Aligning Implied Statements for Implicit Hate Speech Generalizability with Context-Bounded Semi-hard Negative Mining
Pith reviewed 2026-06-26 21:04 UTC · model grok-4.3
The pith
Aligning posts with implied statements via context-bounded semi-hard negative mining offers a more stable mapping for implicit hate speech detection across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Aligning posts with their implied statements via context-bounded mining provides a more stable, bijective-like mapping to related insinuations, overcoming the volatility inherent in traditional clustering-based representation learning.
What carries the argument
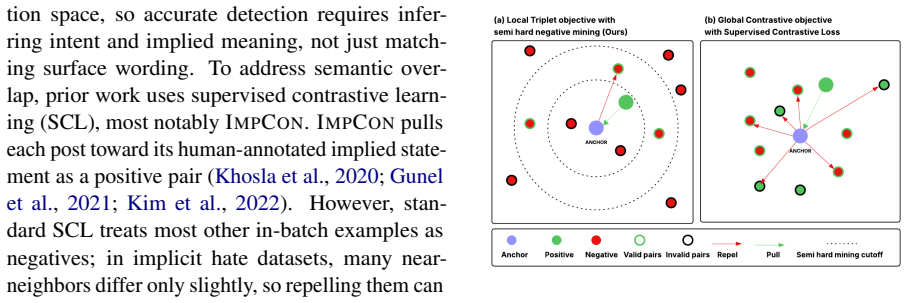
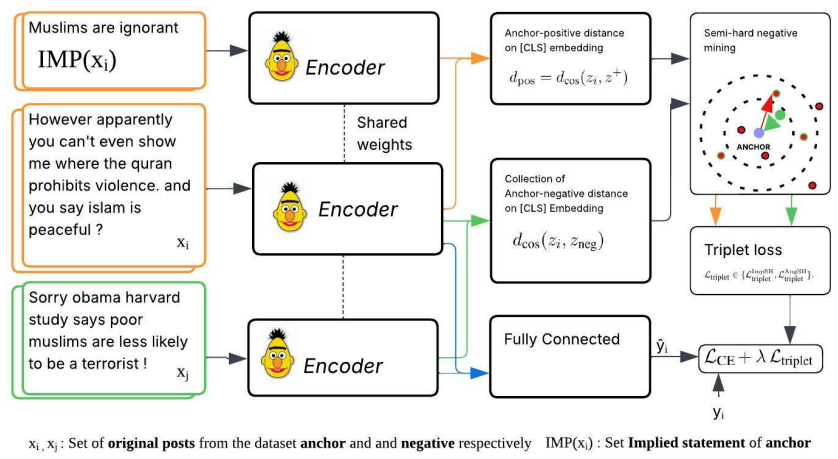
The ImpSH triplet-based framework that aligns posts with implied statements when available and employs context-bounded semi-hard negatives to focus learning.
Load-bearing premise
Implied statements are reliably available or generatable for training posts, and context-bounded semi-hard negative mining focuses learning on near confusions without introducing domain-specific biases.
What would settle it
A controlled test on a new dataset where implied statements cannot be reliably generated or where context-bounded mining yields no cross-domain gain over standard contrastive baselines would disprove the central claim.
Figures

read the original abstract
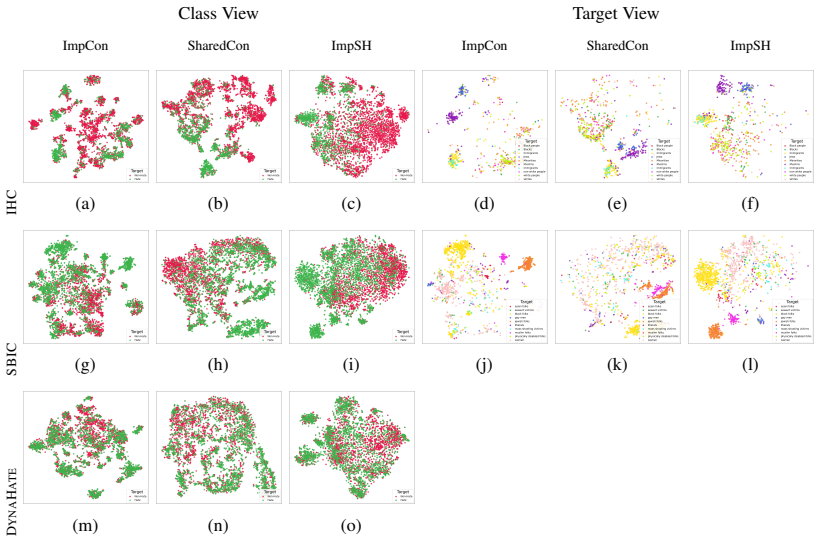
Classifying implicit hate speech remains a challenge, as intent is often masked through insinuation and context rather than explicit slurs. Prior supervised contrastive approaches improve in-domain detection but can overfit surface cues and struggle to transfer across datasets. We propose ImpSH, a triplet-based framework that aligns posts with implied statements when available and uses context-bounded semi-hard negatives to focus learning on near confusions. We also examine AugSH, which forms positives via data augmentation. In controlled evaluations on IHC, SBIC, and DynaHate with BERT and HateBERT, ImpSH is a viable alternative to standard supervised contrastive baselines and often improves cross-domain performance under matched preprocessing and tuning budgets. Representation analysis using alignment and uniformity indicates tighter positive pairs with balanced global spread, and qualitative nearest-neighbor case studies illustrate typical false negatives under domain shift. These results demonstrate that aligning posts with their implied statements via context-bounded mining provides a more stable, bijective-like mapping to related insinuations, overcoming the volatility inherent in traditional clustering-based representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ImpSH, a triplet-based contrastive framework for implicit hate speech detection. It aligns posts to implied statements (when available) and applies context-bounded semi-hard negative mining to focus on near confusions; AugSH is introduced as an augmentation-based positive-pair variant. Controlled experiments on IHC, SBIC, and DynaHate using BERT and HateBERT claim that ImpSH is a viable alternative to standard supervised contrastive baselines and often yields better cross-domain transfer under matched budgets. Supporting evidence includes alignment/uniformity metrics showing tighter positives with balanced spread and qualitative nearest-neighbor analysis of domain-shift false negatives. The central argument is that this alignment produces a more stable, bijective-like mapping than clustering-based representation learning.
Significance. If the cross-domain gains and representation properties are substantiated, the work would offer a concrete mechanism for reducing surface-cue overfitting in implicit hate speech detection and improving transfer across datasets that differ in annotation style and domain. The explicit use of implied statements and bounded negative mining provides a falsifiable alternative to purely unsupervised clustering approaches.
major comments (3)
- [Abstract] Abstract: the claim that ImpSH 'often improves cross-domain performance under matched preprocessing and tuning budgets' is presented without any accuracy/F1 numbers, standard deviations, ablation tables, or statistical tests. The central empirical assertion therefore rests on an unsupported high-level statement.
- [Abstract] Abstract: the method is qualified as operating 'when available' for implied statements, yet no coverage statistics, generation procedure, or fraction of posts possessing such statements across IHC/SBIC/DynaHate are supplied. This availability assumption is load-bearing for the alignment claim and the asserted bijective-like mapping.
- [Abstract] Abstract: no pseudocode, threshold definitions, or mining algorithm details are given for 'context-bounded semi-hard negative mining,' preventing assessment of whether the procedure consistently selects near-confusion negatives without domain-specific bias or overfitting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract can be strengthened to better support its claims with additional detail while remaining concise, and we will revise it accordingly. Point-by-point responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ImpSH 'often improves cross-domain performance under matched preprocessing and tuning budgets' is presented without any accuracy/F1 numbers, standard deviations, ablation tables, or statistical tests. The central empirical assertion therefore rests on an unsupported high-level statement.
Authors: The abstract is a high-level summary of results reported with full quantitative detail (including F1 scores, standard deviations, ablations, and statistical tests) in Sections 4 and 5. We acknowledge the abstract claim would benefit from concrete support and will revise it to include representative cross-domain performance numbers under the matched budgets. revision: yes
-
Referee: [Abstract] Abstract: the method is qualified as operating 'when available' for implied statements, yet no coverage statistics, generation procedure, or fraction of posts possessing such statements across IHC/SBIC/DynaHate are supplied. This availability assumption is load-bearing for the alignment claim and the asserted bijective-like mapping.
Authors: Coverage statistics, the generation procedure, and per-dataset fractions for implied statements are provided in Section 3.1. The abstract phrasing indicates the component is optional. We will revise the abstract to briefly note the availability rates across IHC, SBIC, and DynaHate. revision: yes
-
Referee: [Abstract] Abstract: no pseudocode, threshold definitions, or mining algorithm details are given for 'context-bounded semi-hard negative mining,' preventing assessment of whether the procedure consistently selects near-confusion negatives without domain-specific bias or overfitting.
Authors: The full pseudocode, threshold definitions, and algorithm for context-bounded semi-hard negative mining appear in Section 3.2 and Algorithm 1. Abstract length constraints limit us to a high-level description. We will revise the abstract to add a concise phrase characterizing the context-bounded selection criterion. revision: partial
Circularity Check
No circularity; empirical proposal with independent experimental support
full rationale
The paper presents ImpSH as an empirical triplet framework for implicit hate speech detection, relying on experimental evaluations across IHC, SBIC, and DynaHate datasets with BERT/HateBERT models, plus representation analysis (alignment/uniformity metrics) and qualitative case studies. No equations, derivations, or fitted parameters are defined in terms of the target claims; the 'bijective-like mapping' is an interpretive description of observed results rather than a self-referential equality. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims rest on controlled cross-domain comparisons under matched budgets, which are externally falsifiable and not reduced to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Supervised contrastive learning benefits from explicit alignment to implied statements for generalization
- ad hoc to paper Context-bounded semi-hard negatives focus learning on near confusions without harmful bias
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 29th International Conference on Computational Linguistics , editor =
Kim, Yejin and Park, Soojin and Han, Young-Sook , title =. Proceedings of the 29th International Conference on Computational Linguistics , editor =. 2022 , pages =
2022
-
[2]
ICLR , year=
Contrastive Learning with Hard Negative Samples , author=. ICLR , year=
-
[3]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Improved embeddings with easy positive triplet mining , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[4]
Zhang, Min and He, Jianfeng and Ji, Taoran and Lu, Chang-Tien. Don ' t Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLM s in Implicit Hate Speech Detection. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.652
-
[5]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Features or spurious artifacts? data-centric baselines for fair and robust hate speech detection , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=. 2022 , organization=
2022
-
[6]
Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models
R. Multilingual H ate C heck: Functional Tests for Multilingual Hate Speech Detection Models. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH). 2022. doi:10.18653/v1/2022.woah-1.15
-
[7]
International conference on machine learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Solving inefficiency of self-supervised representation learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
arXiv preprint arXiv:2308.14893 , year=
When hard negative sampling meets supervised contrastive learning , author=. arXiv preprint arXiv:2308.14893 , year=
-
[10]
Computer Vision and Image Understanding , volume=
Domain-aware triplet loss in domain generalization , author=. Computer Vision and Image Understanding , volume=. 2024 , publisher=
2024
-
[11]
Advances in neural information processing systems , volume=
Supervised contrastive learning , author=. Advances in neural information processing systems , volume=
-
[12]
International Conference on Machine Learning , pages=
Understanding contrastive learning requires incorporating inductive biases , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[13]
TENCON 2022-2022 IEEE Region 10 Conference (TENCON) , pages=
Combating high variance in data-scarce implicit hate speech classification , author=. TENCON 2022-2022 IEEE Region 10 Conference (TENCON) , pages=. 2022 , organization=
2022
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
Robust representation learning by clustering with bisimulation metrics for visual reinforcement learning with distractions , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
International Conference on Machine Learning , pages=
Understanding self-supervised learning dynamics without contrastive pairs , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[16]
arXiv preprint arXiv:2206.09917 , year=
Multilingual HateCheck: Functional tests for multilingual hate speech detection models , author=. arXiv preprint arXiv:2206.09917 , year=
-
[17]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Facenet: A unified embedding for face recognition and clustering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[18]
Proceedings of the IEEE international conference on computer vision , pages=
Sampling matters in deep embedding learning , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[19]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[20]
Advances in neural information processing systems , volume=
Hard negative mixing for contrastive learning , author=. Advances in neural information processing systems , volume=
-
[21]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[22]
Remote Sensing , volume =
Deep Metric Learning with Online Hard Mining for Hyperspectral Classification , author =. Remote Sensing , volume =. 2021 , publisher =
2021
-
[23]
A Metric Learning Reality Check
Musgrave, Kevin and Belongie, Serge and Lim, Ser-Nam. A Metric Learning Reality Check. Computer Vision -- ECCV 2020. 2020
2020
-
[24]
Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
Vidgen, Bertie and Thrush, Tristan and Waseem, Zeerak and Kiela, Douwe. Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. d...
-
[25]
and Choi, Yejin , title =
Sap, Maarten and Gabriel, Saadia and Qin, Leo and Jurafsky, Dan and Smith, Noah A. and Choi, Yejin , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
-
[26]
Latent Hatred: A Benchmark for Understanding Implicit Hate Speech
ElSherief, Mai and Ziems, Caleb and Muchlinski, David and Anupindi, Vaishnavi and Seybolt, Jordyn and De Choudhury, Munmun and Yang, Diyi. Latent Hatred: A Benchmark for Understanding Implicit Hate Speech. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.29
-
[27]
International Conference on Learning Representations (ICLR) , year=
Supervised contrastive learning for pre-trained language model fine-tuning , author=. International Conference on Learning Representations (ICLR) , year=
-
[28]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[29]
H ate BERT : Retraining BERT for Abusive Language Detection in E nglish
Caselli, Tommaso and Basile, Valerio and Mitrovi \'c , Jelena and Granitzer, Michael. H ate BERT : Retraining BERT for Abusive Language Detection in E nglish. Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021). 2021. doi:10.18653/v1/2021.woah-1.3
-
[30]
Proceedings of the international AAAI conference on web and social media , number=
Automated hate speech detection and the problem of offensive language , author=. Proceedings of the international AAAI conference on web and social media , number=
-
[31]
arXiv preprint arXiv:1703.07737 , year=
In defense of the triplet loss for person re-identification , author=. arXiv preprint arXiv:1703.07737 , year=
-
[32]
Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on T witter
Waseem, Zeerak and Hovy, Dirk. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on T witter. Proceedings of the NAACL Student Research Workshop. 2016. doi:10.18653/v1/N16-2013
-
[33]
Proceedings of the 26th international conference on World Wide Web companion , pages=
Deep learning for hate speech detection in tweets , author=. Proceedings of the 26th international conference on World Wide Web companion , pages=
-
[34]
Proceedings of the international AAAI conference on web and social media , number=
Large scale crowdsourcing and characterization of twitter abusive behavior , author=. Proceedings of the international AAAI conference on web and social media , number=
-
[35]
Proceedings of the 2017 ACM on web science conference , pages=
A large labeled corpus for online harassment research , author=. Proceedings of the 2017 ACM on web science conference , pages=
2017
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Alignment-uniformity aware representation learning for zero-shot video classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Improving Contrastive Learning of Sentence Embeddings with Focal I nfo NCE
Hou, Pengyue and Li, Xingyu. Improving Contrastive Learning of Sentence Embeddings with Focal I nfo NCE. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.315
-
[38]
D iff CSE : Difference-based Contrastive Learning for Sentence Embeddings
Chuang, Yung-Sung and Dangovski, Rumen and Luo, Hongyin and Zhang, Yang and Chang, Shiyu and Soljacic, Marin and Li, Shang-Wen and Yih, Scott and Kim, Yoon and Glass, James. D iff CSE : Difference-based Contrastive Learning for Sentence Embeddings. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Lingui...
-
[39]
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi. S im CSE : Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.552
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Augmentation in Embedding Space for Deep Metric Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
arXiv preprint arXiv:2011.11765 , year=
Boosting contrastive self-supervised learning with false negatives , author=. arXiv preprint arXiv:2011.11765 , year=
arXiv 2011
-
[42]
2025 , note=
Contrastive Learning - SimCLR and BYOL (With Code Example) , author=. 2025 , note=
2025
-
[43]
Not All Negatives are Equal: L abel-Aware Contrastive Loss for Fine-grained Text Classification
Suresh, Varsha and Ong, Desmond. Not All Negatives are Equal: L abel-Aware Contrastive Loss for Fine-grained Text Classification. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.359
-
[44]
Advances in neural information processing systems , volume=
Debiased contrastive learning , author=. Advances in neural information processing systems , volume=
-
[45]
arXiv preprint arXiv:2010.04592 , year=
Contrastive learning with hard negative samples , author=. arXiv preprint arXiv:2010.04592 , year=
arXiv 2010
-
[46]
EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Wei, Jason and Zou, Kai. EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1670
-
[47]
arXiv preprint arXiv:1511.06709 , year=
Improving neural machine translation models with monolingual data , author=. arXiv preprint arXiv:1511.06709 , year=
-
[48]
arXiv preprint arXiv:2004.10964 , year=
Don't stop pretraining: Adapt language models to domains and tasks , author=. arXiv preprint arXiv:2004.10964 , year=
arXiv 2004
-
[49]
Symmetry , volume=
Deep metric learning: A survey , author=. Symmetry , volume=. 2019 , publisher=
2019
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-similarity loss with general pair weighting for deep metric learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Boosting contrastive self-supervised learning with false negative cancellation , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[52]
arXiv preprint arXiv:2104.09540 , year=
Sentence Embeddings using Supervised Contrastive Learning , author=. arXiv preprint arXiv:2104.09540 , year=
-
[53]
arXiv preprint arXiv:2406.15175 , year=
Enhancing idiomatic representation in multiple languages via an adaptive contrastive triplet loss , author=. arXiv preprint arXiv:2406.15175 , year=
-
[54]
arXiv preprint arXiv:2210.11173 , year=
Mathematical Justification of Hard Negative Mining via Isometric Approximation Theorem , author=. arXiv preprint arXiv:2210.11173 , year=
-
[55]
Journal of Visual Communication and Image Representation , volume=
Semantic granularity metric learning for visual search , author=. Journal of Visual Communication and Image Representation , volume=. 2020 , publisher=
2020
-
[56]
European conference on computer vision , pages=
Hard negative examples are hard, but useful , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[57]
IEEE Transactions on Affective Computing , volume=
Hybrid contrastive learning of tri-modal representation for multimodal sentiment analysis , author=. IEEE Transactions on Affective Computing , volume=. 2022 , publisher=
2022
-
[58]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
SharedCon: Implicit hate speech detection using shared semantics , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[59]
arXiv preprint arXiv:2010.07414 , year=
On cross-dataset generalization in automatic detection of online abuse , author=. arXiv preprint arXiv:2010.07414 , year=
arXiv 2010
-
[60]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
The risk of racial bias in hate speech detection , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[61]
HateCheck: Functional tests for hate speech detection models , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[62]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
The hitchhiker’s guide to testing statistical significance in natural language processing , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[63]
International conference on machine learning , pages=
Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[64]
Advances in Neural Information Processing Systems , volume=
Id and ood performance are sometimes inversely correlated on real-world datasets , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.