See First, Answer Later: Visual Evidence Pre-Alignment via Sufficiency-Driven RL
Pith reviewed 2026-06-27 01:41 UTC · model grok-4.3
The pith
An intermediate RL stage called VEPA trains multimodal models to generate sufficient question-conditioned visual evidence descriptions before standard post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
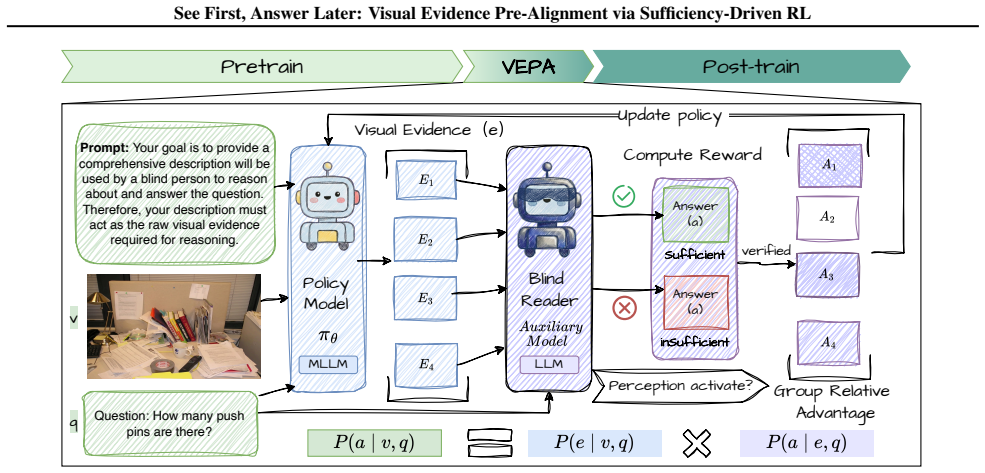
Inserting VEPA between pretraining and post-training, where models optimize question-conditioned visual evidence descriptions under a sufficiency-driven GRPO objective, produces strengthened visual grounding that transfers to downstream tasks, raises accuracy on visually demanding evaluations, and works together with standard supervised post-training without requiring additional task-specific training.
What carries the argument
Sufficiency-driven Group Relative Policy Optimization (GRPO) applied to question-conditioned visual evidence descriptions inside the VEPA intermediate stage.
If this is right
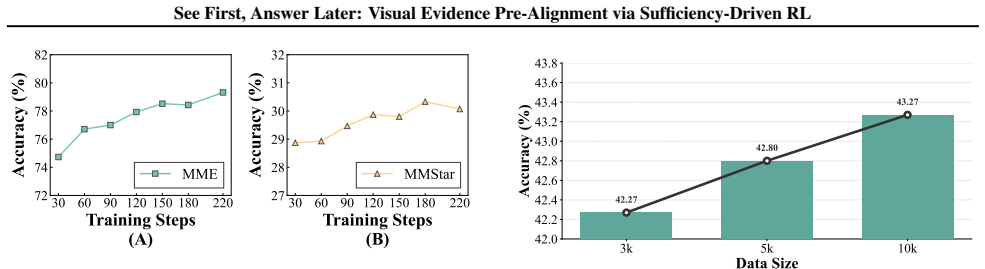
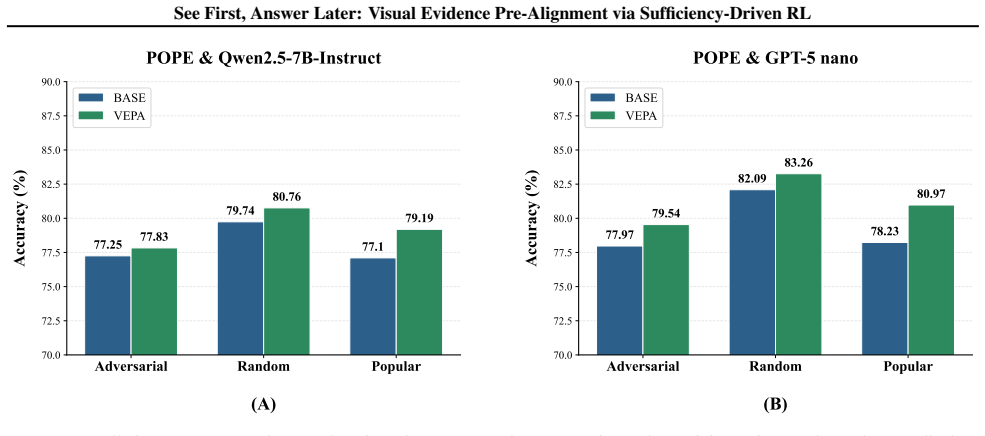
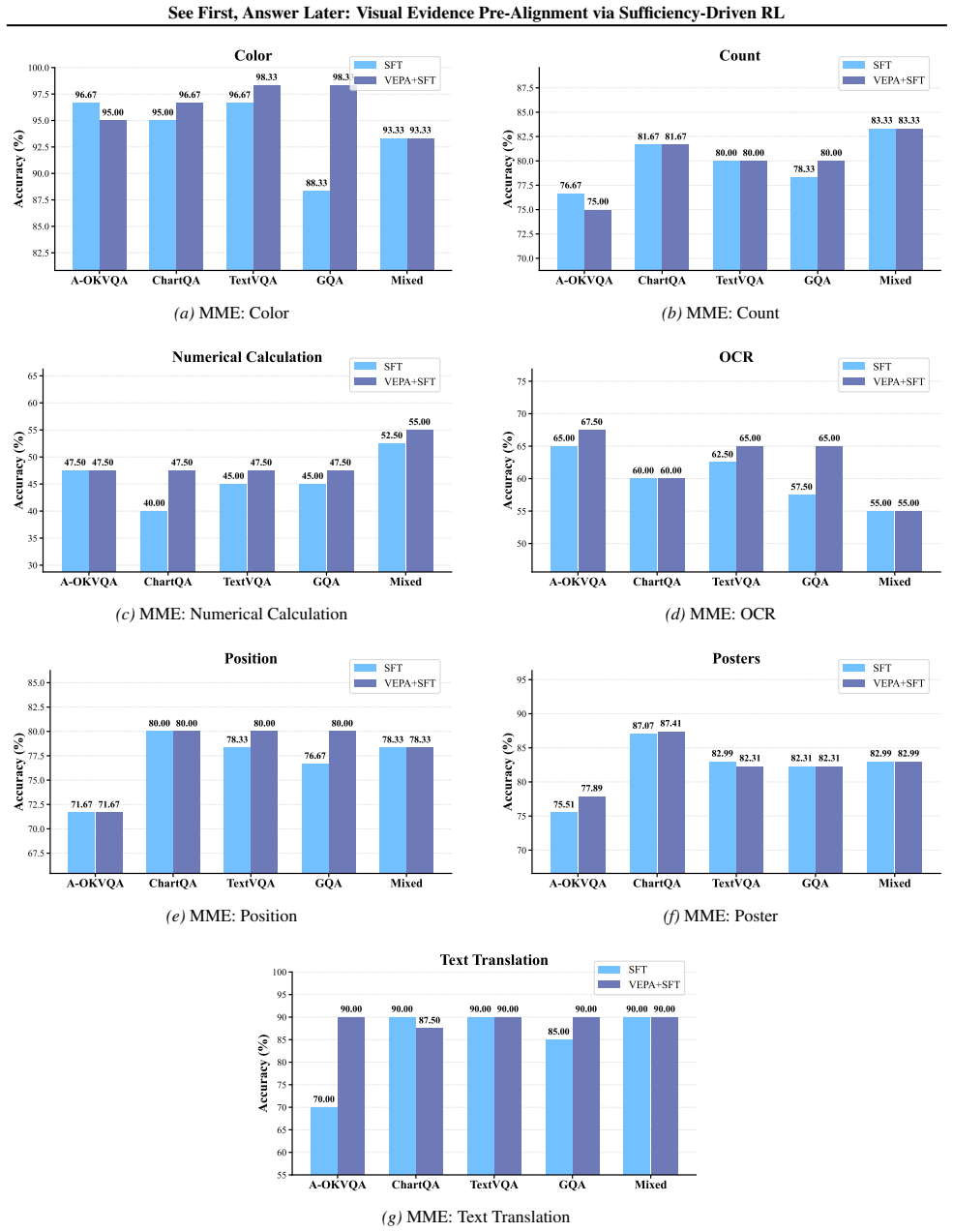
- Performance rises on visually demanding evaluations across diverse benchmarks.
- Gains originate from improved transferable visual grounding rather than added task-specific training.
- VEPA can be inserted into existing pipelines and complements supervised fine-tuning plus reinforcement learning post-training.
- The method requires no extra task-specific training data to produce the observed improvements.
Where Pith is reading between the lines
- Training pipelines could separate visual alignment from reasoning alignment to improve efficiency.
- Similar sufficiency objectives might be defined for other input types such as video or audio to strengthen grounding before reasoning stages.
- Pre-alignment may reduce the amount of later supervision needed for tasks that depend on fine visual details.
Load-bearing premise
That optimizing for sufficiency of visual evidence descriptions in the intermediate stage will create grounding improvements that transfer to final tasks instead of being tied to the specific benchmarks or reward signals used during that stage.
What would settle it
Train models with VEPA on one set of visually demanding tasks, then evaluate on a separate collection of image-based questions that differ in visual content and format; if accuracy shows no consistent lift over a matched baseline without VEPA, the transfer claim is false.
Figures



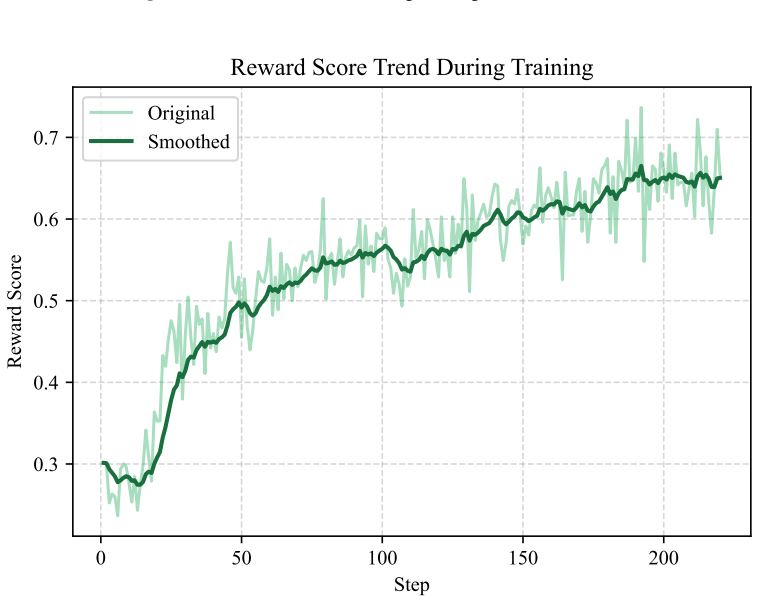
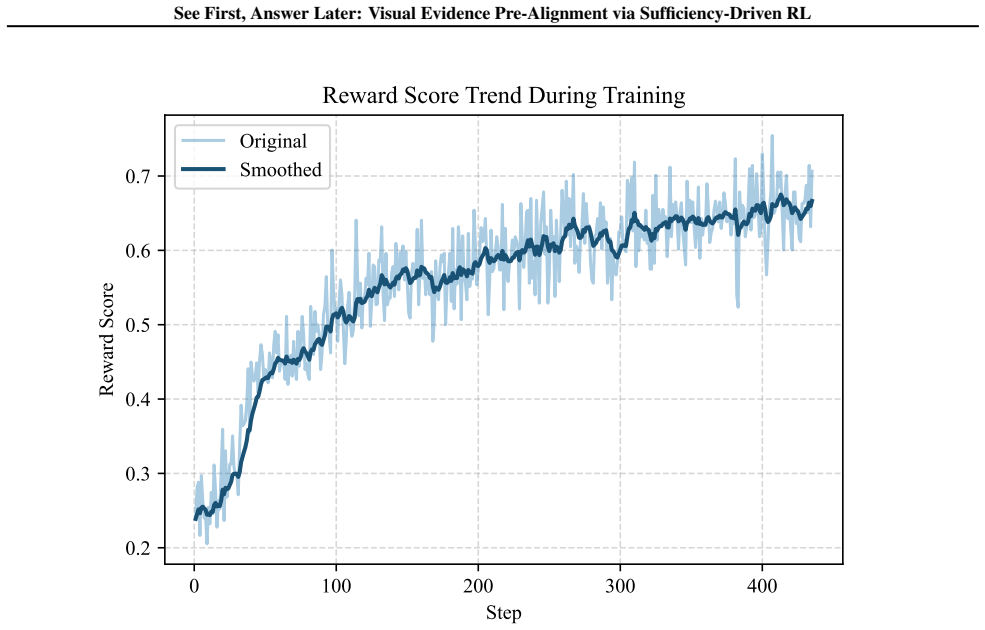
read the original abstract
Multimodal large language models (MLLMs) integrate strong text reasoning with visual inputs, yet their responses can be inconsistent with the underlying images, indicating ineffective utilization of visual evidence during inference. The prevailing training paradigm relies on large-scale caption-based pretraining for general alignment, followed by supervised fine-tuning and reinforcement learning to enable instruction following and complex reasoning. However, such pretraining provides only weak visual grounding: short, coarse captions bias models toward salient objects while neglecting fine-grained visual evidence. In this paper, we introduce Visual Evidence Pre-Alignment (VEPA), an intermediate stage between pretraining and post-training that explores a novel sufficiency-driven objective with Group Relative Policy Optimization (GRPO) to optimize question-conditioned visual evidence descriptions. Extensive experiments across diverse benchmarks show that our VEPA consistently enhances performance on visually demanding evaluations and complements standard supervised post-training. Further analyses show that the income stems from strengthened, transferable visual grounding, rather than from additional task-specific training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Visual Evidence Pre-Alignment (VEPA), an intermediate training stage for multimodal LLMs placed between caption-based pretraining and standard supervised post-training. VEPA uses a sufficiency-driven objective optimized via Group Relative Policy Optimization (GRPO) on question-conditioned visual evidence descriptions, with the central claim that this produces strengthened, transferable visual grounding that yields consistent gains on visually demanding benchmarks and is not reducible to task-specific artifacts.
Significance. If the transferability claim holds under rigorous controls, the work would offer a concrete, modular addition to existing MLLM pipelines that targets a documented weakness (coarse caption pretraining) without requiring changes to the final supervised or RL stages. The use of GRPO on a sufficiency objective is a clear technical choice that could be adopted or ablated by others.
major comments (2)
- [Abstract] Abstract: the claim that VEPA 'consistently enhances performance' and that 'the gain stems from strengthened, transferable visual grounding, rather than from additional task-specific training' is asserted without any reported numbers, baselines, ablation tables, or statistical tests. The full experimental section (including reward definition, training details, and cross-benchmark controls) is required to determine whether the data actually support the transferability conclusion.
- [Abstract / implied experimental design] The weakest assumption—that sufficiency-driven GRPO on question-conditioned descriptions produces grounding improvements that generalize beyond the intermediate-stage benchmarks and reward formulation—remains untested in the provided text. Explicit held-out-task or cross-domain evaluations (distinct from any benchmarks used to shape the GRPO reward) are needed to rule out benchmark-specific artifacts.
minor comments (1)
- [Abstract] Abstract contains the apparent typo 'the income stems from' (should be 'the gain stems from').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the experimental support in the full manuscript while noting where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that VEPA 'consistently enhances performance' and that 'the gain stems from strengthened, transferable visual grounding, rather than from additional task-specific training' is asserted without any reported numbers, baselines, ablation tables, or statistical tests. The full experimental section (including reward definition, training details, and cross-benchmark controls) is required to determine whether the data actually support the transferability conclusion.
Authors: The abstract follows standard conventions by summarizing claims at a high level. The full manuscript contains the complete experimental section with reward definitions, training details, baseline comparisons, ablation tables, and statistical analyses across benchmarks that substantiate the performance gains and the conclusion that improvements derive from transferable visual grounding rather than task-specific artifacts. We will revise the abstract to incorporate key quantitative results where length permits. revision: partial
-
Referee: [Abstract / implied experimental design] The weakest assumption—that sufficiency-driven GRPO on question-conditioned descriptions produces grounding improvements that generalize beyond the intermediate-stage benchmarks and reward formulation—remains untested in the provided text. Explicit held-out-task or cross-domain evaluations (distinct from any benchmarks used to shape the GRPO reward) are needed to rule out benchmark-specific artifacts.
Authors: The manuscript evaluates VEPA on multiple visually demanding benchmarks that are distinct from the question-conditioned descriptions used to define the sufficiency objective and GRPO reward. Additional analyses explicitly test and confirm that gains transfer beyond the intermediate stage and are not reducible to artifacts of the reward formulation or task-specific training. We maintain that the current cross-benchmark design already addresses generalization; however, we can add explicit discussion clarifying the separation between reward data and evaluation sets. revision: no
Circularity Check
No significant circularity; derivation is self-contained empirical claim
full rationale
The paper introduces VEPA as an intermediate training stage using a sufficiency-driven GRPO objective to optimize question-conditioned visual evidence descriptions. Claims rest on experimental results showing performance gains on visually demanding benchmarks, attributed to strengthened transferable visual grounding. No equations, derivations, or load-bearing steps are present in the provided text that reduce any 'prediction' or result to fitted inputs, self-definitions, or self-citation chains by construction. The central mechanism is framed as an empirical outcome independent of the training signal, consistent with external benchmark evaluation rather than internal tautology. This is the expected non-finding for an applied RL method paper without mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coarse, short captions in pretraining bias models toward salient objects and neglect fine-grained visual evidence.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Visual Evidence Prompting Mitigates Hallucinations in Large Vision-Language Models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
European conference on computer vision , pages=
A-okvqa: A benchmark for visual question answering using world knowledge , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
Findings of the association for computational linguistics: ACL 2022 , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[6]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Evaluating Object Hallucination in Large Vision-Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[9]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[10]
ArXiv , year=
Qwen2.5 Technical Report , author=. ArXiv , year=
-
[11]
2025 , note =
OpenAI , title =. 2025 , note =
2025
-
[12]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[13]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[14]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[17]
Forty-second International Conference on Machine Learning , year=
Probing Visual Language Priors in VLMs , author=. Forty-second International Conference on Machine Learning , year=
-
[18]
arXiv preprint arXiv:2505.14677 , year=
Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning , author=. arXiv preprint arXiv:2505.14677 , year=
-
[19]
Lecture Notes in Computer Science , pages=
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks , author=. Lecture Notes in Computer Science , pages=. 2020 , publisher=
2020
-
[20]
Scalable Vision Language Model Training via High Quality Data Curation
Dong, Hongyuan and Kang, Zijian and Yin, Weijie and LiangXiao, LiangXiao and ChaoFeng, ChaoFeng and Jiao, Ran. Scalable Vision Language Model Training via High Quality Data Curation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
Deyao Zhu and Jun Chen and Xiaoqian Shen and Xiang Li and Mohamed Elhoseiny , booktitle=. Mini
-
[23]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[24]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[25]
CoRR , year=
Visual-RFT: Visual Reinforcement Fine-Tuning , author=. CoRR , year=
-
[26]
arXiv preprint arXiv:2504.07615 , year=
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
-
[27]
Advances in neural information processing systems , volume=
Fine-tuning large vision-language models as decision-making agents via reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[29]
European Conference on Computer Vision , pages=
Dreamlip: Language-image pre-training with long captions , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[30]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing large vision-language models with ultra-detailed image caption generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[31]
DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning , author=. arXiv preprint arXiv:2505.14362 , year=
-
[32]
arXiv preprint arXiv:1809.02156 , year=
Object hallucination in image captioning , author=. arXiv preprint arXiv:1809.02156 , year=
-
[33]
arXiv preprint arXiv:2504.08837 , year=
Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning , author=. arXiv preprint arXiv:2504.08837 , year=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On scaling up a multilingual vision and language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
Proceedings of the Third Workshop on Multimodal Artificial Intelligence , pages=
A First Look: Towards Explainable TextVQA Models via Visual and Textual Explanations , author=. Proceedings of the Third Workshop on Multimodal Artificial Intelligence , pages=
-
[36]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Vqa-e: Explaining, elaborating, and enhancing your answers for visual questions , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[37]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2506.14245 , year=
Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms , author=. arXiv preprint arXiv:2506.14245 , year=
-
[39]
Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
What Makes for Good Image Captions? , author=. Workshop on Machine Learning and Compression, NeurIPS 2024 , year=
2024
-
[40]
Advances in Neural Information Processing Systems , volume=
Lossy compression for lossless prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Seeing through the human reporting bias: Visual classifiers from noisy human-centric labels , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Promptcap: Prompt-guided image captioning for vqa with gpt-3 , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2510.17269 , year=
Finevision: Open data is all you need , author=. arXiv preprint arXiv:2510.17269 , year=
-
[45]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[46]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[47]
European conference on computer vision , pages=
A diagram is worth a dozen images , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[48]
arXiv preprint arXiv:2105.04165 , year=
Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning , author=. arXiv preprint arXiv:2105.04165 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.