Robustness of Similarity-based Positional Encoding Under Rotations: Theoretical Analysis and Experimental Validation
Pith reviewed 2026-06-27 01:15 UTC · model grok-4.3
The pith
Similarity-based positional encoding remains stable under rotations given mild Lipschitz conditions on its components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under mild Lipschitz assumptions on the elementary components, simPE is stable under rotational perturbations and explicit perturbation bounds in Frobenius norm are derived. On four datasets with rotated test images, simPE consistently outperforms standard learned positional encoding in accuracy, F1 score, precision, and recall, most markedly in the small-to-moderate angle regime.
What carries the argument
Similarity-based positional encoding (simPE), which injects positional information through pairwise relations among input elements.
If this is right
- simPE supplies a quantifiable robustness guarantee for Transformer models facing small rotational shifts in input geometry.
- Performance gains appear most reliably in the small-to-moderate rotation range on both synthetic shapes and real image benchmarks.
- The encoding is provably not fully invariant, so some degradation must still be expected for large angles.
- The same stability mechanism can be checked on other controlled perturbations once the Lipschitz property is verified.
Where Pith is reading between the lines
- If the Lipschitz property holds for a given architecture, simPE could replace learned encodings in pipelines that preprocess medical or satellite images.
- The explicit bounds open the possibility of analytically predicting the angle threshold at which accuracy begins to fall sharply.
- Extending the same Lipschitz analysis to translations or affine transforms would test whether the stability result generalizes beyond rotations.
- Hybrid encodings that combine simPE with a small learned component might preserve the bound while recovering some invariance.
Load-bearing premise
The elementary components inside simPE satisfy mild Lipschitz conditions.
What would settle it
Measure whether the observed drop in classification metrics on rotated test images exceeds the size of the derived Frobenius-norm bounds when the Lipschitz condition on simPE components is deliberately violated.
Figures
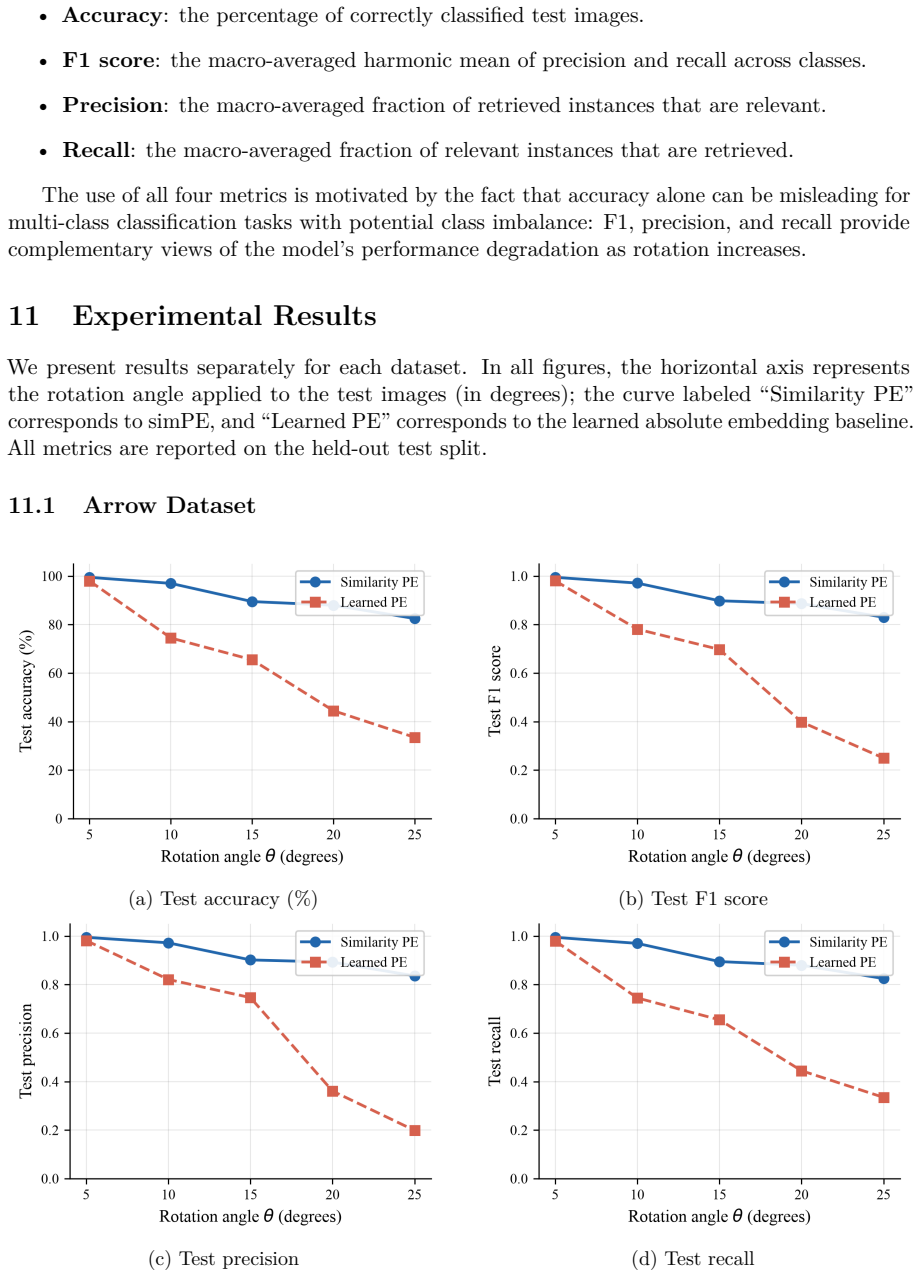
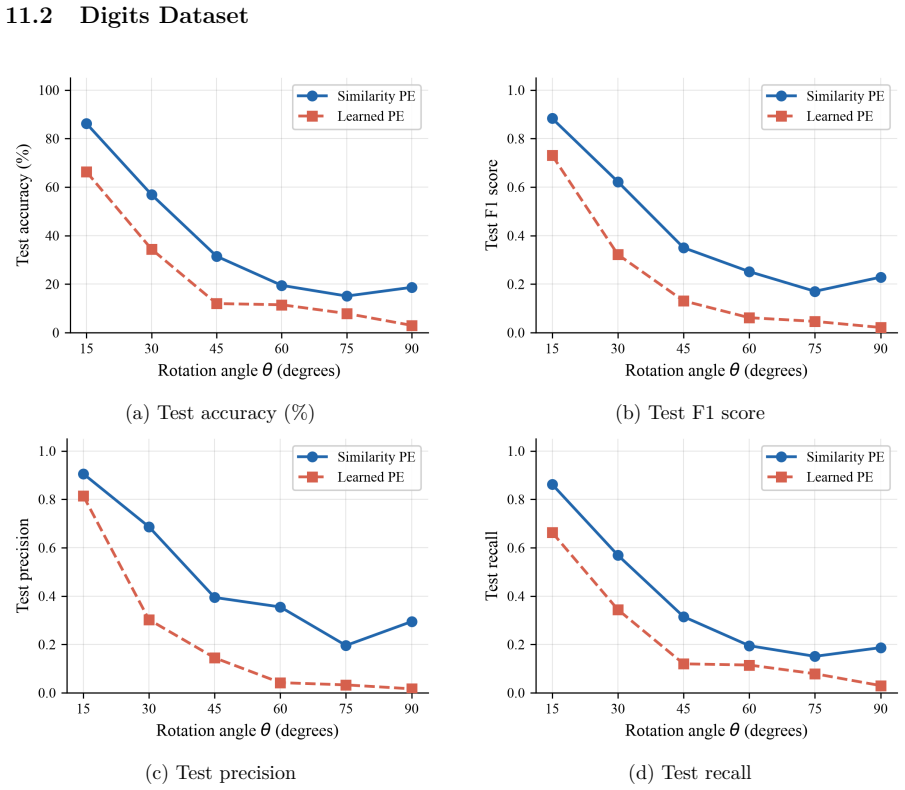
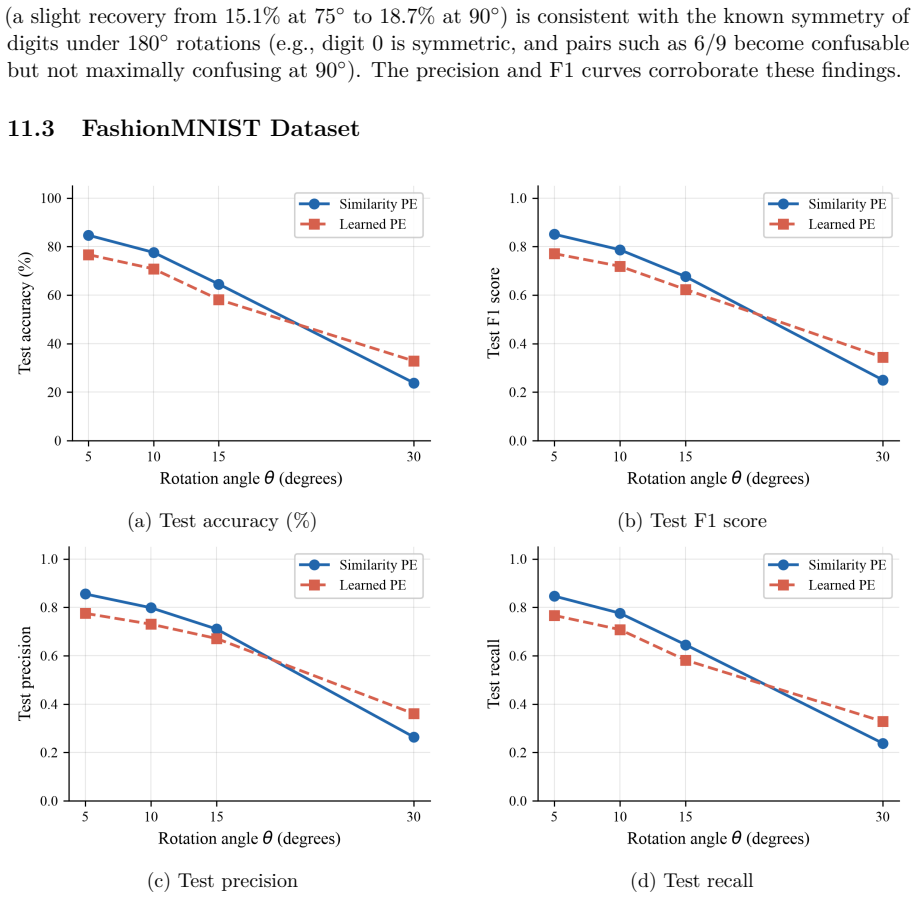
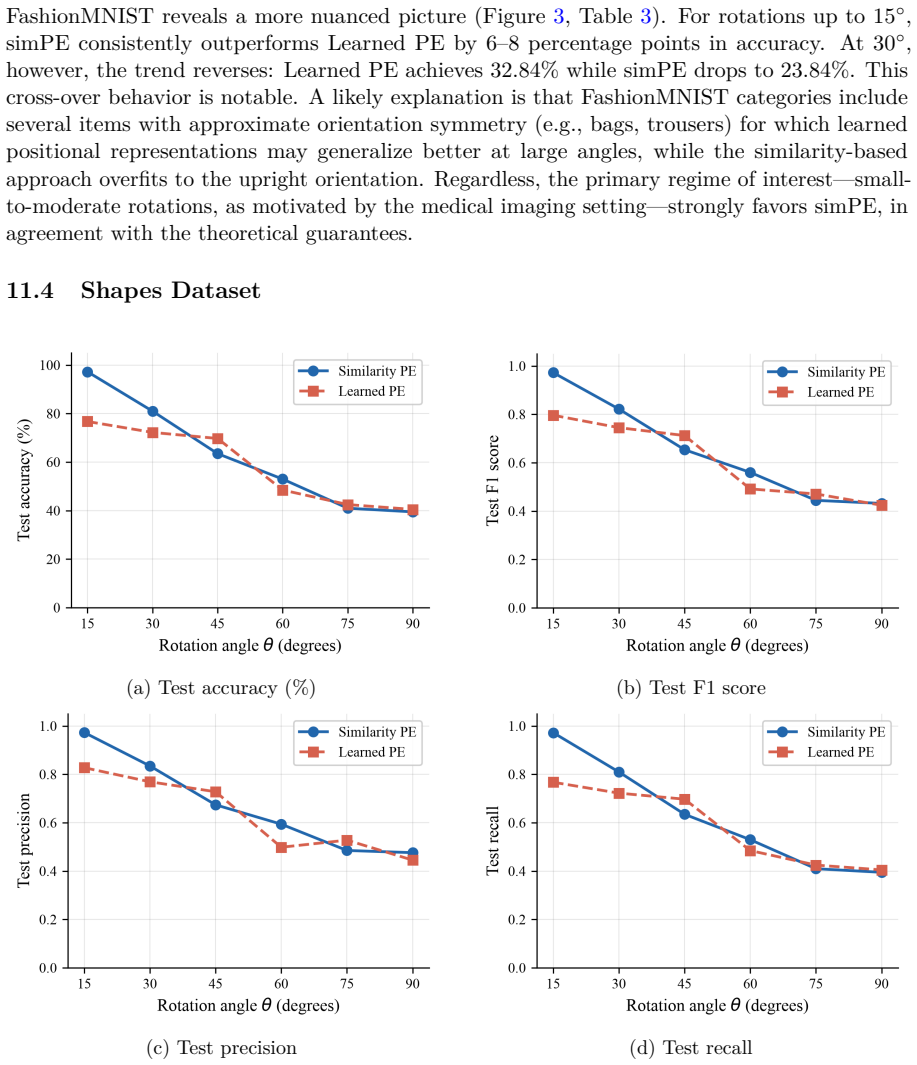
read the original abstract
Positional encoding is a fundamental component of Transformer architectures, as it injects information about the spatial or sequential arrangement of inputs. Among recent alternatives to standard absolute and sinusoidal encodings, similarity-based positional encoding (simPE) has emerged as a flexible framework for representing positional structure through pairwise relations. simPE was originally designed for medical imaging applications, where geometric robustness is especially relevant: small rotations naturally arise during image acquisition, induced by imaging instruments, patient positioning, or slight acquisition misalignments. Despite its empirical promise, the theoretical behavior of simPE under geometric perturbations has not been fully characterized. In this paper, we study the robustness of simPE with respect to rotations, combining formal theoretical analysis with experimental validation. We first show that simPE is generally not rotation-invariant. We then prove that, under mild Lipschitz assumptions on the elementary components, simPE is stable under rotational perturbations and derive explicit perturbation bounds in Frobenius norm. We validate these findings experimentally on four controlled datasets--a synthetic Arrow dataset, a synthetic Shapes dataset (four geometric shape categories), a synthetic Digits dataset, and a benchmark image classification dataset (FashionMNIST)--in which training and validation images are kept in a fixed canonical orientation while test images are subjected to increasing rotation angles. Across all datasets, simPE consistently outperforms standard learned positional encoding in terms of accuracy, F1 score, precision, and recall under rotation, particularly in the small-to-moderate angle regime, corroborating the theoretical stability guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that similarity-based positional encoding (simPE) is not generally rotation-invariant but becomes stable under rotational perturbations when mild Lipschitz assumptions hold on its elementary components; explicit perturbation bounds are derived in the Frobenius norm. Experiments on four controlled datasets (synthetic Arrow, Shapes, Digits, and FashionMNIST) with canonically oriented training/validation images and rotated test images show simPE consistently outperforming standard learned positional encoding on accuracy, F1, precision, and recall, especially in the small-to-moderate angle regime.
Significance. If the Lipschitz constants can be instantiated and shown to be sufficiently small for the concrete similarity functions and kernels, the work supplies useful theoretical grounding for simPE in rotation-sensitive domains such as medical imaging. The controlled experimental protocol across multiple synthetic and benchmark datasets provides concrete evidence of practical robustness gains over learned encodings.
major comments (2)
- [Abstract] Abstract and theoretical analysis: the explicit Frobenius-norm perturbation bounds are derived only after invoking unspecified 'mild Lipschitz assumptions on the elementary components.' These assumptions are not instantiated for the specific similarity functions, kernels, or embedding maps used in simPE, nor are the resulting constants computed or shown to produce non-vacuous bounds at the tested rotation angles. If the constants are large, the stability guarantees do not actually support the observed experimental robustness.
- [Experimental validation] Experimental section: full dataset construction details (exact rotation application procedure, angle ranges, and number of trials) and error-bar or statistical significance reporting are not visible, preventing verification that the reported outperformance is robust rather than anecdotal.
minor comments (1)
- Consider adding a short table or paragraph that either computes or bounds the Lipschitz constants for the concrete simPE components used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity and verifiability of our work on the robustness of simPE under rotations. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and theoretical analysis: the explicit Frobenius-norm perturbation bounds are derived only after invoking unspecified 'mild Lipschitz assumptions on the elementary components.' These assumptions are not instantiated for the specific similarity functions, kernels, or embedding maps used in simPE, nor are the resulting constants computed or shown to produce non-vacuous bounds at the tested rotation angles. If the constants are large, the stability guarantees do not actually support the observed experimental robustness.
Authors: We agree that the manuscript states the Lipschitz assumptions at a general level without providing concrete instantiations or numerical values for the constants associated with the specific similarity functions (e.g., dot-product or RBF) and embedding maps employed. This leaves open the question of bound tightness. In the revised manuscript we will add an appendix subsection that instantiates the constants for the concrete components used in the experiments (cosine similarity and Gaussian kernel) and evaluates the resulting Frobenius-norm bounds at the rotation angles tested (0–45°). If the computed constants render the bounds loose, we will explicitly note this limitation and discuss its implications for the theoretical support of the empirical results. revision: yes
-
Referee: [Experimental validation] Experimental section: full dataset construction details (exact rotation application procedure, angle ranges, and number of trials) and error-bar or statistical significance reporting are not visible, preventing verification that the reported outperformance is robust rather than anecdotal.
Authors: The referee correctly identifies that the current experimental description omits several implementation specifics required for full reproducibility. In the revision we will expand the experimental section (and add a dedicated appendix) with: (i) the precise rotation procedure (scipy.ndimage.rotate with bilinear interpolation and zero-padding), (ii) the exact angle ranges and increments used on each dataset, (iii) the number of independent trials (five random seeds), and (iv) error bars showing mean ± one standard deviation together with paired t-test p-values comparing simPE against learned positional encoding. These additions will allow readers to assess the statistical robustness of the reported gains. revision: yes
Circularity Check
No circularity: bounds derived from external assumptions; experiments provide independent validation
full rationale
The paper's central derivation establishes stability bounds under explicitly stated mild Lipschitz assumptions on the elementary components of simPE, which are invoked as external conditions rather than derived from the paper's own equations or data fits. Experimental results on four separate datasets (synthetic Arrow, Shapes, Digits, and FashionMNIST) with controlled rotations supply independent empirical corroboration. No load-bearing steps reduce by construction to self-citations, fitted parameters renamed as predictions, or self-definitional relations; the theoretical claim and validation remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild Lipschitz assumptions on the elementary components of simPE
Reference graph
Works this paper leans on
-
[1]
Why do deep convolutional networks generalize so poorly to small image transformations?Journal of Machine Learning Research, 20(184):1–25, 2019
Aharon Azulay and Yair Weiss. Why do deep convolutional networks generalize so poorly to small image transformations?Journal of Machine Learning Research, 20(184):1–25, 2019
2019
-
[2]
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. TransUNet: Transformers make strong encoders for medical image segmentation.arXiv preprint arXiv:2102.04306, 2021
Pith/arXiv arXiv 2021
-
[3]
Group equivariant convolutional networks
Taco Cohen and Max Welling. Group equivariant convolutional networks. InProceedings of the 33rd International Conference on Machine Learning, pages 2990–2999. PMLR, 2016
2016
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[5]
Convo- lutional sequence to sequence learning
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convo- lutional sequence to sequence learning. InProceedings of the 34th International Conference on Machine Learning, pages 1243–1252. PMLR, 2017
2017
-
[6]
John Wiley & Sons, New York, 1978
Erwin Kreyszig.Introductory Functional Analysis with Applications. John Wiley & Sons, New York, 1978
1978
-
[7]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[8]
Similarity-based positional encoding for enhanced classification in medical images
Giorgio Leonardi, Luigi Portinale, and Andrea Santomauro. Similarity-based positional encoding for enhanced classification in medical images. InProceedings of the 3rd AIxIA Workshop on Artificial Intelligence for Healthcare (HC@AIxIA 2024), volume 3880 ofCEUR Workshop Proceedings, pages 182–188, Bolzano, Italy, 2024. CEUR-WS.org. 17
2024
-
[9]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[10]
Image transformer
Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Łukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. InProceedings of the 35th International Conference on Machine Learning, pages 4055–4064. PMLR, 2018
2018
-
[11]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[12]
Tyrrell Rockafellar and Roger J.-B
R. Tyrrell Rockafellar and Roger J.-B. Wets.Variational Analysis, volume 317 of Grundlehren der mathematischen Wissenschaften. Springer, Berlin, Heidelberg, 1998
1998
-
[13]
McGraw-Hill, New York, 2 edition, 1991
Walter Rudin.Functional Analysis. McGraw-Hill, New York, 2 edition, 1991
1991
-
[14]
Comparing different positional encodings for the interpretation of medical images
Andrea Santomauro, Giorgio Leonardi, and Luigi Portinale. Comparing different positional encodings for the interpretation of medical images. In Pierangela Bruno, Francesco Calimeri, Francesco Cauteruccio, Mauro Dragoni, Fabio Stella, and Giorgio Terracina, editors,Artifi- cial Intelligence for Healthcare, and Hybrid Models for Coupling Deductive and Induc...
2026
-
[15]
Self-attention with relative position representations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 464–468. Association for Computational Linguistics, 2018
2018
-
[16]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[17]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[18]
General E(2)-equivariant steerable CNNs
Maurice Weiler and Gabriele Cesa. General E(2)-equivariant steerable CNNs. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[19]
Rethinking and improving relative position encoding for vision transformer
Kan Wu, Houwen Peng, Minghao Chen, Jianlong Fu, and Hongyang Chao. Rethinking and improving relative position encoding for vision transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10033–10041, 2021
2021
-
[20]
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 18
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.