Bounded Context Management for Tabular Foundation Models on Stream Learning
Pith reviewed 2026-06-26 21:42 UTC · model grok-4.3
The pith
Tabular foundation models outperform classical stream learners by managing context through uncertainty-aware admission and redundancy-aware eviction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
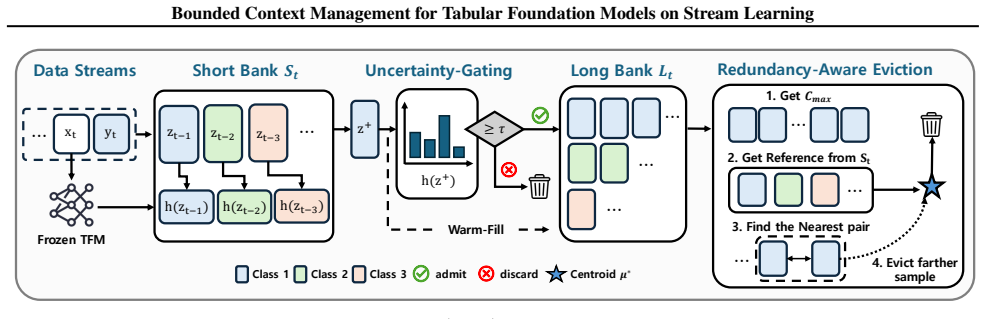
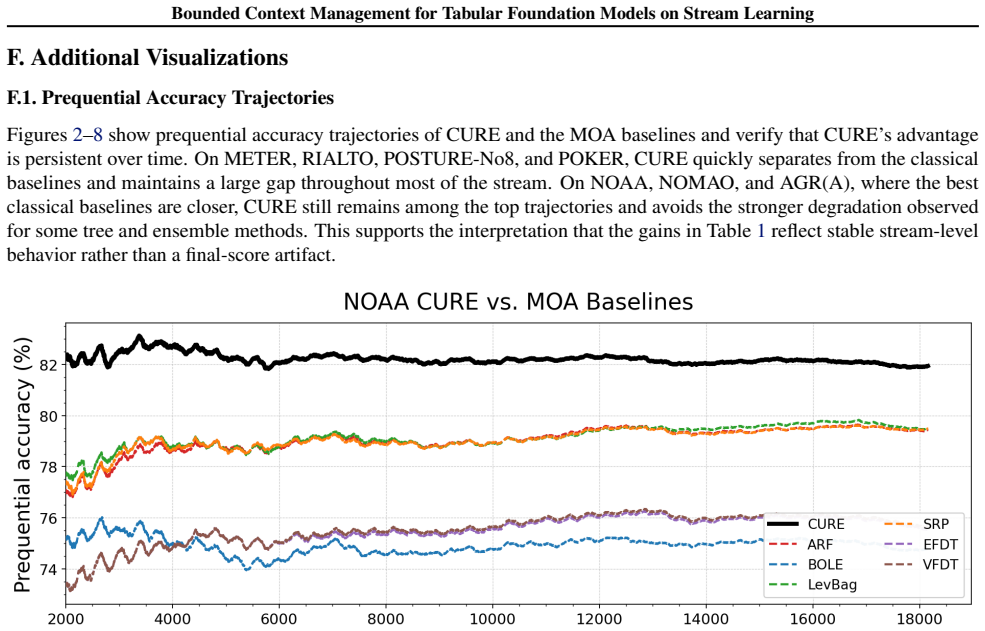
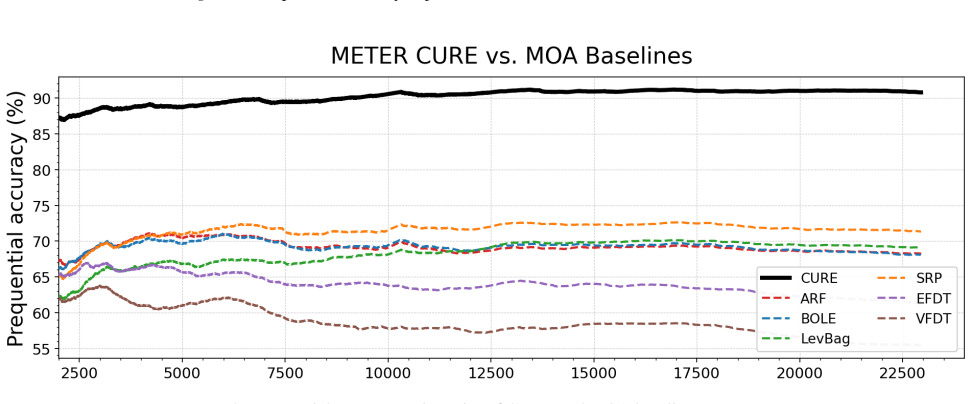
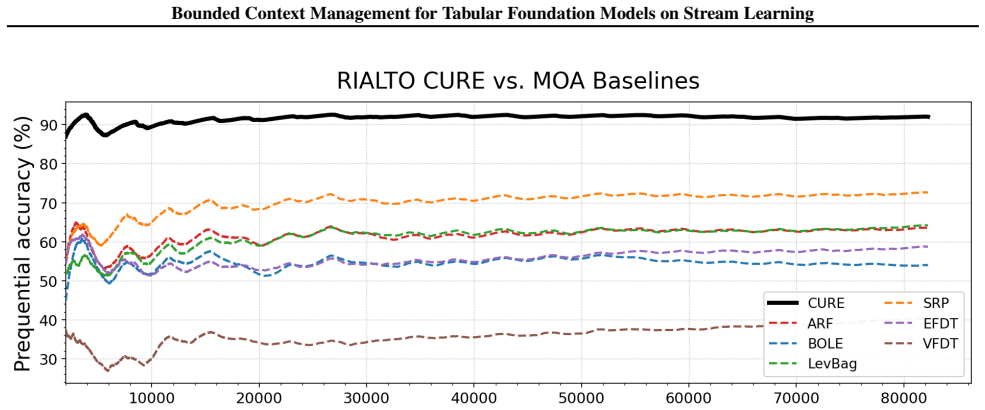
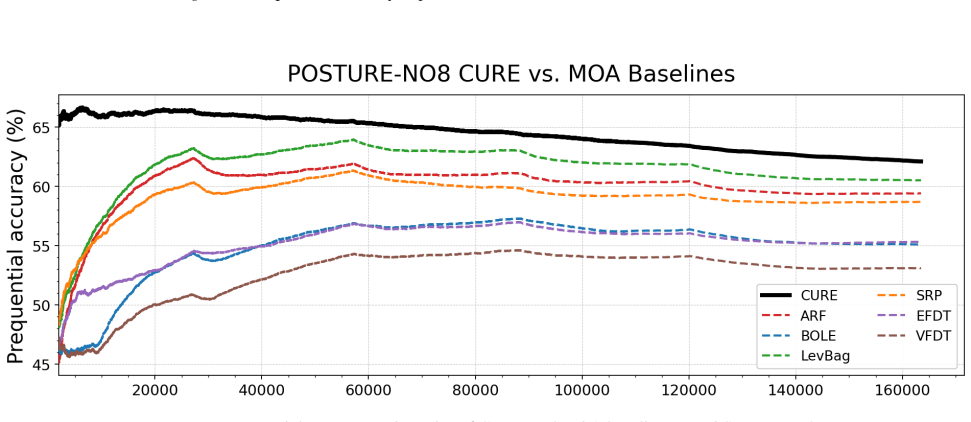
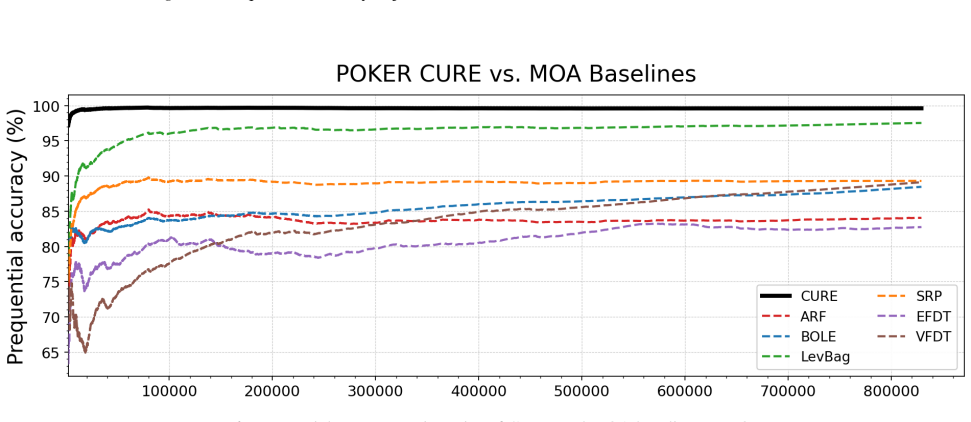
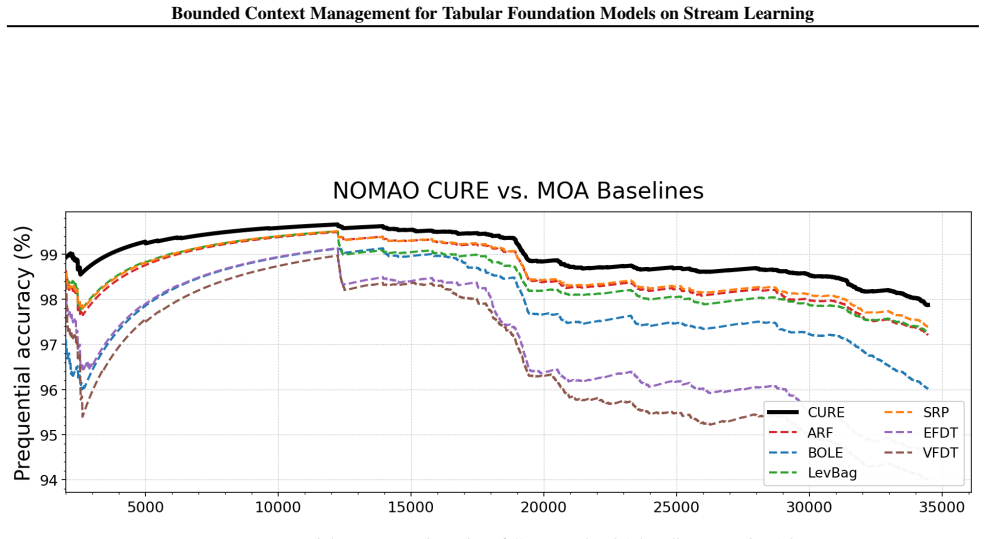
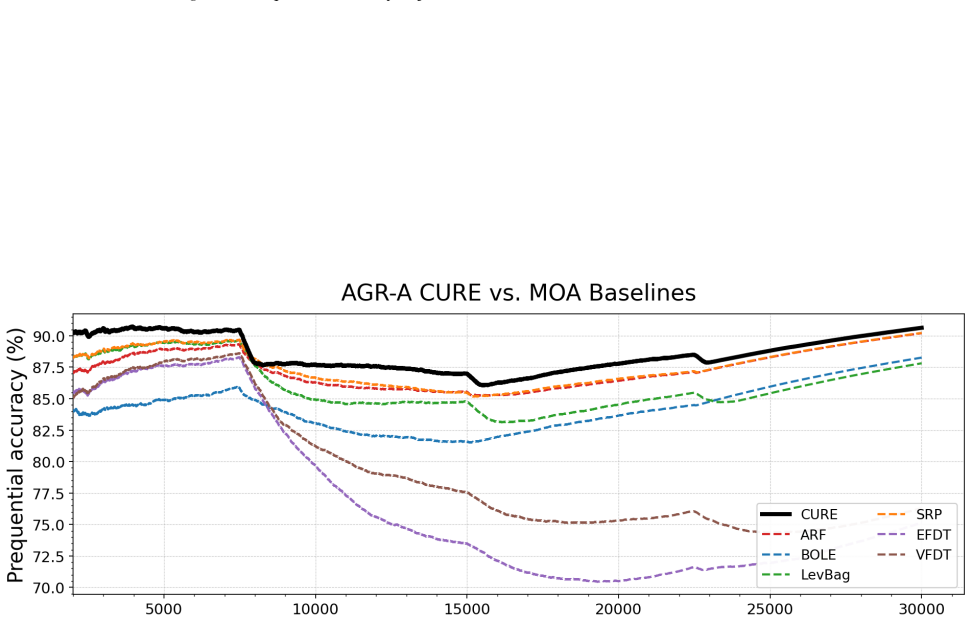
The future information view identifies preserving recent examples, retaining uncertain examples, and removing redundant examples as the necessary and sufficient conditions for bounded context management in tabular foundation models. These conditions are realized as CURE through entropy-gated admission and redundancy-aware eviction, producing up to 27.0% relative improvement over classical stream learners on seven streams while remaining robust across multiple TFM backbones and ranking first among policy variants.
What carries the argument
CURE, the context management policy that applies entropy-gated admission and redundancy-aware eviction to enforce the three requirements derived from the future information view.
If this is right
- CURE achieves up to 27.0% relative improvement over classical stream learners across seven streams.
- The approach remains robust when swapping among multiple TFM backbones.
- CURE ranks first among the policy variants evaluated on the streams.
- Context management replaces internal model-state updates as the primary adaptation mechanism for tabular foundation models.
Where Pith is reading between the lines
- The same three requirements could be tested as a design template for context policies in non-tabular foundation models that perform sequential prediction.
- Dynamic context sizing that explicitly tracks uncertainty and redundancy may reduce the need for fixed window lengths in other streaming settings.
- The separation of admission and eviction rules offers a modular way to combine different uncertainty estimators with different redundancy metrics.
Load-bearing premise
The future information view correctly identifies preserving recent examples, retaining uncertain examples, and removing redundant examples as the necessary and sufficient conditions for effective context management in tabular foundation models.
What would settle it
A stream where a policy that violates at least one of the three requirements (recent preservation, uncertainty retention, or redundancy removal) matches or exceeds CURE accuracy on the same seven datasets would falsify the necessity of those conditions.
Figures
read the original abstract
Tabular stream learning requires predictions on sequentially arriving examples under distribution shift. While standard methods adapt by updating model states, tabular foundation models (TFMs) make predictions conditioned on a labeled context in an in-context manner, making them a natural alternative for stream learning. This shifts the challenge from how to update the model to how to manage the context. We propose a future information view that yields three practical requirements for context management: preserve recent examples, retain uncertain examples, and remove redundant examples. We instantiate these requirements as CURE (Context management via Uncertainty-aware admission and Redundancy aware Eviction), a context-managing policy with entropy-gated admission and redundancy-aware eviction. Across seven streams, CURE shows up to 27.0% relative improvement over classical stream learners, remains robust across multiple TFM backbones, and ranks first among other policy variants. Code and datasets are available at https://github.com/morcellinus/CURE-ICML-FMSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CURE, a context-management policy for tabular foundation models (TFMs) performing stream learning under distribution shift. It introduces a 'future information view' asserted to yield three requirements—preserve recent examples, retain uncertain examples, remove redundant examples—as necessary and sufficient conditions; these are instantiated via entropy-gated admission and redundancy-aware eviction. On seven streams the policy reports up to 27% relative improvement over classical stream learners, robustness across multiple TFM backbones, and first rank among policy variants. Code and datasets are released.
Significance. If the empirical ranking holds after verification of baselines and statistical testing, the work supplies a practical, bounded-context strategy that shifts the adaptation burden from model updates to context curation for in-context TFMs. The open release of code strengthens reproducibility and enables direct follow-up.
major comments (2)
- [§3] §3 (Future information view): the manuscript states that the view 'yields' the three requirements as necessary and sufficient, yet supplies no derivation, reduction, or minimality argument establishing that these three conditions are jointly required and sufficient for effective TFM context management. Without such grounding, the attribution of the reported gains to the proposed framework (rather than to the specific entropy and redundancy heuristics) remains open.
- [Experimental section] Experimental section (results on seven streams): the abstract and summary claim 'consistent gains' and 'robustness across backbones,' but the provided text does not report statistical significance tests, variance across random seeds, or explicit baseline implementation details (e.g., hyper-parameter search budgets for classical stream learners). These omissions are load-bearing for the central empirical claim of up to 27% relative improvement.
minor comments (2)
- Notation for entropy threshold and redundancy metric should be defined once in a single location rather than re-introduced in multiple subsections.
- Figure captions for the policy-variant comparison should explicitly state the number of runs and error bars used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript's rigor.
read point-by-point responses
-
Referee: [§3] §3 (Future information view): the manuscript states that the view 'yields' the three requirements as necessary and sufficient, yet supplies no derivation, reduction, or minimality argument establishing that these three conditions are jointly required and sufficient for effective TFM context management. Without such grounding, the attribution of the reported gains to the proposed framework (rather than to the specific entropy and redundancy heuristics) remains open.
Authors: We agree that the current text presents the three requirements as following from the future information view without an explicit derivation or minimality argument. In the revision we will expand §3 with a step-by-step reasoning that derives the necessity and sufficiency of the three conditions directly from the view, including a brief minimality discussion. This will clarify the link between the framework and the observed gains versus the specific heuristics. revision: yes
-
Referee: Experimental section (results on seven streams): the abstract and summary claim 'consistent gains' and 'robustness across backbones,' but the provided text does not report statistical significance tests, variance across random seeds, or explicit baseline implementation details (e.g., hyper-parameter search budgets for classical stream learners). These omissions are load-bearing for the central empirical claim of up to 27% relative improvement.
Authors: We concur that statistical tests, seed-wise variance, and baseline implementation details are required to substantiate the central claims. In the revised version we will report performance averaged over multiple random seeds with standard deviations, include statistical significance tests (e.g., paired t-tests), and provide explicit hyper-parameter search budgets and procedures for all classical stream learners. These additions will be placed in the experimental section and supplementary material. revision: yes
Circularity Check
No circularity; empirical claims rest on external baselines
full rationale
The paper introduces a 'future information view' that informally motivates three requirements for context management, then instantiates them as the CURE policy and reports relative improvements (up to 27%) against classical stream learners across seven streams. No equations, fitted parameters, or self-citations are described that would make any reported prediction reduce to the inputs by construction. The central result is an empirical ranking that can be independently replicated or falsified on the released code and datasets; the mapping from view to requirements is conceptual rather than a self-referential derivation. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The future information view correctly identifies preserve-recent, retain-uncertain, and remove-redundant as the three practical requirements for context management.
Reference graph
Works this paper leans on
-
[1]
Mining associ- ation rules between sets of items in large databases
Agrawal, R., Imieli´nski, T., and Swami, A. Mining associ- ation rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD international conference on Management of data, pp. 207–216,
1993
-
[2]
de Barros, R. S. M., de Carvalho Santos, S. G. T., and J´unior, P. M. G. A boosting-like online learning ensemble. In 2016 international joint conference on neural networks (IJCNN), pp. 1871–1878. IEEE,
2016
-
[3]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L., Fl¨oge, K., Key, O., Birkel, F., Jund, P., Roof, B., J ¨ager, B., Safaric, D., Alessi, S., Hayler, A., et al. Tabpfn-2.5: Advancing the state of the art in tabular foun- dation models.arXiv preprint arXiv:2511.08667,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Hollmann, N., M ¨uller, S., Eggensperger, K., and Hut- ter, F. Tabpfn: A transformer that solves small tabu- lar classification problems in a second.arXiv preprint arXiv:2207.01848,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Lourenc ¸o, A., Gama, J., Xing, E. P., and Marreiros, G. Bridging streaming continual learning via in-context large tabular models.arXiv preprint arXiv:2512.11668,
-
[6]
C., Golestan, K., Yu, G., Caterini, A
Ma, J., Thomas, V ., Hosseinzadeh, R., Labach, A., Kamkari, H., Cresswell, J. C., Golestan, K., Yu, G., Caterini, A. L., and V olkovs, M. Tabdpt: Scaling tabular foundation models on real data.arXiv preprint arXiv:2410.18164,
-
[7]
I., and Salehi, M
Manapragada, C., Webb, G. I., and Salehi, M. Extremely fast decision tree. InProceedings of the 24th ACM SIGKDD international conference on knowledge discov- ery & data mining, pp. 1953–1962,
1953
-
[8]
P., Grabocka, J., and Hutter, F
M¨uller, S., Hollmann, N., Arango, S. P., Grabocka, J., and Hutter, F. Transformers can do bayesian inference.arXiv preprint arXiv:2112.10510,
-
[9]
Qu, J., Holzmuller, D., Varoquaux, G., and Morvan, M. L. Tabicl: A tabular foundation model for in-context learn- ing on large data.arXiv preprint arXiv:2502.05564,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Limix: Unleashing structured-data modeling capability for generalist intelligence
Zhang, X., Ren, G., Yu, H., Yuan, H., Wang, H., Li, J., Wu, J., Mo, L., Mao, L., Hao, M., et al. Limix: Unleashing structured-data modeling capability for generalist intelli- gence.arXiv preprint arXiv:2509.03505,
-
[12]
The near-future feature distribution is P + t,X = 1 h X s∈H+ t Ps,X ,H + t ={t+ 1,
We fix a stream step t, a current context Dt, and a newly observed candidatez t = (xt, yt). The near-future feature distribution is P + t,X = 1 h X s∈H+ t Ps,X ,H + t ={t+ 1, . . . , t+h}. For a future feature value x′, let Yx′ denote its label random variable. For the current candidate feature xt, we use Yxt to denote the label random variable before its...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.