Decoupling Search from Reasoning: A Vendor-Agnostic Grounding Architecture for LLM Agents
Pith reviewed 2026-06-26 21:04 UTC · model grok-4.3
The pith
Decoupling search from reasoning lets LLM agents match native accuracy at 91% lower search cost while keeping strict output contracts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
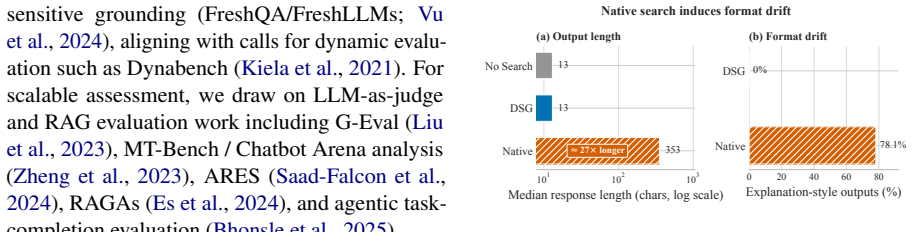
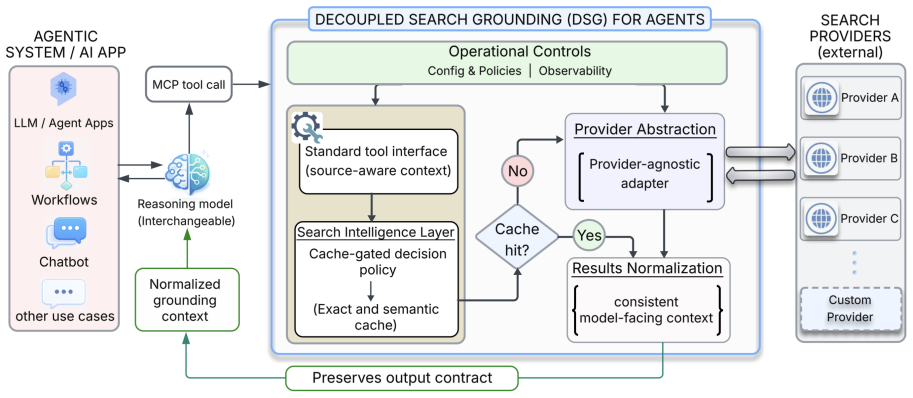
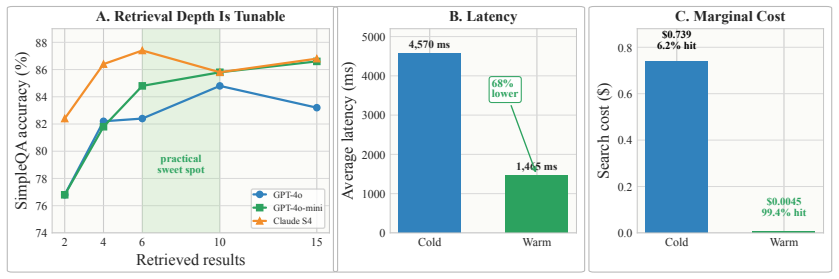
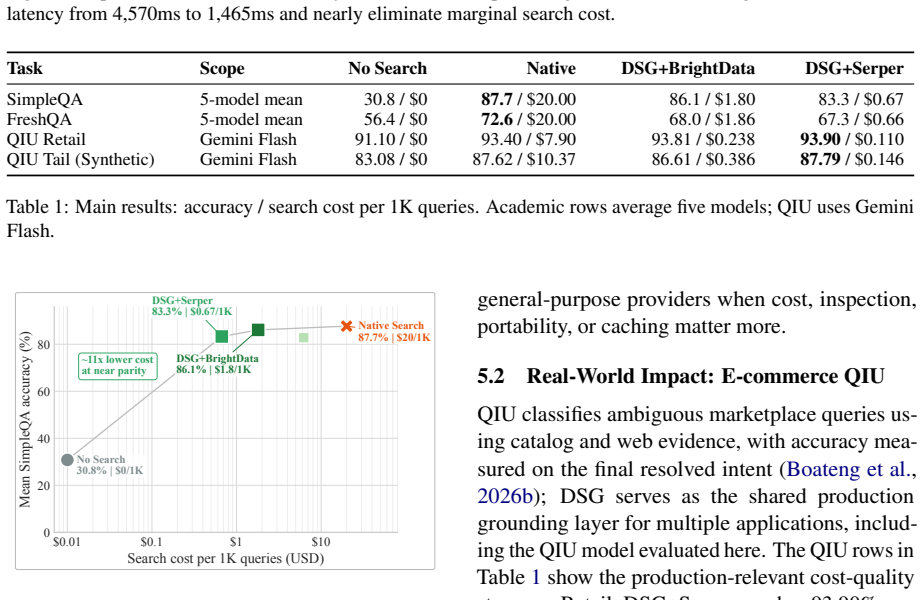
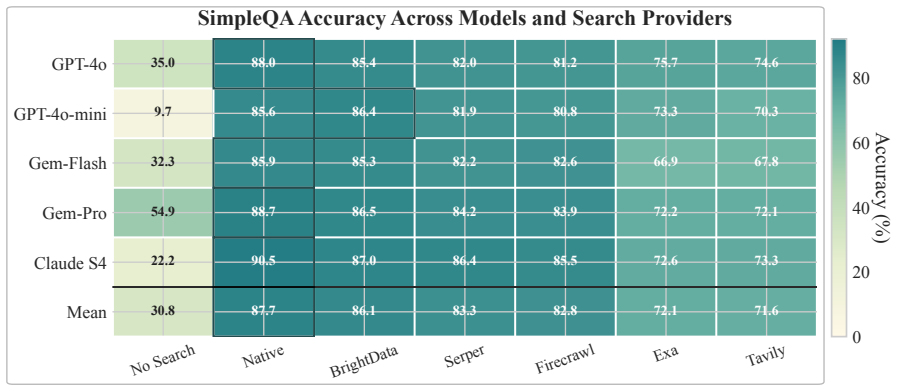
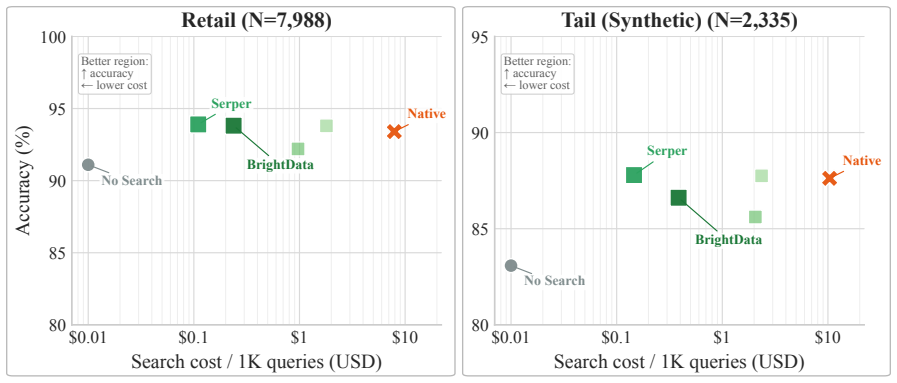
Decoupled Search Grounding (DSG) is a vendor-agnostic boundary that moves grounding outside the reasoning model through an MCP-compatible gateway, exposing provider routing, source-aware context rendering, configured fallback, retrieval-depth control, and exact plus semantic caching as first-class controls. On SimpleQA it nearly matches native accuracy (86.1% vs 87.7%) at 91% lower search cost, preserves concise answer contracts, and reaches a 99.4% warm-cache hit rate with 68% lower latency. Deployed as a shared production grounding layer for interchangeable models on an e-commerce query-understanding workload, DSG matches or slightly exceeds native-search accuracy while cutting search cost
What carries the argument
Decoupled Search Grounding (DSG), the vendor-agnostic MCP-compatible gateway that separates retrieval policy, evidence injection, and caching from the downstream reasoning model.
If this is right
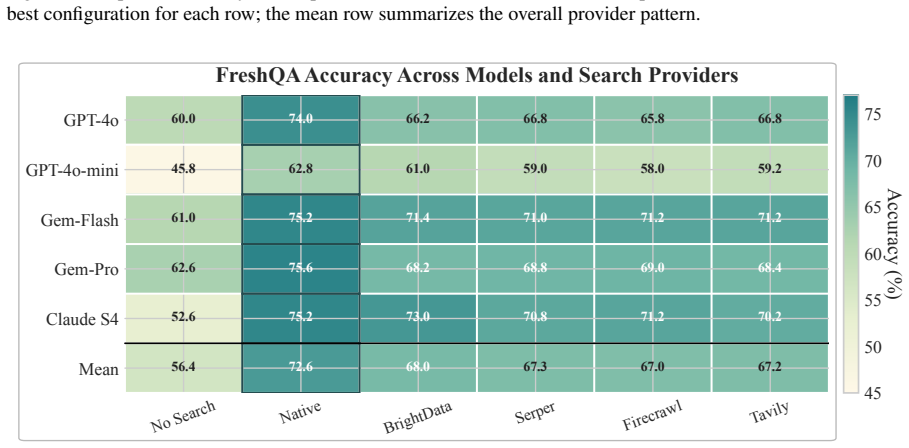
- Native search remains preferable on recency-sensitive tasks such as FreshQA, but DSG supplies stronger control on tasks where accuracy, cost, and output format must be managed independently.
- A single DSG layer can serve as shared grounding infrastructure for multiple interchangeable reasoning models in production agentic workloads.
- Exact and semantic caching inside the gateway produces 99.4% warm-hit rates and 68% lower latency without changing the reasoning model.
- Search cost reductions of 91% on SimpleQA and over 98% on the e-commerce QIU workload are achieved while accuracy stays at or above native levels.
Where Pith is reading between the lines
- The separation allows grounding policies to be audited, versioned, and optimized on their own schedule rather than being locked to model releases.
- Porting an agent between model providers becomes simpler because the retrieval and evidence-injection logic no longer has to be re-tuned inside each new model.
- Shared production grounding layers could be extended to enforce organization-wide retrieval rules or compliance filters across many agents without touching the reasoning models.
Load-bearing premise
The MCP-compatible gateway can be implemented to deliver the listed controls without introducing new errors in evidence injection or altering the downstream reasoning model's behavior in ways not captured by the reported metrics.
What would settle it
An implementation of the DSG gateway followed by side-by-side comparison of reasoning-model outputs for any systematic change in answer style, hallucination rate, or reasoning path that is not explained by the accuracy, cost, or latency numbers already reported.
Figures

read the original abstract
Production LLM agents increasingly depend on real-time search, yet native search grounding bundles retrieval policy, provider choice, evidence injection, cost, latency, and generation behavior behind a single model-provider boundary. This coupling makes grounding hard to inspect, tune, reuse, or port, and can trigger Search-Induced Verbosity that breaks strict output contracts. We present Decoupled Search Grounding (DSG), a vendor-agnostic boundary that moves grounding outside the reasoning model through an MCP-compatible gateway, exposing provider routing, source-aware context rendering, configured fallback, retrieval-depth control, and exact plus semantic caching as first-class controls. Across five frontier models on SimpleQA, FreshQA, and HotpotQA, native search leads on recency-sensitive FreshQA, but DSG exposes a stronger frontier when control matters: on SimpleQA it nearly matches native accuracy (86.1% vs. 87.7%) at 91% lower search cost, preserves concise answer contracts, and reaches a 99.4% warm-cache hit rate with 68% lower latency. Deployed as a shared production grounding layer for large-scale agentic workloads with interchangeable models, DSG matches or slightly exceeds native-search accuracy on an e-commerce query-understanding (QIU) workload while cutting search cost by over 98%. Real-time grounding is best treated as an optimizable interface boundary, not a fixed model feature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Decoupled Search Grounding (DSG), a vendor-agnostic architecture that moves search/retrieval outside the reasoning model via an MCP-compatible gateway. The gateway exposes explicit controls for provider routing, source-aware context rendering, configured fallback, retrieval-depth, and exact/semantic caching. Empirical results across five frontier models on SimpleQA, FreshQA, and HotpotQA show native search leading on recency-sensitive tasks but DSG achieving near-parity accuracy (e.g., 86.1% vs. 87.7% on SimpleQA) at 91% lower search cost, 68% lower latency, 99.4% warm-cache hit rate, and preserved output contracts; a production e-commerce query-understanding deployment reports matching or exceeding native accuracy with >98% cost reduction.
Significance. If the gateway can be shown to deliver the stated controls while preserving downstream model behavior, the work offers a practical contribution to agentic LLM systems by enabling reusable, tunable grounding independent of model providers. The concrete cross-model and production numbers on cost/latency/cache performance provide falsifiable evidence for treating grounding as an optimizable interface boundary.
major comments (2)
- [Evaluation results on SimpleQA and production QIU workload] The central claim that DSG preserves downstream reasoning behavior rests on accuracy parity alone (SimpleQA: 86.1% vs. 87.7%); no verification is provided that source-aware context rendering, evidence injection, or caching logic maintains semantic equivalence of sources or avoids reordering/dropping that could affect chain-of-thought or contract adherence on other inputs.
- [Gateway architecture and controls description] No ablation, error analysis, or implementation details are given for the MCP-compatible gateway's controls (routing, fallback, depth, caching); the reported metrics therefore do not rule out new errors in evidence handling introduced by the gateway itself.
minor comments (2)
- The reported accuracy, cost, and latency figures lack error bars, dataset split details, and statistical tests.
- Consider adding a figure or pseudocode illustrating the gateway's context-rendering and caching logic for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point-by-point below, indicating where revisions will be made to strengthen the presentation of evidence while remaining faithful to the experiments and data already collected.
read point-by-point responses
-
Referee: [Evaluation results on SimpleQA and production QIU workload] The central claim that DSG preserves downstream reasoning behavior rests on accuracy parity alone (SimpleQA: 86.1% vs. 87.7%); no verification is provided that source-aware context rendering, evidence injection, or caching logic maintains semantic equivalence of sources or avoids reordering/dropping that could affect chain-of-thought or contract adherence on other inputs.
Authors: We agree that accuracy parity on the reported benchmarks is not by itself a complete demonstration of semantic equivalence or invariance under reordering. The manuscript does note that DSG preserves concise answer contracts in the production QIU deployment (where it matches or exceeds native accuracy), but this is still indirect evidence. We will add a dedicated error-analysis subsection that examines the (small) set of cases where DSG and native search disagree, together with a qualitative discussion of how the source-aware rendering and caching logic are designed to avoid reordering or dropping. Because we cannot run new experiments at this stage, the revision will be partial and will focus on deeper analysis of existing results. revision: partial
-
Referee: [Gateway architecture and controls description] No ablation, error analysis, or implementation details are given for the MCP-compatible gateway's controls (routing, fallback, depth, caching); the reported metrics therefore do not rule out new errors in evidence handling introduced by the gateway itself.
Authors: The manuscript presents the gateway controls at the architectural level but does not include ablations, detailed error analysis, or low-level implementation pseudocode. We accept that this leaves open the possibility of gateway-introduced artifacts. In the revised manuscript we will expand the architecture section with concrete implementation details for each control, add an error-analysis paragraph that enumerates potential failure modes (e.g., cache-induced staleness, fallback misrouting), and include a limited ablation on retrieval depth and caching policy using the existing evaluation harness. These additions will directly address the concern. revision: yes
Circularity Check
No circularity; all claims are direct empirical measurements
full rationale
The paper introduces the DSG architecture as a vendor-agnostic gateway and evaluates it via direct measurements of accuracy (e.g., 86.1% vs 87.7% on SimpleQA), search cost reductions (91%, 98%), latency (68% lower), cache hit rate (99.4%), and contract preservation on fixed benchmarks (SimpleQA, FreshQA, HotpotQA) plus a live e-commerce workload. No equations, fitted parameters, or derivations appear; results are reported as observed outcomes rather than quantities defined by or predicted from internal fits. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on external benchmark performance and production metrics, which are independently falsifiable and do not reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An MCP-compatible gateway can expose provider routing, source-aware rendering, fallback, depth control, and dual caching without interfering with the LLM reasoning process or output contract.
invented entities (1)
-
DSG gateway
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems , volume =
-
[2]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. arXiv preprint arXiv:2507.06261 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2026 , howpublished =
Grounding with Google Search , author =. 2026 , howpublished =
2026
-
[4]
Augmented Language Models: a Survey
Augmented Language Models: A Survey , author =. arXiv preprint arXiv:2302.07842 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The Eleventh International Conference on Learning Representations , year =
ReAct: Synergizing Reasoning and Acting in Language Models , author =. The Eleventh International Conference on Learning Representations , year =
-
[6]
2023 , doi =
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , booktitle =. 2023 , doi =
2023
-
[7]
2024 , note =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , note =
2024
-
[8]
2021 , url =
Nakano, Reiichiro and Hilton, Jacob and Balaji, Suchir and Wu, Jeff and Ouyang, Long and Kim, Christina and Hesse, Christopher and Jain, Shantanu and Kosaraju, Vineet and Saunders, William and Jiang, Xu and Cobbe, Karl and Eloundou, Tyna and Krueger, Gretchen and Button, Kevin and Knight, Matthew and Chess, Benjamin and Schulman, John , journal =. 2021 , url =
2021
-
[9]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =
-
[10]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , doi =
2020
-
[11]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages =
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages =. 2021 , doi =
2021
-
[12]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Active Retrieval Augmented Generation , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , doi =
2023
-
[13]
2023 , doi =
Gao, Luyu and Dai, Zhuyun and Pasupat, Panupong and Chen, Anthony and Chaganty, Arun Tejasvi and Fan, Yicheng and Zhao, Vincent and Lao, Ni and Lee, Hongrae and Juan, Da-Cheng and Guu, Kelvin , booktitle =. 2023 , doi =
2023
-
[14]
2024 , note =
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. 2024 , note =
2024
-
[15]
, booktitle =
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong C. , booktitle =. 2024 , doi =
2024
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , doi =
2023
-
[17]
Measuring short-form factuality in large language models
Measuring Short-Form Factuality in Large Language Models , author =. arXiv preprint arXiv:2411.04368 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2024 , doi =
Vu, Tu and Iyyer, Mohit and Wang, Xuezhi and Constant, Noah and Wei, Jerry and Wei, Jason and Tar, Chris and Sung, Yun-Hsuan and Zhou, Denny and Le, Quoc and Luong, Thang , booktitle =. 2024 , doi =
2024
-
[19]
, booktitle =
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =. 2018 , doi =
2018
-
[20]
2024 , doi =
Saad-Falcon, Jon and Khattab, Omar and Potts, Christopher and Zaharia, Matei , booktitle =. 2024 , doi =
2024
-
[21]
2024 , url =
Es, Shahul and James, Jithin and Espinosa-Anke, Luis and Schockaert, Steven , booktitle =. 2024 , url =
2024
-
[22]
2023 , doi =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , doi =
2023
-
[23]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[24]
2021 , doi =
Kiela, Douwe and Bartolo, Max and Nie, Yixin and Kaushik, Divyansh and Geiger, Atticus and Wu, Zhengxuan and Vidgen, Bertie and Prasad, Grusha and Singh, Amanpreet and Ringshia, Pratik and Ma, Zhiyi and Thrush, Tristan and Riedel, Sebastian and Waseem, Zeerak and Stenetorp, Pontus and Jia, Robin and Bansal, Mohit and Potts, Christopher and Williams, Adina...
2021
-
[25]
Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025) , pages =
Demystify Verbosity Compensation Behavior of Large Language Models , author =. Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025) , pages =. 2025 , doi =
2025
-
[26]
arXiv preprint arXiv:2601.05503 , year =
Over-Searching in Search-Augmented Large Language Models , author =. arXiv preprint arXiv:2601.05503 , year =
-
[27]
Agentic Multi-Source Grounding for Enhanced Query Intent Understanding: A
Boateng, Emmanuel Aboah and MacDonald, Kyle and Viswanathan, Akshad and Das, Sudeep , journal =. Agentic Multi-Source Grounding for Enhanced Query Intent Understanding: A. 2026 , url =
2026
-
[28]
, journal =
Hasan, Mohammed Mehedi and Li, Hao and Rajbahadur, Gopi Krishnan and Adams, Bram and Hassan, Ahmed E. , journal =. Model Context Protocol (. 2026 , url =
2026
-
[29]
Bridging Protocol and Production: Design Patterns for Deploying
Srinivasan, Vasundra , journal =. Bridging Protocol and Production: Design Patterns for Deploying. 2026 , url =
2026
-
[30]
Implementing Retrieval Augmented Generation Technique on Unstructured and Structured Data Sources in a Call Center of a Large Financial Institution , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track) , pages =. 2025 , doi =
2025
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages =
Proactive Guidance of Multi-Turn Conversation in Industrial Search , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages =. 2025 , doi =
2025
-
[32]
2025 , doi =
Chen, Qinwen and Tao, Wenbiao and Zhu, Zhiwei and Xi, Mingfan and Guo, Liangzhong and Wang, Yuan and Wang, Wei and Lan, Yunshi , booktitle =. 2025 , doi =
2025
-
[33]
Retrieval Enhancements for
Gonz. Retrieval Enhancements for. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages =. 2026 , doi =
2026
-
[34]
arXiv preprint arXiv:2508.05508 , year =
Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation , author =. arXiv preprint arXiv:2508.05508 , year =
-
[35]
and Xia, T
Boateng, Emmanuel Aboah and Johnson, Z. and Xia, T. and Zhang, S. and Jay, A. and Feng, J. and Mate, A. and others , booktitle =
-
[36]
2025 , note =
Using Large Generative Models to Improve the Performance of Weak Language Models in Performing Complex Tasks , author =. 2025 , note =
2025
-
[37]
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
2025
-
[38]
The Eleventh International Conference on Learning Representations , year =
Large Language Models Are Human-Level Prompt Engineers , author =. The Eleventh International Conference on Learning Representations , year =
-
[39]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.