RedactionBench
Pith reviewed 2026-06-26 21:15 UTC · model grok-4.3
The pith
Contextual redaction of personally identifiable information is not solved by current models or tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
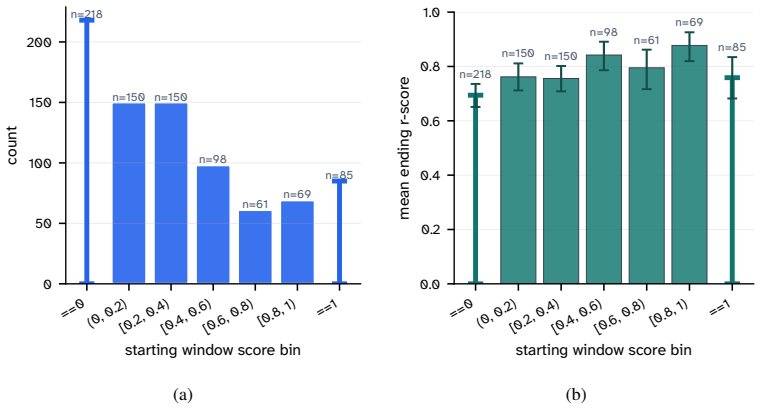
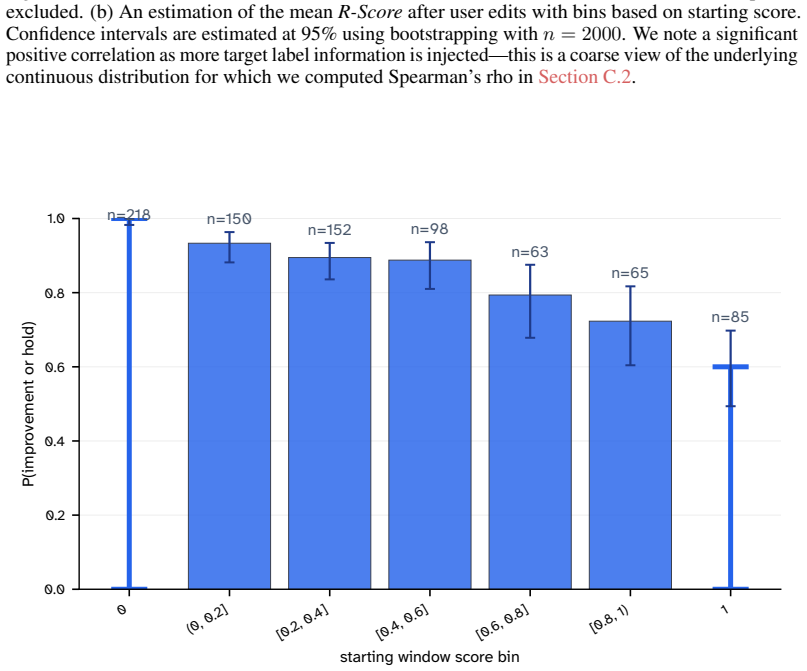
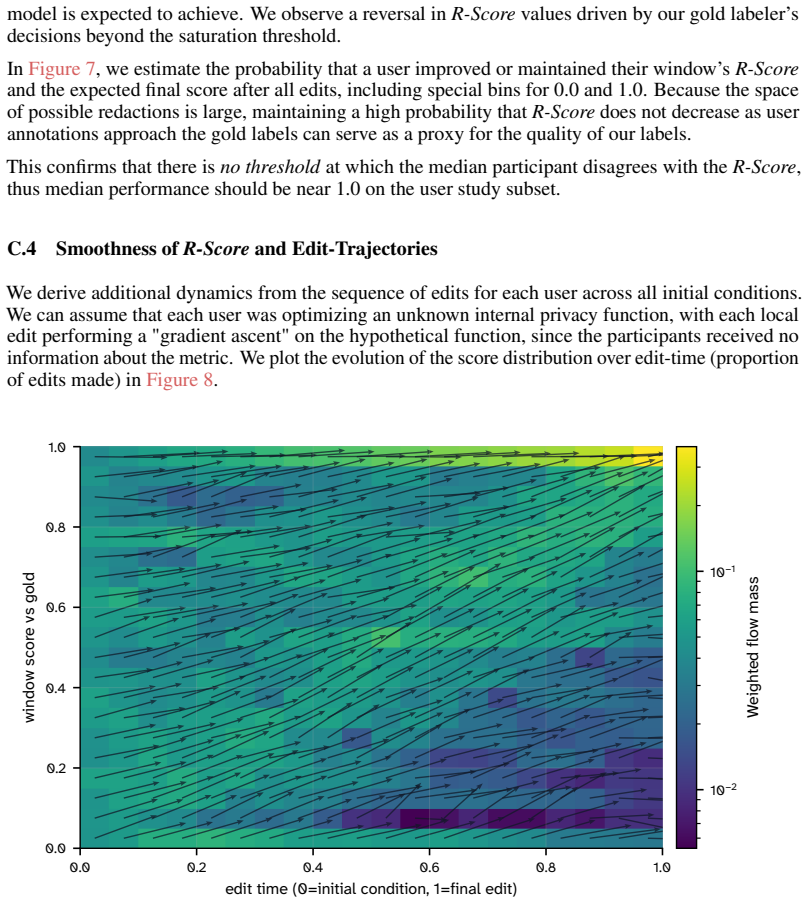
Grounded in contextual integrity, RedactionBench provides target labels for redaction decisions in diverse documents. The R-Score metric decouples performance from shallow formatting choices. Across 35 models, contextual redaction remains unsolved, and the subjective nature of contextual privacy is shown by low human consensus on those cases.
What carries the argument
RedactionBench, a manually annotated benchmark of 200 documents, paired with the R-Score metric that treats semantically similar redactions equally.
If this is right
- Current approaches to PII extraction fail to account for context in privacy decisions.
- Standardized benchmarks like RedactionBench are needed to evaluate privacy-preserving systems.
- Model design should focus on understanding contextual privacy norms rather than just entity detection.
- Human variance in privacy perceptions motivates metrics that handle ambiguity.
Where Pith is reading between the lines
- Future systems might need to handle ambiguous cases by deferring to user input or probabilistic outputs.
- Extending the benchmark to more domains could reveal patterns in privacy norms across contexts.
- The separation of mandatory and contextual redactions suggests hybrid approaches combining rules and learned context.
- Releasing the benchmark establishes a baseline that can drive competition on privacy tasks.
Load-bearing premise
The manually created target labels in RedactionBench accurately represent the correct contextual privacy decisions.
What would settle it
A model that achieves high scores on RedactionBench while matching human consensus rates on contextual redactions, or a study showing consistent human agreement on contextual cases.
Figures

read the original abstract
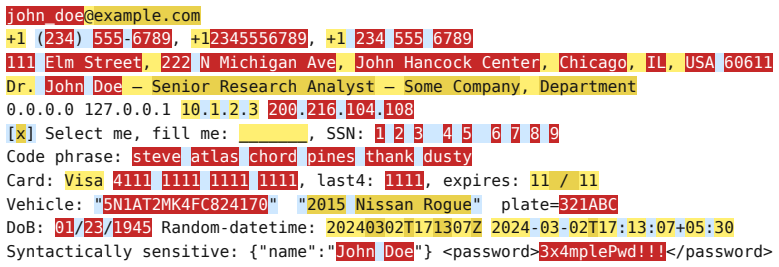
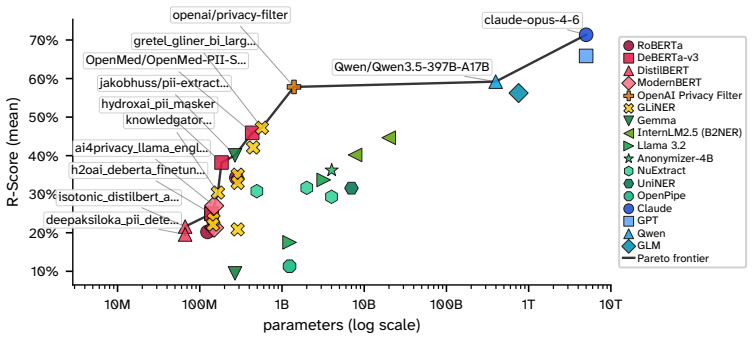
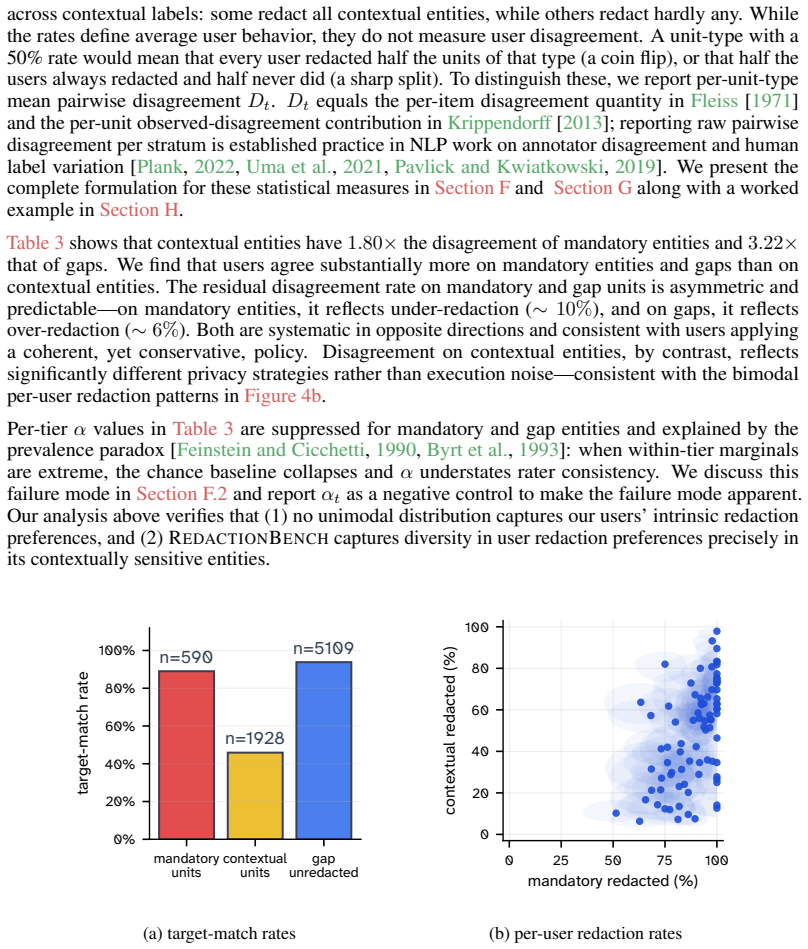
Large Language Models are increasingly applied to sensitive domains that require redaction of personally identifiable information (PII). While redacting PII is a data cleaning prerequisite, existing benchmarks conflate extraction mechanics with privacy semantics. A public phone number is not equivalent to a phone number in a medical record. Whether information constitutes a violation depends heavily on who holds it, why, and in what context, fundamentally differentiating redaction from simple entity recognition. Grounded in contextual integrity, we introduce RedactionBench, a manually annotated benchmark comprising 200 diverse documents across 11 domains, mostly seeded from real-world sources. We also introduce R-Score, a novel character-level metric that treats semantically similar redactions equally and nullifies shallow formatting choices, such as varying masking styles for phone numbers. Evaluations across Named Entity Recognition models, entity extraction Small Language Models, and frontier models equipped with agentic tools demonstrate that contextual redaction remains an unsolved problem. A human evaluation with over 80 users on RedactionBench reveals a stark dichotomy in privacy perceptions. Annotators show consensus with target labels for mandatory redactions (89.4 percent) and safe text preservations (94.1 percent), but fail to agree on contextual redactions (47.7 percent). This variance demonstrates the subjective nature of contextual privacy and motivates R-Score, which decouples contextual ambiguity from strict precision. We compare 35 models across families and report their performance in redacting PII. Finally, we release RedactionBench to establish a baseline for future privacy-preserving systems, hoping to inspire efficient model design and standardized evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RedactionBench, a manually annotated benchmark of 200 documents across 11 domains (mostly real-world sources) for evaluating contextual PII redaction grounded in contextual integrity. It proposes the R-Score, a character-level metric that equates semantically similar redactions and ignores formatting variations. Evaluations of 35 models (NER systems, entity-extraction SLMs, and frontier LLMs with agentic tools) show poor performance on contextual cases, while a human study with >80 users reports 89.4% agreement with targets on mandatory redactions, 94.1% on safe preservations, and only 47.7% on contextual redactions; the authors conclude that contextual redaction remains unsolved and release the benchmark.
Significance. If the target labels constitute stable, inter-subjectively validated ground truth, RedactionBench and R-Score would usefully separate contextual privacy decisions from mechanical entity extraction and provide a needed public baseline for privacy-preserving systems. The release of the dataset itself is a concrete strength that enables future work.
major comments (2)
- [Benchmark construction / human evaluation] Benchmark construction / human evaluation section: the target labels are described as 'manually annotated' and 'manually created' but the manuscript supplies no information on the number of annotators who produced them, their selection or expertise, the adjudication procedure used to resolve disagreements, or any inter-annotator agreement statistics computed on the targets themselves. This is load-bearing because all model scores (including the claim that contextual redaction is unsolved) are computed against these targets, yet the same human study reports only 47.7% agreement precisely on the contextual subset.
- [Abstract and evaluation results] Abstract and evaluation results: the central claim that 'contextual redaction remains an unsolved problem' is supported only by model performance against the author-defined targets; the reported 47.7% human agreement on contextual cases directly undercuts the assumption that those targets encode a reliable standard rather than one (or a small set of) subjective privacy judgments. Without additional validation (e.g., multi-annotator consensus labels or external expert review), model under-performance may simply track label idiosyncrasy.
minor comments (2)
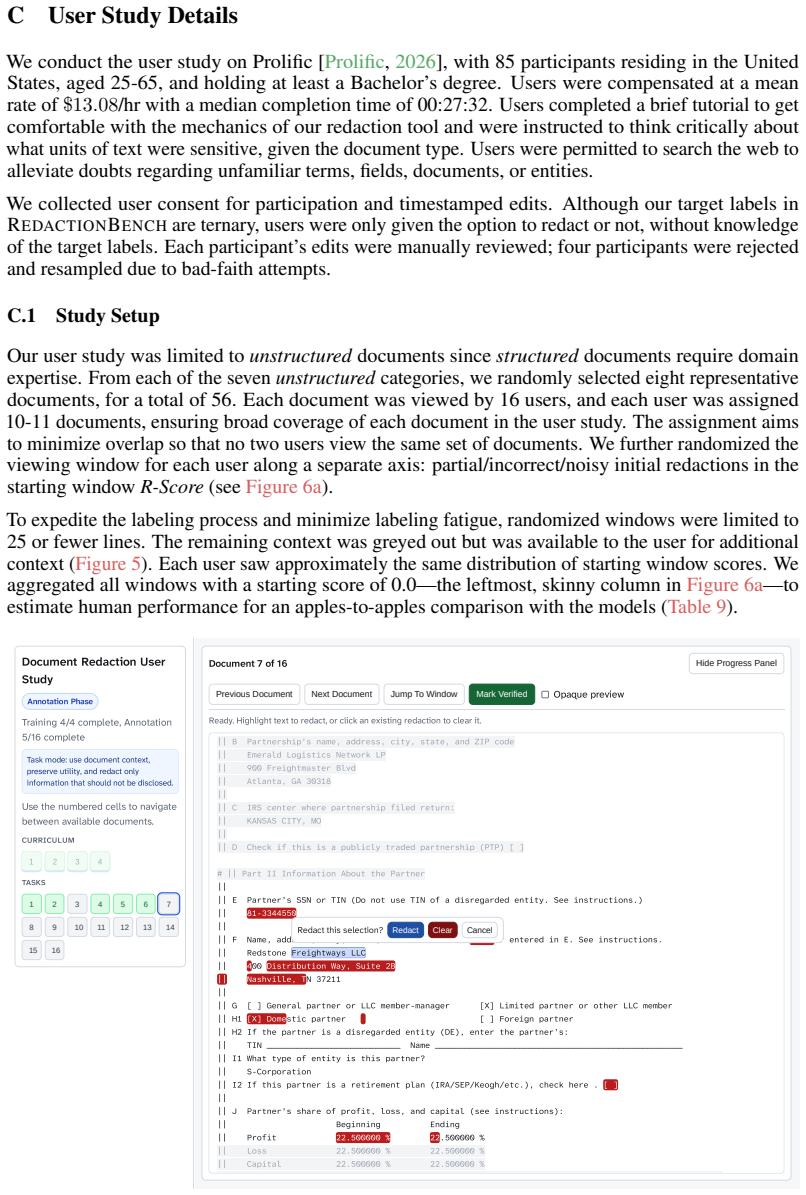
- [Benchmark construction] Document selection criteria and domain sampling procedure are not described in sufficient detail to allow replication or assessment of coverage bias.
- [R-Score definition] The exact definition and implementation of R-Score (character-level matching rules, handling of partial overlaps, normalization) should be given with a worked example or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments raise important points about the transparency of our target label creation process and the strength of evidence for our central claim. We address each below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Benchmark construction / human evaluation] Benchmark construction / human evaluation section: the target labels are described as 'manually annotated' and 'manually created' but the manuscript supplies no information on the number of annotators who produced them, their selection or expertise, the adjudication procedure used to resolve disagreements, or any inter-annotator agreement statistics computed on the targets themselves. This is load-bearing because all model scores (including the claim that contextual redaction is unsolved) are computed against these targets, yet the same human study reports only 47.7% agreement precisely on the contextual subset.
Authors: The target labels were produced by the three lead authors, each with prior experience in NLP and privacy research. Annotation proceeded via iterative individual review followed by group discussion to reach consensus on each document; no external annotators or crowd-sourcing were used because contextual-integrity judgments require sustained domain familiarity. We will add a new subsection (likely 3.2) that explicitly states the number of annotators, their backgrounds, the consensus procedure, and the rationale for not computing IAA on the targets themselves (they represent the authors' agreed reference standard rather than an averaged crowd label). The separate human study (>80 participants) was conducted afterward precisely to measure agreement against these targets and to surface the subjectivity that appears in the 47.7 % contextual figure. Adding this description addresses the transparency concern without altering the experimental design. revision: yes
-
Referee: [Abstract and evaluation results] Abstract and evaluation results: the central claim that 'contextual redaction remains an unsolved problem' is supported only by model performance against the author-defined targets; the reported 47.7% human agreement on contextual cases directly undercuts the assumption that those targets encode a reliable standard rather than one (or a small set of) subjective privacy judgments. Without additional validation (e.g., multi-annotator consensus labels or external expert review), model under-performance may simply track label idiosyncrasy.
Authors: We agree that the 47.7 % figure on contextual cases demonstrates subjectivity, but we view this as supporting rather than undermining the claim. The targets achieve high agreement on mandatory redactions (89.4 %) and safe preservations (94.1 %), indicating they are reliable where privacy norms are clear; the drop on contextual cases is the very phenomenon we argue makes the task unsolved. Model failures are measured against a fixed, reproducible reference that is already shown to be non-idiosyncratic on the non-contextual subsets. We will revise the abstract and Section 5 to clarify that the targets constitute one expert-validated standard (not the sole possible labeling) and to emphasize that both model and human performance remain low on contextual items. This framing keeps the claim intact while acknowledging the inherent variability that R-Score is designed to accommodate. No further external validation round was performed, but the existing human study already supplies the multi-annotator data the referee requests. revision: partial
Circularity Check
No circularity: benchmark and metric are introduced without self-referential derivations
full rationale
The paper introduces RedactionBench (200 documents, 11 domains) and R-Score (character-level metric) as new artifacts. No equations, fitted parameters, or predictions are defined; evaluations consist of direct model runs on the manually labeled set. The human agreement figures (89.4%, 94.1%, 47.7%) are reported as observations rather than inputs to any derivation. No self-citations serve as load-bearing premises for uniqueness or ansatzes. The work is self-contained as an empirical benchmark release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contextual integrity theory supplies the correct criteria for deciding whether a piece of information should be redacted.
invented entities (1)
-
R-Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[2]
, title =
Wilson, Edwin B. , title =. Journal of the American Statistical Association , year =
-
[3]
Text Chunking using Transformation-Based Learning
Ramshaw, Lance and Marcus, Mitch. Text Chunking using Transformation-Based Learning. Third Workshop on Very Large Corpora. 1995
1995
-
[4]
Washington Law Review , year =
Nissenbaum, Helen , title =. Washington Law Review , year =
-
[5]
The C o NLL -2013 Shared Task on Grammatical Error Correction
Ng, Hwee Tou and Wu, Siew Mei and Wu, Yuanbin and Hadiwinoto, Christian and Tetreault, Joel. The C o NLL -2013 Shared Task on Grammatical Error Correction. Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task. 2013
2013
-
[6]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[7]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[8]
arXiv preprint arXiv:2502.18443 , year=
olmocr: Unlocking trillions of tokens in pdfs with vision language models , author=. arXiv preprint arXiv:2502.18443 , year=
-
[9]
arXiv preprint arXiv:2507.05595 , year=
Paddleocr 3.0 technical report , author=. arXiv preprint arXiv:2507.05595 , year=
-
[10]
arXiv preprint arXiv:2506.03197 , year=
Infinity parser: Layout aware reinforcement learning for scanned document parsing , author=. arXiv preprint arXiv:2506.03197 , year=
-
[11]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Gliner: Generalist model for named entity recognition using bidirectional transformer , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[12]
arXiv preprint arXiv:2507.18546 , year=
GLiNER2: An Efficient Multi-Task Information Extraction System with Schema-Driven Interface , author=. arXiv preprint arXiv:2507.18546 , year=
-
[13]
2025 , publisher =
Amy Steier and Andre Manoel and Alexa Haushalter and Maarten Van Segbroeck , title =. 2025 , publisher =
2025
-
[14]
Piiranha-v1: Protect your personal information! , year =
-
[15]
2026 , publisher =
OpenMed-PII-SuperClinical-Large-434M-v1: PII Detection Model , author =. 2026 , publisher =
2026
-
[16]
2024 , publisher =
Knowledgator , title =. 2024 , publisher =
2024
-
[17]
2024 , url =
Presidio , title =. 2024 , url =
2024
-
[18]
2024 , url =
Maarten Van Segbroeck , title =. 2024 , url =
2024
-
[19]
2026 , howpublished =
Privacy Filter , author =. 2026 , howpublished =
2026
-
[20]
2020 , doi =
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , title =. 2020 , doi =
2020
-
[21]
PII Masking 200k Dataset , year =
-
[22]
Synthetic financial PII multilingual dataset , year =
-
[23]
2025 , eprint=
OpenMed NER: Open-Source, Domain-Adapted State-of-the-Art Transformers for Biomedical NER Across 12 Public Datasets , author=. 2025 , eprint=
2025
-
[24]
N u NER : Entity Recognition Encoder Pre-training via LLM -Annotated Data
Bogdanov, Sergei and Constantin, Alexandre and Bernard, Timoth \'e e and Crabb \'e , Benoit and Bernard, Etienne P. N u NER : Entity Recognition Encoder Pre-training via LLM -Annotated Data. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.660
-
[26]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Beyond boundaries: Learning a universal entity taxonomy across datasets and languages for open named entity recognition , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[27]
arXiv preprint arXiv:1907.11692 , year=
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
Pith/arXiv arXiv 1907
-
[28]
2025 , eprint =
OpenAI GPT-5 System Card , author =. 2025 , eprint =
2025
-
[29]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[30]
2025 , month =
System Card: Claude Opus 4.5 , institution =. 2025 , month =
2025
-
[31]
Pengcheng He and Jianfeng Gao and Weizhu Chen , booktitle=. De. 2023 , url=
2023
-
[32]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Union-over-Intersections: Object Detection beyond Winner-Takes-All , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition
Shen, Yongliang and Ma, Xinyin and Tan, Zeqi and Zhang, Shuai and Wang, Wen and Lu, Weiming. Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)...
-
[35]
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Bourdev, Lubomir and Girshick, Ross and Hays, James and Perona, Pietro and Ramanan, Deva and Zitnick, C. Lawrence and Doll. Microsoft COCO: Common Objects in Context , booktitle =. 2014 , publisher =. doi:10.1007/978-3-319-10602-1_48 , series =
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Xueqing Deng, Qihang Yu, Peng Wang, Xiaohui Shen, Liang-Chieh Chen , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[37]
Nejadgholi, Isar and Fraser, Kathleen C. and de Bruijn, Berry. Extensive Error Analysis and a Learning-Based Evaluation of Medical Entity Recognition Systems to Approximate User Experience. Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing. 2020. doi:10.18653/v1/2020.bionlp-1.19
-
[38]
Boundary Smoothing for Named Entity Recognition
Zhu, Enwei and Li, Jinpeng. Boundary Smoothing for Named Entity Recognition. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.490
-
[39]
Meena, Bharti and Skubisz, Joanna and Rajgarhia, Harshit and Dave, Nand and Ganesh, Kiran and Dalmia, Shivali and Mukherji, Abhishek and Sundarababu, Vasudevan and Pospelova, Olga , booktitle =. 2025 , volume =. doi:10.1109/ICDMW69685.2025.00049 , url =
-
[40]
Advances in Neural Information Processing Systems , volume=
Bigbio: A framework for data-centric biomedical natural language processing , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003 , pages=
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition , author=. Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003 , pages=
2003
-
[42]
O nto N otes: The 90 \
Hovy, Eduard and Marcus, Mitchell and Palmer, Martha and Ramshaw, Lance and Weischedel, Ralph. O nto N otes: The 90 \. Proceedings of the Human Language Technology Conference of the NAACL , Companion Volume: Short Papers. 2006
2006
-
[43]
Zhang, Y. and Chen, Q. and Yang, Z. and others , title =. Scientific Data , volume =. 2019 , month =. doi:10.1038/s41597-019-0055-0 , url =
-
[44]
Mitchell, Alexis and Strassel, Stephanie and Huang, Shudong and Zakhary, Ramez , title =. 2005 , publisher =. doi:10.35111/8m4r-v312 , url =
-
[45]
Walker, Christopher and Strassel, Stephanie and Medero, Julie and Maeda, Kazuaki , title =. 2006 , publisher =. doi:10.35111/mwxc-vh88 , url =
-
[46]
2012--2026 , url =
Faraglia, Daniele and others , title =. 2012--2026 , url =
2012
-
[47]
2013 , publisher=
Content Analysis: An Introduction to Its Methodology , author=. 2013 , publisher=
2013
-
[48]
2026 , eprint=
RAT-Bench: A Comprehensive Benchmark for Text Anonymization , author=. 2026 , eprint=
2026
-
[49]
2025 , eprint=
PII-Bench: Evaluating Query-Aware Privacy Protection Systems , author=. 2025 , eprint=
2025
-
[50]
Ponomarenko, Mariia and Abedini, Sepideh and Shafieinejad, Masoumeh and Emerson, D. B. and Mohapatra, Shubhankar and He, Xi. CAPID : Context-Aware PII Detection for Question-Answering Systems. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 4: Student Research Workshop). 2026. doi:10....
-
[51]
PRvL: Quantifying the Capabilities and Risks of Large Language Models for PII Redaction , year=
Garza, Leon and Kotal, Anantaa and Piplai, Aritran and Elluri, Lavanya and Das, Prajit Kumar and Chadha, Aman , booktitle=. PRvL: Quantifying the Capabilities and Risks of Large Language Models for PII Redaction , year=
-
[52]
2026 , url=
Privasis: Synthesizing the Largest ''Public'' Private Dataset from Scratch , author=. 2026 , url=
2026
-
[53]
2024 , eprint=
DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts , author=. 2024 , eprint=
2024
-
[54]
Large Language Models Can Be Contextual Privacy Protection Learners
Xiao, Yijia and Jin, Yiqiao and Bai, Yushi and Wu, Yue and Yang, Xianjun and Luo, Xiao and Yu, Wenchao and Zhao, Xujiang and Liu, Yanchi and Gu, Quanquan and Chen, Haifeng and Wang, Wei and Cheng, Wei. Large Language Models Can Be Contextual Privacy Protection Learners. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing...
-
[55]
RedacBench: Can
Hyunjun Jeon and Kyuyoung Kim and Jinwoo Shin , booktitle=. RedacBench: Can. 2026 , url=
2026
-
[56]
Niloofar Mireshghallah and Hyunwoo Kim and Xuhui Zhou and Yulia Tsvetkov and Maarten Sap and Reza Shokri and Yejin Choi , booktitle=. Can. 2024 , url=
2024
-
[57]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[58]
2024 , eprint=
CI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data , author=. 2024 , eprint=
2024
-
[59]
2025 , eprint=
Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory , author=. 2025 , eprint=
2025
-
[60]
Journal of the American Medical Informatics Association , year =
Davidson, Rory and Hardman, Will and Amit, Guy and Bilu, Yonatan and Della Mea, Vincenzo and Galaida, Aleksandr and Girshovitz, Irena and Kulyabin, Mikhail and Popescu, Mihai Horia and Roitero, Kevin and Sokolov, Gleb and Yanover, Chen , title =. Journal of the American Medical Informatics Association , year =
-
[61]
Computational Linguistics , volume =
Artstein, Ron and Poesio, Massimo , title =. Computational Linguistics , volume =. 2008 , publisher =
2008
-
[62]
, title =
Byrt, Ted and Bishop, Janet and Carlin, John B. , title =. Journal of Clinical Epidemiology , volume =
-
[63]
and Feinstein, Alvan R
Cicchetti, Domenic V. and Feinstein, Alvan R. , title =. Journal of Clinical Epidemiology , volume =
-
[64]
, title =
Efron, Bradley and Tibshirani, Robert J. , title =
-
[65]
and Cicchetti, Domenic V
Feinstein, Alvan R. and Cicchetti, Domenic V. , title =. Journal of Clinical Epidemiology , volume =
-
[66]
, title =
Fleiss, Joseph L. , title =. Psychological Bulletin , volume =
-
[67]
, title =
Gwet, Kilem L. , title =. British Journal of Mathematical and Statistical Psychology , volume =
-
[68]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Nie, Yixin and Zhou, Xiang and Bansal, Mohit , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2020
-
[69]
Transactions of the Association for Computational Linguistics , volume =
Pavlick, Ellie and Kwiatkowski, Tom , title =. Transactions of the Association for Computational Linguistics , volume =
-
[70]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Plank, Barbara , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2022
-
[71]
and Fornaciari, Tommaso and Hovy, Dirk and Paun, Silviu and Plank, Barbara and Poesio, Massimo , title =
Uma, Alexandra N. and Fornaciari, Tommaso and Hovy, Dirk and Paun, Silviu and Plank, Barbara and Poesio, Massimo , title =. Journal of Artificial Intelligence Research , volume =
-
[72]
Together AI: AI-Native Cloud , year =
-
[73]
Urchade Zaratiana and Nadi Tomeh and Pierre Holat and Thierry Charnois , year =. 2311.08526 , archivePrefix =
-
[74]
2025 , address =
Yang, Yuming and Zhao, Wantong and Huang, Caishuang and Ye, Junjie and Wang, Xiao and Zheng, Huiyuan and Nan, Yang and Wang, Yuran and Xu, Xueying and Huang, Kaixin and Zhang, Yunke and Gui, Tao and Zhang, Qi and Huang, Xuanjing , booktitle =. 2025 , address =
2025
-
[75]
Wenxuan Zhou and Sheng Zhang and Yu Gu and Muhao Chen and Hoifung Poon , year =. 2308.03279 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.