Hand-4DGS: Feed-Forward 3D Gaussian Splatting for 4D Hand Reconstruction from Egocentric Videos
Pith reviewed 2026-06-26 21:09 UTC · model grok-4.3
The pith
A feed-forward network with mesh-guided Gaussian splatting reconstructs dynamic 4D hands from single egocentric videos at roughly 60 frames per second.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
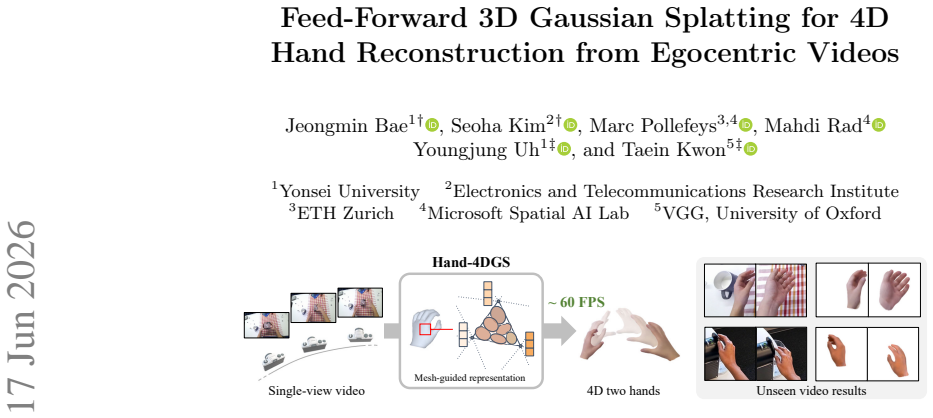
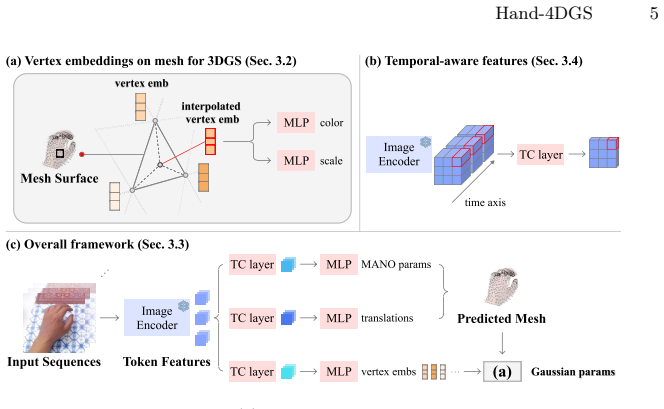
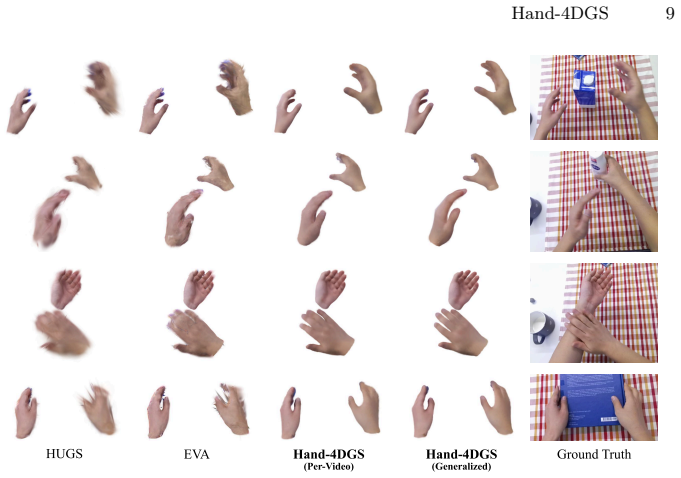
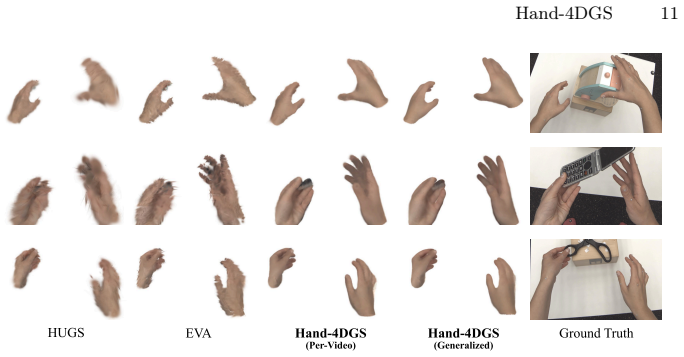
Hand-4DGS is the first feed-forward framework that reconstructs dynamic 4D hands directly from egocentric videos by combining a mesh-guided representation for structural priors with temporal convolutions to model motion, delivering inference at approximately 60 FPS and strong generalization without expensive 3D hand-pose ground truth.
What carries the argument
Mesh-guided 3D Gaussian representation predicted by a feed-forward network that also applies temporal convolutions across frames to encode dynamic hand motion.
If this is right
- Reconstruction runs at interactive rates without per-video optimization.
- Performance improves on two standard egocentric hand datasets relative to existing methods.
- Training relies only on 2D image losses from Gaussian splatting, removing the need for 3D annotations.
- The same architecture generalizes across different subjects and recording conditions in the tested datasets.
Where Pith is reading between the lines
- The feed-forward design could be combined with existing real-time mesh trackers to initialize the Gaussian prediction and further reduce error under heavy occlusion.
- If the temporal convolution module scales, the same pattern might apply to reconstructing other fast-moving objects such as tools or faces from head-mounted video.
- Deployment on consumer AR glasses becomes feasible once the network is quantized, because no test-time optimization or multi-view setup is required.
Load-bearing premise
Mesh guidance plus temporal convolutions will be enough to overcome single-view depth ambiguity and rapid motion in egocentric hand videos.
What would settle it
Quantitative comparison on a new egocentric test set containing faster head turns or more severe finger occlusions than H2O or ARCTIC, where the method produces higher reconstruction error than an optimized per-sequence Gaussian baseline.
Figures
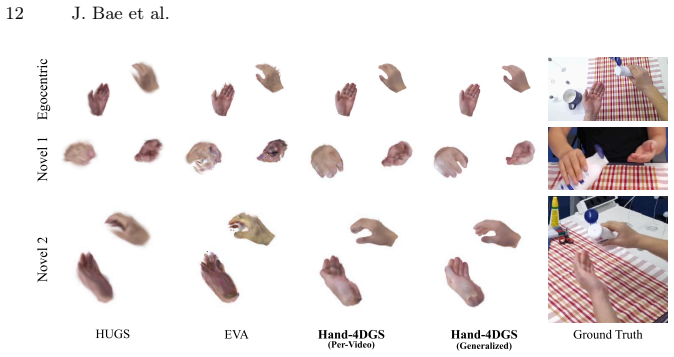
read the original abstract
Dynamic 3D hand reconstruction from egocentric videos is essential for next-generation computing platforms such as AR/VR and AI glasses. Despite its importance, most prior works focus either on multi-view 3D hand reconstruction or on 4D human body reconstruction. Egocentric 4D hand reconstruction remains challenging due to fast head motion, rapid hand dynamics, severe occlusions, and inherent ambiguity from single-view observations. To address these challenges, we introduce Hand-4DGS, the first feed-forward framework for reconstructing dynamic 4D hands directly from egocentric videos, enabling both fast (~60 FPS) inference and strong generalization. Our approach incorporates a mesh-guided representation for structural priors and temporal convolutions to model dynamic motion. We evaluate our framework on two challenging egocentric datasets, H2O and ARCTIC, and demonstrate significant improvements over baselines. Our method benefits from the generalization capability of feed-forward networks and effective 2D image supervision through Gaussian splatting, without requiring expensive 3D hand pose ground-truth annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hand-4DGS, the first feed-forward framework for reconstructing dynamic 4D hands directly from egocentric videos using 3D Gaussian Splatting. It incorporates a mesh-guided representation for structural priors and temporal convolutions to model dynamic motion. The method is evaluated on the H2O and ARCTIC datasets and claims significant improvements over baselines, fast inference at ~60 FPS, strong generalization, and the ability to train using only 2D image supervision without 3D hand pose ground-truth annotations. The approach targets challenges including fast head motion, rapid hand dynamics, severe occlusions, and single-view ambiguity.
Significance. If the quantitative results and generalization claims hold, the work would be significant for enabling real-time 4D hand reconstruction in egocentric AR/VR settings. The feed-forward design combined with Gaussian splatting for 2D supervision (avoiding expensive 3D annotations) and the explicit handling of temporal dynamics represent practical advances over prior multi-view or non-feed-forward methods. The reported ~60 FPS inference speed would be a notable engineering contribution if validated.
major comments (2)
- [Abstract] Abstract: The claim that the method is the 'first feed-forward framework' for egocentric 4D hand reconstruction requires explicit support via a comparison table or discussion in the related work section; without it, the novelty statement remains unsubstantiated.
- [Evaluation] Evaluation section (referenced in abstract): The abstract asserts 'significant improvements over baselines' on H2O and ARCTIC, but the provided text contains no quantitative metrics, ablation results, or baseline descriptions; this prevents assessment of whether the gains are load-bearing or merely incremental.
minor comments (2)
- Define all acronyms (e.g., 4DGS, FPS) on first use in the abstract and introduction.
- The abstract mentions 'mesh-guided representation' and 'temporal convolutions' but provides no equations or architectural diagram references; adding these in §3 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review. We address the two major comments below and will revise the manuscript to strengthen the novelty claim and ensure quantitative results are clearly presented.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the method is the 'first feed-forward framework' for egocentric 4D hand reconstruction requires explicit support via a comparison table or discussion in the related work section; without it, the novelty statement remains unsubstantiated.
Authors: We agree that the 'first' claim requires explicit substantiation to avoid unsubstantiated novelty statements. In the revised manuscript, we will expand the Related Work section with a dedicated paragraph and a comparison table. The table will categorize prior works by input type (egocentric vs. multi-view), output representation (implicit, explicit mesh, NeRF, 3DGS), and whether they are feed-forward or optimization-based, highlighting that no existing method combines feed-forward inference with 3D Gaussian Splatting for dynamic egocentric 4D hand reconstruction. revision: yes
-
Referee: [Evaluation] Evaluation section (referenced in abstract): The abstract asserts 'significant improvements over baselines' on H2O and ARCTIC, but the provided text contains no quantitative metrics, ablation results, or baseline descriptions; this prevents assessment of whether the gains are load-bearing or merely incremental.
Authors: The full manuscript contains a dedicated Evaluation section with quantitative metrics (including PSNR, SSIM, LPIPS, and hand-specific metrics), ablation studies on mesh guidance and temporal convolutions, and comparisons against baselines on both H2O and ARCTIC. To address the concern that these results are not sufficiently visible from the abstract, we will add a short summary of key quantitative gains (e.g., FPS and reconstruction quality deltas) directly into the abstract and ensure the Evaluation section is cross-referenced clearly. We maintain that the reported improvements are load-bearing given the feed-forward design and 2D-only supervision. revision: yes
Circularity Check
No circularity: method claims rest on architectural choices and empirical evaluation, not self-referential definitions or fitted inputs.
full rationale
The abstract and available description introduce Hand-4DGS as a feed-forward network that combines mesh-guided priors with temporal convolutions, trained and evaluated on H2O and ARCTIC datasets using 2D image supervision via Gaussian splatting. No equations, loss terms, or uniqueness theorems are shown that reduce a claimed prediction to a parameter fitted from the target quantity itself. No self-citation is invoked as the sole justification for a load-bearing premise. The derivation chain is therefore self-contained: the network architecture is proposed, trained end-to-end, and measured against baselines, without any step that is definitionally equivalent to its own input.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ICCV (2021)
Cao, Z., Radosavovic, I., Kanazawa, A., Malik, J.: Reconstructing hand-object interactions in the wild. ICCV (2021)
2021
-
[2]
In: CVPR (2024)
Charatan, D., Li, S., Tagliasacchi, A., Sitzmann, V.: pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: CVPR (2024)
2024
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, K., Mohan, S., Theiss, J., Oprea, S., Sridhar, S., Prakash, A.: Interactavatar: Modelinghand-faceinteractioninphotorealisticavatarswithdeformablegaussians. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10410–10420 (2025)
2025
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Wang, B., Shum, H.Y.: Hand avatar: Free-pose hand animation and rendering from monocular video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8683–8693 (2023)
2023
-
[5]
arXiv preprint arXiv:2403.14627 (2024)
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. arXiv preprint arXiv:2403.14627 (2024)
- [6]
-
[7]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Duran, E., Kocabas, M., Choutas, V., Fan, Z., Black, M.J.: Hmp: Hand motion priors for pose and shape estimation from video. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6353–6363 (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fan, Z., Parelli, M., Kadoglou, M.E., Kocabas, M., Chen, X., Black, M.J., Hilliges, O.: HOLD: Category-agnostic 3d reconstruction of interacting hands and objects from video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 494–504 (2024)
2024
-
[9]
In: Pro- ceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: ARCTIC: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[10]
Eu- ropean Conference on Computer Vision (2024)
Fang, Y.K.B., Dong, Y.L.H., Carrasco, C.Z.F.V., Xu, A.M.M.J., Kim, S.T.D., la Torre, A.P.F.D.: Generalizable human gaussians for sparse view synthesis. Eu- ropean Conference on Computer Vision (2024)
2024
-
[11]
In: International Confer- ence on Computer Vision (ICCV) (2023)
Goel, S., Pavlakos, G., Rajasegaran, J., Kanazawa*, A., Malik*, J.: Humans in 4D: Reconstructing and tracking humans with transformers. In: International Confer- ence on Computer Vision (ICCV) (2023)
2023
-
[12]
In: CVPR (2023)
Guo, Z., Zhou, W., Wang, M., Li, L., Li, H.: HandNeRF: Neural radiance fields for animatable interacting hands. In: CVPR (2023)
2023
-
[13]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Hasson, Y., Varol, G., Tzionas, D., Kalevatykh, I., Black, M.J., Laptev, I., Schmid, C.: Learning joint reconstruction of hands and manipulated objects. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11807–11816 (2019) 16 J. Bae et al
2019
-
[14]
In: NeurIPS (2024)
Hu,H.,Fan,Z.,Wu,T.,Xi,Y.,Lee,S.,Pavlakos,G.,Wang,Z.:Expressivegaussian human avatars from monocular rgb video. In: NeurIPS (2024)
2024
- [15]
-
[16]
arXiv preprint arXiv:2410.01425 (2024)
Hu, Y., Liu, Z., Shao, J., Lin, Z., Zhang, J.: Eva-gaussian: 3d gaussian-based real- time human novel view synthesis under diverse camera settings. arXiv preprint arXiv:2410.01425 (2024)
-
[17]
Advances in Neural Information Processing Systems37, 14127–14147 (2024)
Huang, X., Li, H., Liu, W., Liang, X., Yan, Y., Cheng, Y., Gao, C.: Learning interaction-aware 3d gaussian splatting for one-shot hand avatars. Advances in Neural Information Processing Systems37, 14127–14147 (2024)
2024
-
[18]
CVPR (2022)
Jain, A., Mildenhall, B., Barron, J.T., Abbeel, P., Poole, B.: Zero-shot text-guided object generation with dream fields. CVPR (2022)
2022
-
[19]
Pattern Recognition Letters 183, 155–164 (2024)
Jiao, Z., Wang, X., Li, J., Gao, R., He, M., Liang, J., Xia, Z., Gao, Q.: Handformer: Hand pose reconstructing from a single rgb image. Pattern Recognition Letters 183, 155–164 (2024)
2024
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karunratanakul, K., Prokudin, S., Hilliges, O., Tang, S.: Harp: Personalized hand reconstruction from a monocular rgb video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12802–12813 (2023)
2023
-
[21]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kocabas, M., Chang, J.H.R., Gabriel, J., Tuzel, O., Ranjan, A.: Hugs: Human gaussian splats. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 505–515 (2024)
2024
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kwon, T., Tekin, B., Stühmer, J., Bogo, F., Pollefeys, M.: H2o: Two hands ma- nipulating objects for first person interaction recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10138– 10148 (October 2021)
2021
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, M., An, L., Zhang, H., Wu, L., Chen, F., Yu, T., Liu, Y.: Interacting attention graph for single image two-hand reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2761–2770 (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Jiang, H., Xu, J., Liu, S., Wang, X.: Semi-supervised 3d hand-object poses estimation with interactions in time. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14687–14697 (2021)
2021
-
[26]
In: CVPR (2023)
Moon, G.: Bringing inputs to shared domains for 3D interacting hands recovery in the wild. In: CVPR (2023)
2023
-
[27]
Moon, G., Xu, W., Joshi, R., Wu, C., Shiratori, T.: Authentic hand avatar from a phonescanviauniversalhandmodel.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 2029–2038 (2024)
2029
-
[28]
Mundra, A., B R, M., Wang, J., Habermann, M., Theobalt, C., Elgharib, M.: Livehand: Real-time and photorealistic neural hand rendering (October 2023)
2023
- [29]
-
[30]
In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
Pan, P., Su, Z., Lin, C., Fan, Z., Zhang, Y., Li, Z., Shen, T., Mu, Y., Liu, Y.: Humansplat: Generalizable single-image human gaussian splatting with structure priors. In: Advances in Neural Information Processing Systems (NeurIPS) (2024)
2024
-
[31]
In: CVPR (2024) Hand-4DGS 17
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing hands in 3D with transformers. In: CVPR (2024) Hand-4DGS 17
2024
-
[32]
Pokhariya, C., Shah, I.N., Xing, A., Li, Z., Chen, K., Sharma, A., Sridhar, S.: Manus: Markerless hand-object grasp capture using articulated 3d gaussians (2023)
2023
-
[33]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Potamias, R.A., Ploumpis, S., Moschoglou, S., Triantafyllou, V., Zafeiriou, S.: Handy: Towards a high fidelity 3d hand shape and appearance model. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4670–4680 (2023)
2023
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Potamias, R.A., Zhang, J., Deng, J., Zafeiriou, S.: Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12242–12254 (2025)
2025
-
[35]
In: European Conference on Computer Vision
Qian, N., Wang, J., Mueller, F., Bernard, F., Golyanik, V., Theobalt, C.: Html: A parametric hand texture model for 3d hand reconstruction and personalization. In: European Conference on Computer Vision. pp. 54–71. Springer (2020)
2020
-
[36]
In: Proceedings of Neural Information Processing Systems(NeurIPS) (Dec 2024)
Ren, J., Xie, K., Mirzaei, A., Liang, H., Zeng, X., Kreis, K., Liu, Z., Torralba, A., Fidler, S., Kim, S.W., Ling, H.: L4gm: Large 4d gaussian reconstruction model. In: Proceedings of Neural Information Processing Systems(NeurIPS) (Dec 2024)
2024
-
[37]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ren, P., Wen, C., Zheng, X., Xue, Z., Sun, H., Qi, Q., Wang, J., Liao, J.: Decoupled iterative refinement framework for interacting hands reconstruction from a single rgb image. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8014–8025 (2023)
2023
-
[38]
ACM Transactions on Graphics, (Proc
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6) (Nov 2017)
2017
-
[39]
In: IEEE International Conference on Computer Vision Workshops (2021)
Rong, Y., Shiratori, T., Joo, H.: Frankmocap: A monocular 3d whole-body pose es- timation system via regression and integration. In: IEEE International Conference on Computer Vision Workshops (2021)
2021
-
[40]
arXiv preprint arXiv:2106.05954 (2021)
Spurr, A., Molchanov, P., Iqbal, U., Kautz, J., Hilliges, O.: Adversarial mo- tion modelling helps semi-supervised hand pose estimation. arXiv preprint arXiv:2106.05954 (2021)
- [41]
-
[42]
arxiv (2024)
Szymanowicz, S., Insafutdinov, E., Zheng, C., Campbell, D., Henriques, J., Rup- precht,C.,Vedaldi,A.:Flash3d:Feed-forwardgeneralisable3dscenereconstruction from a single image. arxiv (2024)
2024
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, X., Kwon, T., Rad, M., Pan, B., Chakraborty, I., Andrist, S., Bohus, D., Feniello, A., Tekin, B., Frujeri, F.V., et al.: Holoassist: an egocentric human in- teraction dataset for interactive ai assistants in the real world. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20270–20281 (2023)
2023
-
[44]
In: ICLR (2025)
Wen, J., Schwing, A., Wang, S.: LIFe-GoM: Generalizable Human Rendering with Learned Iterative Feedback Over Multi-Resolution Gaussians-on-Mesh. In: ICLR (2025)
2025
-
[45]
In: CVPR (2025)
Xiao, J., Zhang, Q., Nie, Y., Zhu, L., Zheng, W.S.: RoGSplat: Learning robust generalizable human gaussian splatting from sparse multi-view images. In: CVPR (2025)
2025
-
[46]
Xu, Z., Li, Z., Dong, Z., Zhou, X., Newcombe, R., Lv, Z.: 4dgt: Learning a 4d gaussian transformer using real-world monocular videos (2025)
2025
-
[47]
In: European Conference on Computer Vision
Yang, J., Chang, H.J., Lee, S., Kwak, N.: Seqhand: Rgb-sequence-based 3d hand pose and shape estimation. In: European Conference on Computer Vision. pp. 122–139. Springer (2020)
2020
-
[48]
arXiv preprint arXiv:2501.08329 (2025) 18 J
Ye, Y., Feng, Y., Tehari, O., Feng, H., Tulsiani, S., Black, M.J.: Predicting 4d hand trajectory from monocular videos. arXiv preprint arXiv:2501.08329 (2025) 18 J. Bae et al
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, Z., Huang, S., Fang, C., Breckon, T.P., Wang, J.: Acr: Attention collaboration- based regressor for arbitrary two-hand reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12955– 12964 (2023)
2023
-
[50]
In: arXiv preprint arXiv:2412.12861 (December 2024)
Yu, Z., Zafeiriou, S., Birdal, T.: Dyn-hamr: Recovering 4d interacting hand motion from a dynamic camera. In: arXiv preprint arXiv:2412.12861 (December 2024)
-
[51]
arXiv preprint arXiv:2505.03351 (2025)
Zhang, D., Liu, Y., Lin, L., Zhu, Y., Li, Y., Qin, M., Li, Y., Wang, H.: Guava: Generalizable upper body 3d gaussian avatar. arXiv preprint arXiv:2505.03351 (2025)
-
[52]
arXiv preprint arXiv:2501.02973 (2025)
Zhang, J., Deng, J., Ma, C., Potamias, R.A.: Hawor: World-space hand motion reconstruction from egocentric videos. arXiv preprint arXiv:2501.02973 (2025)
-
[53]
IEEE Transactions on Visualization & Computer Graphics pp
Zhao, L., Lu, X., Fan, R., Im, S.K., Wang, L.: Gaussianhand: Real-time 3d gaus- sian rendering for hand avatar animation. IEEE Transactions on Visualization & Computer Graphics pp. 1–13 (Dec 5555)
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Zheng, S., Zhou, B., Shao, R., Liu, B., Zhang, S., Nie, L., Liu, Y.: Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view syn- thesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, X., Wen, C., Su, Z., Xu, Z., Li, Z., Zhao, Y., Xue, Z.: Ohta: One-shot hand avatar via data-driven implicit priors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 799–810 (2024)
2024
-
[56]
arXiv preprint arXiv:2412.14963 (2024),https://arxiv.org/abs/2412.14963
Zhuang, Y., Lv, J., Wen, H., Shuai, Q., Zeng, A., Zhu, H., Chen, S., Yang, Y., Cao, X., Liu, W.: Idol: Instant photorealistic 3d human creation from a single image. arXiv preprint arXiv:2412.14963 (2024),https://arxiv.org/abs/2412.14963
-
[57]
In: 2022 International Conference on 3D Vision (3DV)
Ziani, A., Fan, Z., Kocabas, M., Christen, S., Hilliges, O.: Tempclr: Reconstructing hands via time-coherent contrastive learning. In: 2022 International Conference on 3D Vision (3DV). pp. 627–636. IEEE (2022) Hand-4DGS 1 In the Appendix, we present in-the-wild video results (Section A). To further show the robustness and applicability of our framework, w...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.