MambaCount: Efficient Text-guided Open-vocabulary Object Counting with Spatial Sparse State Space Duality Block
Pith reviewed 2026-06-27 01:49 UTC · model grok-4.3
The pith
MambaCount reaches 12.23 MAE on text-guided object counting while keeping linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
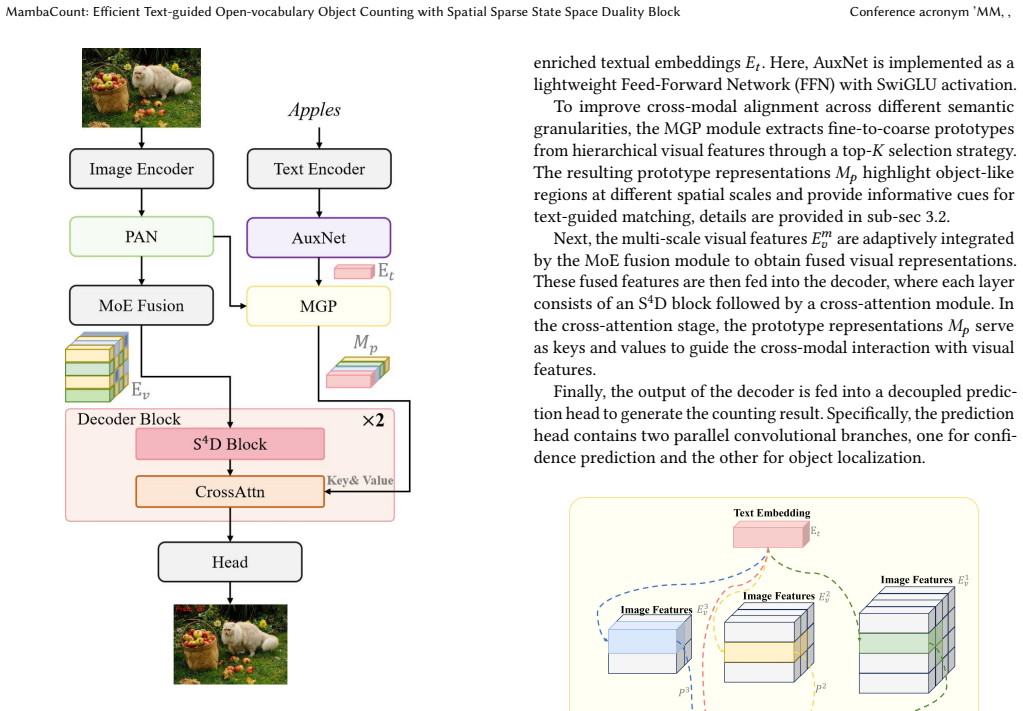
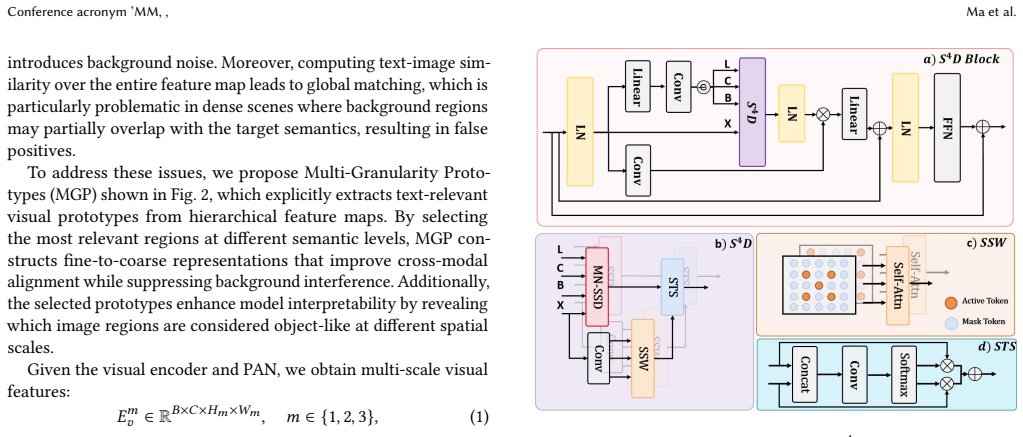
The central claim is that the Spatial Sparse State Space Duality block enables Mamba to model bidirectional spatial dependencies for non-causal vision tasks by reconstructing hidden state decay dynamics, while the Spatial Token Selection sub-block reduces high entropy in responses to preserve local details. Combined with Multi-Granularity Prototypes for semantic alignment, this framework delivers state-of-the-art results on the FSC-147 benchmark for text-guided counting without requiring secondary queries, all at linear computational complexity.
What carries the argument
The Spatial Sparse State Space Duality (S^4D) block, which reconstructs Mamba hidden-state decay dynamics and adds token selection to support bidirectional spatial modeling with lower entropy.
If this is right
- Delivers a test mean absolute error of 12.23 on FSC-147 among methods that avoid secondary querying.
- Maintains linear complexity scaling with image resolution instead of quadratic.
- Handles dense scenes and large object-scale variations through multi-granularity prototypes.
- Improves cross-modal alignment and interpretability without added query overhead.
Where Pith is reading between the lines
- The same block changes could apply to other dense-prediction tasks that need full spatial context, such as segmentation.
- Linear scaling opens the possibility of real-time counting on higher-resolution inputs that current quadratic models cannot handle.
- The token-selection step may transfer to other state-space vision models to control response entropy.
Load-bearing premise
Reconstructing the decay dynamics of hidden states in Mamba is enough to remove the causal dependency constraints for non-causal vision tasks.
What would settle it
Measure the test MAE on FSC-147 after removing only the decay-dynamics reconstruction; if performance falls back to levels of unmodified causal Mamba methods, the central fix does not hold.
Figures

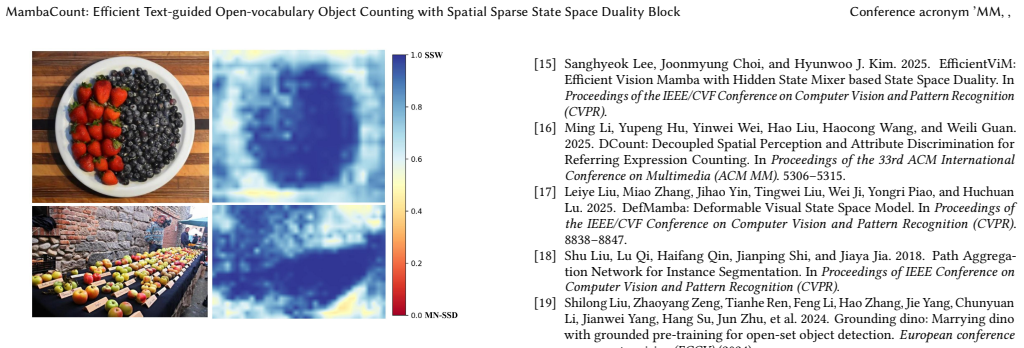
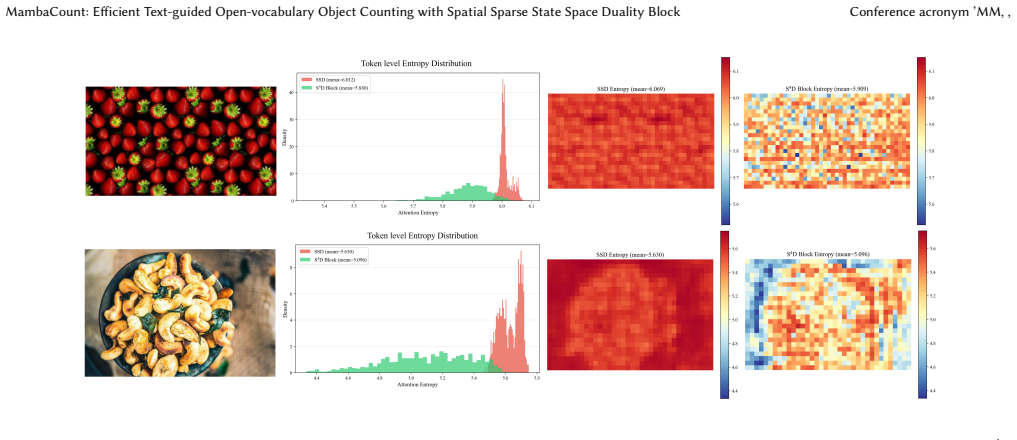
read the original abstract
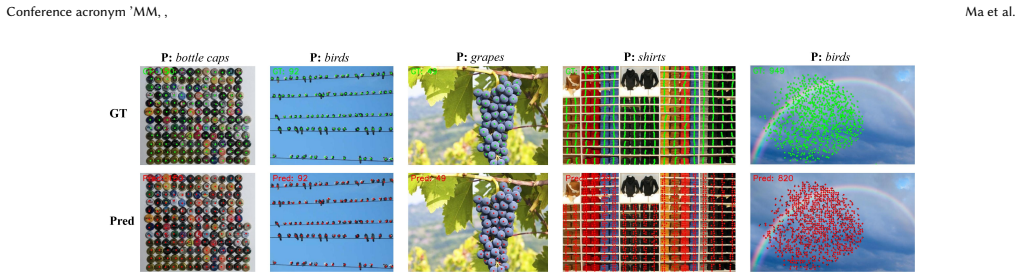
Text-guided Open-vocabulary Object Counting (TOOC) aims to estimate the number of objects described by text prompts, which is particularly challenging in dense scenes with large scale variations. Existing TOOC approaches predominantly rely on Transformers, whose quadratic complexity with respect to image resolution limits their scalability. Mamba offers a promising alternative due to its linear complexity. However, previous Mamba-based methods have two main limitations. On the one hand, the inherent causal formulation of Mamba constrains the bidirectional spatial dependency modeling required by non-causal vision tasks. On the other hand, existing Mamba-based vision models often overlook the unconstrained high entropy in the spatial token responses, which can weaken local details and high-frequency cues. To address these limitations, we propose MambaCount, an efficient framework built on the Spatial Sparse State Space Duality (S^4D) block. Specifically, we analyze and reconstruct the decay dynamics of hidden states in Mamba to alleviate the dependency constraints introduced by causal modeling. Moreover, we introduce a Spatial Token Selection (STS) sub-block to reduce the unconstrained high entropy in spatial token responses within Mamba. In addition, we design Multi-Granularity Prototypes (MGP) to identify object-like regions at different semantic levels, improving cross-modal alignment and interpretability. Extensive experiments on FSC-147 demonstrate that MambaCount achieves state-of-the-art performance among methods without secondary querying, obtaining a test MAE of 12.23, while retaining linear complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MambaCount for text-guided open-vocabulary object counting (TOOC). It identifies quadratic complexity in Transformers and causal constraints plus high-entropy spatial tokens in prior Mamba vision models as key limitations. The proposed Spatial Sparse State Space Duality (S^4D) block reconstructs hidden-state decay dynamics to enable bidirectional spatial modeling, augmented by a Spatial Token Selection (STS) sub-block for entropy reduction and Multi-Granularity Prototypes (MGP) for cross-modal alignment. On FSC-147 it reports SOTA MAE of 12.23 among no-secondary-query methods while preserving linear complexity.
Significance. If the S^4D adaptation is shown to deliver true bidirectional context at linear cost, the work would offer a scalable alternative to Transformer-based dense prediction models and could influence state-space approaches in other non-causal vision tasks. The MGP component adds potential interpretability value. The linear-complexity claim and the specific MAE number are the primary contributions that would need to be substantiated.
major comments (2)
- [Abstract] Abstract: The claim that reconstructing decay dynamics 'alleviate[s] the dependency constraints introduced by causal modeling' is load-bearing for the central contribution, yet the manuscript provides no equations, derivation, or empirical check (e.g., dependency range or receptive-field measurement) demonstrating that the modified dynamics actually permit full bidirectional context without reintroducing quadratic cost or losing selectivity. The STS sub-block is presented separately, so performance gains cannot yet be attributed to the core adaptation.
- [Abstract] Abstract: The precise test MAE of 12.23 and SOTA status are asserted without any experimental protocol, baseline list, error bars, dataset splits, or implementation details. This absence prevents assessment of whether the reported figure supports the claim that the S^4D block enables the result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that reconstructing decay dynamics 'alleviate[s] the dependency constraints introduced by causal modeling' is load-bearing for the central contribution, yet the manuscript provides no equations, derivation, or empirical check (e.g., dependency range or receptive-field measurement) demonstrating that the modified dynamics actually permit full bidirectional context without reintroducing quadratic cost or losing selectivity. The STS sub-block is presented separately, so performance gains cannot yet be attributed to the core adaptation.
Authors: The manuscript analyzes and reconstructs the decay dynamics in Section 3.2 with the corresponding equations and derivation showing how the modified hidden-state formulation removes the strict causal constraint while preserving linear complexity and selectivity. We agree an explicit empirical check (e.g., receptive-field or dependency-range measurement) is not yet present and will add one in the revision. Ablation results in Section 4.3 already separate the contribution of the S^4D core from the STS sub-block. revision: partial
-
Referee: [Abstract] Abstract: The precise test MAE of 12.23 and SOTA status are asserted without any experimental protocol, baseline list, error bars, dataset splits, or implementation details. This absence prevents assessment of whether the reported figure supports the claim that the S^4D block enables the result.
Authors: Full experimental protocol, FSC-147 splits, baseline list (Table 1), error bars, and implementation details appear in Section 4. The reported 12.23 is the test MAE under the no-secondary-query protocol. Abstracts conventionally summarize results; the supporting details are already in the body. No change to the manuscript is required on this point. revision: no
Circularity Check
No circularity: performance claim is empirical, not derived by construction
full rationale
The paper identifies two limitations of prior Mamba vision models (causal constraints and high entropy), then proposes the S^4D block via analysis/reconstruction of decay dynamics plus STS and MGP sub-components. The reported test MAE of 12.23 on FSC-147 is presented strictly as an experimental outcome among no-secondary-query methods, with linear complexity retained. No equations, parameters, or claims reduce to fitted inputs renamed as predictions, self-citations that bear the central load, or ansatzes imported from the authors' prior work. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Spatial Sparse State Space Duality (S^4D) block
no independent evidence
-
Spatial Token Selection (STS) sub-block
no independent evidence
-
Multi-Granularity Prototypes (MGP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amini-Naieni, K
N. Amini-Naieni, K. Amini-Naieni, T. Han, and A. Zisserman. 2023. Open-world Text-specified Object Counting. InBritish Machine Vision Conference (BMCV)
2023
-
[2]
Amini-Naieni, T
N. Amini-Naieni, T. Han, and A. Zisserman. 2024. CountGD: Multi-Modal Open- World Counting. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[3]
Kang Hao Cheong, Sandra Poeschmann, Joel Weijia Lai, Jin Ming Koh, U Rajendra Acharya, Simon Ching Man Yu, and Kenneth Jian Wei Tang. 2019. Practical automated video analytics for crowd monitoring and counting.IEEE access7 (2019), 183252–183261
2019
-
[4]
Siyang Dai, Jun Liu, and Ngai-Man Cheung. 2024. Referring Expression Count- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[5]
Tri Dao and Albert Gu. 2024. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. InInternational Conference on Machine Learning (ICML)
2024
-
[6]
Albert Gu and Tri Dao. 2023. Mamba: Linear-Time Sequence Modeling with Selective State Spaces.arXiv preprint arXiv:2312.00752(2023)
Pith/arXiv arXiv 2023
-
[7]
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, and Gao Huang. 2024. Demystify mamba in vision: A linear attention perspective.Advances in Neural Information Processing Systems (NeurIPS)37 (2024), 127181–127203
2024
-
[8]
Meng-Ru Hsieh, Yen-Liang Lin, and Winston H Hsu. 2017. Drone-based object counting by spatially regularized regional proposal network. InProceedings of the IEEE international conference on computer vision (ICCV)
2017
-
[9]
Ruixiang Jiang, Lingbo Liu, and Changwen Chen. 2023. CLIP-Count: Towards Text-Guided Zero-Shot Object Counting.arXiv preprint arXiv:2305.07304(2023)
arXiv 2023
-
[10]
Seunggu Kang, WonJun Moon, Euiyeon Kim, and Jae-Pil Heo. 2024. VLCounter: Text-Aware Visual Representation for Zero-Shot Object Counting. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2024
-
[11]
Rahima Khanam and Muhammad Hussain. 2024. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv:2410.17725
Pith/arXiv arXiv 2024
-
[12]
Kingma and Jimmy Lei Ba
Diederik P. Kingma and Jimmy Lei Ba. 2015. Adam: A Method for Stochastic Optimization. InProceedings of the International Conference on Learning Repre- sentations (ICLR)
2015
-
[13]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al
-
[14]
InProceedings of the IEEE/CVF international conference on computer vision (CVPR)
Segment anything. InProceedings of the IEEE/CVF international conference on computer vision (CVPR). 4015–4026
-
[15]
Harold W Kuhn. 1955. The Hungarian Method for the Assignment Problem. Naval research logistics quarterly2, 1-2 (1955), 83–97
1955
-
[16]
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J. Kim. 2025. EfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[17]
Ming Li, Yupeng Hu, Yinwei Wei, Hao Liu, Haocong Wang, and Weili Guan
-
[18]
InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM)
DCount: Decoupled Spatial Perception and Attribute Discrimination for Referring Expression Counting. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). 5306–5315
-
[19]
Leiye Liu, Miao Zhang, Jihao Yin, Tingwei Liu, Wei Ji, Yongri Piao, and Huchuan Lu. 2025. DefMamba: Deformable Visual State Space Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 8838–8847
2025
-
[20]
Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. 2018. Path Aggrega- tion Network for Instance Segmentation. InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[21]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. 2024. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.European conference on computer vision (ECCV)(2024)
2024
-
[22]
Shuai Liu, Peng Zhang, Shiwei Zhang, and Wei Ke. 2025. CountSE: Soft Exemplar Open-set Object Counting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 21536–21546
2025
-
[23]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. 2024. VMamba: Visual State Space Model. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems NeurIPS
2024
-
[24]
Hao-Yuan Ma and Li Zhang. 2024. Multi-head multi-scale pixel localization network for crowd counting with highly dense and small-scale samples. In2024 IEEE International Conference on Multimedia and Expo (ICME). 1–5
2024
-
[25]
Hao-Yuan Ma, Li Zhang, and Minjie Qiang. 2026. OVID: Text-Guided Open- Vocabulary Dense Object Counting and Localization.IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP)(2026)
2026
-
[26]
Hao-Yuan Ma, Li Zhang, and Shuai Shi. 2024. VMambaCC: A Visual State Space Model for Crowd Counting.arXiv preprint arXiv:2405.03978(2024)
arXiv 2024
-
[27]
Hao-Yuan Ma, Li Zhang, and Xiang-Yi Wei. 2024. FGENet: Fine-Grained Ex- traction Network for Congested Crowd Counting. InProceedings of the 30th International Conference on Multimedia Modeling (MMM)
2024
-
[28]
Cinthya Vanessa Muñoz Macas, Jorge Andrés Espinoza Aguirre, Rodrigo Arcentales-Carrión, and Mario Peña. 2021. Inventory management for retail companies: A literature review and current trends. In2021 second international conference on information systems and software technologies (ICISST). IEEE, 71–78
2021
-
[29]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning (ICME). 8748–8763
2021
-
[30]
Viresh Ranjan, Udbhav Sharma, Thu Nguyen, and Minh Hoai. 2021. Learning to count everything. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3394–3403
2021
-
[31]
Yuheng Shi, Minjing Dong, Mingjia Li, and Chang Xu. 2025. VSSD: Vision Mamba with Non-Causal State Space Duality.Proceedings of the IEEE international conference on computer vision (ICCV)(2025)
2025
-
[32]
Ziqiang Shi, Rujie Liu, Jun Takahashi, and Shan Jiang. 2025. TrueCount: Improv- ing Open-World Object Counting with Visual-Language Models and Dynamic Multi-Modal Inputs. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). 1764–1773
2025
-
[33]
Qingyu Song, Changan Wang, Zhengkai Jiang, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yang Wu. 2021. Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 3365–3374
2021
-
[34]
Colin J Torney, David J Lloyd-Jones, Mark Chevallier, David C Moyer, Honori T Maliti, Machoke Mwita, Edward M Kohi, and Grant C Hopcraft. 2019. A com- parison of deep learning and citizen science techniques for counting wildlife in aerial survey images.Methods in Ecology and Evolution10, 6 (2019), 779–787
2019
-
[35]
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vem- ulapalli, and Oncel Tuzel. 2024. MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems (NeurIPS)30 (2017)
2017
-
[37]
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. 2025. YOLOE: Real-Time Seeing Anything. arXiv:2503.07465
arXiv 2025
-
[38]
Zhicheng Wang, Zhiyu Pan, Zhan Peng, Jian Cheng, Liwen Xiao, Wei Jiang, and Zhiguo Cao. 2025. Exploring Contextual Attribute Density in Referring Expression Counting
2025
-
[39]
Jingyi Xu, Hieu Le, Vu Nguyen, Viresh Ranjan, and Dimitris Samaras. 2023. Zero- Shot Object Counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 15548–15557. Conference acronym ’MM, , Ma et al
2023
-
[40]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth anything v2.Advances in Neural Information Processing Systems (NeurIPS)37 (2024), 21875–21911
2024
-
[41]
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. 2023. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635(2023)
Pith/arXiv arXiv 2023
-
[42]
Shuo-Diao Yang, Hung-Ting Su, Winston H Hsu, and Wen-Chin Chen. 2021. Class-agnostic few-shot object counting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (CVPR). 870–878
2021
-
[43]
Weihao Yu and Xinchao Wang. 2025. MambaOut: Do We Really Need Mamba for Vision?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[44]
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. [n. d.]. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. InForty-first International Conference on Machine Learning (ICML)
-
[45]
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2020. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159(2020). A Experiment We train MambaCount on the REC-8K training set and evaluate it on the corresponding test split for the REC task. For the class- agnostic counting task, we...
Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.