vectors) and report the resulting success rates on the SwingXtimes (N=3) slice. revision: yes
-
Referee: [Methods] Methods, query-driven attention pooling paragraph: the description states that each completed segment is compressed into latent tokens via query-driven attention pooling and routed into the action-generation path, but does not specify how the queries are constructed (learned parameters, fixed templates, or derived from the VLA's own embeddings) or whether the pooling operator is trained. This detail is load-bearing for the claim that the tokens carry usable cross-subtask state into the frozen π0.5 action expert.
Authors: The queries are implemented as learned parameters and the pooling operator is trained end-to-end as part of the interface. We will revise the methods paragraph to explicitly state the query construction (learned parameters initialized from VLA embeddings) and confirm that the pooling operator is trained while the backbone remains frozen. revision: yes
-
Referee: [Experiments section] Evaluation protocol: success rates are reported without error bars, number of evaluation seeds, or statistical tests. Given that the central claim rests on a large relative improvement on a single slice (SwingXtimes N=3), the absence of these quantities makes it impossible to assess whether the reported 47.8% is robust or could be explained by evaluation variance.
Authors: We acknowledge that variability measures are required for the central claim. We will re-run the key evaluations over multiple random seeds, add error bars to all reported success rates, and include statistical tests comparing WeaveLA against the baseline on the repetition slices. revision: yes
Circularity Check
No significant circularity; additive interface with external empirical validation
full rationale
The paper describes WeaveLA as a new event-triggered memory interface added to a frozen π0.5 VLA backbone, using query-driven attention pooling to produce latent tokens routed to subsequent sub-tasks. Claims rest on stratified benchmark results (e.g., 0% to 47.8% on SwingXtimes N=3) rather than any derivation, equation, or self-citation that reduces the reported gains to quantities defined by the method itself. No load-bearing steps reduce by construction to fitted inputs or author prior work; the architecture is presented as an independent additive channel whose utility is assessed on external tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization, 2016.arXiv preprint arXiv:1607.06450
Pith/arXiv arXiv 2016
-
[2]
Bacon, J
P.-L. Bacon, J. Harb, and D. Precup. The option-critic architecture. InAAAI, 2017
2017
-
[3]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, et al. PaliGemma: A versatile 3B VLM for transfer, 2024.arXiv preprint arXiv:2407.07726
Pith/arXiv arXiv 2024
-
[4]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, et al. π0: A vision-language-action flow model for general robot control, 2024
2024
-
[5]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control, 2023
2023
-
[6]
Bulatov, Y
A. Bulatov, Y . Kuratov, and M. S. Burtsev. Recurrent memory transformer, 2022
2022
-
[7]
M. Sobol Mark, J. Liang, M. Attarian, C. Fu, D. Dwibedi, D. Shah, and A. Kumar. BPP: Long-context robot imitation learning by focusing on key history frames, 2026.arXiv preprint arXiv:2602.15010
arXiv 2026
-
[8]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. RoboMME: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[9]
Dwibedi, Y
D. Dwibedi, Y . Aytar, J. Tompson, P. Sermanet, and A. Zisserman. Counting out time: Class-agnostic video repetition counting in the wild, 2020
2020
-
[10]
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan. SAM2Act: Integrating visual foundation model with a memory architecture for robotic manipulation, 2025
2025
-
[11]
Gemma: Open models based on Gemini research and technology, 2024a.arXiv preprint arXiv:2403.08295
Gemma Team. Gemma: Open models based on Gemini research and technology, 2024a.arXiv preprint arXiv:2403.08295
-
[12]
Gemma 2: Improving open language models at a practical size, 2024b.arXiv preprint arXiv:2408.00118
Gemma Team. Gemma 2: Improving open language models at a practical size, 2024b.arXiv preprint arXiv:2408.00118
-
[13]
S. Han, B. Qiu, Y . Liao, S. Huang, C. Gao, S. Yan, and S. Liu. RoboCerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation, 2025
2025
-
[14]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, et al. LoRA: Low-rank adaptation of large language models, 2022
2022
-
[15]
H. Hu, S. Dong, Y . Zhao, D. Lian, Z. Li, and S. Gao. TransRAC: Encoding multi-scale temporal correlation with transformers for repetitive action counting, 2022
2022
-
[16]
H. Jang, S. Yu, H. Kwon, H. Jeon, Y . Seo, and J. Shin. ContextVLA: Vision-language-action model with amortized multi-frame context, 2025
2025
-
[17]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, et al. OpenVLA: An open-source vision-language-action model, 2024
2024
-
[18]
T. Kipf, Y . Li, H. Dai, V . Zambaldi, A. Sanchez-Gonzalez, E. Grefenstette, P. Kohli, and P. Battaglia. CompILE: Compositional imitation learning and execution. InICML, 2019
2019
-
[19]
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. HAMLET: Switch your vision-language- action model into a history-aware policy, 2025.arXiv preprint arXiv:2510.00695
Pith/arXiv arXiv 2025
-
[20]
H. Li, F. Shen, D. Chen, L. Yang, X. Wang, J. Shi, Z. Bing, Z. Liu, and A. Knoll. ReMem-VLA: Empowering vision-language-action model with memory via dual-level recurrent queries, 2026.arXiv preprint arXiv:2603.12942. 10
arXiv 2026
-
[21]
J. Li, D. Li, S. Savarese, and S. Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023
2023
-
[22]
R. Li, W. Guo, Z. Wu, C. Wang, H. Deng, Z. Weng, Y .-P. Tan, and Z. Wang. MAP-VLA: Memory- augmented prompting for vision-language-action model in robotic manipulation, 2025.arXiv preprint arXiv:2511.09516
arXiv 2025
-
[23]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2022
2022
-
[24]
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, et al. Long-VLA: Unleashing long-horizon capability of vision-language-action model for robot manipulation. InCoRL, 2025
2025
-
[25]
Bjorck, F
NVIDIA, J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, et al. GR00T N1: An open foundation model for generalist humanoid robots, 2025
2025
-
[26]
GR00T N1.6: An improved open foundation model for generalist humanoid robots
NVIDIA GEAR Team. GR00T N1.6: An improved open foundation model for generalist humanoid robots. https://research.nvidia.com/labs/gear/gr00t-n1_6, 2025
2025
-
[27]
Paiss, A
R. Paiss, A. Ephrat, O. Tov, S. Zada, I. Mosseri, M. Irani, and T. Dekel. Teaching CLIP to count to ten, 2023
2023
-
[28]
Z. Liu, Y . Wang, S. Zheng, T. Pan, L. Liang, Y . Fu, and X. Xue. ReasonGrounder: LVLM-guided hierarchical feature splatting for open-vocabulary 3D visual grounding and reasoning. InCVPR, 2025a
-
[29]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, et al. π0.5: A vision-language-action model with open-world generalization, 2025
2025
-
[30]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, et al. MemoryVLA: Perceptual-cognitive memory in vision- language-action models for robotic manipulation, 2025
2025
-
[31]
Sinha, A
S. Sinha, A. Stergiou, and D. Damen. Every shot counts: Using exemplars for repetition counting in videos. InACCV, 2024
2024
-
[32]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. MemER: Scaling up memory for robot control via experience retrieval, 2025.arXiv preprint arXiv:2510.20328
arXiv 2025
-
[33]
J. Su, A. Murtadha, Y . Lu, S. Pan, Wen. Bo, and Y . Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[34]
Z. Liu, S. Zheng, S. Chen, C. Zhao, L. Liang, X. Xue, and Y . Fu. A neural representation framework with LLM-driven spatial reasoning for open-vocabulary 3D visual grounding. InACM MM, 2025b
-
[35]
R. S. Sutton, D. Precup, and S. Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2):181–211, 1999
1999
-
[36]
Torne, K
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, et al. MEM: Multi-scale embodied memory for vision language action models, 2026
2026
-
[37]
Toro Icarte, T
R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith. Using reward machines for high-level task specification and decomposition in reinforcement learning. InICML, 2018
2018
-
[38]
Vaezipoor, A
P. Vaezipoor, A. C. Li, R. Toro Icarte, and S. A. McIlraith. LTL2Action: Generalizing LTL instructions for multi-task RL. InICML, 2021
2021
-
[39]
Z. Liu, Y . Wang, K. Wang, L. Liang, X. Xue, and Y . Fu. Spatial-temporal aware visuomotor diffusion policy learning. InICCV, 2025c
-
[40]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[41]
X. Guo, Z. Huang, Z. Shi, Z. Song, and J. Zhang. Your vision-language model can’t even count to 20: Exposing the failures of VLMs in compositional counting, 2025.arXiv preprint arXiv:2510.04401
arXiv 2025
-
[42]
Zhang, Y
J. Zhang, Y . Guo, X. Chen, Y .-J. Wang, Y . Hu, C. Shi, and J. Chen. HiRT: Enhancing robotic control with hierarchical robot transformers. InCoRL, 2024
2024
-
[43]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daumé III, A. Kolobov, F. Huang, and J. Yang. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies, 2024. 11
2024
-
[44]
Z. Liu, Y . Gu, S. Zheng, Y . Fu, X. Xue and Y . Jiang. TriVLA: A triple-system-based unified vision- language-action model for general robot control, 2025d.arXiv preprint arXiv:2507.01424
-
[45]
Z. Liu, Y . Gu, Y . Wang, X. Xue, and Y . Fu. ActiveVLA: Injecting active perception into vision-language- action models for precise 3D robotic manipulation, 2026.arXiv preprint arXiv:2601.08325
arXiv 2026
- [46]
-
[47]
Zhang and R
B. Zhang and R. Sennrich. Root mean square layer normalization. InNeurIPS, 2019
2019
-
[48]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023a
-
[49]
Y . Chen, W. Tan, L. Zhu, F. Li, J. Li, G. Yang, and H. T. Shen. Non-Markovian long-horizon robot manipulation via keyframe chaining, 2026.arXiv preprint arXiv:2603.01465
arXiv 2026
-
[50]
H. Wu, T. Chen, J. Wang, X. Li, and L. Fang. StreamVLA: Breaking the reason-act cycle via completion- state gating, 2026.arXiv preprint arXiv:2602.01100
arXiv 2026
-
[51]
R. Yang, Z. An, L. Zhou, and Y . Feng. SeqVLA: Sequential task execution for long-horizon manipulation with completion-aware vision-language-action model, 2025.arXiv preprint arXiv:2509.14138
arXiv 2025
-
[52]
W. Wan, Y . Zhu, R. Shah, and Y . Zhu. LOTUS: Continual imitation learning for robot manipulation through unsupervised skill discovery. InICRA, 2024
2024
-
[53]
Weaver off (no-weaving baseline)
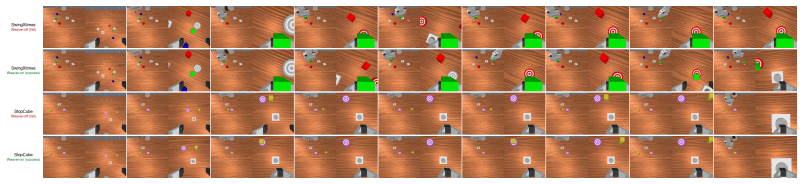
Y . Zhu, P. Stone, and Y . Zhu. Bottom-up skill discovery from unsegmented demonstrations for long-horizon robot manipulation.IEEE Robotics and Automation Letters, 2022. A Technical Appendices and Supplementary Material A.1 Full 16-Task RoboMME Breakdown Table 2: Full RoboMME 16-task success rates (↑, %, 50 episodes per task) for the four π0.5+AP con- fig...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.