Learning to Annotate Delayed and False AEB Events: A Practical System for Extreme Class Imbalance and Asymmetric Label Noise
Pith reviewed 2026-06-26 20:34 UTC · model grok-4.3
The pith
An automated framework annotates rare delayed and false AEB triggers despite extreme class imbalance and label noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
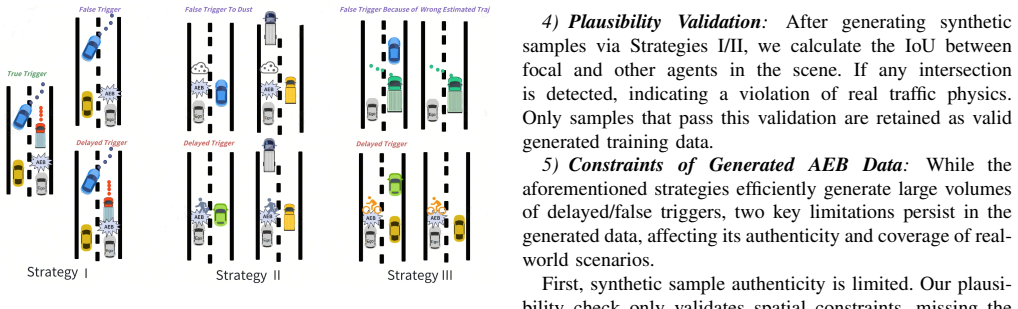
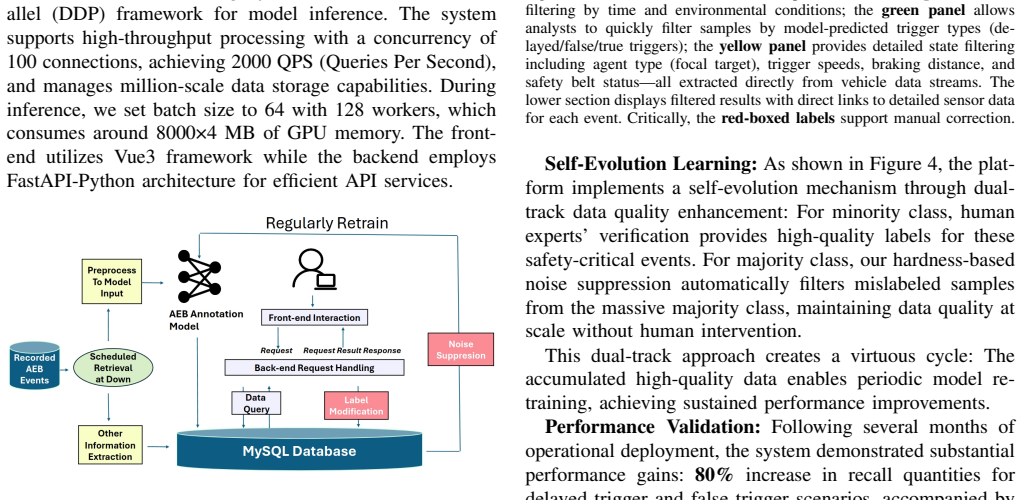
The authors present the first automated AEB annotation framework that uses specific data augmentation by manipulating focal target attributes, transplanting ego-vehicle dynamics, and masking non-focal agents, combined with noise suppression via stable hardness estimation and probe-guided adaptive threshold, to overcome class imbalance and asymmetric label noise and efficiently annotate delayed and false triggers.
What carries the argument
Specific data augmentation for synthesizing realistic minority samples combined with stable hardness estimation and probe-guided adaptive threshold for cleaning mislabeled samples.
If this is right
- The system can process thousands of daily AEB events to identify critical delayed and false triggers automatically.
- It achieves an 80% improvement in recall of delayed and false triggers along with a 50% reduction in manual workload.
- Accumulated high-quality annotations create a data foundation for ongoing on-vehicle AEB system optimization.
Where Pith is reading between the lines
- Similar data augmentation and noise-handling steps could transfer to annotation tasks for other rare safety events in driving data.
- Evaluating the approach on triggers from different vehicle types would test whether the transplanted dynamics remain effective.
- The pipeline might scale to label other imbalanced event categories beyond AEB in autonomous vehicle logs.
Load-bearing premise
The data augmentation produces samples realistic enough to improve minority class learning without introducing new biases or artifacts that degrade performance on real data.
What would settle it
A held-out test set of real delayed and false AEB triggers would show recall below the reported levels if the augmented samples introduce artifacts or if the noise suppression removes true minority samples.
Figures


read the original abstract
Autonomous Emergency Braking (AEB) optimization relies on accurately annotated real-world trigger events, particularly rare but critical delayed and false AEB triggers that expose system deficiencies. However, these minority samples comprise less than 5% of thousands of daily triggers, making manual annotation prohibitively expensive at scale. We present the first automated AEB annotation framework to address this problem. During development, we identified two fundamental challenges that severely impair delayed/false trigger annotation accuracy: (1) Extreme class imbalance where delayed/false triggers are overwhelmed by true triggers; (2) Asymmetric label noise where mislabeled majority samples (true triggers) suppress minority samples (delayed/false triggers) learning. To overcome these challenges, we propose two key innovations: (1) Specific data augmentation that synthesizes realistic samples by manipulating focal target attributes, transplanting ego-vehicle dynamics, and masking non-focal agents; (2) noise suppression using stable hardness estimation and probe-guided adaptive threshold to clean mislabeled true trigger samples. Crucially, we deploy our model as a practical annotation system with full-stack architecture, efficiently identifying critical delayed/false triggers from thousands of daily AEB events. Production results demonstrate 80% improvement in recall of delayed/false triggers and 50% reduction in manual workload. Beyond immediate gains, the system enables continuous self-improvement through accumulated high-quality annotations, establishing a necessary data foundation for on-vehicle AEB system optimization
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first automated framework for annotating rare delayed and false AEB trigger events from thousands of daily triggers. It identifies two core challenges—extreme class imbalance (<5% minority class) and asymmetric label noise—and proposes (1) data augmentation via focal-target attribute manipulation, ego-vehicle dynamics transplantation, and non-focal agent masking to synthesize realistic minority samples, and (2) noise suppression via stable hardness estimation and probe-guided adaptive thresholding to clean mislabeled majority samples. The system is deployed as a full-stack production annotation pipeline that reportedly achieves an 80% recall improvement on delayed/false triggers and a 50% reduction in manual workload while enabling continuous self-improvement.
Significance. If the production results hold under rigorous validation, the work would be significant for practical autonomous-systems deployment: it directly tackles the prohibitive cost of annotating safety-critical rare events and supplies a closed-loop data foundation for AEB optimization. The emphasis on a deployable full-stack system and the explicit handling of asymmetric noise are strengths that distinguish it from purely academic imbalance techniques.
major comments (3)
- [Abstract / Production Results] Abstract and Production Results section: the central claims of '80% improvement in recall' and '50% reduction in manual workload' are stated without any description of experimental protocol, baselines, evaluation metrics, dataset splits, or statistical significance testing. This absence makes it impossible to determine whether the reported gains are attributable to the proposed augmentation and noise-suppression pipeline or to unstated factors.
- [Data Augmentation] Data Augmentation pipeline (described in the abstract and likely §4): the claim that the three operations produce 'realistic samples' that improve minority-class learning without introducing new biases is load-bearing for the 80% recall result. No quantitative validation—feature-distribution overlap, perceptual study, or ablation on held-out real data—is reported, leaving open the possibility that transplanted dynamics or masked scenes create spurious correlations that the downstream noise-suppression stage cannot correct.
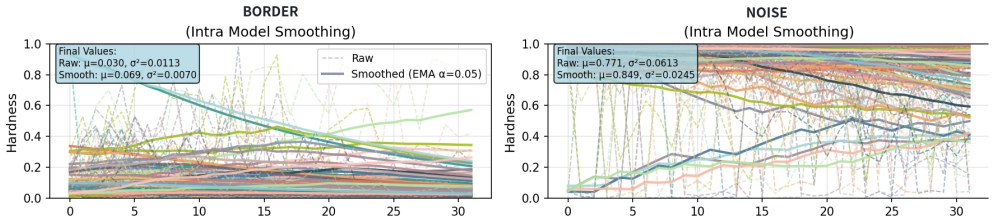
- [Noise Suppression] Noise Suppression module: the 'stable hardness estimation and probe-guided adaptive threshold' are presented as the solution to asymmetric label noise, yet no equations, algorithmic pseudocode, or ablation isolating their contribution versus standard hardness or threshold methods appear. Without these details it is unclear whether the method actually mitigates the suppression of minority samples by mislabeled majority examples.
minor comments (1)
- [Abstract] The abstract refers to 'thousands of daily triggers' and '<5% minority samples' but supplies no concrete dataset statistics (total events, exact imbalance ratio, annotation budget) that would allow readers to gauge the scale of the problem addressed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the production claims require more supporting experimental details and that the technical components need expanded formalization and validation. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract / Production Results] Abstract and Production Results section: the central claims of '80% improvement in recall' and '50% reduction in manual workload' are stated without any description of experimental protocol, baselines, evaluation metrics, dataset splits, or statistical significance testing. This absence makes it impossible to determine whether the reported gains are attributable to the proposed augmentation and noise-suppression pipeline or to unstated factors.
Authors: We agree that the current presentation of the production results is insufficiently detailed. In the revised manuscript we will expand the Production Results section with a full description of the evaluation protocol, including dataset characteristics and splits, baseline annotation methods, the precise recall and workload metrics, and any statistical testing performed on the deployed system. revision: yes
-
Referee: [Data Augmentation] Data Augmentation pipeline (described in the abstract and likely §4): the claim that the three operations produce 'realistic samples' that improve minority-class learning without introducing new biases is load-bearing for the 80% recall result. No quantitative validation—feature-distribution overlap, perceptual study, or ablation on held-out real data—is reported, leaving open the possibility that transplanted dynamics or masked scenes create spurious correlations that the downstream noise-suppression stage cannot correct.
Authors: We acknowledge the need for explicit validation that the augmentation operations preserve realism. While the three operations are described in the manuscript, the revision will add quantitative evidence: feature-distribution overlap statistics between real and synthesized samples, and ablation results on held-out real data demonstrating performance gains without measurable introduction of spurious correlations. revision: yes
-
Referee: [Noise Suppression] Noise Suppression module: the 'stable hardness estimation and probe-guided adaptive threshold' are presented as the solution to asymmetric label noise, yet no equations, algorithmic pseudocode, or ablation isolating their contribution versus standard hardness or threshold methods appear. Without these details it is unclear whether the method actually mitigates the suppression of minority samples by mislabeled majority examples.
Authors: We agree that the noise-suppression component requires formal specification and isolation experiments. The revised manuscript will include the mathematical definitions of stable hardness estimation and probe-guided adaptive thresholding, the corresponding algorithmic pseudocode, and ablation studies that compare the proposed approach against standard hardness-based and thresholding baselines to quantify its effect on minority-sample retention under asymmetric noise. revision: yes
Circularity Check
No circularity: practical systems paper with no derivation chain or fitted quantities
full rationale
The paper describes an applied annotation system using data augmentation and noise suppression for imbalanced AEB triggers. No equations, parameter fittings, uniqueness theorems, or self-citations appear in the abstract or described claims. Production results (80% recall lift, 50% workload reduction) are presented as empirical outcomes rather than outputs of a derivation that reduces to its own inputs. No load-bearing steps match any of the enumerated circularity patterns; the framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Test Protocol – AEB/LSS VRU systems, Implementation 2023,
European New Car Assessment Programme (Euro NCAP), “Test Protocol – AEB/LSS VRU systems, Implementation 2023,” Euro NCAP, Tech. Rep. Version 4.5.1, Feb. 2024
2023
-
[2]
Effectiveness of low speed au- tonomous emergency braking in real-world rear-end crashes,
B. Fildes, M. Keall, N. Bos, A. Lie, Y . Page, C. Pastor, L. Pennisi, M. Rizzi, P. Thomas, and C. Tingvall, “Effectiveness of low speed au- tonomous emergency braking in real-world rear-end crashes,”Accident Analysis & Prevention, vol. 81, pp. 24–29, 2015
2015
-
[3]
Survey on deep learning with class imbalance,
J. M. Johnson and T. M. Khoshgoftaar, “Survey on deep learning with class imbalance,”Journal of big data, vol. 6, no. 1, pp. 1–54, 2019
2019
-
[4]
Learning with noisy labels,
N. Natarajan, I. S. Dhillon, P. K. Ravikumar, and A. Tewari, “Learning with noisy labels,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[5]
Equal- ization loss for long-tailed object recognition,
J. Tan, C. Wang, B. Li, Q. Li, W. Ouyang, C. Yin, and J. Yan, “Equal- ization loss for long-tailed object recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 662–11 671
2020
-
[6]
Climb: Class-imbalanced learning benchmark on tabular data,
Z. Liu, Z. Li, Z. Yang, T. Wei, J. Kang, Y . Zhu, H. Hamann, J. He, and H. Tong, “Climb: Class-imbalanced learning benchmark on tabular data,”arXiv preprint arXiv:2505.17451, 2025
arXiv 2025
-
[7]
Smote: synthetic minority over-sampling technique,
N. V . Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,”Journal of arti- ficial intelligence research, vol. 16, pp. 321–357, 2002
2002
-
[8]
Self-supervised aggregation of diverse experts for test-agnostic long-tailed recognition,
Y . Zhang, B. Hooi, L. Hong, and J. Feng, “Self-supervised aggregation of diverse experts for test-agnostic long-tailed recognition,”Advances in neural information processing systems, vol. 35, pp. 34 077–34 090, 2022
2022
-
[9]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988
2017
-
[10]
Asymmetric loss for multi-label classification,
T. Ridnik, E. Ben-Baruch, N. Zamir, A. Noy, I. Friedman, M. Protter, and L. Zelnik-Manor, “Asymmetric loss for multi-label classification,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 82–91
2021
-
[11]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[12]
A survey of deep long-tail classifi- cation advancements,
C. De Alvis and S. Seneviratne, “A survey of deep long-tail classifi- cation advancements,”arXiv preprint arXiv:2404.15593, 2024
arXiv 2024
-
[13]
Deep long- tailed learning: A survey,
Y . Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long- tailed learning: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 9, pp. 10 795–10 816, 2023
2023
-
[14]
A multiple resampling method for learning from imbalanced data sets,
A. Estabrooks, T. Jo, and N. Japkowicz, “A multiple resampling method for learning from imbalanced data sets,”Computational in- telligence, vol. 20, no. 1, pp. 18–36, 2004
2004
-
[15]
Exploratory undersampling for class-imbalance learning,
X.-Y . Liu, J. Wu, and Z.-H. Zhou, “Exploratory undersampling for class-imbalance learning,”IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 39, no. 2, pp. 539–550, 2008
2008
-
[16]
Learning fast sample re-weighting without reward data,
Z. Zhang and T. Pfister, “Learning fast sample re-weighting without reward data,” inProceedings of the IEEE/CVF international confer- ence on computer vision, 2021, pp. 725–734
2021
-
[17]
Asymptotic properties of nearest neighbor rules using edited data,
D. L. Wilson, “Asymptotic properties of nearest neighbor rules using edited data,”IEEE Transactions on Systems, Man, and Cybernetics, no. 3, pp. 408–421, 1972
1972
-
[18]
Class-balanced loss based on effective number of samples,
Y . Cui, M. Jia, T.-Y . Lin, Y . Song, and S. Belongie, “Class-balanced loss based on effective number of samples,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 9268–9277
2019
-
[19]
Balanced meta-softmax for long-tailed visual recognition,
J. Ren, C. Yu, X. Ma, H. Zhao, S. Yiet al., “Balanced meta-softmax for long-tailed visual recognition,”Advances in neural information processing systems, vol. 33, pp. 4175–4186, 2020
2020
-
[20]
Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition,
B. Zhou, Q. Cui, X.-S. Wei, and Z.-M. Chen, “Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9719–9728
2020
-
[21]
Self-paced ensemble for highly imbalanced massive data classification,
Z. Liu, W. Cao, Z. Gao, J. Bian, H. Chen, Y . Chang, and T.- Y . Liu, “Self-paced ensemble for highly imbalanced massive data classification,” in2020 IEEE 36th international conference on data engineering (ICDE). IEEE, 2020, pp. 841–852
2020
-
[22]
Decoupling representation and classifier for long-tailed recognition,
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis, “Decoupling representation and classifier for long-tailed recognition,”arXiv preprint arXiv:1910.09217, 2019
arXiv 1910
-
[23]
Pervasive label errors in test sets destabilize machine learning benchmarks,
C. G. Northcutt, A. Athalye, and J. Mueller, “Pervasive label errors in test sets destabilize machine learning benchmarks,”arXiv preprint arXiv:2103.14749, 2021
arXiv 2021
-
[24]
O2u-net: A simple noisy label detection approach for deep neural networks,
J. Huang, L. Qu, R. Jia, and B. Zhao, “O2u-net: A simple noisy label detection approach for deep neural networks,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3326–3334
2019
-
[25]
Augmentation strategies for learning with noisy labels,
K. Nishi, Y . Ding, A. Rich, and T. Hollerer, “Augmentation strategies for learning with noisy labels,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8022–8031
2021
-
[26]
Prototypical classifier for robust class-imbalanced learning,
T. Wei, J.-X. Shi, Y .-F. Li, and M.-L. Zhang, “Prototypical classifier for robust class-imbalanced learning,” inPacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2022, pp. 44–57
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.