Handling Feature Heterogeneity with Learnable Graph Patches
Pith reviewed 2026-06-27 01:34 UTC · model grok-4.3
The pith
Learnable graph patches let models pre-train on graphs from many domains despite mismatched node features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
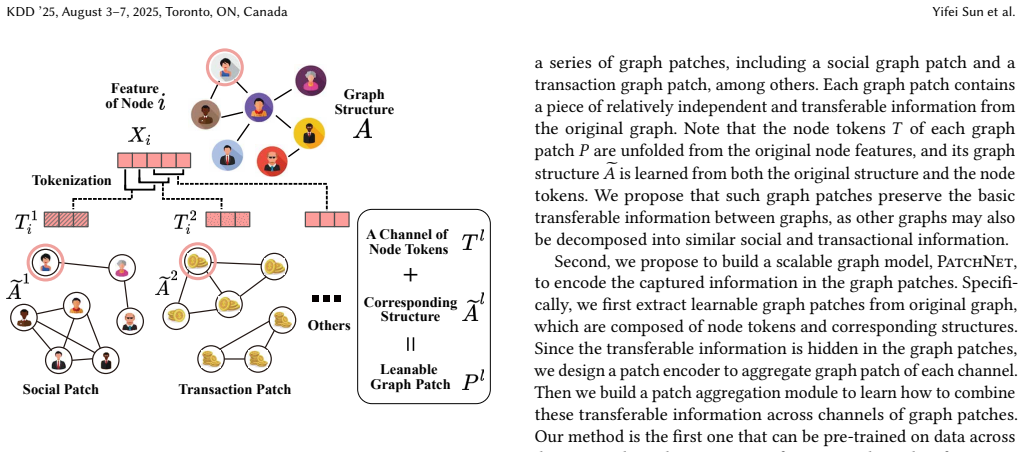
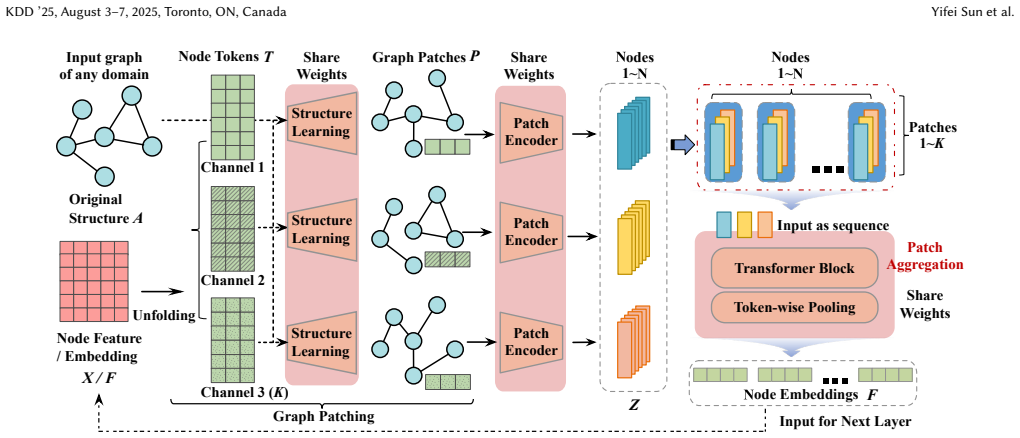
Unfolding node features into learnable graph patches produces domain-agnostic semantic units; a patch encoder extracts knowledge from each unit and a patch aggregator learns their combinations, so that a single model can be pre-trained on multi-domain graphs and transferred to downstream datasets across domains without textual information.
What carries the argument
Learnable graph patches: the smallest semantic units created by unfolding node features and constructing separate patch structures for each.
If this is right
- Multi-domain graphs can be used together for pre-training a single model.
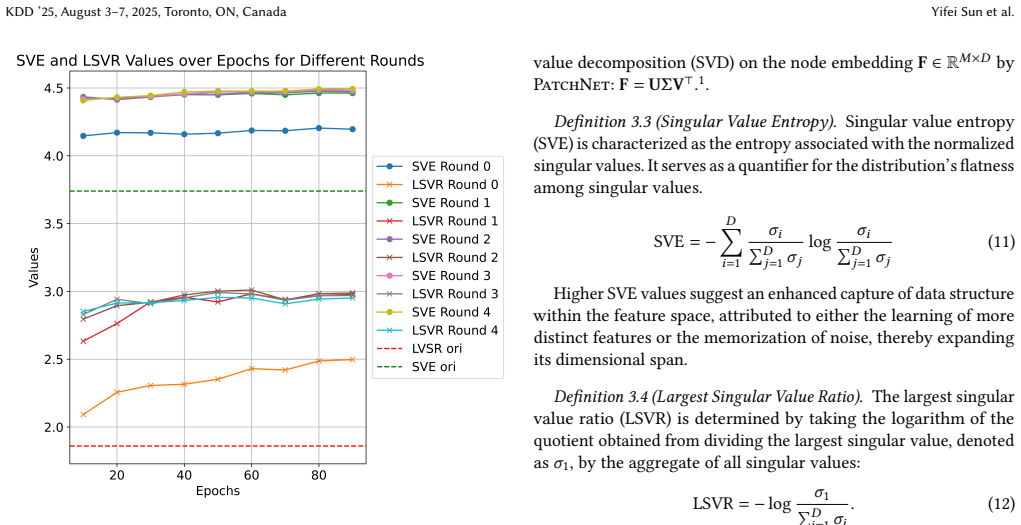
- Downstream performance improves on a range of datasets and tasks after such pre-training.
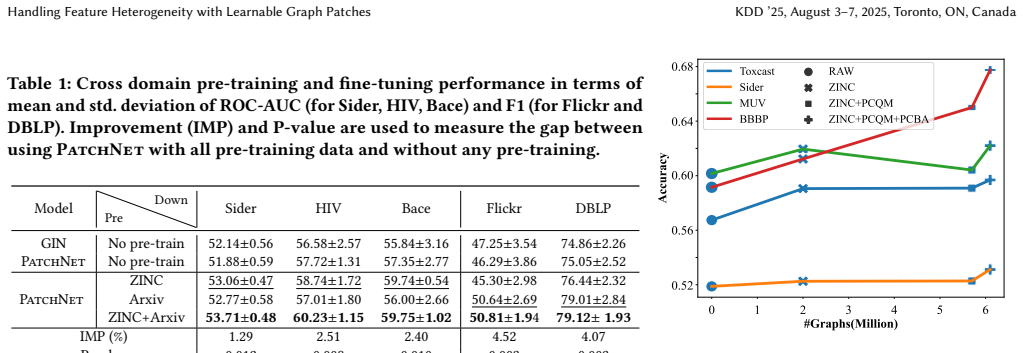
- Performance on downstream tasks increases consistently as the amount of pre-training data grows.
- The generated node embeddings remain transferable across domains.
- The approach connects to and extends existing graph models through the patch decomposition step.
Where Pith is reading between the lines
- The same patch idea might be tested on other structured data types that suffer from feature mismatch, such as heterogeneous tabular collections.
- Scaling the pre-training set to thousands of graphs from dozens of domains would provide a direct check on whether the observed scaling continues.
- If patch structures can be aligned with known motifs or subgraphs in a domain, the method could offer a route to interpretable transfer.
- The framework could be combined with existing graph contrastive or generative objectives to see whether the patch units improve those losses.
Load-bearing premise
Unfolding node features into patches yields semantic units whose encodings transfer across datasets even when no text is available to describe the features.
What would settle it
A controlled test in which a model pre-trained on multiple domains performs no better (or worse) than the same architecture pre-trained on a single domain when both are evaluated on the same downstream tasks.
Figures

read the original abstract
In recent years, the rapid development of foundation models and graph pre-training technologies has spurred increasing interest in constructing a universal pre-trained graph model or Graph Foundation Model (GFM). However, a significant challenge is that existing models are unable to address feature heterogeneity in graph data without textual information, which hinders the transferability of graph models across different datasets. To bridge this gap, we propose the concept of learnable graph patches, which we regard as the smallest semantic units of any graph data. We decompose the graph into learnable graph patches by unfolding the node features and constructing corresponding patch structures separately. We then design a framework that mines transferable information from graph data across domains. Specifically, after extracting graph patches, we propose a patch encoder to extract knowledge from each unit and a patch aggregator to learn how the units are combined into a whole. Due to its domain-agnostic nature, the model can be applied to downstream data across different domains. Furthermore, we analyze the connection between our method and existing graph models, as well as the transferability of the node embeddings it generates. Empirically, our method not only achieves the capability to use multi-domain graphs for pre-training, but also shows enhanced performance across various downstream datasets and tasks. Moreover, we observe consistent improvement in downstream performance as the volume of pre-training data increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learnable graph patches as the smallest semantic units to address feature heterogeneity in graphs lacking textual information. It decomposes graphs by unfolding node features and building separate patch structures, then applies a shared patch encoder and aggregator to mine transferable knowledge across domains for pre-training. The central claims are that this enables multi-domain graph pre-training, yields enhanced downstream performance on varied datasets and tasks, and shows consistent gains as pre-training data volume increases; the work also analyzes connections to existing graph models and node embedding transferability.
Significance. If the empirical scaling and cross-domain transfer results are robustly demonstrated with proper baselines, ablations, and controls for feature heterogeneity, the approach could meaningfully advance graph foundation models by removing reliance on textual alignment. The domain-agnostic patch construction is a potentially useful primitive, but its value hinges on whether the unfolding and shared encoder actually produce invariant units rather than domain-specific artifacts.
major comments (2)
- [Abstract / decomposition paragraph] Abstract and framework description: the assertion that unfolding node features into learnable patches produces domain-agnostic semantic units whose encodings transfer across datasets is load-bearing for the multi-domain pre-training claim, yet no derivation, normalization step, or alignment mechanism is supplied to show why outputs remain invariant to differing feature dimensions, distributions, and semantics; this directly matches the skeptic concern and leaves the scaling observation and downstream gains dependent on an untested assumption.
- [Abstract] Abstract: the empirical claims of enhanced performance and consistent improvement with pre-training volume are stated without reference to any baselines, error bars, dataset statistics, ablation results, or statistical tests, making it impossible to evaluate whether the reported gains exceed what could be obtained by simpler domain-specific models or random effects.
minor comments (2)
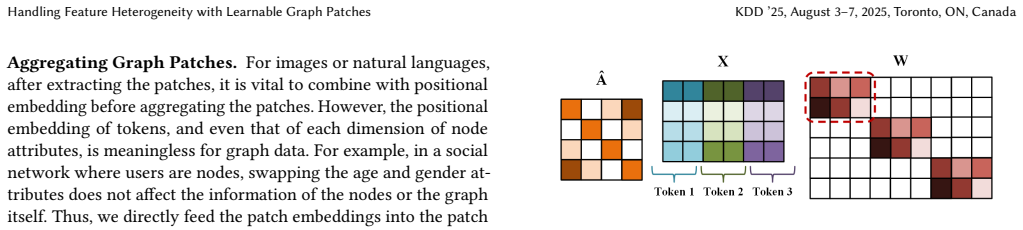
- [Framework] Notation for patch construction and the distinction between patch encoder and aggregator should be formalized with equations or pseudocode to clarify the shared parameters across domains.
- [Analysis section] The connection analysis to existing graph models would benefit from explicit comparison of computational complexity or embedding properties rather than high-level discussion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / decomposition paragraph] Abstract and framework description: the assertion that unfolding node features into learnable patches produces domain-agnostic semantic units whose encodings transfer across datasets is load-bearing for the multi-domain pre-training claim, yet no derivation, normalization step, or alignment mechanism is supplied to show why outputs remain invariant to differing feature dimensions, distributions, and semantics; this directly matches the skeptic concern and leaves the scaling observation and downstream gains dependent on an untested assumption.
Authors: The domain-agnostic property is achieved by first unfolding each node's feature vector into a fixed collection of learnable patches with uniform structure and dimensionality, independent of the original feature space; a shared patch encoder then processes every patch identically, and the aggregator combines them without reference to domain-specific semantics. While the current manuscript describes this construction, we agree that an explicit derivation of invariance (including any implicit normalization from the unfolding step) would strengthen the presentation. We will add a short subsection deriving the invariance property and clarifying the absence of domain-specific alignment. revision: yes
-
Referee: [Abstract] Abstract: the empirical claims of enhanced performance and consistent improvement with pre-training volume are stated without reference to any baselines, error bars, dataset statistics, ablation results, or statistical tests, making it impossible to evaluate whether the reported gains exceed what could be obtained by simpler domain-specific models or random effects.
Authors: The abstract is intentionally concise; all requested elements (baselines, error bars from repeated runs, dataset statistics, ablations, and significance tests) appear in the experimental section. To address the concern directly, we will revise the abstract to include a brief qualifier referencing the controlled experiments (e.g., “outperforming domain-specific baselines with statistical significance, as shown in Section 5”). revision: yes
Circularity Check
No circularity; derivation self-contained as new methodological proposal
full rationale
The provided abstract and description introduce learnable graph patches as a novel decomposition of node features into domain-agnostic semantic units, followed by a patch encoder and aggregator for multi-domain pre-training. No equations, fitted parameters, or self-citations are quoted that would reduce the transferability claim or performance scaling to inputs by construction. The central premise—that unfolding produces transferable units—is presented as an empirical design choice rather than derived from prior results or tautological definitions. This qualifies as an independent methodological contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Uchenna Akujuobi, Han Yufei, Qiannan Zhang, and Xiangliang Zhang. 2019. Collaborative Graph Walk for Semi-Supervised Multi-label Node Classification. In2019 IEEE International Conference on Data Mining (ICDM). 1–10. https: //doi.org/10.1109/ICDM.2019.00010
-
[2]
Yuxuan Cao, Jiarong Xu, Carl Yang, Jiaan Wang, Yunchao Zhang, Chunping Wang, Lei Chen, and Yang Yang. 2023. When to Pre-Train Graph Neural Networks? From Data Generation Perspective!. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 142–153
2023
-
[3]
Jinsong Chen, Kaiyuan Gao, Gaichao Li, and Kun He. 2023. NAGphormer: A Tok- enized Graph Transformer for Node Classification in Large Graphs. InProceedings of the International Conference on Learning Representations
2023
-
[4]
Xinyang Chen, Sinan Wang, Mingsheng Long, and Jianmin Wang. 2019. Transfer- ability vs. Discriminability: Batch Spectral Penalization for Adversarial Domain Adaptation. InProceedings of the 36th International Conference on Machine Learn- ing (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 1081–1090
2019
-
[5]
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al . 2023. Exploring the potential of large language models (llms) in learning on graphs.arXiv preprint arXiv:2307.03393(2023)
arXiv 2023
-
[6]
Tri Dao, Beidi Chen, Nimit S Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher Ré. 2022. Monarch: Expressive structured matrices for efficient and accurate training. InInternational Conference on Machine Learning. PMLR, 4690–4721
2022
-
[7]
Vijay Prakash Dwivedi and Xavier Bresson. 2020. A generalization of transformer networks to graphs.arXiv preprint arXiv:2012.09699(2020)
arXiv 2020
-
[8]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jian, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D Hwang, et al
-
[9]
Faith and Fate: Limits of Transformers on Compositionality.arXiv preprint arXiv:2305.18654(2023)
arXiv 2023
-
[10]
Taoran Fang, Yunchao Zhang, Yang Yang, Chunping Wang, and Lei Chen. 2023. Universal Prompt Tuning for Graph Neural Networks. InThirty-seventh Confer- ence on Neural Information Processing Systems
2023
-
[11]
Taoran Fang, Wei Zhou, Yifei Sun, Kaiqiao Han, Lvbin Ma, and Yang Yang. 2024. Exploring Correlations of Self-supervised Tasks for Graphs. InInternational Conference on Machine Learning
2024
-
[12]
Bahare Fatemi, Layla El Asri, and Seyed Mehran Kazemi. 2021. Slaps: Self- supervision improves structure learning for graph neural networks.Advances in Neural Information Processing Systems34 (2021), 22667–22681
2021
-
[13]
Xiaoxin He, Bryan Hooi, Thomas Laurent, Adam Perold, Yann LeCun, and Xavier Bresson. 2023. A generalization of vit/mlp-mixer to graphs. InInternational conference on machine learning. PMLR, 12724–12745
2023
-
[14]
Zhenyu Hou, Yufei He, Yukuo Cen, Xiao Liu, Yuxiao Dong, Evgeny Kharlamov, and Jie Tang. 2023. GraphMAE2: A Decoding-Enhanced Masked Self-Supervised Graph Learner. arXiv:2304.04779 [cs.LG] https://arxiv.org/abs/2304.04779
arXiv 2023
-
[15]
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022. GraphMAE: Self-Supervised Masked Graph Autoencoders. arXiv:2205.10803 [cs.LG] https://arxiv.org/abs/2205.10803
arXiv 2022
-
[16]
Weihua Hu, Matthias Fey, Hongyu Ren, Maho Nakata, Yuxiao Dong, and Jure Leskovec. 2021. OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs. arXiv:2103.09430 [cs.LG]
arXiv 2021
-
[17]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open Graph Benchmark: Datasets for Machine Learning on Graphs.arXiv preprint arXiv:2005.00687(2020)
arXiv 2020
-
[18]
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. 2019. Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265(2019)
arXiv 2019
-
[19]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. 2020. Gpt-gnn: Generative pre-training of graph neural networks. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1857–1867
2020
-
[20]
Renhong Huang, Jiarong Xu, Xin Jiang, Chenglu Pan, Zhiming Yang, Chunping Wang, and Yang Yang. 2024. Measuring Task Similarity and Its Implication in Fine-Tuning Graph Neural Networks. 38, 11 (2024), 12617–12625
2024
-
[21]
Mingxuan Ju, Tong Zhao, Qianlong Wen, Wenhao Yu, Neil Shah, Yanfang Ye, and Chuxu Zhang. 2023. Multi-task Self-supervised Graph Neural Networks Enable Stronger Task Generalization. (2023)
2023
-
[22]
Xi Lin, Hui-Ling Zhen, Zhenhua Li, Qing-Fu Zhang, and Sam Kwong. 2019. Pareto multi-task learning.Advances in neural information processing systems32 (2019)
2019
-
[23]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. 2023. One for All: Towards Training One Graph Model for All Classification Tasks.arXiv preprint arXiv:2310.00149(2023)
arXiv 2023
-
[24]
Jiawei Liu, Cheng Yang, Zhiyuan Lu, Junze Chen, Yibo Li, Mengmei Zhang, Ting Bai, Yuan Fang, Lichao Sun, Philip S Yu, et al. 2023. Towards graph foundation models: A survey and beyond.arXiv preprint arXiv:2310.11829(2023)
arXiv 2023
-
[26]
Shengchao Liu, Hanchen Wang, Weiyang Liu, Joan Lasenby, Hongyu Guo, and Jian Tang. 2022. Pre-training Molecular Graph Representation with 3D Geometry. arXiv:2110.07728 [cs.LG]
arXiv 2022
-
[27]
Yixin Liu, Yu Zheng, Daokun Zhang, Hongxu Chen, Hao Peng, and Shirui Pan
-
[28]
InProceedings of the ACM Web Conference 2022
Towards unsupervised deep graph structure learning. InProceedings of the ACM Web Conference 2022. 1392–1403
2022
-
[29]
Haitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Michael Galkin, and Jiliang Tang. 2024. Graph foundation models.arXiv preprint arXiv:2402.02216(2024)
arXiv 2024
-
[30]
Gaspard Michel, Giannis Nikolentzos, Johannes F Lutzeyer, and Michalis Vazir- giannis. 2023. Path neural networks: Expressive and accurate graph neural networks. InInternational Conference on Machine Learning. PMLR, 24737–24755
2023
-
[31]
Erxue Min, Runfa Chen, Yatao Bian, Tingyang Xu, Kangfei Zhao, Wenbing Huang, Peilin Zhao, Junzhou Huang, Sophia Ananiadou, and Yu Rong. 2022. Trans- former for graphs: An overview from architecture perspective.arXiv preprint arXiv:2202.08455(2022)
arXiv 2022
-
[32]
Samet Oymak, Zalan Fabian, Mingchen Li, and Mahdi Soltanolkotabi. 2019. Gen- eralization guarantees for neural networks via harnessing the low-rank structure of the jacobian.arXiv preprint arXiv:1906.05392(2019)
Pith/arXiv arXiv 2019
-
[33]
Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. 2020. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training.KDD(2020)
2020
-
[34]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[35]
Ladislav Rampášek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. 2022. Recipe for a general, powerful, scalable graph transformer.Advances in Neural Information Processing Systems35 (2022), 14501–14515
2022
-
[36]
O’Reilly Media, Inc
Bharath Ramsundar, Peter Eastman, Pat Walters, and Vijay Pande. 2019.Deep learning for the life sciences: applying deep learning to genomics, microscopy, drug discovery, and more. " O’Reilly Media, Inc. "
2019
-
[37]
Abulhair Saparov and He He. 2022. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought.arXiv preprint arXiv:2210.01240 (2022)
arXiv 2022
-
[38]
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Pitfalls of Graph Neural Network Evaluation.arXiv preprint arXiv: 1811.05868(2018)
Pith/arXiv arXiv 2018
-
[39]
Hannes Stärk, Dominique Beaini, Gabriele Corso, Prudencio Tossou, Christian Dallago, Stephan Günnemann, and Pietro Liò. 2022. 3d infomax improves gnns for molecular property prediction. InInternational Conference on Machine Learning. PMLR, 20479–20502
2022
-
[40]
Teague Sterling and John J Irwin. 2015. ZINC 15–ligand discovery for everyone. Journal of chemical information and modeling55, 11 (2015), 2324–2337
2015
-
[41]
Yifei Sun, Haoran Deng, Yang Yang, Chunping Wang, Jiarong Xu, Renhong Huang, Linfeng Cao, Yang Wang, and Lei Chen. 2022. Beyond Homophily: Structure- aware Path Aggregation Graph Neural Network. InProceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Lud De Raedt (Ed.). International Joint Conferences on Arti...
-
[42]
Yifei Sun, Qi Zhu, Yang Yang, Chunping Wang, Tianyu Fan, Jiajun Zhu, and Lei Chen. 2024. Fine-Tuning Graph Neural Networks by Preserving Graph Generative Patterns. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 9053–9061
2024
-
[43]
Susheel Suresh, Pan Li, Cong Hao, and Jennifer Neville. 2021. Adversarial graph augmentation to improve graph contrastive learning.Advances in Neural Infor- mation Processing Systems34 (2021), 15920–15933
2021
-
[44]
Kavukcuoglu
Aäron van den Oord, Oriol Vinyals, and K. Kavukcuoglu. 2017. Neural Discrete Representation Learning.NIPS(2017)
2017
-
[45]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. InICLR
2018
-
[46]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can Language Models Solve Graph Problems in Natural Language?arXiv preprint arXiv:2305.10037(2023)
arXiv 2023
-
[47]
Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani. 2022. Molecular Contrastive Learning of Representations via Graph Neural Networks. arXiv:2102.10056 [cs.LG]
arXiv 2022
-
[48]
Max Welling and Thomas N Kipf. 2016. Semi-supervised classification with graph convolutional networks. InJ. International Conference on Learning Representations (ICLR 2017)
2016
-
[49]
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Ge- niesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. 2018. MoleculeNet: a benchmark for molecular machine learning.Chemical science9, 2 (2018), 513–530
2018
-
[50]
Jun Xia, Lirong Wu, Jintao Chen, Bozhen Hu, and Stan Z Li. 2022. Simgrace: A simple framework for graph contrastive learning without data augmentation. In Proceedings of the ACM Web Conference 2022. 1070–1079. Handling Feature Heterogeneity with Learnable Graph Patches KDD ’25, August 3–7, 2025, Toronto, ON, Canada Type Name𝑁 𝐸 Pre-training Graph levelZIN...
2022
-
[51]
Jun Xia, Chengshuai Zhao, Bozhen Hu, Zhangyang Gao, Cheng Tan, Yue Liu, Siyuan Li, and Stan Z Li. 2023. Mole-bert: Rethinking pre-training graph neural networks for molecules. (2023)
2023
-
[52]
Jun Xia, Yanqiao Zhu, Yuanqi Du, and Stan Z Li. 2022. A survey of pretraining on graphs: Taxonomy, methods, and applications.arXiv preprint arXiv:2202.07893 (2022)
arXiv 2022
-
[53]
Jun Xia, Yanqiao Zhu, Yuanqi Du, and Stan Z. Li. 2022. A Systematic Survey of Chemical Pre-trained Models.arXiv preprint arXiv: Arxiv-2210.16484(2022)
arXiv 2022
-
[54]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How Powerful are Graph Neural Networks?. InICLR
2019
-
[55]
Minghao Xu, Hang Wang, Bingbing Ni, Hongyu Guo, and Jian Tang. 2021. Self- supervised graph-level representation learning with local and global structure. InInternational Conference on Machine Learning. PMLR, 11548–11558
2021
-
[56]
Yihao Xue, Kyle Whitecross, and Baharan Mirzasoleiman. 2022. Investigating why contrastive learning benefits robustness against label noise. InInternational Conference on Machine Learning. PMLR, 24851–24871
2022
-
[57]
Yang Yang, Yuhong Xu, Yizhou Sun, Yuxiao Dong, Fei Wu, and Yueting Zhuang
-
[58]
Mining fraudsters and fraudulent strategies in large-scale mobile social networks.IEEE Transactions on Knowledge and Data Engineering33, 1 (2019), 169–179
2019
-
[59]
Yang Yang, Yuhong Xu, Chunping Wang, Yizhou Sun, Fei Wu, Yueting Zhuang, and Ming Gu. 2019. Understanding default behavior in online lending. InCIKM. 2043–2052
2019
-
[60]
Jiacai Yi, Chengkun Wu, Xiaochen Zhang, Xinyi Xiao, Yanlong Qiu, Wentao Zhao, Tingjun Hou, and Dongsheng Cao. 2022. MICER: a pre-trained encoder– decoder architecture for molecular image captioning.Bioinformatics38, 19 (2022), 4562–4572
2022
-
[61]
Peiqi Yin, Xiao Yan, Jinjing Zhou, Qiang Fu, Zhenkun Cai, James Cheng, Bo Tang, and Minjie Wang. 2022. DGI: Easy and Efficient Inference for GNNs. arXiv:2211.15082 [cs.LG] https://arxiv.org/abs/2211.15082
arXiv 2022
-
[62]
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. 2021. Do transformers really perform badly for graph representation?Advances in Neural Information Processing Systems34 (2021), 28877–28888
2021
-
[63]
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. 2021. Do Transformers Really Perform Badly for Graph Representation?. InThirty-Fifth Conference on Neural Information Processing Systems. https://openreview.net/forum?id=OeWooOxFwDa
2021
-
[64]
Yuning You, Tianlong Chen, Yang Shen, and Zhangyang Wang. 2021. Graph contrastive learning automated. InInternational Conference on Machine Learning. PMLR, 12121–12132
2021
-
[65]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations.Advances in neural information processing systems33 (2020), 5812–5823
2020
-
[66]
Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. 2019. Graphsaint: Graph sampling based inductive learning method. arXiv preprint arXiv:1907.04931(2019)
arXiv 2019
-
[67]
Shuaicheng Zhang, Haohui Wang, Si Zhang, and Dawei Zhou. 2023. GPatcher: A Simple and Adaptive MLP Model for Alleviating Graph Heterophily.arXiv preprint arXiv:2306.14340(2023)
arXiv 2023
-
[68]
Haihong Zhao, Aochuan Chen, Xiangguo Sun, Hong Cheng, and Jia Li. 2024. All in one and one for all: A simple yet effective method towards cross-domain graph pretraining.arXiv preprint arXiv:2402.09834(2024)
arXiv 2024
-
[69]
Qi Zhu, Carl Yang, Yidan Xu, Haonan Wang, Chao Zhang, and Jiawei Han
-
[70]
Transfer learning of graph neural networks with ego-graph information maximization.Advances in Neural Information Processing Systems34 (2021), 1766–1779
2021
-
[71]
Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2020. Deep Graph Contrastive Representation Learning. arXiv:2006.04131 [cs.LG] https://arxiv.org/abs/2006.04131
arXiv 2020
-
[72]
Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. 2020. A comprehensive survey on transfer learning. Proc. IEEE109, 1 (2020), 43–76. A Details of Experiments A.1 Datasets The datasets used are shown in Tab. 7. The scale of the graphs used in pre-training and downstream tasks also highlights the high scalab...
2020
-
[73]
Recent self- supervised learning on graph data [10] explores the relationships between different tasks and designs models to achieve the most balanced embeddings for labels
captures the universal network topological properties through subgraph instance discrimination as pre-training task. Recent self- supervised learning on graph data [10] explores the relationships between different tasks and designs models to achieve the most balanced embeddings for labels. However, a majority of these works still utilize a plain GNN, such...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.