Beyond Prediction: Tail-Aware Scheduling for LLM Inference
Pith reviewed 2026-06-27 00:58 UTC · model grok-4.3
The pith
A prediction-free scheduler using statistical signals cuts P99 TTLT up to 50 percent versus perfect-knowledge SRPT in LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
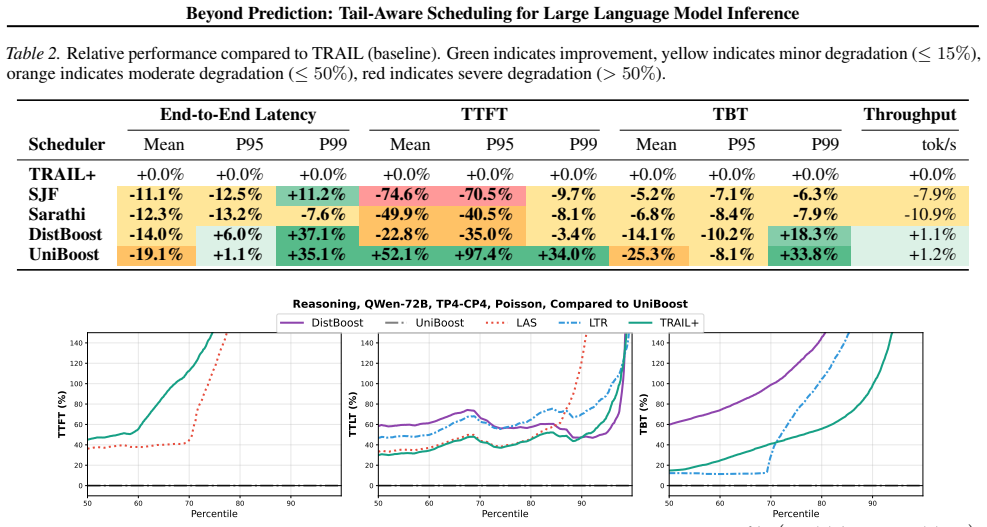
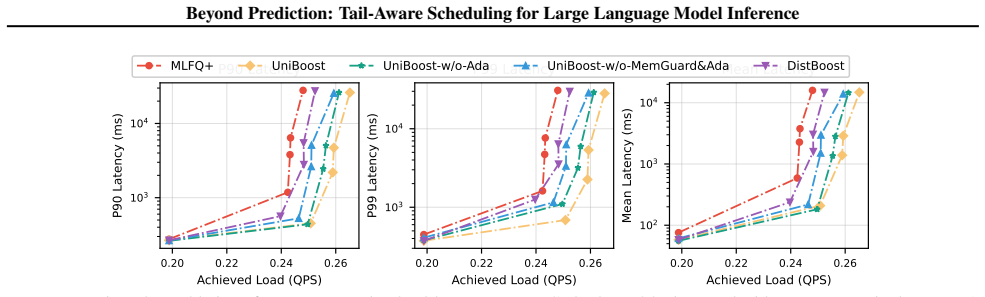
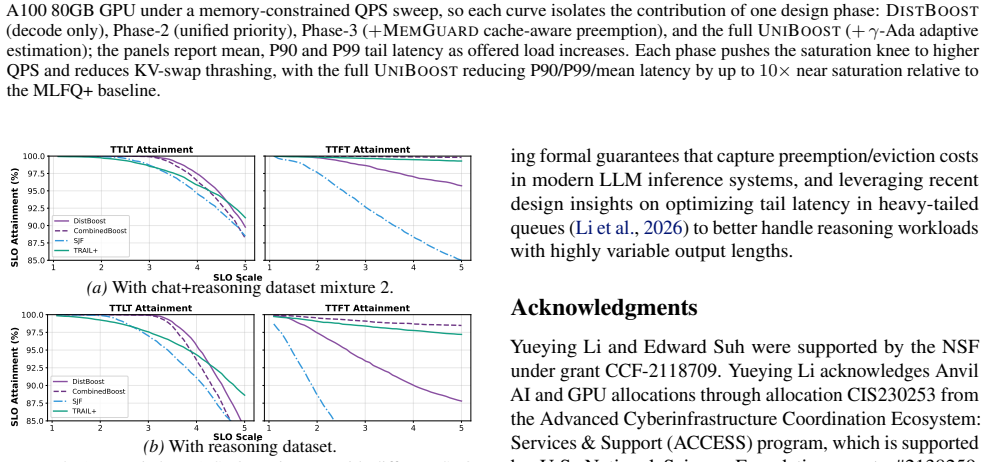
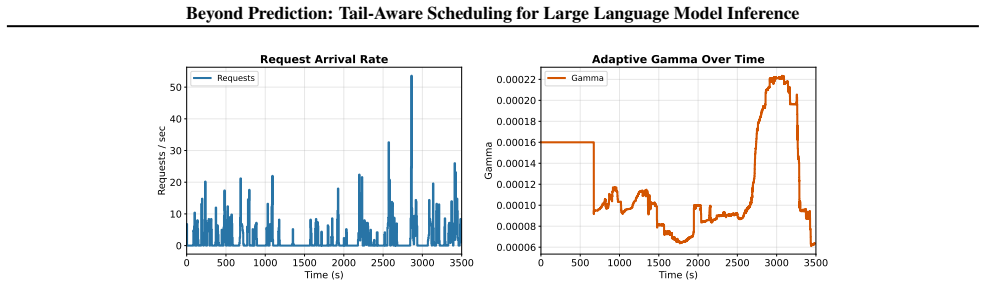
By replacing explicit length prediction with distribution-aware soft priority boosting from lightweight statistical signals and co-optimizing scheduling with cache-aware preemption to account for memory-coupled decode dynamics across workload mixes, the framework reduces P99 TTLT by up to 35-50 percent relative to SRPT even with perfect length knowledge and reduces TTFT by 34-47 percent across workloads including reasoning-heavy and chat-heavy tasks.
What carries the argument
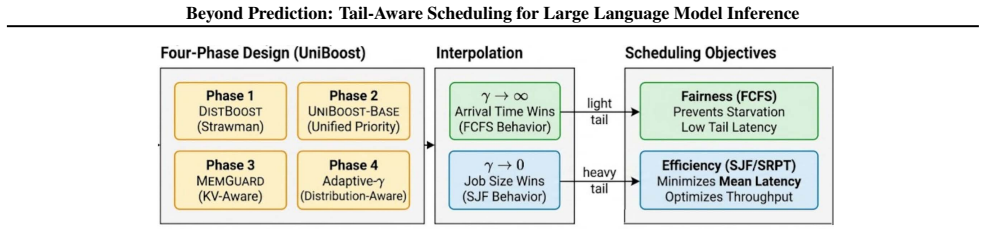
The distribution-aware, prediction-free scheduling framework that replaces explicit length prediction with soft priority boosting driven by lightweight statistical signals and co-optimizes it with cache-aware preemption.
If this is right
- The method delivers superior tail control compared with length-based policies even when those policies have oracle knowledge.
- It maintains robustness under bursty arrivals, distribution shifts, and GPU memory pressure where prediction-driven approaches degrade.
- It produces gains on both production traces and open-source traces for mixed reasoning and chat workloads.
- It achieves these results without requiring accurate decode-length predictions or additional tuning steps.
Where Pith is reading between the lines
- The design could reduce the operational burden of maintaining accurate length predictors in production LLM deployments.
- Similar statistical-signal approaches might apply to other high-variability request serving systems outside LLMs.
- The preemption and priority mechanism could be combined with existing memory-management techniques to further improve throughput under load.
Load-bearing premise
Lightweight statistical signals combined with cache-aware preemption can robustly handle memory-coupled decode dynamics and distribution shifts without explicit length modeling or post-hoc tuning.
What would settle it
A workload exhibiting a strong unmodeled distribution shift where P99 TTLT shows no improvement or worsens relative to perfect-knowledge SRPT would falsify the central claim.
Figures


read the original abstract
LLM serving exhibits extreme length variability, making size-based scheduling difficult in practice. Recent LLM schedulers approximate SJF/SRPT using predicted decode lengths or ranks and primarily report mean-centric metrics such as TTFT and TBT. We show that these prediction-driven policies can be fragile under distribution shifts, bursty arrivals, and GPU memory pressure, while offering limited control over the tail latency (P90-P99) that dominates user experience, even with perfect decode-length knowledge. We introduce a distribution-aware, prediction-free scheduling framework that replaces explicit length prediction with soft priority boosting driven by lightweight statistical signals. Our design co-optimizes scheduling and cache-aware preemption to account for memory-coupled decode dynamics across workload mixes. Evaluated on production and open-source traces, our method reduces P99 TTLT by up to 35-50% relative to SRPT with perfect length knowledge and reduces TTFT by 34-47% across workloads, including reasoning-heavy and chat-heavy tasks. These results demonstrate a robust alternative for optimizing tail latency in online LLM serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prediction-driven LLM schedulers (approximating SJF/SRPT via decode-length predictions) are fragile under distribution shifts and memory pressure and provide limited tail control; it introduces a prediction-free framework that uses lightweight statistical signals for soft priority boosting, co-optimized with cache-aware preemption to handle memory-coupled decode dynamics. On production and open-source traces (reasoning-heavy and chat-heavy workloads), the method reportedly reduces P99 TTLT by 35-50% versus SRPT even with perfect length knowledge and TTFT by 34-47%.
Significance. If the central empirical claim holds after baseline clarification, the result would be significant for LLM serving systems: it demonstrates that statistical signals plus co-optimized preemption can outperform even oracle length information on tail metrics (P99 TTLT) while remaining robust to shifts, offering a practical alternative to prediction-heavy designs. The evaluation on both production and open-source traces is a strength.
major comments (2)
- [Evaluation section] Evaluation section (and any associated appendix on baselines): the SRPT baseline is presented as having 'perfect length knowledge,' yet the manuscript does not explicitly state whether this baseline incorporates the identical cache-aware preemption logic that the proposed framework co-optimizes with scheduling. Because the abstract and design description tie the reported 35-50% P99 TTLT gains to the combination of statistical signals and preemption, an inequivalent SRPT implementation would make the gains attributable to preemption rather than the prediction-free policy, directly undermining the central claim of superiority over prediction-driven SRPT.
- [Experimental setup] § on experimental setup: workload definitions, arrival patterns, and GPU memory pressure conditions are referenced but lack sufficient detail (e.g., exact trace statistics, burst parameters, or memory occupancy thresholds) to allow reproduction or to confirm that the reported gains are not sensitive to post-hoc tuning of the statistical signals.
minor comments (2)
- [Abstract] Abstract and results tables: report error bars or confidence intervals on the 35-50% and 34-47% figures; without them the magnitude of improvement is difficult to assess against workload variability.
- [Design section] Notation for statistical signals (e.g., any equations defining the soft priority boosting) should be introduced with explicit definitions before use in the design section to improve readability.
Simulated Author's Rebuttal
Thank you for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity on baselines and reproducibility of the experimental setup.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and any associated appendix on baselines): the SRPT baseline is presented as having 'perfect length knowledge,' yet the manuscript does not explicitly state whether this baseline incorporates the identical cache-aware preemption logic that the proposed framework co-optimizes with scheduling. Because the abstract and design description tie the reported 35-50% P99 TTLT gains to the combination of statistical signals and preemption, an inequivalent SRPT implementation would make the gains attributable to preemption rather than the prediction-free policy, directly undermining the central claim of superiority over prediction-driven SRPT.
Authors: We agree that explicit confirmation of baseline equivalence is required to substantiate the central claim. The SRPT baseline was implemented using the identical cache-aware preemption logic co-optimized in our framework. We will revise the evaluation section (and appendix if present) to state this explicitly, ensuring the P99 TTLT gains are attributed to the prediction-free statistical signals rather than preemption differences. revision: yes
-
Referee: [Experimental setup] § on experimental setup: workload definitions, arrival patterns, and GPU memory pressure conditions are referenced but lack sufficient detail (e.g., exact trace statistics, burst parameters, or memory occupancy thresholds) to allow reproduction or to confirm that the reported gains are not sensitive to post-hoc tuning of the statistical signals.
Authors: We agree that additional detail is needed for reproducibility. We will expand the experimental setup section to include exact trace statistics, arrival patterns, burst parameters, and the specific GPU memory occupancy thresholds and pressure conditions used. revision: yes
Circularity Check
No circularity; empirical comparisons to external baselines
full rationale
The paper presents an empirical systems contribution: a prediction-free scheduler evaluated against SRPT (with oracle length knowledge) and other baselines on production traces. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The central claims rest on measured latency reductions rather than any quantity defined in terms of itself or reduced to prior author work by construction. The skeptic concern about baseline preemption implementation is a potential fairness issue in experimental design, not a circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Operations Research , volume=
When Does the Gittins Policy Have Asymptotically Optimal Response Time Tail in the M/G/1? , author=. Operations Research , volume=. 2025 , publisher=
2025
-
[2]
Operations research , volume=
Is tail-optimal scheduling possible? , author=. Operations research , volume=. 2012 , publisher=
2012
-
[3]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
A Tale of Two Traffics: Optimizing Tail Latency in the Light-Tailed M/G/k , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2025 , publisher=
2025
-
[4]
SPLIT: SymPathy for Large jobs Improves Tail latency
SPLIT: SymPathy for Large jobs Improves Tail latency , author=. arXiv preprint arXiv:2605.13749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Throughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents
Throughput-optimal scheduling algorithms for llm inference and ai agents , author=. arXiv preprint arXiv:2504.07347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advances in Neural Information Processing Systems , volume=
Tail-Optimized Caching for LLM Inference , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Annals of Operations Research , volume=
Queues with equally heavy sojourn time and service requirement distributions , author=. Annals of Operations Research , volume=. 2002 , publisher=
2002
-
[8]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
A Gittins policy for optimizing tail latency , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2025 , publisher=
2025
-
[9]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
Strongly tail-optimal scheduling in the light-tailed M/G/1 , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2024 , publisher=
2024
-
[10]
Operations Research , year=
Tail Optimality and Performance Analysis of the Nudge*(M) Scheduling Algorithm , author=. Operations Research , year=
-
[11]
Performance Evaluation , pages=
-CounterBoost: Optimizing response time tails using job type information only , author=. Performance Evaluation , pages=. 2025 , publisher=
2025
-
[12]
and Urvoy-Keller, Guillaume and Biersack, Ernst W
Rai, Idris A. and Urvoy-Keller, Guillaume and Biersack, Ernst W. , title =. Proceedings of the 2003 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems , pages =. 2003 , isbn =. doi:10.1145/781027.781055 , abstract =
-
[13]
and Urvoy-Keller, Guillaume and Biersack, Ernst W
Rai, Idris A. and Urvoy-Keller, Guillaume and Biersack, Ernst W. , title =. SIGMETRICS Perform. Eval. Rev. , month = jun, pages =. 2003 , issue_date =. doi:10.1145/885651.781055 , abstract =
-
[14]
arXiv preprint arXiv:2410.01035 , year=
Don't Stop Me Now: Embedding Based Scheduling for LLMs , author=. arXiv preprint arXiv:2410.01035 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Efficient llm scheduling by learning to rank , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Taming throughput-latency tradeoff in llm inference with sarathi-serve , author=. arXiv preprint arXiv:2403.02310 , year=
-
[17]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
Fairness in serving large language models , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[18]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , pages=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , pages=
-
[19]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
Characterizing policies with optimal response time tails under heavy-tailed job sizes , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2020 , publisher=
2020
-
[20]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
SOAP: One clean analysis of all age-based scheduling policies , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2018 , publisher=
2018
-
[21]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Abhyankar, Reyna and He, Zijian and Srivatsa, Vikranth and Zhang, Hao and Zhang, Yiying , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[22]
2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=
Libpreemptible: Enabling fast, adaptive, and hardware-assisted user-space scheduling , author=. 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=. 2024 , organization=
2024
-
[23]
Shinjuku: Preemptive Scheduling for µsecond-scale Tail Latency Shinjuku: Preemptive Scheduling for µsecond-scale Tail Latency , url =
Kostis Kaffes and Timothy Chong and Jack Tigar Humphries and David Mazires and Christos Kozyrakis and Adam Belay and David Maz. Shinjuku: Preemptive Scheduling for µsecond-scale Tail Latency Shinjuku: Preemptive Scheduling for µsecond-scale Tail Latency , url =. 2019 , Bdsk-Url-1 =
2019
-
[24]
Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI '19)
Amy Ousterhout and Joshua Fried and Jonathan Behrens and Adam Belay and Hari Balakrishnan , isbn =. Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI '19). , title =. 2019 , Bdsk-Url-1 =
2019
-
[25]
Symbolic execution for software testing: Three decades later,
Jeffrey Dean and Luiz Andr. The tail at scale , volume =. Communications of the ACM , month =. 2013 , Bdsk-Url-1 =. doi:10.1145/2408776.2408794 , issn =
-
[26]
Introducing ChatGPT , howpublished =
OpenAI , month =. Introducing ChatGPT , howpublished =
-
[27]
, howpublished =
ShareGPT Team , year =. , howpublished =
-
[28]
Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
Tail-Optimized Caching for LLM Inference , author =. Advances in Neural Information Processing Systems (NeurIPS 2025) , year =
2025
-
[29]
Fast Distributed Inference Serving for Large Language Models
Fast distributed inference serving for large language models , author=. arXiv preprint arXiv:2305.05920 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19) , pages=
Shinjuku: Preemptive Scheduling for \ second-scale \ Tail Latency , author=. 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19) , pages=
-
[31]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
Orca: A distributed serving system for \ Transformer-Based \ generative models , author=. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
-
[32]
Advances in Neural Information Processing Systems , volume=
S^3 : Increasing GPU Utilization during Generative Inference for Higher Throughput , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Response length perception and sequence scheduling: An llm-empowered llm inference pipeline , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
DistServe: Disaggregating Prefill and Decoding for Goodput- optimized Large Language Model Serving
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving , author=. arXiv preprint arXiv:2401.09670 , year=
-
[35]
arXiv preprint arXiv:2311.18677 , year=
Splitwise: Efficient generative llm inference using phase splitting , author=. arXiv preprint arXiv:2311.18677 , year=
-
[36]
arXiv preprint arXiv:2404.09526 , year=
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism , author=. arXiv preprint arXiv:2404.09526 , year=
-
[37]
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline , url =
Zheng, Zangwei and Ren, Xiaozhe and Xue, Fuzhao and Luo, Yang and Jiang, Xin and You, Yang , booktitle =. Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline , url =
-
[38]
arXiv preprint arXiv:2406.04785 , year=
Enabling Efficient Batch Serving for LMaaS via Generation Length Prediction , author=. arXiv preprint arXiv:2406.04785 , year=
-
[39]
arXiv preprint arXiv:2404.08509 , year=
Efficient interactive LLM serving with proxy model-based sequence length prediction , author=. arXiv preprint arXiv:2404.08509 , year=
-
[40]
arXiv preprint arXiv:2404.16283 , year=
Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services , author=. arXiv preprint arXiv:2404.16283 , year=
-
[41]
Jin, Yunho and Wu, Chun-Feng and Brooks, David and Wei, Gu-Yeon , journal=. S^
-
[42]
Proceedings of the 25th international conference on Machine learning , pages=
Listwise approach to learning to rank: theory and algorithm , author=. Proceedings of the 25th international conference on Machine learning , pages=
-
[43]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[44]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2110.14168 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =. 2009.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[46]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. arXiv preprint arXiv:2210.09261 , year =. 2210.09261 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =. 2107.03374 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2201.11903 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , journal =. Measuring Mathematical Problem Solving With the. 2021 , eprint =
2021
-
[50]
2019 , url =
Amini, Aida and Gabriel, Saadia and Lin, Peter and Koncel-Kedziorski, Rik and Choi, Yejin and Hajishirzi, Hannaneh , booktitle =. 2019 , url =
2019
-
[51]
Patel, Arkil and Bhattamishra, Satwik and Goyal, Navin , booktitle =. Are. 2021 , eprint =
2021
-
[52]
Think you have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal =. Think you have Solved Question Answering? Try. 2018 , eprint =
2018
-
[53]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author =. arXiv preprint arXiv:1809.02789 , year =. 1809.02789 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
, journal =
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , journal =. 2023 , eprint =
2023
-
[55]
2019 , eprint =
Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt , journal =. 2019 , eprint =
2019
-
[56]
Transactions of the Association for Computational Linguistics (TACL) , year =
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies , author =. Transactions of the Association for Computational Linguistics (TACL) , year =. 2101.02235 , archivePrefix=
-
[57]
2020 , eprint =
Liu, Jian and Cui, Leyang and Liu, Hanmeng and Huang, Dandan and Wang, Yile and Zhang, Yue , journal =. 2020 , eprint =
2020
-
[58]
2022 , month = oct, day =
Brooker, Marc , title =. 2022 , month = oct, day =
2022
-
[59]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
Nudge: Stochastically improving upon FCFS , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2021 , publisher=
2021
-
[60]
2020 , eprint =
Yu, Weihao and Jiang, Zihang and Dong, Yanfei and Feng, Jiashi , journal =. 2020 , eprint =
2020
-
[61]
Thinking Machines Lab: Connectionism , year =
Horace He and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[62]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Understanding and mitigating numerical sources of nondeterminism in llm inference , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[63]
2021 , pages =
Tafjord, Oyvind and Dalvi, Bhavana and Clark, Peter , booktitle =. 2021 , pages =
2021
-
[64]
2024 , eprint=
WildChat: 1M ChatGPT Interaction Logs in the Wild , author=. 2024 , eprint=
2024
-
[65]
2024 , eprint=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. 2024 , eprint=
2024
-
[66]
arXiv preprint arXiv:2503.22562 , year=
Niyama: Breaking the silos of llm inference serving , author=. arXiv preprint arXiv:2503.22562 , year=
-
[67]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , author =. arXiv preprint arXiv:2206.04615 , year =. 2206.04615 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
arXiv preprint arXiv:2502.13965 , year=
Autellix: An efficient serving engine for llm agents as general programs , author=. arXiv preprint arXiv:2502.13965 , year=
-
[69]
Preble: Efficient distributed prompt scheduling for LLM serving.arXiv preprint arXiv:2407.00023,
Preble: Efficient distributed prompt scheduling for llm serving , author=. arXiv preprint arXiv:2407.00023 , year=
-
[70]
Advances in Neural Information Processing Systems (NeurIPS 2025) , year=
HyGen: Efficient LLM Serving via Elastic Online-Offline Request Co-location , author=. Advances in Neural Information Processing Systems (NeurIPS 2025) , year=
2025
-
[71]
arXiv preprint arXiv:2504.20068 , year=
Tempo: Application-aware LLM Serving with Mixed SLO Requirements , author=. arXiv preprint arXiv:2504.20068 , year=
-
[72]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
Biao Sun and Ziming Huang and Hanyu Zhao and Wencong Xiao and Xinyi Zhang and Yong Li and Wei Lin , title =. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
-
[73]
and Prabhu, Ramya and Mohan, Jayashree and Peter, Simon and Ramjee, Ramachandran and Panwar, Ashish , title =
Kamath, Aditya K. and Prabhu, Ramya and Mohan, Jayashree and Peter, Simon and Ramjee, Ramachandran and Panwar, Ashish , title =. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages =. 2025 , isbn =
2025
-
[74]
2024 , editor =
Duan, Jiangfei and Lu, Runyu and Duanmu, Haojie and Li, Xiuhong and Zhang, Xingcheng and Lin, Dahua and Stoica, Ion and Zhang, Hao , booktitle =. 2024 , editor =
2024
-
[75]
2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=
Scheduling for the tail: Robustness versus Optimality , author=. 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=. 2010 , organization=
2010
-
[76]
Proceedings of the 2024 ACM Symposium on Cloud Computing , pages=
Queue management for slo-oriented large language model serving , author=. Proceedings of the 2024 ACM Symposium on Cloud Computing , pages=
2024
-
[77]
Operations Research , volume=
Preventing large sojourn times using SMART scheduling , author=. Operations Research , volume=. 2008 , publisher=
2008
-
[78]
2025 , eprint=
Kairos: Low-latency Multi-Agent Serving with Shared LLMs and Excessive Loads in the Public Cloud , author=. 2025 , eprint=
2025
-
[79]
2025 , eprint=
On Evaluating Performance of LLM Inference Serving Systems , author=. 2025 , eprint=
2025
-
[80]
2025 , eprint=
Nexus:Proactive Intra-GPU Disaggregation of Prefill and Decode in LLM Serving , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.