Sumi: Open Uniform Diffusion Language Model from Scratch
Pith reviewed 2026-06-26 20:32 UTC · model grok-4.3
The pith
A 7B uniform diffusion language model trained from scratch on 1.5T tokens matches autoregressive models on knowledge and reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Sumi, a fully open 7B uniform diffusion language model pretrained from scratch on 1.5T tokens that performs competitively with autoregressive models trained at comparable token budgets on knowledge, reasoning, and coding benchmarks.
What carries the argument
Uniform diffusion language model, which permits any token to be updated at any step during the diffusion process.
If this is right
- Uniform diffusion models can be scaled to 7B parameters and 1.5T tokens while remaining competitive on several standard benchmarks.
- Releasing the complete training recipe and data mixture allows direct replication and controlled experiments on generation flexibility.
- The model provides a clean baseline for comparing scaling behavior and controllability against autoregressive and masked diffusion approaches.
Where Pith is reading between the lines
- Adjusting the data mixture in future runs could isolate whether uniform diffusion itself carries any inherent advantage or disadvantage on commonsense tasks.
- The open release may enable targeted tests of controllability features that uniform diffusion is claimed to support in principle.
Load-bearing premise
The underperformance on commonsense benchmarks is primarily due to the education-heavy data mixture rather than inherent limits of the uniform diffusion method.
What would settle it
Retraining Sumi or an equivalent model with a data mixture that reduces the education-heavy component and measuring whether commonsense benchmark scores rise to match autoregressive levels.
Figures
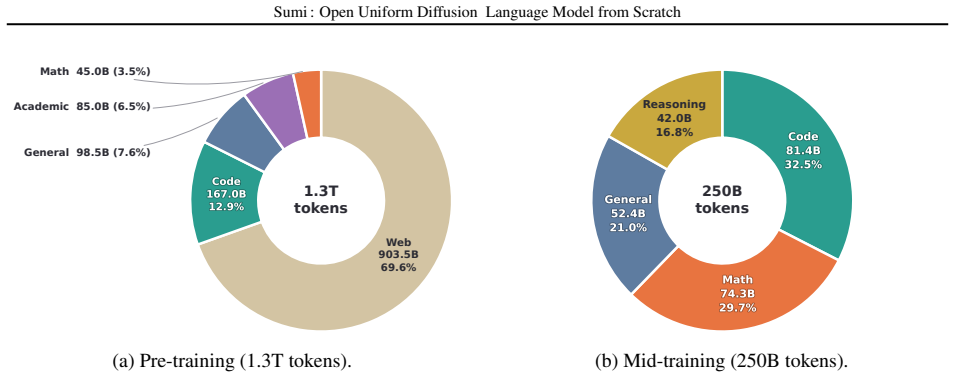
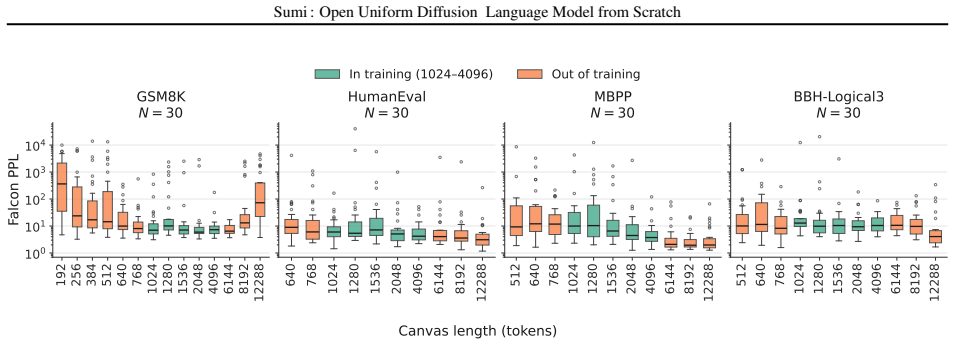

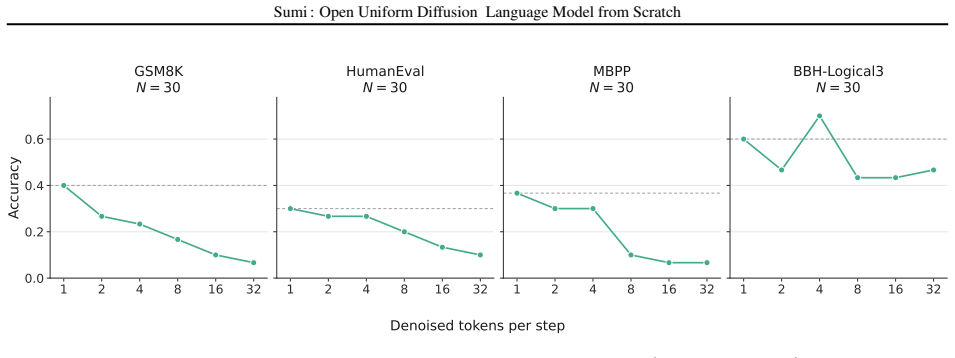
read the original abstract
Diffusion models have become a promising alternative to autoregressive models. Among these, uniform diffusion language models (UDLMs) permit any token to be updated at any step, in principle enabling more flexible generation. However, no UDLM has yet been pretrained from scratch at both large parameter scale and large token budget. Both autoregressive modeling and masked diffusion modeling already have capable models at scale that the community can study and build on; uniform diffusion has none. A scratch-pretrained UDLM at scale would provide a clean reference point for studying scaling behavior, generation dynamics, controllability, and trade-offs against established autoregressive and masked diffusion models. To this end, we introduce Sumi ("ink" in Japanese), a fully open 7B uniform diffusion language model pretrained from scratch on 1.5T tokens. Sumi performs competitively with autoregressive models trained at comparable token budgets on knowledge, reasoning, and coding benchmarks, while under-performing on commonsense benchmarks, where our education-heavy data mixture is a likely contributor. We release our model weights, checkpoints, and full training recipe, including a complete specification of the data mixture over publicly available corpora. We hope this release enables the community to study native uniform diffusion at scale and catalyzes work on its as-yet poorly understood aspects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sumi, a 7B-parameter uniform diffusion language model pretrained from scratch on 1.5T tokens. It claims competitive performance versus autoregressive models trained at comparable scale on knowledge, reasoning, and coding benchmarks, while reporting underperformance on commonsense benchmarks that the authors attribute to an education-heavy data mixture. The work releases model weights, checkpoints, and the full training recipe including a complete data-mixture specification over public corpora, positioning Sumi as a reference point for studying uniform diffusion at scale.
Significance. If the benchmark results hold after clarification, the release supplies the first open large-scale UDLM, addressing the absence of such models relative to scaled autoregressive and masked-diffusion counterparts. The explicit release of the complete data mixture and training recipe constitutes a concrete strength that supports reproducibility and community follow-up on scaling behavior and generation dynamics.
major comments (2)
- [Abstract] Abstract: the statement that commonsense underperformance is 'a likely contributor' of the education-heavy data mixture lacks any ablation, control experiment, or comparison to an autoregressive model trained on the identical mixture. This attribution is load-bearing for the central claim that Sumi supplies a clean reference separating modeling paradigm from data effects.
- [Abstract] Abstract / §4 (benchmark results): high-level claims of competitiveness are presented without naming the specific benchmarks, reporting exact scores, or listing the autoregressive baselines and token budgets used for comparison, preventing direct verification of the 'competitive' assertion.
minor comments (2)
- [Introduction] Introduction: the distinction between uniform diffusion and masked diffusion is referenced but not given a concise operational definition (e.g., token-update probability schedule) before the experimental sections.
- The data-mixture table (presumably in the training-recipe section) would benefit from an explicit column showing token counts per corpus to allow readers to reproduce the 'education-heavy' characterization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. Where the comments identify opportunities for clarification or textual revision, we will incorporate changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that commonsense underperformance is 'a likely contributor' of the education-heavy data mixture lacks any ablation, control experiment, or comparison to an autoregressive model trained on the identical mixture. This attribution is load-bearing for the central claim that Sumi supplies a clean reference separating modeling paradigm from data effects.
Authors: We agree that the phrasing in the abstract presents the data-mixture explanation as a hypothesis without supporting ablation or a matched autoregressive baseline. The central contribution of Sumi as a reference point rests on the public release of weights, checkpoints, and the complete data-mixture specification over public corpora, which enables future controlled comparisons rather than on any claim about the source of the observed gap. We will revise the abstract to remove the speculative attribution and instead note the observed pattern while emphasizing the openness of the training recipe. revision: yes
-
Referee: [Abstract] Abstract / §4 (benchmark results): high-level claims of competitiveness are presented without naming the specific benchmarks, reporting exact scores, or listing the autoregressive baselines and token budgets used for comparison, preventing direct verification of the 'competitive' assertion.
Authors: Section 4 of the manuscript already contains the full set of benchmark names, exact scores, autoregressive baselines, and token budgets. To improve readability of the abstract, we will revise it to name the primary benchmarks (e.g., MMLU, GSM8K, HumanEval) and report the key comparative scores against the cited autoregressive models trained at comparable scale. revision: yes
Circularity Check
No significant circularity; empirical training and benchmarking results are self-contained
full rationale
The paper reports results from pretraining a 7B UDLM from scratch on 1.5T tokens and evaluating on standard benchmarks. No equations, derivations, or 'predictions' are presented that reduce to fitted parameters or self-citations by construction. The competitiveness claims rest on direct model training and external benchmark comparisons, which are falsifiable outside the paper. The data-mixture interpretation for commonsense underperformance is an untested hypothesis but does not form a load-bearing circular step in any derivation chain. This matches the default case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Blázquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydlíček, A. P. Lajarín, V. Srivastav, J. Lochner, C. Fahlgren, X.-S. Nguyen, C. Fourrier, B. Burtenshaw, H. Larcher, H. Zhao, C. Zakka, M. Morlon, C. Raffel, L. von Werra, and T. Wolf. Smollm2: When smol goes big -- data-centric training of a small language mode...
Pith/arXiv arXiv 2025
-
[2]
E. Almazrouei, H. Alobeidli, A. Alshamsi, A. Cappelli, R. Cojocaru, M. Debbah, Étienne Goffinet, D. Hesslow, J. Launay, Q. Malartic, D. Mazzotta, B. Noune, B. Pannier, and G. Penedo. The falcon series of open language models, 2023. URL https://arxiv.org/abs/2311.16867
Pith/arXiv arXiv 2023
-
[3]
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021. URL https://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[4]
Y. Bisk, R. Zellers, R. Le Bras, J. Gao, and Y. Choi. PIQA : Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432--7439, 2020. URL https://ojs.aaai.org/index.php/AAAI/article/view/6239
2020
-
[5]
Y. Bondarenko, M. Nagel, and T. Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing. In Advances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2306.12929
arXiv 2023
-
[6]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. URL https://arxiv.org/abs/2107.03374
Pith/arXiv arXiv 2021
-
[7]
Chowdhery, S
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H...
2023
-
[8]
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try ARC , the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018. URL https://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[9]
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
Pith/arXiv arXiv 2021
-
[10]
DiffusionGemma
DeepMind . DiffusionGemma . https://deepmind.google/models/gemma/diffusiongemma/, 2026. Accessed: 2026-06-16
2026
-
[11]
K. Fujii, Y. Tajima, S. Mizuki, H. Shimada, T. Shiotani, K. Saito, M. Ohi, M. Kawamura, T. Nakamura, T. Okamoto, S. Ishida, K. Hattori, Y. Ma, H. Takamura, R. Yokota, and N. Okazaki. Rewriting pre-training data boosts llm performance in math and code, 2025. URL https://arxiv.org/abs/2505.02881
arXiv 2025
-
[12]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac'h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. The language model evaluation harness, 07 2024. URL https://zenodo.org/records/12608602
arXiv 2024
-
[13]
OLM o: Accelerating the science of language models
D. Groeneveld, I. Beltagy, E. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. Jha, H. Ivison, I. Magnusson, Y. Wang, S. Arora, D. Atkinson, R. Authur, K. Chandu, A. Cohan, J. Dumas, Y. Elazar, Y. Gu, J. Hessel, T. Khot, W. Merrill, J. Morrison, N. Muennighoff, A. Naik, C. Nam, M. Peters, V. Pyatkin, A. Ravichander, D. Schwenk, S. Shah, W. Smith, E. Strubell, ...
-
[14]
X. Gu, T. Pang, C. Du, Q. Liu, F. Zhang, C. Du, Y. Wang, and M. Lin. When attention sink emerges in language models: An empirical view. In International Conference on Learning Representations (ICLR), 2025. arXiv:2410.10781
Pith/arXiv arXiv 2025
-
[15]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/2009.03300
Pith/arXiv arXiv 2021
-
[16]
S. Hu, Y. Tu, X. Han, G. Cui, C. He, W. Zhao, X. Long, Z. Zheng, Y. Fang, Y. Huang, X. Zhang, Z. L. Thai, C. Wang, Y. Yao, C. Zhao, J. Zhou, J. Cai, Z. Zhai, N. Ding, C. Jia, G. Zeng, dahai li, Z. Liu, and M. Sun. Mini CPM : Unveiling the potential of small language models with scalable training strategies. In First Conference on Language Modeling, 2024. ...
2024
-
[17]
Kodama and Y
T. Kodama and Y. Oda. Comprehensive study of bilingual and multi-category instruction pre-training. In Findings of the A ssociation for C omputational L inguistics: EACL 2026 , pages 1323--1340, Rabat, Morocco, Mar. 2026. Association for Computational Linguistics. URL https://aclanthology.org/2026.findings-eacl.68/
2026
-
[18]
G. Lai, Q. Xie, H. Liu, Y. Yang, and E. Hovy. RACE : Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785--794, Copenhagen, Denmark, 2017. Association for Computational Linguistics. URL https://aclanthology.org/D17-1082/
2017
-
[19]
S. Lin, J. Hilton, and O. Evans. T ruthful QA : Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland, 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.acl-long.229/
2022
-
[20]
LLM-jp Corpus v4
LLM-jp . LLM-jp Corpus v4 . https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v4, 2025. Accessed: 2026-06-11
2025
-
[21]
LLM-jp Corpus v4.1
LLM-jp . LLM-jp Corpus v4.1 . https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v4.1, 2026. Accessed: 2026-06-11
2026
-
[22]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[23]
Lozhkov, L
A. Lozhkov, L. Ben Allal, L. von Werra, and T. Wolf. Fineweb-edu: the finest collection of educational content, 2024. URL https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
2024
-
[24]
E. Miller. Attention is off by one. https://www.evanmiller.org/attention-is-off-by-one.html, July 2023. Blog post, accessed 2026-06-15
2023
-
[25]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. ZHOU, Y. Lin, J.-R. Wen, and C. Li. Large language diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=KnqiC0znVF
2026
-
[26]
T. Olmo, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brahman, F. Timbers, H. Ivison, J. Morrison, J. Poznanski, K. Lo, L. Soldaini, M. Jordan, M. Chen, M. Noukhovitch, N. Lambert, P. Walsh, P. Dasigi, R. Berry, S. Malik, S. Shah, S. Geng, S. Arora, S. Gupta, T. Anderson, T. Xiao, T. Murray, T. Romero, V. Graf, A. Asai, A. ...
Pith/arXiv arXiv 2025
-
[27]
OpenAI, :, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao, B. Barak, A. Bennett, T. Bertao, N. Brett, E. Brevdo, G. Brockman, S. Bubeck, C. Chang, K. Chen, M. Chen, E. Cheung, A. Clark, D. Cook, M. Dukhan, C. Dvorak, K. Fives, V. Fomenko, T. Garipov, K. Georgiev, M. Glaese, T. Gogineni, A. Goucher, L....
Pith/arXiv arXiv 2025
-
[28]
G. Penedo, H. Kydlíček, L. B. allal, A. Lozhkov, M. Mitchell, C. Raffel, L. V. Werra, and T. Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URL https://arxiv.org/abs/2406.17557
Pith/arXiv arXiv 2024
-
[29]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. GPQA : A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling (COLM), 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[30]
S. S. Sahoo, J.-M. Lemercier, Z. Yang, J. Deschenaux, J. Liu, J. Thickstun, and A. Jukic. Scaling beyond masked diffusion language models, 2026. URL https://arxiv.org/abs/2602.15014
arXiv 2026
-
[31]
Sakaguchi, R
K. Sakaguchi, R. Le Bras, C. Bhagavatula, and Y. Choi. WinoGrande : An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8732--8740, 2020. URL https://ojs.aaai.org/index.php/AAAI/article/view/6399
2020
-
[32]
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019
Pith/arXiv arXiv 1909
-
[33]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomput., 568 0 (C), Feb. 2024. ISSN 0925-2312. doi:10.1016/j.neucom.2023.127063. URL https://doi.org/10.1016/j.neucom.2023.127063
-
[34]
Suzgun, N
M. Suzgun, N. Scales, N. Sch \"a rli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. Chi, D. Zhou, and J. Wei. Challenging BIG -bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023, pages 13003--13051, Toronto, Canada, 2023. Association for Computational Linguistic...
2023
-
[35]
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev,...
Pith/arXiv arXiv 2023
-
[36]
u tte, J. Fluri, Y. Ding, A. Orvieto, B. Sch \
D. von R \"u tte, J. Fluri, Y. Ding, A. Orvieto, B. Sch \"o lkopf, and T. Hofmann. Generalized interpolating discrete diffusion. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=rvZv7sDPV9
2025
-
[37]
u tte, J. Fluri, O. Pooladzandi, B. Sch \
D. von R \"u tte, J. Fluri, O. Pooladzandi, B. Sch \"o lkopf, T. Hofmann, and A. Orvieto. Scaling behavior of discrete diffusion language models. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=GDYaNzxt9T
2026
-
[38]
Z. Wang, F. Zhou, X. Li, and P. Liu. Octothinker: Mid-training incentivizes reinforcement learning scaling. arXiv preprint arXiv:2506.20512, 2025. Preprint
arXiv 2025
-
[39]
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. In International Conference on Learning Representations (ICLR), 2024. arXiv:2309.17453
Pith/arXiv arXiv 2024
-
[40]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
Pith/arXiv arXiv 2025
-
[41]
J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and L. Kong. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025
Pith/arXiv arXiv 2025
-
[42]
Zellers, A
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. HellaSwag : Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791--4800, Florence, Italy, 2019. Association for Computational Linguistics. URL https://aclanthology.org/P19-1472/
2019
-
[43]
F. Zhou, Z. Wang, N. Ranjan, Z. Cheng, L. Tang, G. He, Z. Liu, and E. P. Xing. Megamath: Pushing the limits of open math corpora. arXiv preprint arXiv:2504.02807, 2025. Preprint
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.