Towards an Agent-First Web: Redesigning the Web for AI Agents
Pith reviewed 2026-06-26 20:47 UTC · model grok-4.3
The pith
The web's human-centric design must be replaced by ten principles that make AI agents first-class participants across access, economics, and content layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
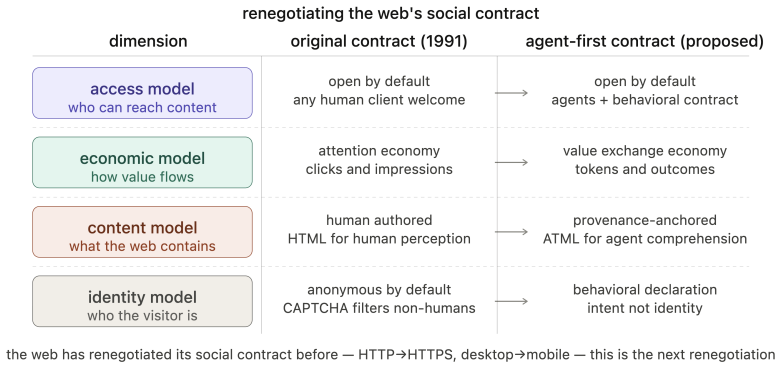
The rapid emergence of AI agents as intermediaries between humans and web content invalidates the human-centric assumption of the web, requiring a principled redesign across access, economic, and content layers that constitutes ten design principles for an agent-first internet.
What carries the argument
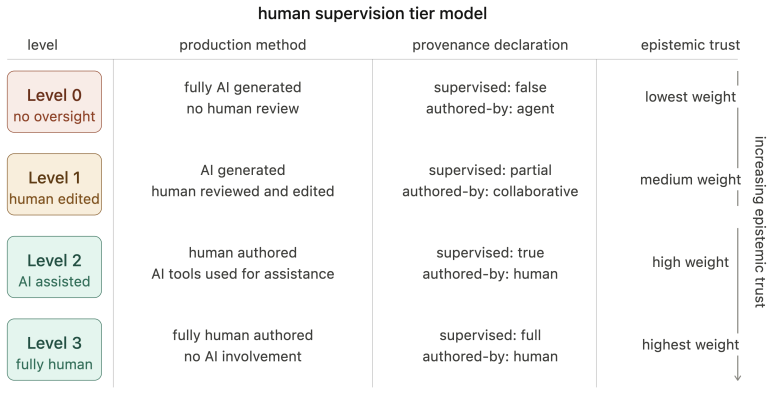
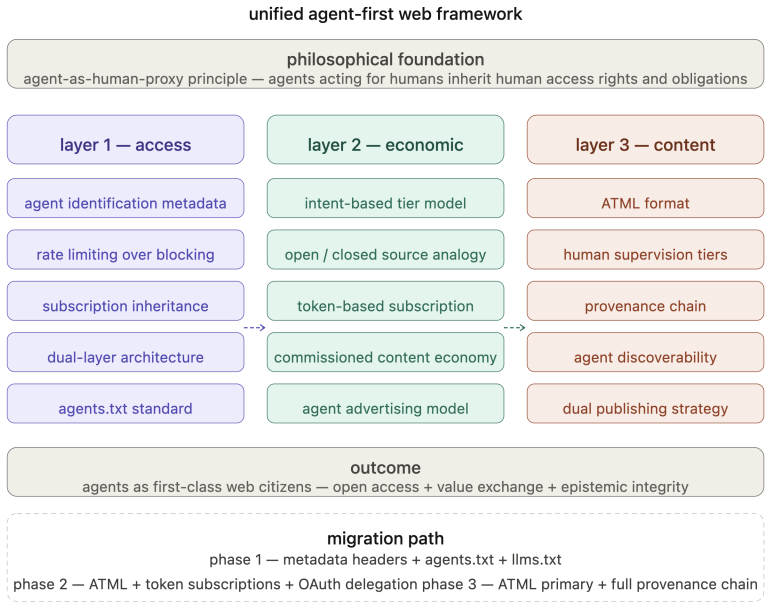
the three-layer architecture (access, economic, content) together with the Agent Text Markup Language (ATML) four-level human supervision model and cryptographic provenance chain
If this is right
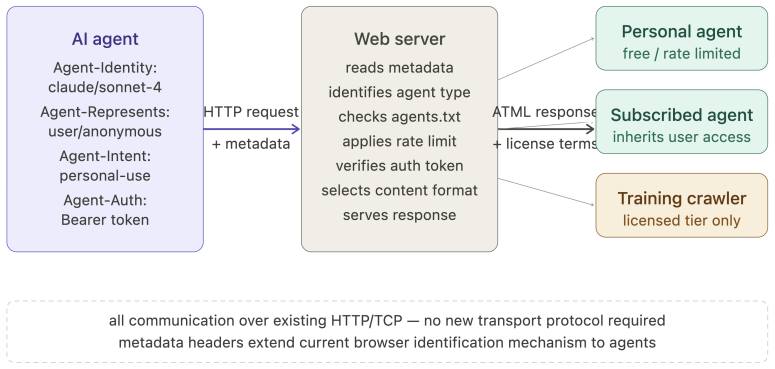
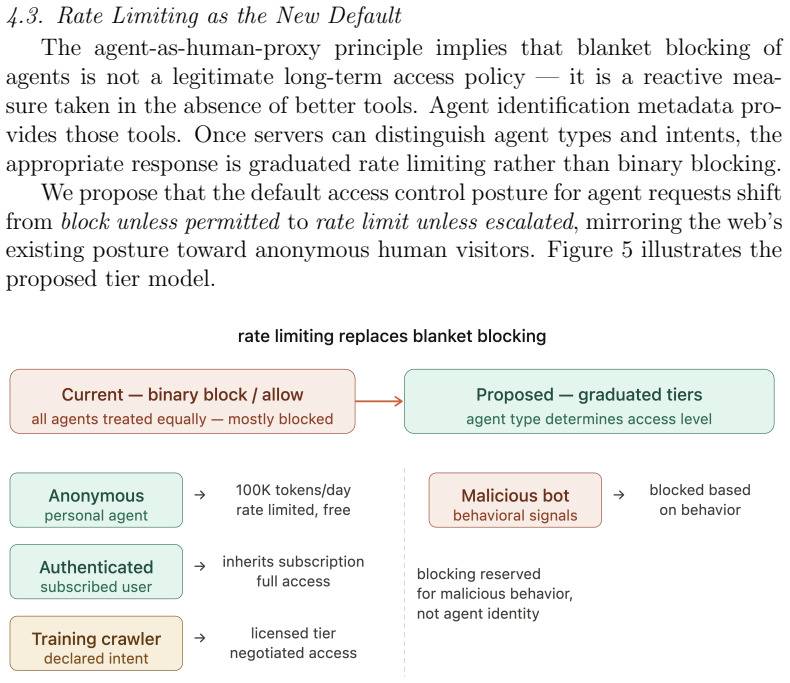
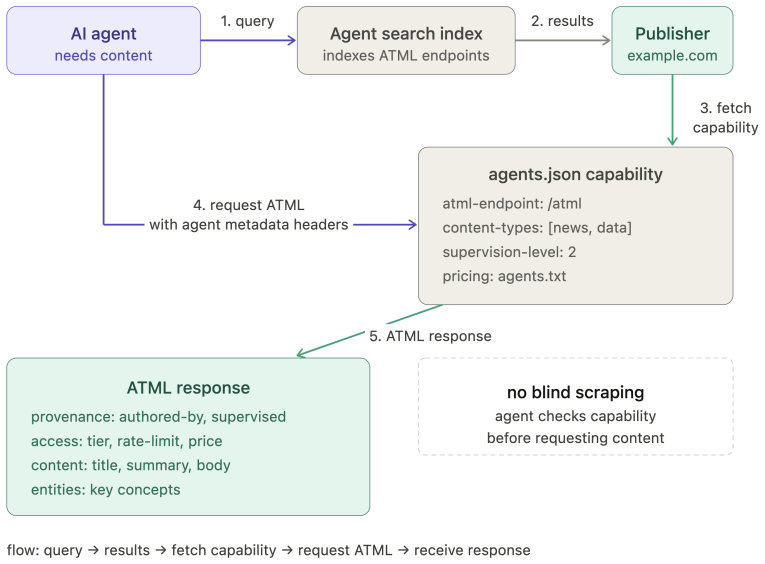
- Agents acting for humans inherit equivalent access rights governed by rate limiting and agent identification metadata in HTTP requests.
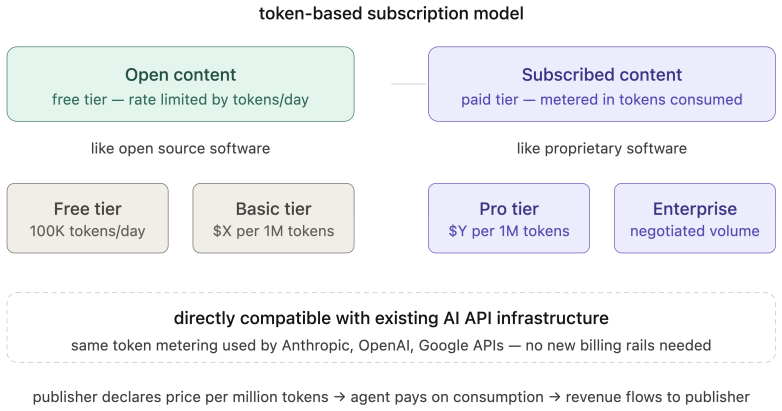
- An agent's economic obligation mirrors that of the human it represents through intent-based tiers and token-based metering instead of pageviews.
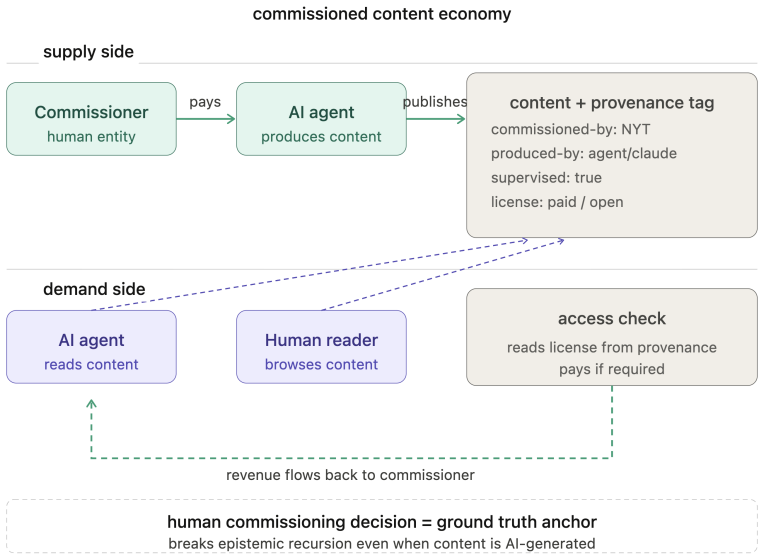
- The four-level ATML model with cryptographic provenance counters epistemic recursion by anchoring AI-generated content to human supervision.
- A commissioned content economy ties AI production to human intentionality rather than autonomous loops.
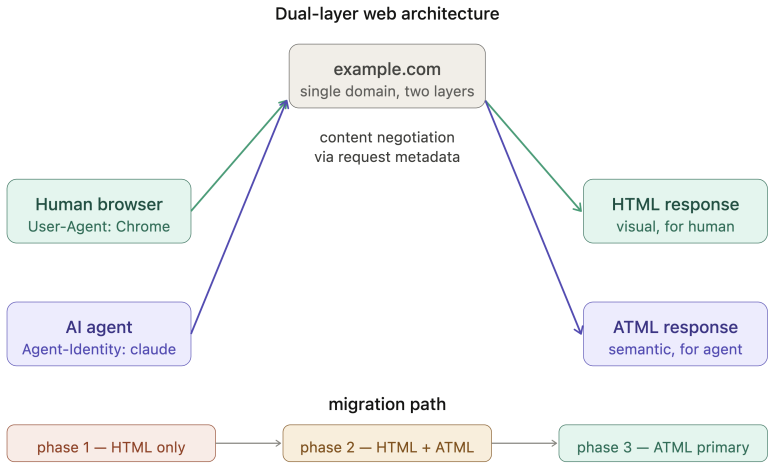
- Dual-layer architecture serves both human-readable and agent-optimized content from the same domain.
Where Pith is reading between the lines
- Standards bodies would need to formalize agent metadata headers as a required extension to existing HTTP practices.
- Content platforms might develop separate APIs optimized for agent consumption while keeping the human-facing version unchanged.
- Legal systems could treat agent actions as direct proxies for human intent, affecting liability and contract enforcement online.
- Long-term testing of ATML on live sites could measure whether the supervision tiers actually reduce content drift over multiple generations.
Load-bearing premise
The proposed mechanisms such as dual-layer content serving, intent-based economic tiers, and the ATML supervision model can be implemented at scale by existing web operators and standards bodies without major technical, legal, or adoption barriers.
What would settle it
Widespread deployment of the proposed agent identification headers, dual-layer serving, and ATML markup on major sites followed by continued blanket blocking or measurable detachment of web content from human ground truth would show the redesign fails to solve the problem.
Figures


read the original abstract
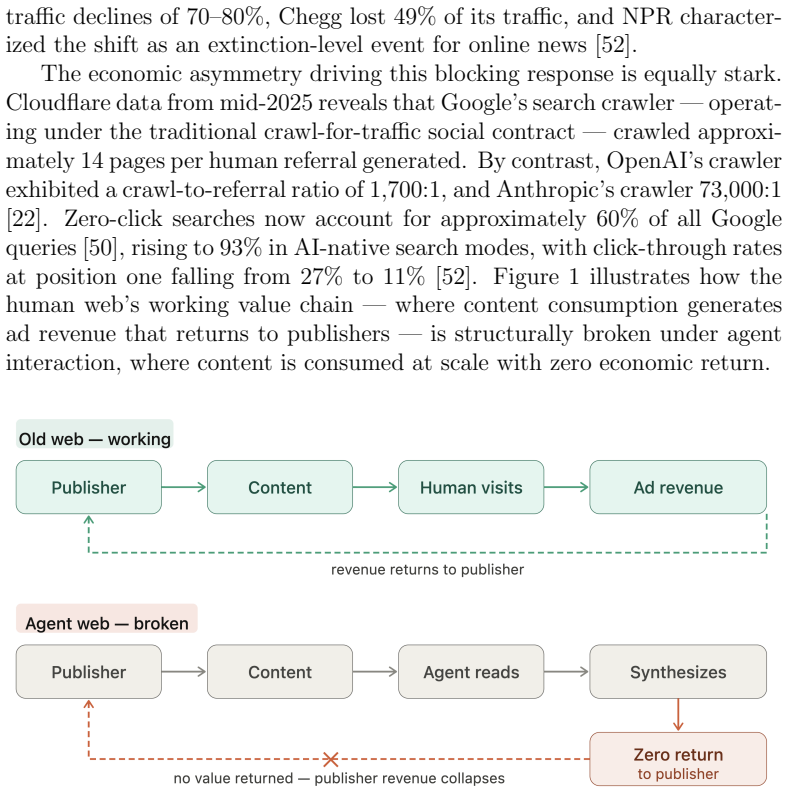
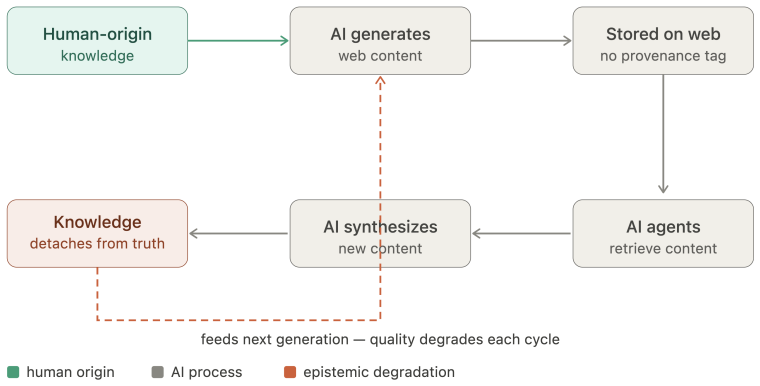
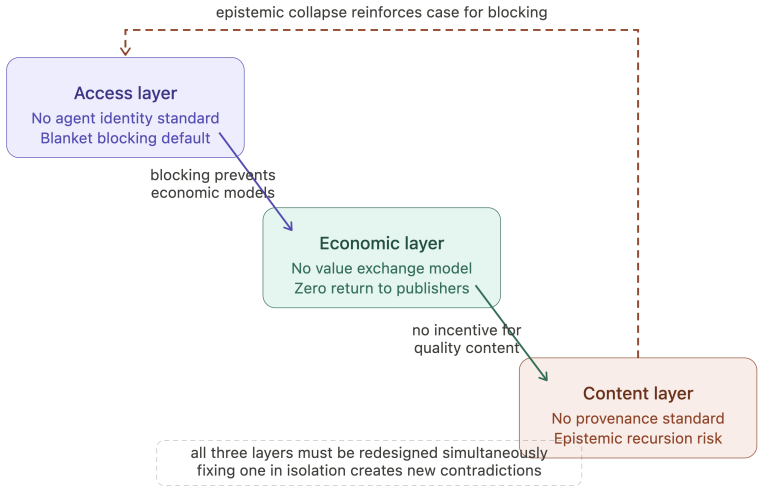
The World Wide Web was built on an assumption held for three decades: the primary consumer of web content is a human being. This permeates every layer; its access model presumes human visitors, its economics rest on human attention, and its content targets human perception. The rapid emergence of AI agents as intermediaries between humans and web content invalidates this assumption. Yet the web resists agents through blanket blocking, CAPTCHA-based exclusion, and economic models that treat agent access as extraction rather than legitimate interaction. This paper proposes a principled redesign across three layers. At the access layer, agents acting for humans should inherit equivalent access rights, governed by rate limiting and agent identification metadata in HTTP requests, analogous to browser headers, alongside a dual-layer architecture serving human-readable and agent-optimized content from the same domain. At the economic layer, we propose an intent-based tier framework grounded in the agent-as-human-proxy principle: an agent's economic obligation mirrors that of the human it represents. A token-based subscription model meters content in tokens rather than pageviews, alongside a commissioned content economy anchoring AI content production in human intentionality. At the content layer, we identify epistemic recursion, the self-referential loop in which AI-generated content is consumed by agents to produce further content, progressively detaching web knowledge from human ground truth. We propose the Agent Text Markup Language (ATML), a four-level human supervision tier model, and a cryptographic provenance chain to counter this threat. Together these constitute ten design principles for an agent-first internet, one in which agents are first-class citizens whose integration requires renegotiating the web's foundational social contract across access, economics, and content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the human-centric assumptions of the World Wide Web are invalidated by AI agents acting as intermediaries, resulting in blocking and mismatched economics; it proposes a three-layer redesign (access, economic, content) consisting of ten design principles, including HTTP agent metadata and dual-layer serving, intent-based economic tiers with token metering and commissioned content, and the Agent Text Markup Language (ATML) with four-level human supervision plus cryptographic provenance to address epistemic recursion.
Significance. If the proposals prove viable, the work could supply a coherent conceptual framework for integrating AI agents into web infrastructure while mitigating risks of access exclusion and knowledge detachment from human sources. The manuscript identifies timely problems and offers structured principles, but its significance is limited by the absence of any feasibility analysis, implementation details, or validation.
major comments (3)
- [Abstract] Abstract and three-layer architecture description: the claim that the proposed dual-layer content serving, intent-based tier framework, and ATML four-level model constitute realizable solutions at web scale rests on the unexamined premise that operators and standards bodies will voluntarily adopt and enforce them; no analysis of incentive alignment, migration costs, legal barriers, or historical precedents for cross-layer standardization is supplied, which is load-bearing for the central assertion that these changes renegotiate the web's social contract.
- [Content layer] Content layer proposal: the ATML four-level supervision model and cryptographic provenance chain are presented as countermeasures to epistemic recursion, yet the manuscript supplies neither a formal specification of the levels, example markup, nor any demonstration (even conceptual) that the mechanism would break self-referential AI-content loops in practice.
- [Economic layer] Economic layer proposal: the intent-based tier framework and token-based subscription model are asserted to mirror human obligations and anchor content in human intentionality, but no discussion of integration with existing payment rails, enforcement against agent abuse, or economic viability under current pageview-driven incentives is included.
minor comments (2)
- [Abstract] The acronym ATML is introduced without expansion on first use or comparison to existing markup standards such as HTML or XML extensions.
- The ten design principles are enumerated in the abstract but not explicitly mapped or numbered in the body, making it difficult to track which mechanisms correspond to which principle.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the timeliness of the identified problems. The manuscript presents a conceptual framework of ten design principles rather than an implemented system or economic analysis. We respond point-by-point to the major comments below, maintaining that the contribution lies in the structured identification of mismatches and the proposed principles.
read point-by-point responses
-
Referee: [Abstract] Abstract and three-layer architecture description: the claim that the proposed dual-layer content serving, intent-based tier framework, and ATML four-level model constitute realizable solutions at web scale rests on the unexamined premise that operators and standards bodies will voluntarily adopt and enforce them; no analysis of incentive alignment, migration costs, legal barriers, or historical precedents for cross-layer standardization is supplied, which is load-bearing for the central assertion that these changes renegotiate the web's social contract.
Authors: The manuscript does not assert that the proposals are immediately realizable at web scale or that voluntary adoption is assured. It argues that the human-centric assumptions are invalidated and that the listed principles provide a coherent framework for renegotiating the social contract. The central claim concerns the necessity of redesign, not its guaranteed enforcement. Detailed incentive or migration analysis lies outside the scope of a principles paper; analogous shifts (e.g., HTTPS adoption) occurred through iterative standards processes without initial exhaustive feasibility studies in the originating documents. revision: no
-
Referee: [Content layer] Content layer proposal: the ATML four-level supervision model and cryptographic provenance chain are presented as countermeasures to epistemic recursion, yet the manuscript supplies neither a formal specification of the levels, example markup, nor any demonstration (even conceptual) that the mechanism would break self-referential AI-content loops in practice.
Authors: ATML and the provenance chain are introduced at the conceptual level to illustrate how human supervision tiers and cryptographic anchoring can interrupt epistemic recursion by enabling traceability to human-grounded sources. A full formal specification and implementation demonstration would require a follow-on technical paper. The conceptual mechanism is that agents can query supervision level and provenance metadata to prioritize or filter content, thereby breaking pure self-referential loops. We will add a short illustrative ATML markup example in revision. revision: partial
-
Referee: [Economic layer] Economic layer proposal: the intent-based tier framework and token-based subscription model are asserted to mirror human obligations and anchor content in human intentionality, but no discussion of integration with existing payment rails, enforcement against agent abuse, or economic viability under current pageview-driven incentives is included.
Authors: The economic principles rest on the agent-as-proxy premise, shifting from pageview to token metering and intent-based tiers to align obligations with represented humans. Practical integration with payment rails, abuse enforcement, and transition from existing incentives are implementation details that follow from the conceptual model rather than prerequisites for stating the principles. The paper highlights the mismatch with current models but does not claim immediate economic viability. revision: no
Circularity Check
No circularity: design proposal with no derivations or self-referential reductions
full rationale
The paper is a forward-looking conceptual proposal outlining ten design principles for an agent-first web across access, economic, and content layers. It contains no equations, fitted parameters, predictions derived from data, or logical derivations that reduce to their own inputs. The central claims rest on reasoning about observed web trends and proposed mechanisms (dual-layer serving, ATML tiers, cryptographic provenance) without any self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via prior work. No load-bearing step reduces by construction to a fit or self-reference; the argument is self-contained as normative design advice rather than a closed deductive system.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI agents act as human proxies whose access rights and economic obligations should mirror those of the represented humans.
- domain assumption Epistemic recursion from AI-generated content poses a growing threat that requires new markup and provenance mechanisms.
invented entities (2)
-
Agent Text Markup Language (ATML)
no independent evidence
-
intent-based tier framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CAPTCHA: Using hard AI problems for security, in: Advances in Cryptology – EU- ROCRYPT 2003, pp
von Ahn, L., Blum, M., Hopper, N.J., Langford, J., 2003. CAPTCHA: Using hard AI problems for security, in: Advances in Cryptology – EU- ROCRYPT 2003, pp. 294–311
2003
-
[2]
Publisher revenue sharing program.https://www
AI, P., 2024. Publisher revenue sharing program.https://www. perplexity.ai. 63
2024
-
[3]
DomainKeys identified mail (DKIM) signatures – RFC 4871
Allman, E., Callas, J., Delany, M., Libbey, M., Fenton, J., Thomas, M., 2007. DomainKeys identified mail (DKIM) signatures – RFC 4871. https://tools.ietf.org/html/rfc4871
2007
-
[4]
Agent network protocol (ANP).https: //agent-network-protocol.com
ANP Working Group, 2025. Agent network protocol (ANP).https: //agent-network-protocol.com
2025
-
[5]
Model context protocol (MCP).https:// modelcontextprotocol.io
Anthropic, 2024. Model context protocol (MCP).https:// modelcontextprotocol.io
2024
-
[6]
Language models enable simple systems for gen- erating structured views of heterogeneous data lakes
Arora, S., Yang, B., Eyuboglu, S., Narayan, A., Hojel, A., Trummer, I., R´ e, C., 2023. Language models enable simple systems for gen- erating structured views of heterogeneous data lakes. arXiv preprint arXiv:2304.09433
arXiv 2023
-
[7]
Slice-mcp — fine-tuned llama-4 llm and mcp enabled 5g network slice orchestration platform, in: MILCOM 2025 - 2025 IEEE Military Communications Conference (MILCOM), pp
Bandara, E., Bouk, S.H., Mukkamala, R., Rahman, A., Liang, X., Gore, R., Shetty, S., 2025a. Slice-mcp — fine-tuned llama-4 llm and mcp enabled 5g network slice orchestration platform, in: MILCOM 2025 - 2025 IEEE Military Communications Conference (MILCOM), pp. 1506–
2025
-
[8]
doi:10.1109/MILCOM64451.2025.11310417
-
[9]
A practical guide for designing, developing, and deploying production- grade agentic ai workflows
Bandara, E., Gore, R., Foytik, P., Shetty, S., Mukkamala, R., Rah- man, A., Liang, X., Bouk, S.H., Hass, A., Rajapakse, S., et al., 2025b. A practical guide for designing, developing, and deploying production- grade agentic ai workflows. arXiv preprint arXiv:2512.08769
-
[10]
Think before you act–a neurocognitive governance model for autonomous ai agents
Bandara, E., Gore, R., Gunaratna, A., Rajapakse, S., Kularathna, I., Mukkamala, R., Shetty, S., Liang, X., Hass, A., Hewa, T., et al., 2026a. Think before you act–a neurocognitive governance model for autonomous ai agents. arXiv preprint arXiv:2604.25684
-
[11]
Agentsway–software development methodology for ai agents-based teams
Bandara, E., Gore, R., Liang, X., Rajapakse, S., Kularathne, I., Karunarathna, P., Foytik, P., Shetty, S., Mukkamala, R., Rahman, A., et al., 2025c. Agentsway–software development methodology for ai agents-based teams. arXiv preprint arXiv:2510.23664
-
[12]
Bandara, E., Gore, R., Shetty, S., Mukkamala, R., Rhea, C., Yarla- gadda, A., Kaushik, S., De Silva, L., Maznychenko, A., Sokolowska, 64 I., et al., 2025d. Standardization of neuromuscular reflex analysis– role of fine-tuned vision-language model consortium and openai gpt- oss reasoning llm enabled decision support system. arXiv preprint arXiv:2508.12473
-
[13]
A practical guide to agentic ai transition in organizations
Bandara, E., Gore, R., Shetty, S., Rajapakse, S., Kularathna, I., Karunarathna, P., Mukkamala, R., Foytik, P., Bouk, S.H., Rahman, A., et al., 2026b. A practical guide to agentic ai transition in organizations. arXiv preprint arXiv:2602.10122
-
[14]
Bandara, E., Gunaratna, A., Gore, R., Rahman, A., Mukkamala, R., Shetty, S., Rajapakse, S., Kularathna, I., Foytik, P., Bouk, S.H., et al., 2026c. Ai trust os–a continuous governance framework for autonomous ai observability and zero-trust compliance in enterprise environments. arXiv preprint arXiv:2604.04749
-
[15]
Astride: A security threat modeling platform for agentic-ai applications
Bandara, E., Hass, A., Gore, R., Shetty, S., Mukkamala, R., Bouk, S.H., Liang, X., Keong, N.W., De Zoysa, K., Withanage, A., et al., 2025e. Astride: A security threat modeling platform for agentic-ai applications. arXiv preprint arXiv:2512.04785
-
[16]
Towards responsible and explainable ai agents with consensus-driven reasoning
Bandara, E., Hewa, T., Gore, R., Shetty, S., Mukkamala, R., Foytik, P., Rahman, A., Bouk, S.H., Liang, X., Hass, A., et al., 2025f. Towards responsible and explainable ai agents with consensus-driven reasoning. arXiv preprint arXiv:2512.21699
-
[17]
Model context contracts-mcp-enabled framework to integrate llms with blockchain smart contracts
Bandara, E., Shetty, S., Mukkamala, R., Gore, R., Foytik, P., Bouk, S.H., Rahman, A., Liang, X., Keong, N.W., De Zoysa, K., et al., 2025g. Model context contracts-mcp-enabled framework to integrate llms with blockchain smart contracts. arXiv preprint arXiv:2510.19856
-
[18]
On the dangers of stochastic parrots: Can language models be too big?, in: Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT), pp
Bender, E.M., Gebru, T., McMillan-Major, A., Shmitchell, S., 2021. On the dangers of stochastic parrots: Can language models be too big?, in: Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT), pp. 610–623
2021
-
[19]
Information Management: A Proposal
Berners-Lee, T., 1989. Information Management: A Proposal. Technical Report. CERN
1989
-
[20]
The semantic web
Berners-Lee, T., Hendler, J., Lassila, O., 2001. The semantic web. Sci- entific American 284, 34–43. 65
2001
-
[21]
The anatomy of a large-scale hypertextual web search engine, in: Proceedings of the 7th International Conference on World Wide Web (WWW), pp
Brin, S., Page, L., 1998. The anatomy of a large-scale hypertextual web search engine, in: Proceedings of the 7th International Conference on World Wide Web (WWW), pp. 107–117
1998
-
[22]
Cloudflare blocks AI crawlers by default.https: //blog.cloudflare.com
Cloudflare, 2025a. Cloudflare blocks AI crawlers by default.https: //blog.cloudflare.com
-
[23]
The crawl-to-click gap: Cloudflare data on AI bots, training, and referrals.https://blog.cloudflare.com
Cloudflare, 2025b. The crawl-to-click gap: Cloudflare data on AI bots, training, and referrals.https://blog.cloudflare.com
-
[24]
From Googlebot to GPTBot: Who’s crawling your site in 2025.https://blog.cloudflare.com
Cloudflare, 2025c. From Googlebot to GPTBot: Who’s crawling your site in 2025.https://blog.cloudflare.com
2025
-
[25]
Google’s AI crawler policy and competitive implica- tions.https://blog.cloudflare.com
Cloudflare, 2026. Google’s AI crawler policy and competitive implica- tions.https://blog.cloudflare.com
2026
-
[26]
C2PA tech- nical specification.https://c2pa.org/specifications
Coalition for Content Provenance and Authenticity, 2024. C2PA tech- nical specification.https://c2pa.org/specifications
2024
-
[27]
Mind2web: Towards a generalist agent for the web, in: Advances in Neural Information Processing Systems (NeurIPS)
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y., 2023. Mind2web: Towards a generalist agent for the web, in: Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[28]
Agent AI: Surveying the horizons of multimodal interaction, in: arXiv preprint arXiv:2401.03568
Durante, Z., Sarkar, B., Gong, R., Taori, R., Noda, Y., Tang, P., Adeli, E., Lakshmikanth, S.K., Schulman, K., Milstein, A., et al., 2024. Agent AI: Surveying the horizons of multimodal interaction, in: arXiv preprint arXiv:2401.03568
Pith/arXiv arXiv 2024
-
[29]
General data protection regulation (GDPR) – regulation (eu) 2016/679.https://gdpr-info.eu
European Parliament, 2016. General data protection regulation (GDPR) – regulation (eu) 2016/679.https://gdpr-info.eu
2016
-
[30]
The economics of the online advertising industry
Evans, D.S., 2008. The economics of the online advertising industry. Review of Network Economics 7, 359–391
2008
-
[31]
Felt, A.P., Barnes, R., King, A., Palmer, C., Bentzel, C., Tabriz, P.,
-
[32]
1323–1338
Measuring HTTPS adoption on the web, in: 26th USENIX Secu- rity Symposium, pp. 1323–1338
-
[33]
HTTP/1.1 – RFC 2616
Fielding, R., Gettys, J., Mogul, J., Nielsen, H., Masinter, L., Leach, P., Berners-Lee, T., 1999. HTTP/1.1 – RFC 2616. Technical Report. IETF. 66
1999
-
[34]
Architectural Styles and the Design of Network- based Software Architectures
Fielding, R.T., 2000. Architectural Styles and the Design of Network- based Software Architectures. Ph.D. thesis. University of California, Irvine
2000
-
[35]
Agent-to-agent protocol (A2A).https://developers
Google, 2025. Agent-to-agent protocol (A2A).https://developers. google.com/agent-to-agent
2025
-
[36]
The OAuth 2.0 Authorization Framework – RFC 6749
Hardt, D., 2012. The OAuth 2.0 Authorization Framework – RFC 6749. Technical Report. IETF
2012
-
[37]
Foundation models and fair use, in: arXiv preprint arXiv:2303.15715
Henderson, P., Li, X., Jurafsky, D., Hashimoto, T., Lemley, M.A., Liang, P., 2023. Foundation models and fair use, in: arXiv preprint arXiv:2303.15715
arXiv 2023
-
[38]
A proposed standard for LLMs: llms.txt.https: //llmstxt.org
Howard, J., 2024. A proposed standard for LLMs: llms.txt.https: //llmstxt.org
2024
-
[39]
Kapoor, S., et al., 2025. Infrastructure for AI Agents. Technical Report 2501.10114. arXiv
arXiv 2025
-
[40]
Html is the language of the agentic web.https: //twitter.com/karpathy
Karpathy, A., 2025. Html is the language of the agentic web.https: //twitter.com/karpathy
2025
-
[41]
A watermark for large language models, in: International Conference on Machine Learning (ICML)
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., Goldstein, T., 2023. A watermark for large language models, in: International Conference on Machine Learning (ICML)
2023
-
[42]
A standard for robot exclusion.https://www
Koster, M., 1994. A standard for robot exclusion.https://www. robotstxt.org/orig.html
1994
-
[43]
Agentic Web: Weaving the Next Web with AI Agents
Li, Y., et al., 2025. Agentic Web: Weaving the Next Web with AI Agents. Technical Report 2507.21206. arXiv
arXiv 2025
-
[44]
Responsive Web Design
Marcotte, E., 2011. Responsive Web Design. A Book Apart
2011
-
[45]
Provenance requirements for agentic content pipelines
Martini, M., et al., 2024. Provenance requirements for agentic content pipelines. arXiv preprint
2024
-
[46]
NLWeb: Natural language interface for the web.https: //github.com/microsoft/NLWeb
Microsoft, 2025. NLWeb: Natural language interface for the web.https: //github.com/microsoft/NLWeb. 67
2025
-
[47]
Economic models for AI agent content access
Nguyen, T., et al., 2025. Economic models for AI agent content access. arXiv preprint
2025
-
[48]
User behavior with AI overviews in search
Pew Research Center, 2025. User behavior with AI overviews in search. https://www.pewresearch.org
2025
-
[49]
HTML 4.01 specification
Raggett, D., Le Hors, A., Jacobs, I., 1999. HTML 4.01 specification. W3C Recommendation
1999
-
[50]
The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary
Raymond, E.S., 1999. The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary. O’Reilly Media
1999
-
[51]
Agent Communication Protocol (ACP)
Research, I., 2025. Agent Communication Protocol (ACP). Technical Report. IBM
2025
-
[52]
Zero-click searches in AI mode.https://www.semrush
Semrush, 2025. Zero-click searches in AI mode.https://www.semrush. com
2025
-
[53]
The curse of recursion: Training on generated data makes models forget, in: Advances in Neural Information Processing Systems (NeurIPS)
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., Ander- son, R., 2023. The curse of recursion: Training on generated data makes models forget, in: Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[54]
Click-through rate analysis: AI overviews impact
SISTRIX, 2026. Click-through rate analysis: AI overviews impact. https://www.sistrix.com
2026
-
[55]
Agent web: Architecture and challenges.https://www.w3.org/community/agent-web
W3C Agent Web Community Group, 2025. Agent web: Architecture and challenges.https://www.w3.org/community/agent-web
2025
-
[56]
A survey on large language model based autonomous agents
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., Zhao, W.X., Wei, Z., Wen, J.R., 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science 18
2024
-
[57]
webMCP: A Client-Side Standard for Agent- Ready Web Design
webMCP Authors, 2025. webMCP: A Client-Side Standard for Agent- Ready Web Design. Technical Report 2508.09171. arXiv
arXiv 2025
-
[58]
The Attention Merchants: The Epic Scramble to Get Inside Our Heads
Wu, T., 2016. The Attention Merchants: The Epic Scramble to Get Inside Our Heads. Knopf. 68
2016
-
[59]
Webshop: Towards scalable real-world web interaction with grounded language agents, in: Advances in Neural Information Processing Systems (NeurIPS)
Yao, S., Chen, H., Yang, J., Narasimhan, K., 2022. Webshop: Towards scalable real-world web interaction with grounded language agents, in: Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[60]
Defending against neural fake news, in: Advances in Neural Information Processing Systems (NeurIPS)
Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F., Choi, Y., 2019. Defending against neural fake news, in: Advances in Neural Information Processing Systems (NeurIPS)
2019
-
[61]
WebArena: A realis- tic web environment for building autonomous agents, in: International Conference on Learning Representations (ICLR)
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Bisk, Y., Fried, D., Alon, U., Neubig, G., 2024. WebArena: A realis- tic web environment for building autonomous agents, in: International Conference on Learning Representations (ICLR)
2024
-
[62]
The Future of the Internet – And How to Stop It
Zittrain, J., 2008. The Future of the Internet – And How to Stop It. Yale University Press. 69
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.