AI-Driven Assessment of Human Tutors: Linking Training Performance to Real-Life Practice
Pith reviewed 2026-06-26 19:34 UTC · model grok-4.3
The pith
Tutor training performance predicts real-life tutoring transcript scores with a 0.25 SD effect size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An AI system using Gemini-2.5-pro scores both open responses in scenario-based training lessons and transcriptions of authentic remote math tutoring. Across 405 pairs, training performance significantly predicts real-life transcript scores at an effect size of 0.25 SD. Averaging open-response and multiple-choice scores during training provides the best prediction of real performance, though open responses alone are more predictive than multiple choice. Tutors achieve a 7.4 percent average learning gain, encounter pedagogical opportunities more often (61.1 percent to 68.9 percent), and show higher execution quality within those opportunities (65.5 percent to 68.1 percent), with changes follow
What carries the argument
The AI-driven scoring system that applies Gemini-2.5-pro with fixed prompts and rubrics to rate training responses and real tutoring transcripts, then links those ratings through mixed-effects models.
If this is right
- Averaged training scores serve as the strongest single indicator of later real-life tutoring quality.
- Open-response items during training capture more transferable skill information than multiple-choice items alone.
- Post-training gains appear as increased frequency and better execution of pedagogical moves rather than an immediate jump.
- Open release of datasets, prompts, and rubrics enables direct replication and refinement of the linking method.
Where Pith is reading between the lines
- Programs could use the same AI pipeline for ongoing monitoring of tutor cohorts instead of periodic human observation.
- The approach might extend to other domains where short training exercises must predict performance in live, variable settings.
- Because the prediction holds across many session-to-lesson pairs, training platforms could triage which tutors need extra practice before live work.
Load-bearing premise
The AI model with the supplied prompts and rubrics produces scores that accurately reflect true pedagogical skill quality without systematic bias in either training or real transcripts.
What would settle it
Independent human raters scoring the same real-life transcripts find no correlation with the AI-generated scores, or training performance shows no predictive relation to transcript quality in a fresh sample of tutors.
Figures
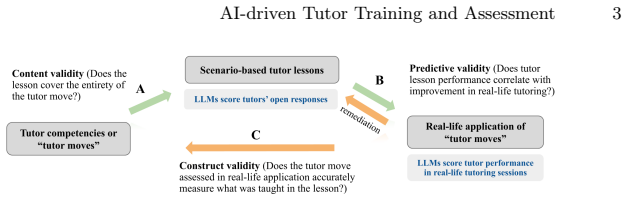


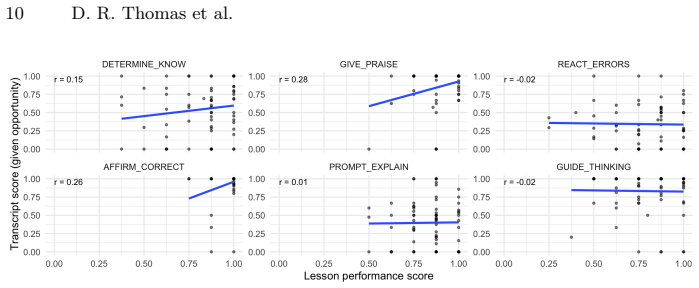
read the original abstract
There exist numerous tutor training platforms. However, few provide AI-driven training and evaluation for human tutors based on real-life performance. We present an AI-driven system that assesses both open responses during training and authentic real-life tutoring. Unlike platforms that only assess learning through online training or simulations, our system utilizes Generative AI (Gemini-2.5-pro) to analyze transcriptions of authentic tutoring, measuring the transfer of tutor skills to real-life application. Human tutors instructing students remotely in math (N=86) completed six scenario-based lessons, averaging a significant 7.4% learning gain. Using mixed-effects models across 405 session-to-lesson pairs, we found that training performance significantly predicted real-life transcript scores with an effect size of 0.25 SD. Model comparison (AIC/BIC) indicated averaging open response and multiple choice performance during training predicted real-life tutor performance best, although open responses were comparatively more predictive. Exploratory analysis showed that after training, tutors were significantly more likely to encounter pedagogical opportunities to apply their skills (61.1% to 68.9%) and demonstrated higher execution quality within those opportunities (65.5% to 68.1%). Interrupted time series analysis suggested that these tutor improvements were part of a gradual trend over time rather than an immediate intervention effect of training. We illustrate an AI-driven method to link tutor training with real-life assessment. In doing so, we contribute open datasets, AI prompts, and scoring rubrics to support transparency and reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an AI-driven assessment system that uses Gemini-2.5-pro to score open-response answers during six scenario-based tutor training lessons and to score authentic real-life tutoring transcripts. With N=86 tutors and 405 session-to-lesson pairs, it reports a 7.4% learning gain from training and, via mixed-effects models, a statistically significant prediction from training performance to real-life transcript scores (effect size 0.25 SD). Model comparison favors averaging open-response and multiple-choice training scores; exploratory interrupted time-series analyses indicate gradual increases in both the frequency of pedagogical opportunities (61.1% to 68.9%) and execution quality within them (65.5% to 68.1%). The manuscript contributes open datasets, prompts, and rubrics.
Significance. If the AI scoring is shown to be valid, the work supplies direct evidence that training performance transfers to real tutoring practice and offers a scalable, reproducible pipeline for linking the two. The explicit release of datasets, prompts, and rubrics is a concrete strength that supports transparency and future replication.
major comments (2)
- [Abstract / Methods] Abstract and Methods: the 0.25 SD effect size and all downstream claims rest entirely on Gemini-2.5-pro scores for both training responses and real-life transcripts, yet no human-AI agreement statistics, inter-rater reliability on a validation subset, or rubric-bias checks are reported. This is load-bearing for the central prediction claim.
- [Results] Results (mixed-effects models): the model specifications (random-effects structure, covariates, handling of the 405 pairs, and any data-exclusion rules) are not described, preventing assessment of whether the reported effect size is robust or sensitive to analytic choices.
minor comments (2)
- [Abstract] The abstract states that 'averaging open response and multiple choice performance' was optimal but does not specify the exact weighting or aggregation procedure.
- [Methods] Clarify how the 405 session-to-lesson pairs were constructed from the N=86 tutors and six lessons (e.g., whether all tutors contributed equally).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to improve transparency and validity reporting.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the 0.25 SD effect size and all downstream claims rest entirely on Gemini-2.5-pro scores for both training responses and real-life transcripts, yet no human-AI agreement statistics, inter-rater reliability on a validation subset, or rubric-bias checks are reported. This is load-bearing for the central prediction claim.
Authors: We agree that human validation of the AI scores is essential to support the central claims. The initial submission omitted these statistics. In the revision we will add a new subsection to Methods that describes a human-rated validation subset (approximately 20% of responses stratified by lesson and tutor), reports agreement metrics (e.g., Cohen’s κ and percentage agreement) between Gemini-2.5-pro and human raters, human inter-rater reliability, and any systematic rubric-bias checks. These additions will directly address the load-bearing concern. revision: yes
-
Referee: [Results] Results (mixed-effects models): the model specifications (random-effects structure, covariates, handling of the 405 pairs, and any data-exclusion rules) are not described, preventing assessment of whether the reported effect size is robust or sensitive to analytic choices.
Authors: We acknowledge the need for full model transparency. The models were fit with lmerTest in R using random intercepts for tutors and for the 405 session-to-lesson pairs; fixed effects included training performance (averaged open-response and multiple-choice scores), tutor experience, and lesson order. No observations were excluded beyond those with missing transcript data. In the revision we will expand the Methods section with the complete model equations, random-effects structure, covariate list, data-handling rules, and results of sensitivity checks (alternative random-effects specifications and covariate sets) to allow readers to evaluate robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claim applies standard mixed-effects regression to 405 independent session-to-lesson pairs, predicting AI-scored real-life transcript quality from separately AI-scored training performance. Training open responses and real transcripts are distinct data sources; neither is defined in terms of the other, and no equation or model fit reduces the reported 0.25 SD effect to a tautology or to a fitted parameter renamed as prediction. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to justify the link. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Mixed-effects models assume normally distributed residuals and random effects.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Ar- tificial Intelligence in Education
Aleven, V., Baraniuk, R., Brunskill, E., Crossley, S., Demszky, D., Fancsali, S., Gupta, S., Koedinger, K., Piech, C., Ritter, S., et al.: Towards the future of ai- augmented human tutoring in math learning. In: International Conference on Ar- tificial Intelligence in Education. pp. 26–31. Springer (2023)
2023
-
[2]
Baker, R.S.: Big Data and Education. Univ. of Pennsylvania, 9 edn. (2025)
2025
-
[3]
Computers & Education169, 104194 (2021)
Bardach,L.,Klassen,R.M.,Durksen,T.L.,Rushby,J.V.,Bostwick,K.C.,Sheridan, L.: The power of feedback and reflection: Testing an online scenario-based learning intervention for student teachers. Computers & Education169, 104194 (2021)
2021
-
[4]
In: Proceedings of the LAK26: 16th International Learning Analytics and Knowledge Conference
Borchers, C., Gurung, A., Liu, Q., Thomas, D.R., Khalil, M., Koedinger, K.R.: Brief but impactful: How human tutoring interactions shape engagement in online learning. In: Proceedings of the LAK26: 16th International Learning Analytics and Knowledge Conference. pp. 160–170 (2026)
2026
-
[5]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[6]
Cognitive science25(4), 471–533 (2001)
Chi, M.T., Siler, S.A., Jeong, H., Yamauchi, T., Hausmann, R.G.: Learning from human tutoring. Cognitive science25(4), 471–533 (2001)
2001
-
[7]
In: Proceedings of the Ninth ACM Conference on Learning@Scale (2022)
Chine, D.R., Chhabra, P., Adeniran, A., Gupta, S., Koedinger, K.R.: Development of scenario-based mentor lessons: an iterative design process for training at scale. In: Proceedings of the Ninth ACM Conference on Learning@Scale (2022)
2022
-
[8]
CMU/PLUS: Ai-driven assessment of human tutors: Linking training perfor- mance to real-life practice, pslc datashop.https://pslcdatashop.web.cmu.edu/ DatasetInfo?datasetId=6815(2026)
2026
-
[9]
com/CMU-PLUS/tutor_training_to_practice(2026) AI-driven Tutor Training and Assessment 15
CMU/PLUS: Supplementary material: Ai-driven-assessment.https://github. com/CMU-PLUS/tutor_training_to_practice(2026) AI-driven Tutor Training and Assessment 15
2026
-
[10]
In: Proceedings of the 14th International Conference on Educational Data Mining (EDM 2021) (2021)
Condor, A., Litster, M., Pardos, Z.: Automatic short answer grading with SBERT on out-of-sample questions. In: Proceedings of the 14th International Conference on Educational Data Mining (EDM 2021) (2021)
2021
-
[11]
Educational Evaluation and Policy Analysis 46(3), 483–505 (2024)
Demszky, D., Liu, J., Hill, H.C., Jurafsky, D., Piech, C.: Can automated feedback improve teachers’ uptake of student ideas? evidence from a randomized controlled trial in a large-scale online course. Educational Evaluation and Policy Analysis 46(3), 483–505 (2024)
2024
-
[12]
Further Education Unit (1988)
Gibbs, G.: Learning by doing: A guide to teaching and learning methods. Further Education Unit (1988)
1988
-
[13]
European Journal of Contem- porary Education6(2), 264–279 (2017)
Hursen, C., Fasli, F.G.: Investigating the efficiency of scenario based learning and reflective learning approaches in teacher education. European Journal of Contem- porary Education6(2), 264–279 (2017)
2017
-
[14]
Aera Open7, 23328584211042858 (2021)
Kraft, M.A., Falken, G.T.: A blueprint for scaling tutoring and mentoring across public schools. Aera Open7, 23328584211042858 (2021)
2021
-
[15]
Computers and Education: Artificial Intelligence6, 100213 (2024)
Lee, G.G., Latif, E., Wu, X., Liu, N., Zhai, X.: Applying large language models and chain-of-thought for automatic scoring. Computers and Education: Artificial Intelligence6, 100213 (2024)
2024
-
[16]
arXiv preprint arXiv:2405.00291 (2024)
Lin, J., Chen, E., Han, Z., Gurung, A., Thomas, D.R., Tan, W., Nguyen, N.D., Koedinger, K.R.: How can i improve? using gpt to highlight the desired and unde- sired parts of open-ended responses. arXiv preprint arXiv:2405.00291 (2024)
-
[17]
Nickow, A., Oreopoulos, P., Quan, V.: The impressive effects of tutoring on prek- 12 learning: A systematic review and meta-analysis of the experimental evidence (2020)
2020
-
[18]
In: Instructional-design theories and models, pp
Schank, R.C., Berman, T.R., Macpherson, K.A.: Learning by doing. In: Instructional-design theories and models, pp. 161–181. Routledge (2013)
2013
-
[19]
In: Proceedings of the thirteenth language resources and evaluation conference
Suresh, A., Jacobs, J., Harty, C., Perkoff, M., Martin, J.H., Sumner, T.: The talk- moves dataset: K-12 mathematics lesson transcripts annotated for teacher and student discursive moves. In: Proceedings of the thirteenth language resources and evaluation conference. pp. 4654–4662 (2022)
2022
-
[20]
In: LAK23: 13th International Learning Analytics and Knowledge Conference
Thomas, D., Yang, X., Gupta, S., Adeniran, A., Mclaughlin, E., Koedinger, K.: When the tutor becomes the student: Design and evaluation of efficient scenario- based lessons for tutors. In: LAK23: 13th International Learning Analytics and Knowledge Conference. pp. 250–261 (2023)
2023
-
[21]
Thomas, D.R., Borchers, C., Bhushan, S., Gatz, E., Gupta, S., Koedinger, K.R.: LLM-generatedfeedbacksupportslearningiflearnerschoosetouseit.In:European Conference on Technology Enhanced Learning. pp. 489–503. Springer (2025)
2025
-
[22]
In: Proceedings of the 15th International Learning Analytics and Knowledge Conference
Thomas, D.R., Borchers, C., Kakarla, S., Lin, J., Bhushan, S., Guo, B., Gatz, E., Koedinger, K.R.: Does multiple choice have a future in the age of generative AI? a posttest-only RCT. In: Proceedings of the 15th International Learning Analytics and Knowledge Conference. pp. 494–504 (2025)
2025
-
[23]
In: European Conference on Technology Enhanced Learning
Thomas, D.R., Borchers, C., Lin, J., Kakarla, S., Bhushan, S., Gatz, E., Gupta, S., Abboud, R., Koedinger, K.R.: Leveraging llms to assess tutor moves in real-life dialogues: A feasibility study. In: European Conference on Technology Enhanced Learning. pp. 268–273. Springer (2025)
2025
-
[24]
arXiv preprint arXiv:2603.29141 (2026)
Thomas, D.R., Borchers, C., Vanacore, K.P., Koedinger, K.R., Kizilcec, R.F.: Mod- ernizing ground truth: Four shifts toward improving reliability and validity in AI in education. arXiv preprint arXiv:2603.29141 (2026)
-
[25]
Thompson, M., Owho-Ovuakporie, K., Robinson, K., Kim, Y.J., Slama, R., Reich, J.: Teacher moments: A digital simulation for preservice teachers to approximate parent–teacher conversations. J. of Digital Learning in Teacher Ed (2019) 16 D. R. Thomas et al
2019
-
[26]
Trochim, W.M., Donnelly, J.P., Arora, K.: Research methods: The essential knowl- edge base (2016)
2016
-
[27]
In: International conference on intelligent tu- toring systems
Vail, A.K., Boyer, K.E.: Identifying effective moves in tutoring: On the refinement of dialogue act annotation schemes. In: International conference on intelligent tu- toring systems. pp. 199–209. Springer (2014)
2014
-
[28]
arXiv preprint arXiv:2410.03017 (2024)
Wang,R.E.,Ribeiro,A.T.,Robinson,C.D.,Loeb,S.,Demszky,D.:Tutorcopilot:A human-ai approach for scaling real-time expertise. arXiv preprint arXiv:2410.03017 (2024)
-
[29]
Advances in Simulation4(1), 9 (2019)
Weersink, K., Hall, A.K., Rich, J., Szulewski, A., Dagnone, J.D.: Simulation ver- sus real-world performance: a direct comparison of emergency medicine resident resuscitation entrustment scoring. Advances in Simulation4(1), 9 (2019)
2019
-
[30]
In: Proceedings of the Eleventh ACM Conference on Learning@Scale
Yun, J., Hicke, Y., Olson, M., Demszky, D.: Enhancing tutoring effectiveness through automated feedback: Preliminary findings from a pilot randomized con- trolled trial on sat tutoring. In: Proceedings of the Eleventh ACM Conference on Learning@Scale. pp. 422–426 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.