Querying an astronomical database using large language models: the ALeRCE text-to-SQL system
Pith reviewed 2026-06-26 22:33 UTC · model grok-4.3
The pith
Large language models generate executable SQL from natural language for the ALeRCE astronomical database when guided by a four-module step-by-step framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
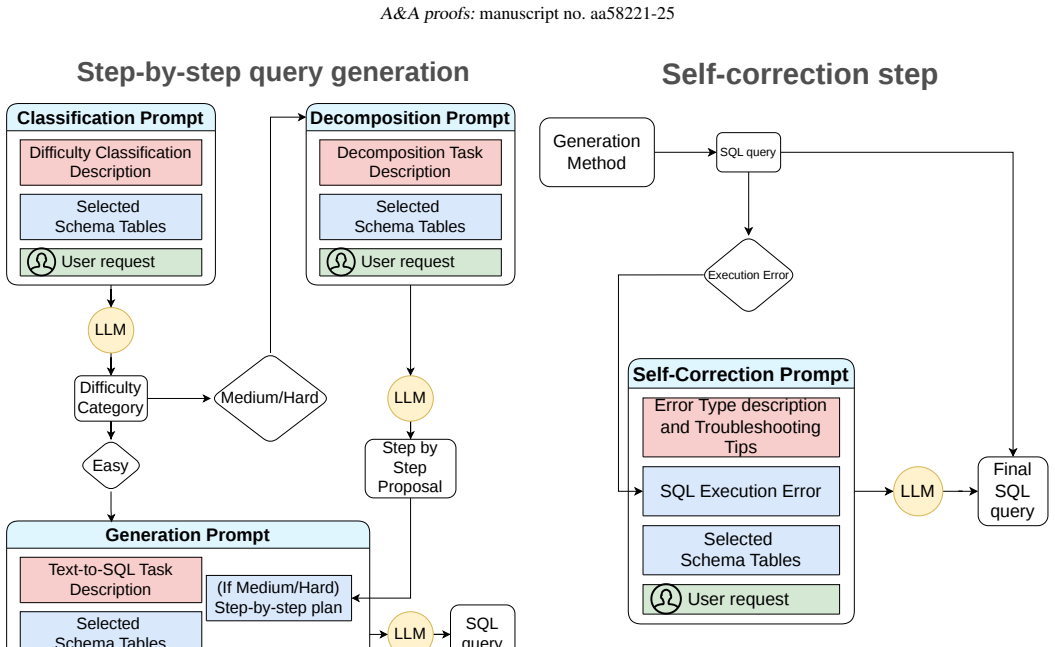
The step-by-step generation framework comprising schema linking, query classification, prompt decomposition, and self-correction modules enables LLMs to produce correct SQL queries from natural language inputs for the ALeRCE schema, consistently outperforming direct-inference baselines while the self-correction module reduces execution errors.
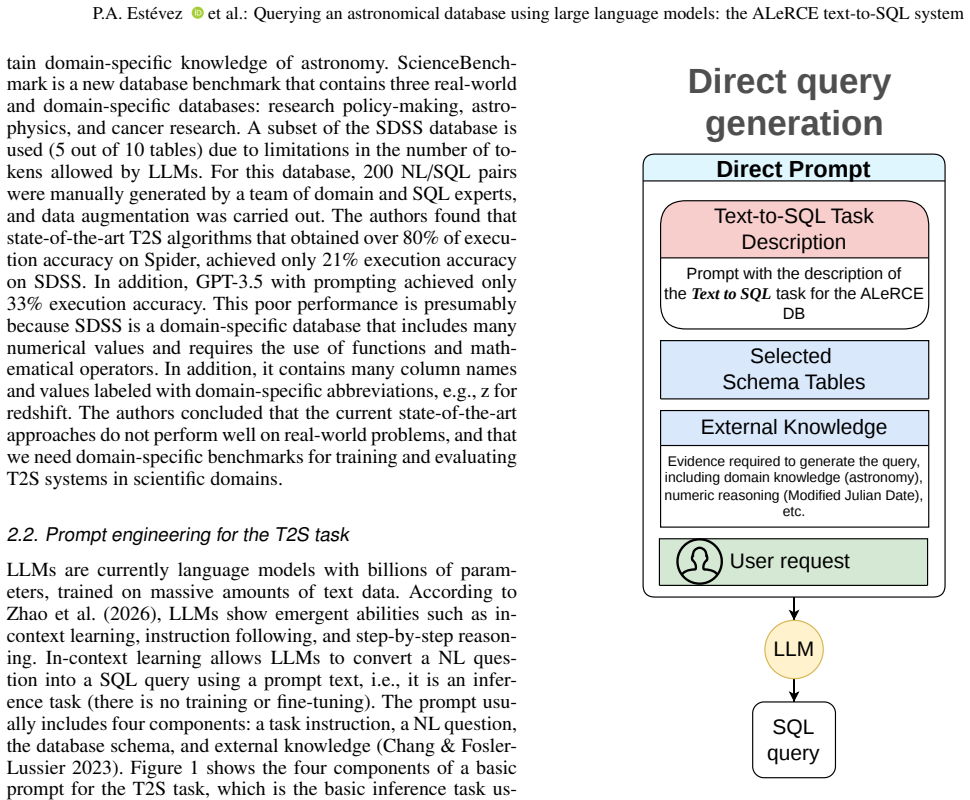
What carries the argument
The four-module step-by-step generation framework that breaks the text-to-SQL task into schema linking, query classification, prompt decomposition, and self-correction.
Load-bearing premise
The hand-constructed set of 110 NL/SQL pairs is representative enough of real user queries to support claims about performance across query complexity levels.
What would settle it
Performance measurements on a new collection of queries submitted by actual ALeRCE users, rather than the hand-crafted test set.
Figures

read the original abstract
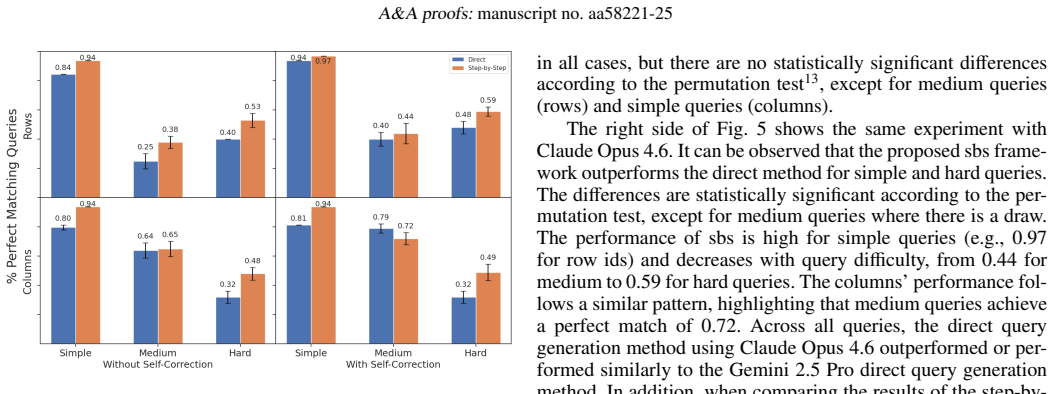
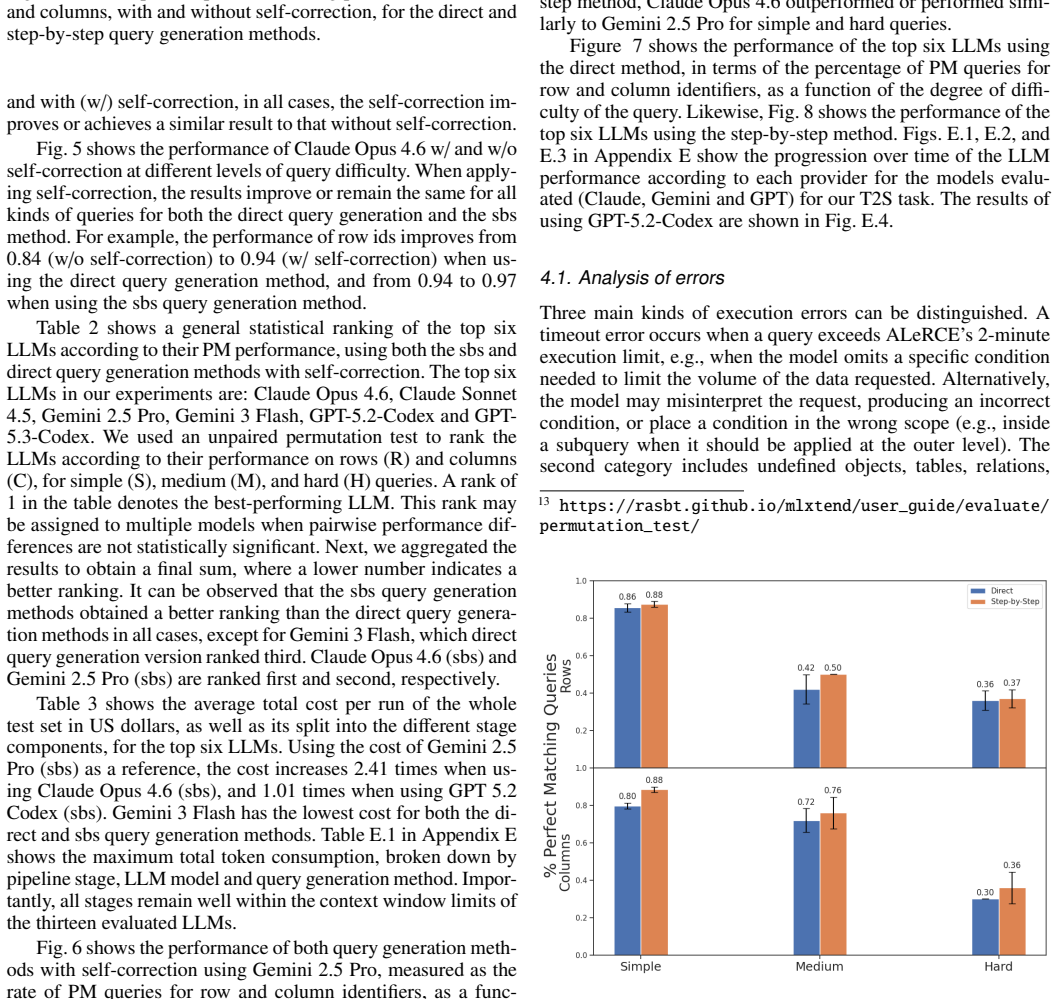
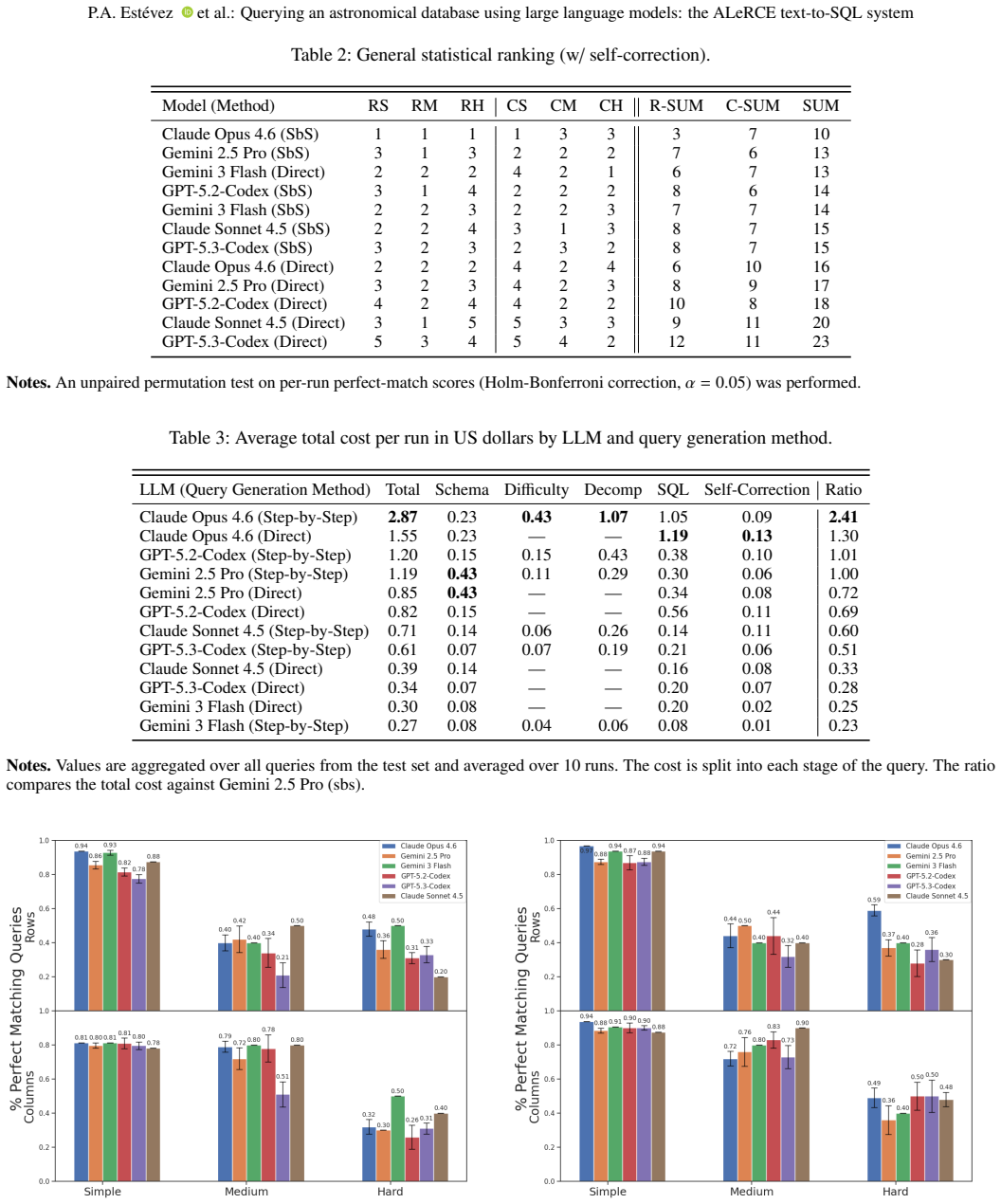
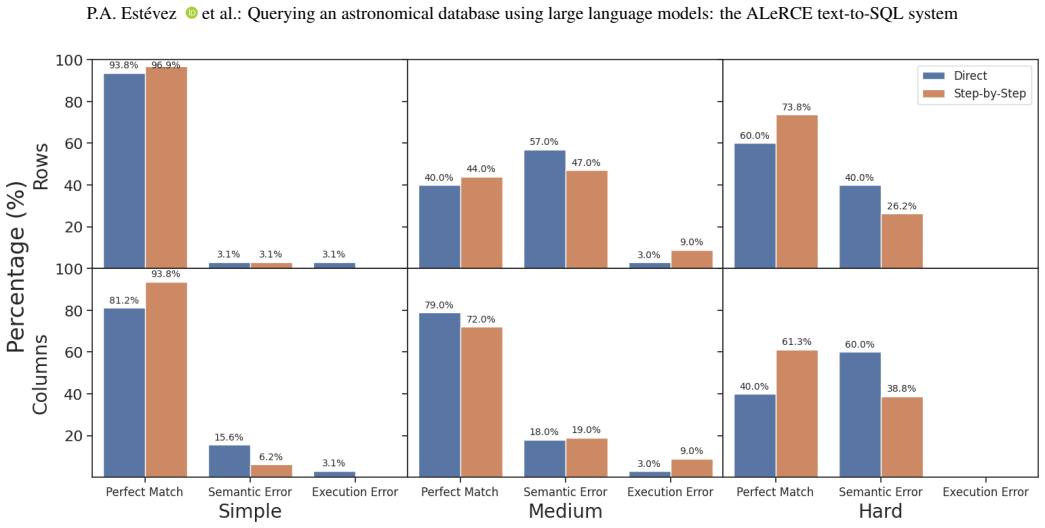
We develop a text-to-SQL (structured query language) system based on large language models (LLMs) using in-context learning and apply it to the Automatic Learning for the Rapid Classification of Events (ALeRCE) astronomical database. ALeRCE is a community broker for the Zwicky Transient Facility and the Vera C. Rubin Observatory. The system enables users to query the database in natural language (NL) and generates executable SQL queries. To develop and evaluate the system, we constructed a dataset of 110 NL/SQL pairs. We propose a step-by-step generation framework comprising four modules: schema linking, query classification, prompt decomposition, and self-correction. The performance of thirteen LLMs is evaluated using in-context learning and prompt engineering techniques. Text-to-SQL performance is assessed using the perfect-match (PM) rate for row identifiers (e.g., object identifiers) and column identifiers (i.e., column names). The proposed step-by-step framework consistently outperforms a direct-inference baseline, while the self-correction module consistently reduces execution errors. For Claude Opus 4.6, PM performance on row (column) identifiers is high for simple queries, reaching 0.97 (0.94), and decreases with query complexity to 0.44 (0.72) for medium queries and 0.59 (0.49) for hard queries. Among the thirteen evaluated models, the best-performing LLMs for the text-to-SQL task are Claude Opus 4.6, Gemini 2.5 Pro, Gemini 3 Flash, and GPT-5.2-Codex.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a text-to-SQL system for the ALeRCE astronomical database using LLMs and in-context learning. It introduces a step-by-step framework with four modules (schema linking, query classification, prompt decomposition, and self-correction) and evaluates thirteen LLMs on a hand-constructed set of 110 NL/SQL pairs. The framework is reported to outperform a direct-inference baseline, with self-correction reducing execution errors; perfect-match rates on row and column identifiers are given for simple/medium/hard queries, with Claude Opus 4.6, Gemini 2.5 Pro, Gemini 3 Flash, and GPT-5.2-Codex identified as the strongest models.
Significance. If the 110-pair evaluation set is shown to be representative of real ALeRCE user queries, the work would provide a practical demonstration of LLM-based natural-language access to an astronomical broker database, together with an empirical comparison of prompting strategies and the utility of modular decomposition plus self-correction. The multi-model evaluation and concrete PM metrics on row/column identifiers constitute a useful domain-specific benchmark.
major comments (1)
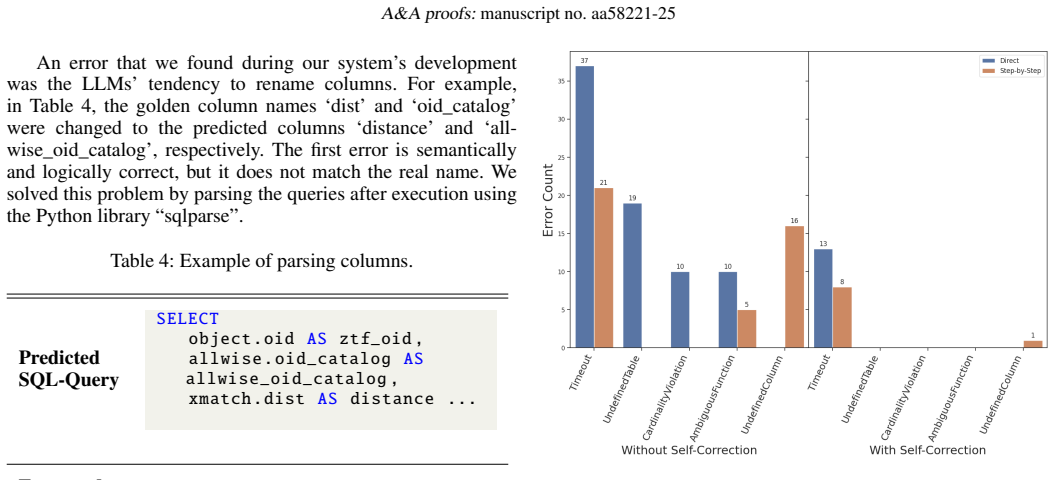
- [Dataset construction and evaluation (abstract and methods)] The central performance claims (step-by-step framework outperforming direct inference; self-correction reducing errors; PM rates of 0.97/0.94 on simple queries falling to 0.44/0.72 on medium queries) rest entirely on the 110 hand-constructed NL/SQL pairs stratified by complexity. The manuscript describes the set only as “hand-constructed” and supplies no construction protocol, expert-validation procedure, comparison to actual ALeRCE query logs, or diversity statistics. Because the generalization statements across complexity levels depend on this set being representative, the missing details are load-bearing.
minor comments (2)
- [Evaluation metrics] The perfect-match metric is defined on row and column identifiers; a brief explicit statement of how ties or partial matches are scored would improve clarity.
- Consider releasing the 110 NL/SQL pairs (with their complexity labels) as supplementary material to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The single major comment concerns the description of the evaluation dataset; we address it directly below and will revise the manuscript to incorporate additional information.
read point-by-point responses
-
Referee: [Dataset construction and evaluation (abstract and methods)] The central performance claims (step-by-step framework outperforming direct inference; self-correction reducing errors; PM rates of 0.97/0.94 on simple queries falling to 0.44/0.72 on medium queries) rest entirely on the 110 hand-constructed NL/SQL pairs stratified by complexity. The manuscript describes the set only as “hand-constructed” and supplies no construction protocol, expert-validation procedure, comparison to actual ALeRCE query logs, or diversity statistics. Because the generalization statements across complexity levels depend on this set being representative, the missing details are load-bearing.
Authors: We agree that the current manuscript provides insufficient detail on how the 110 NL/SQL pairs were assembled. The pairs were produced by the authors (who have direct experience with the ALeRCE schema and typical broker queries) and were stratified a priori into simple/medium/hard categories according to the number of tables joined, the presence of aggregations or sub-queries, and the number of filtering conditions. Each pair was manually verified for syntactic correctness and semantic alignment with the natural-language intent. To make these steps explicit and allow readers to judge representativeness, we will add a dedicated subsection (approximately one page) to the Methods section that (i) states the stratification criteria with examples, (ii) describes the validation procedure, and (iii) reports basic diversity statistics (distribution of tables used, average number of columns selected, fraction of queries involving joins or aggregations). A direct comparison against live ALeRCE query logs is not feasible for privacy reasons, but the added description will clarify the design choices that were intended to reflect realistic astronomical use cases. revision: yes
Circularity Check
No circularity: purely empirical evaluation on fixed test set
full rationale
The paper reports an empirical comparison of LLM prompting strategies (step-by-step framework vs. direct inference, with/without self-correction) on a fixed collection of 110 author-constructed NL/SQL pairs. No equations, fitted parameters, uniqueness theorems, or ansatzes appear; performance numbers (PM rates stratified by simple/medium/hard) are direct measurements on the supplied test set rather than outputs derived from the same inputs. Self-citations are absent from the load-bearing claims. The work is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
How to Prompt
Shuaichen Chang and Eric Fosler-Lussier , booktitle=. How to Prompt. 2023 , url=
2023
-
[2]
Frontiers of Computer Science , author =
A. Frontiers of Computer Science , author =. 2026 , pages =. doi:10.1007/s11704-026-60308-3 , abstract =
-
[3]
Proceedings of the 36th International Conference on Neural Information Processing Systems , journal=
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , journal=. 2022 , isbn =
2022
-
[4]
Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and Zhang, Zilin and Radev, Dragomir. S pider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to- SQL Task. Proceedings of the 2018 Conference on Empirical...
-
[5]
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-
Shuaichen Chang and Jun Wang and Mingwen Dong and Lin Pan and Henghui Zhu and Alexander Hanbo Li and Wuwei Lan and Sheng Zhang and Jiarong Jiang and Joseph Lilien and Steve Ash and William Yang Wang and Zhiguo Wang and Vittorio Castelli and Patrick Ng and Bing Xiang , booktitle=. Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-. 2023 , url=
2023
-
[6]
Semantic Evaluation for Text-to- SQL with Distilled Test Suites
Zhong, Ruiqi and Yu, Tao and Klein, Dan. Semantic Evaluation for Text-to- SQL with Distilled Test Suites. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.29
-
[7]
Alert classification for the ALeRCE broker system: The light curve classifier , author=. , volume=. doi:10.3847/1538-3881/abd5c1 , year=
-
[8]
, volume=
The automatic learning for the rapid classification of events (ALeRCE) alert broker , author=. , volume=. 2021 , publisher=
2021
-
[9]
, volume=
Alert classification for the ALeRCE broker system: the real-time stamp classifier , author=. , volume=. 2021 , publisher=
2021
-
[10]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[11]
Structured chain-of-thought prompting for code generation , author=. ACM Trans. Softw. Eng. Methodol. , volume=. 2025 , issue_date =. doi:10.1145/3690635 , abstract =
-
[12]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Enhancing zero-shot chain-of-thought reasoning in large language models through logic , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[13]
ArXiv e-prints , archivePrefix = "arXiv", eprint =
Divide and Prompt: Chain of Thought Prompting for Text-to-SQL , author=. ArXiv e-prints , archivePrefix = "arXiv", eprint =
-
[14]
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , url =
Pourreza, Mohammadreza and Rafiei, Davood , booktitle =. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , url =. 2023 , articleno =
2023
-
[15]
and Huang, Fei and Cheng, Reynold and Li, Yongbin , journal=
Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Ma, Chenhao and Li, Guoliang and Chang, Kevin C.C. and Huang, Fei and Cheng, Reynold and Li, Yongbin , journal=. Can. Proceedings of the 37th International Conference on Neural Information...
-
[16]
Michael W. Coughlin and Joshua S. Bloom and Guy Nir and Sarah Antier and Theophile Jegou du Laz and St. A Data Science Platform to Enable Time-domain Astronomy , journal =. doi:10.3847/1538-4365/acdee1 , url =
-
[17]
Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy , author=. 2023 , journal =. 2306.11648 , archivePrefix=
arXiv 2023
-
[18]
Galaxies , volume=
Language models for multimessenger astronomy , author=. Galaxies , volume=. 2023 , url =
2023
-
[19]
ArXiv e-prints , archivePrefix = "arXiv", eprint =
A survey on text-to-sql parsing: Concepts, methods, and future directions , author=. ArXiv e-prints , archivePrefix = "arXiv", eprint =
-
[20]
Astro-mT5: Entity Extraction from Astrophysics Literature using mT5 Language Model , author =. Proceedings of the first Workshop on Information Extraction from Scientific Publications , month = nov, year =. doi:10.18653/v1/2022.wiesp-1.12
-
[21]
Gao, Dawei and Wang, Haibin and Li, Yaliang and Sun, Xiuyu and Qian, Yichen and Ding, Bolin and Zhou, Jingren , title =. Proc. VLDB Endow. , month =. 2024 , issue_date =. doi:10.14778/3641204.3641221 , abstract =
-
[22]
Zhang, Yi and Deriu, Jan and Katsogiannis-Meimarakis, George and Kosten, Catherine and Koutrika, Georgia and Stockinger, Kurt , title =. Proc. VLDB Endow. , month =. 2023 , issue_date =. doi:10.14778/3636218.3636225 , abstract =
-
[23]
A survey on deep learning approaches for text-to-SQL , author=. The VLDB Journal , pages=. 2023 , issue_date =. doi:10.1007/s00778-022-00776-8 , keywords =
-
[24]
ArXiv e-prints , archivePrefix = "arXiv", eprint =
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications , author=. ArXiv e-prints , archivePrefix = "arXiv", eprint =. 2024 , url=
2024
-
[25]
Findings of the Association for Computational Linguistics: EMNLP 2023
LogiCoT: Logical Chain-of-Thought Instruction Tuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023 , url=. doi:10.18653/v1/2023.findings-emnlp.191
-
[26]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Mac-sql: A multi-agent collaborative framework for text-to-sql , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[27]
ArXiv e-prints , archivePrefix = "arXiv", eprint =
C3: Zero-shot text-to-sql with chatgpt , author=. ArXiv e-prints , archivePrefix = "arXiv", eprint =
-
[28]
Proceedings of the 31st International Conference on Computational Linguistics
Mcs-sql: Leveraging multiple prompts and multiple-choice selection for text-to-sql generation , author=. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[29]
2024 , eprint=
CHESS: Contextual Harnessing for Efficient SQL Synthesis , author=. 2024 , eprint=
2024
-
[30]
Astronomical Data Analysis Software and Systems XXXI , pages =
Building astroBERT, a language model for astronomy & astrophysics , author=. Astronomical Data Analysis Software and Systems XXXI , pages =
-
[31]
Proceedings of the Second Workshop on Information Extraction from Scientific Publications
Astrollama: Towards specialized foundation models in astronomy , author = "Nguyen, Tuan Dung and Ting, Yuan-Sen and Ciuca, Ioana and O. Proceedings of the Second Workshop on Information Extraction from Scientific Publications. doi:10.18653/v1/2023.wiesp-1.7
-
[32]
Research Notes of the AAS , volume=
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets , author =. Research Notes of the AAS , volume=. doi:10.3847/2515-5172/ad1abe , month = jan, year=
-
[33]
Evgeny A. Smirnov , title =. , abstract =. 2024 , month =. doi:10.3847/1538-4357/ad3ae1 , url =
-
[34]
Research in Astronomy and Astrophysics , abstract =
Wujun Shao and Rui Zhang and Pengli Ji and Dongwei Fan and Yaohua Hu and Xiaoran Yan and Chenzhou Cui and Yihan Tao and Linying Mi and Lang Chen , title =. Research in Astronomy and Astrophysics , abstract =. 2024 , month =. doi:10.1088/1674-4527/ad3d15 , url =
-
[35]
, volume=
pathfinder: A semantic framework for literature review and knowledge discovery in astronomy , author =. , volume=. 2024 , month = nov, publisher =
2024
-
[36]
The Eleventh International Conference on Learning Representations , year=
Decomposed Prompting: A Modular Approach for Solving Complex Tasks , author=. The Eleventh International Conference on Learning Representations , year=
-
[37]
The Eleventh International Conference on Learning Representations , year=
Least-to-most prompting enables complex reasoning in large language models , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
, volume=
The Zwicky Transient Facility: system overview, performance, and first results , author=. , volume=. 2019 , publisher=
2019
-
[39]
, volume=
LSST: from science drivers to reference design and anticipated data products , author=. , volume=. 2019 , publisher=
2019
-
[40]
ArXiv e-prints , archivePrefix = "arXiv", eprint =
ReplicationBench: Can AI Agents Replicate Astrophysics Research Papers? , author=. ArXiv e-prints , archivePrefix = "arXiv", eprint =
-
[41]
Advances in Neural Information Processing Systems , booktitle=
Astrovisbench: A code benchmark for scientific computing and visualization in astronomy , author=. Advances in Neural Information Processing Systems , booktitle=. 2026 , url=
2026
-
[42]
A search for gravitationally lensed supernovae within the Zwicky transient facility public survey , author=. , volume=. 2023 , issn =. doi:10.1093/mnras/stad2263 , publisher=
-
[43]
2023, ApJ, 955, 46, doi: 10.3847/1538-4357/acefbc
The search for thermonuclear transients from the tidal disruption of a white dwarf by an intermediate-mass black hole , author=. , volume=. 2023 , url =. doi:10.3847/1538-4357/acefbc , publisher=
-
[44]
The multiwavelength context of delayed radio emission in tidal disruption events: evidence for accretion-driven outflows , author=. , volume=. 2026 , url =. doi:10.3847/1538-4357/ae40ab , publisher=
-
[45]
Analyzing Type Ia supernovae near-infrared light curves with principal component analysis , author=. , volume=. 2025 , url =. doi:10.1051/0004-6361/202555078 , publisher=
-
[46]
A search for intermediate-mass black holes in compact stellar systems through optical emissions from tidal disruption events , author=. , volume=. 2024 , issn =. doi:10.1093/mnras/stae960 , publisher=
-
[47]
A search for extragalactic fast optical transients in the Tomo-e Gozen high-cadence survey , author=. , volume=. 2024 , issn =. doi:10.1093/mnras/stad3184 , publisher=
-
[48]
, volume=
Confirming new changing-look AGNs discovered through optical variability using a random forest-based light-curve classifier , author=. , volume=. 2022 , publisher=
2022
-
[49]
, volume=
A newborn active galactic nucleus in a star-forming galaxy , author=. , volume=. 2024 , publisher=
2024
-
[50]
, volume=
Searching for Supernovae in HETDEX Data Release 3 , author=. , volume=. 2023 , publisher=
2023
-
[51]
What makes good in-context examples for GPT-3? , author=. Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd workshop on knowledge extraction and integration for deep learning architectures , pages=. doi:10.18653/v1/2022.deelio-1.10
-
[52]
Guo, Chunxi and Tian, Zhiliang and Tang, Jintao and Wang, Pancheng and Wen, Zhihua and Yang, Kang and Wang, Ting , title =. 20th Pacific Rim International Conference on Artificial Intelligence, PRICAI, Proceedings, Part II , pages =. 2023 , isbn =. doi:10.1007/978-981-99-7022-3_23 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.