Multi-Modal Hyper-Graph Fusion for Low-Light Crowd Counting
Pith reviewed 2026-06-26 21:21 UTC · model grok-4.3
The pith
A hyper-graph that fuses RGB with depth and edge cues improves crowd counting under low light.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing RGB appearance, depth geometry, and edge structure as nodes inside one hyper-graph and performing dynamic hyperedge construction plus message passing, the Multi-Modal Hyper-Graph Fusion module captures complementary high-order relationships that remain usable when illumination collapses; combined with the Deformable Rectangular Sparse Attention module, this yields a Low-Light Counting Network that outperforms existing state-of-the-art approaches on the new SHA_Dark, SHB_Dark, and LC-Crowd benchmarks.
What carries the argument
Multi-Modal Hyper-Graph Fusion module that places RGB, depth, and Canny-edge features as nodes in a unified hyper-graph and uses dynamic hyperedge construction with message passing to link their high-order relationships.
If this is right
- Crowd density maps become more accurate in darkness without requiring brighter sensors.
- Computation is concentrated on informative image regions rather than uniform dark areas.
- The three new benchmarks supply standardized test data for any future low-light counting work.
- High-order cross-modal relationships can be modeled explicitly instead of through late fusion.
Where Pith is reading between the lines
- The same hyper-graph construction could be tested on other dense-prediction tasks that suffer from photometric degradation.
- If depth estimation itself degrades under low light, an alternative structural prior would be needed to keep the fusion intact.
- The benchmarks make it possible to measure whether multi-modal priors close the gap to well-lit performance.
- Sparse rectangular attention may transfer to other vision backbones that must allocate compute unevenly across an image.
Load-bearing premise
Depth maps and Canny edges remain reliable geometric and structural signals even when the scene is extremely dark and unevenly lit.
What would settle it
On the LC-Crowd real-world test set the LCNet fails to exceed the best prior method in mean absolute error or mean squared error.
Figures
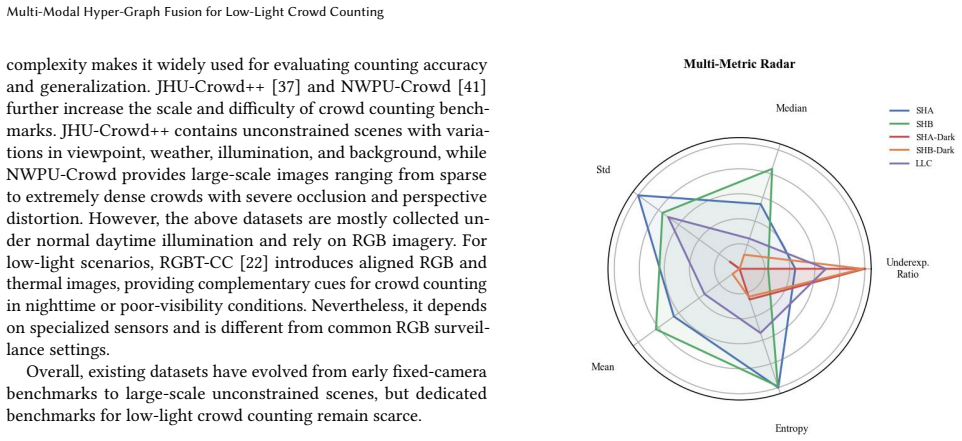

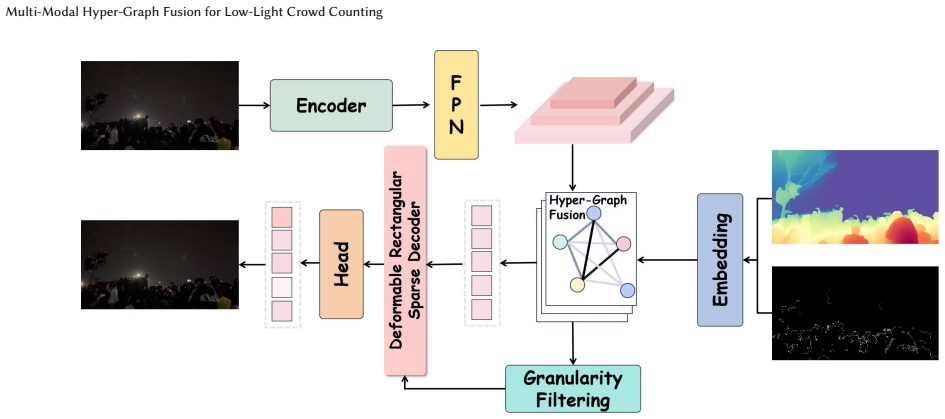
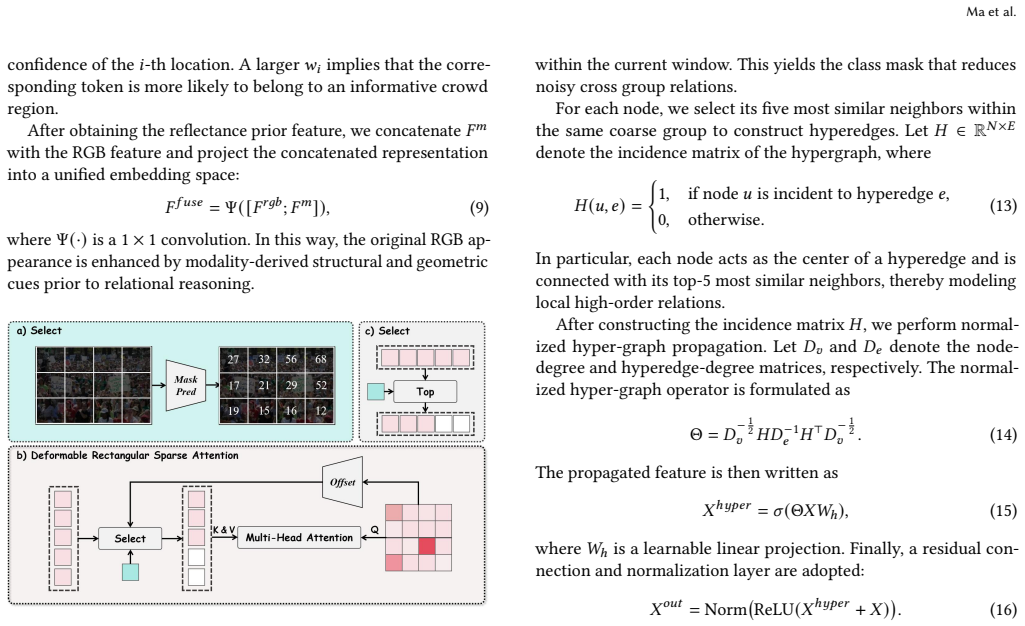
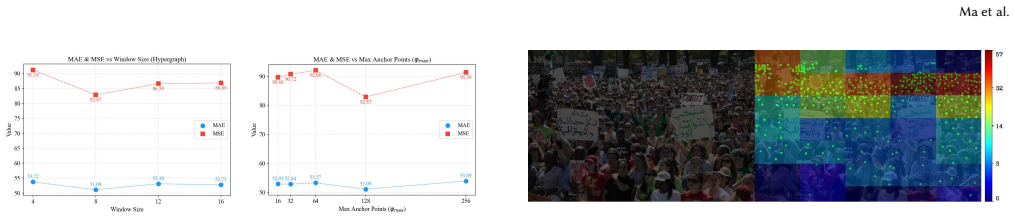

read the original abstract
Crowd counting is a fundamental task in computer vision. However, crowd counting in low-light environments remains largely underexplored, despite its practical importance in the real world. Existing methods mainly focus on well-lit scenes or rely on single-modality Red-Green-Blue (RGB) representations, which often become unreliable under extreme darkness and complex non-uniform illumination. To handle this problem, we construct three new low-light crowd counting benchmarks, which consist of two synthetic datasets, SHA\_Dark and SHB\_Dark, and a real-world benchmark LC-Crowd (Low-light Crowd Dataset). Inspired by Retinex-based physical modeling, we introduce depth and Canny edge cues as complementary geometric and structural priors to enhance the intrinsic reflectance representation under low-light conditions. We propose a Multi-Modal Hyper-Graph Fusion module, which formulates RGB appearance, depth geometry, and edge structure cues as nodes in a unified hyper-graph and explicitly captures their high-order complementary relationships via dynamic hyperedge construction and message passing. Furthermore, to adaptively allocate computation in dense prediction, we propose a Deformable Rectangular Sparse Attention (DRSA) module, which concentrates computation on informative regions through anchor-aware estimation and adaptive rectangular window modeling. Based on these designs, we develop a unified Low-Light Counting Network (LCNet) for robust low-light crowd counting. Extensive experiments on three benchmarks demonstrate that the proposed method achieves the best overall performance against existing state-of-the-art (SOTA) methods. The code is in the supplementary material. The datasets will be made public upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces three new low-light crowd counting benchmarks (SHA_Dark, SHB_Dark, and the real-world LC-Crowd) and proposes LCNet, which integrates RGB appearance with depth geometry and Canny edge structure via a Multi-Modal Hyper-Graph Fusion module (dynamic hyperedge construction and message passing) and a Deformable Rectangular Sparse Attention (DRSA) module for adaptive computation. The approach is motivated by Retinex-based physical modeling and claims state-of-the-art performance over existing methods on the three benchmarks, with code in supplementary material and datasets to be released.
Significance. If the empirical results hold with proper validation, the new benchmarks would be a useful contribution to an underexplored setting, and the hyper-graph fusion of complementary modalities could provide a principled way to handle non-uniform illumination. Explicit credit is due for the planned public release of code and datasets.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'achieves the best overall performance against existing state-of-the-art (SOTA) methods' is stated without any quantitative metrics, tables, error bars, or ablation results, preventing assessment of effect size or robustness; this is load-bearing for the empirical contribution.
- [Abstract] Abstract (Retinex-inspired modeling paragraph): the premise that depth maps and Canny edges supply reliable complementary geometric and structural priors under extreme low-light is not supported by any quantitative validation or ablation on LC-Crowd or the synthetic dark sets; standard monocular depth estimators and gradient detectors are known to degrade with low photon counts, so the hyper-graph construction's gains over RGB-only baselines remain unsubstantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript to strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'achieves the best overall performance against existing state-of-the-art (SOTA) methods' is stated without any quantitative metrics, tables, error bars, or ablation results, preventing assessment of effect size or robustness; this is load-bearing for the empirical contribution.
Authors: We agree that the abstract would benefit from quantitative support. In the revision, we will add specific metrics (e.g., MAE/MSE improvements on SHA_Dark, SHB_Dark, and LC-Crowd versus prior SOTA) and reference the main results table to allow assessment of effect size. revision: yes
-
Referee: [Abstract] Abstract (Retinex-inspired modeling paragraph): the premise that depth maps and Canny edges supply reliable complementary geometric and structural priors under extreme low-light is not supported by any quantitative validation or ablation on LC-Crowd or the synthetic dark sets; standard monocular depth estimators and gradient detectors are known to degrade with low photon counts, so the hyper-graph construction's gains over RGB-only baselines remain unsubstantiated.
Authors: The full manuscript contains modality ablation studies and RGB-only baseline comparisons demonstrating performance gains from the hyper-graph fusion on the low-light benchmarks. We will revise the abstract to explicitly reference these ablation results (in the experiments section) that substantiate the utility of the priors in practice, while acknowledging that direct per-modality reliability metrics under low photon counts are not separately reported. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and description contain no equations, derivations, or parameter-fitting steps that could reduce predictions to inputs by construction. The method is described as constructing new benchmarks and proposing modules (hyper-graph fusion, DRSA) inspired by Retinex modeling, with performance claims resting on experimental results rather than any self-referential or fitted-input logic. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming patterns appear. This is the common case of an empirical method paper whose claims are externally falsifiable via the reported benchmarks and code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retinex-based physical modeling supplies valid intrinsic reflectance priors for low-light scenes
Reference graph
Works this paper leans on
-
[1]
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang
-
[2]
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement. InICCV
-
[3]
I Chen, Wei-Ting Chen, Yu-Wei Liu, Ming-Hsuan Yang, and Sy-Yen Kuo. 2024. Improving Point-based Crowd Counting and Localization Based on Auxiliary Point Guidance.European Conference on Computer Vision (ECCV)(2024)
2024
-
[4]
Xiao-Han Chen and Jian-Huang Lai. 2019. Detecting abnormal crowd behaviors based on the div-curl characteristics of flow fields.Pattern Recognition88 (2019), 342–355
2019
-
[6]
Yongqiang Chen, Chenglin Wen, Weifeng Liu, and Wei He. 2023. A depth iterative illumination estimation network for low-light image enhancement based on retinex theory.Scientific Reports13, 1 (2023), 19709
2023
-
[7]
Zhi-Qi Cheng, Qi Dai, Hong Li, Jingkuan Song, Xiao Wu, and Alexander G Hauptmann. 2022. Rethinking Spatial Invariance of Convolutional Networks for Object Counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 19638–19648
2022
-
[8]
Xiao-Meng Duan, Hong-Mei Sun, Zeng-Min Zhang, Ling-Xiao Qin, and Rui- Sheng Jia. 2025. CMFX: Cross-modal fusion network for RGB-X crowd counting. Neural Networks184 (2025), 107070
2025
-
[9]
Camille Dupont, Luis Tobias, and Bertrand Luvison. 2017. Crowd-11: A dataset for fine grained crowd behaviour analysis. InProceedings of the IEEE conference on computer vision and pattern recognition workshops (ICCVW). 9–16
2017
-
[10]
Chunle Guo Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. 2020. Zero-reference deep curve estimation for low-light image enhancement. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 1780–1789
2020
-
[11]
Xiaojie Guo, Yu Li, and Haibin Ling. 2017. LIME: Low-Light Image Enhancement via Illumination Map Estimation.IEEE Transactions on Image Processing26, 2 (2017), 982–993
2017
-
[12]
Tao Han and etc. 2023. STEERER: Resolving Scale Variations for Counting and Localization via Selective Inheritance Learning.IEEE/CVF International Conference on Computer Vision (ICCV)(2023)
2023
-
[13]
Zhi-Kai Huang, Wei-Ting Chen, Yuan-Chun Chiang, Sy-Yen Kuo, and Ming- Hsuan Yang. 2023. Counting Crowds in Bad Weather. InIEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[14]
Soonmin Hwang, Jaesik Park, Namil Kim, Yukyung Choi, and In So Kweon
-
[15]
InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Multispectral Pedestrian Detection: Benchmark Dataset and Baselines. InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
[16]
Jiayu Jiao, Yu-Ming Tang, Kun-Yu Lin, Yipeng Gao, Andy J Ma, Yaowei Wang, and Wei-Shi Zheng. 2023. Dilateformer: Multi-scale dilated transformer for visual recognition.IEEE transactions on multimedia (TMM)25 (2023), 8906–8919
2023
-
[17]
Kingma and Jimmy Lei Ba
Diederik P. Kingma and Jimmy Lei Ba. 2015. Adam: A Method for Stochastic Optimization. InProceedings of the International Conference on Learning Repre- sentations (ICLR)
2015
-
[18]
Harold W Kuhn. 1955. The Hungarian Method for the Assignment Problem. Naval research logistics quarterly2, 1-2 (1955), 83–97
1955
-
[19]
Edwin H Land. 1977. The retinex theory of color vision.Scientific American237, 6 (1977), 108–129
1977
-
[20]
Hyeonbeen Lee and Jangho Lee. 2024. TinyCount: an efficient crowd counting network for intelligent surveillance.Journal of Real-Time Image Processing21, 4 (2024), 153
2024
-
[21]
Yuhong Li, Xiaofan Zhang, and Deming Chen. 2018. CSRNet: Dilated Convo- lutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1091–1100. Ma et al
2018
-
[22]
Dingkang Liang, Wei Xu, and Xiang Bai. 2022. An End-to-End Transformer Model for Crowd Localization. InProceedings of the European Conference on Computer Vision (ECCV). 38–54
2022
-
[23]
Chengxin Liu, Hao Lu, Zhiguo Cao, and Tongliang Liu. 2023. Point-Query Quadtree for Crowd Counting, Localization, and More. InIEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[24]
Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, and Liang Lin
-
[25]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Cross-modal collaborative representation learning and a large-scale rgbt benchmark for crowd counting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). 4823–4833
-
[26]
Weizhe Liu, Mathieu Salzmann, and Pascal Fua. 2019. Context-Aware Crowd Counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5099–5108
2019
-
[27]
Yan-Bo Liu, Guo Cao, Boshan Shi, and Yingxiang Hu. 2024. CCANet: A Collabo- rative Cross-Modal Attention Network for RGB-D Crowd Counting.IEEE Trans. Multim.26 (2024), 154–165
2024
-
[28]
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. 2017. LLNet: A Deep Autoencoder Approach to Natural Low-light Image Enhancement.Pattern Recog- nition61 (2017), 650–662
2017
-
[29]
Chen Change Loy, Shaogang Gong, and Tao Xiang. 2013. From Semi-supervised to Transfer Counting of Crowds. In2013 IEEE International Conference on Com- puter Vision (ICCV). 2256–2263
2013
-
[30]
Hao-Yuan Ma and Li Zhang. 2024. Multi-head multi-scale pixel localization network for crowd counting with highly dense and small-scale samples. In2024 IEEE International Conference on Multimedia and Expo (ICME). 1–5
2024
-
[31]
Hao-Yuan Ma, Li Zhang, and Shuai Shi. 2024. VMambaCC: A Visual State Space Model for Crowd Counting.arXiv preprint arXiv:2405.03978(2024)
arXiv 2024
-
[32]
Hao-Yuan Ma, Li Zhang, and Xiang-Yi Wei. 2024. FGENet: Fine-Grained Ex- traction Network for Congested Crowd Counting. InProceedings of the 30th International Conference on Multimedia Modeling (MMM)
2024
-
[33]
Baoyang Mu, Feng Shao, Zhengxuan Xie, Hangwei Chen, Zhongjie Zhu, and Qiuping Jiang. 2025. MISF-Net: Modality-invariant and-specific fusion network for RGB-T crowd counting.IEEE Transactions on Multimedia27 (2025), 2593– 2607
2025
-
[34]
Baoyang Mu, Feng Shao, Zhengxuan Xie, Long Xu, and Qiuping Jiang. 2025. RGBT-Booster: Detail-boosted fusion network for RGB-thermal crowd counting with local contrastive learning.IEEE Internet of Things Journal(2025)
2025
-
[35]
Zuodong Niu, Huilong Pi, Guoqing Xiao, Shenghong Yang, Zhuo Tang, and Dazheng Liu. 2025. Low-Light Domain Enhancement and Multidomain Pro- gressive Fusion for RGB-T Day–Night Crowd Counting.IEEE Internet of Things Journal12, 20 (2025), 42533–42548
2025
-
[36]
Yi Pan, Wujie Zhou, Meixin Fang, and Fangfang Qiang. 2024. Graph enhancement and transformer aggregation network for RGB-thermal crowd counting.IEEE Geoscience and Remote Sensing Letters21 (2024), 1–5
2024
-
[37]
Yasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Ban- dara, and Vishal M. Patel. 2024. CrowdDiff: Multi-Hypothesis Crowd Density Estimation Using Diffusion Models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12809–12819
2024
-
[38]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. 2015. Faster R-CNN: To- wards Real-Time Object Detection with Region Proposal Networks. InAdvances in Neural Information Processing Systems (NIPS), Vol. 28
2015
-
[39]
Karen Simonyan and Andrew Zisserman. 2014. Very Deep Convolutional Net- works for Large-Scale Image Recognition.Computer Science(2014)
2014
-
[40]
Sindagi, Rajeev Yasarla, and Vishal M
Vishwanath A. Sindagi, Rajeev Yasarla, and Vishal M. Patel. 2022. JHU- CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method. IEEE Transactions on Pattern Analysis and Machine Intelligence(2022), 2594–2609
2022
-
[41]
Qingyu Song, Changan Wang, Zhengkai Jiang, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yang Wu. 2021. Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 3365–3374
2021
-
[42]
Qingyu Song, Changan Wang, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Jian Wu, and Jiayi Ma. 2021. To choose or to fuse? scale selection for crowd counting. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI). 2576–2583
2021
-
[43]
Haihan Tang, Yi Wang, and Lap-Pui Chau. 2022. Tafnet: A three-stream adaptive fusion network for rgb-t crowd counting. In2022 IEEE international symposium on circuits and systems (ISCAS). IEEE, 3299–3303
2022
-
[44]
Qi Wang, Junyu Gao, Wei Lin, and Xuelong Li. 2021. NWPU-Crowd: A Large- Scale Benchmark for Crowd Counting and Localization.IEEE Transactions on Pattern Analysis and Machine Intelligence43, 6 (2021), 2141–2149
2021
-
[45]
Shuyu Wang, Weiwei Wu, Yinglin Li, Yuhang Xu, and Yan Lyu. 2024. MIANet: Bridging the gap in crowd density estimation with thermal and RGB interaction. IEEE Transactions on Intelligent Transportation Systems26, 1 (2024), 254–267
2024
-
[46]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything V2. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[47]
Shihui Zhang, Kun Chen, Gangzheng Zhai, He Li, and Shaojie Han. 2025. CMPNet: A cross-modal multi-scale perception network for RGB-T crowd counting.Future Generation Computer Systems164 (2025), 107596
2025
-
[48]
Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. 2016. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 589–597
2016
-
[49]
Wujie Zhou, Yi Pan, Jingsheng Lei, Lv Ye, and Lu Yu. 2022. DEFNet: Dual-branch enhanced feature fusion network for RGB-T crowd counting.IEEE Transactions on Intelligent Transportation Systems23, 12 (2022), 24540–24549
2022
-
[50]
Feng Zhu, Xiaogang Wang, and Nenghai Yu. 2016. Crowd tracking by group struc- ture evolution.IEEE Transactions on Circuits and Systems for Video Technology 28, 3 (2016), 772–786
2016
-
[51]
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2020. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159(2020). A Evaluation Metrics To comprehensively evaluate the counting performance, we adopt three widely used metrics, namely Mean Absolute Error (MAE), Mean Squared Error (MS...
Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.