Native Active Perception as Reasoning for Omni-Modal Understanding
Pith reviewed 2026-06-26 21:11 UTC · model grok-4.3
The pith
OmniAgent formulates video understanding as a POMDP where the model actively selects actions to distill relevant audio-visual cues into textual memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
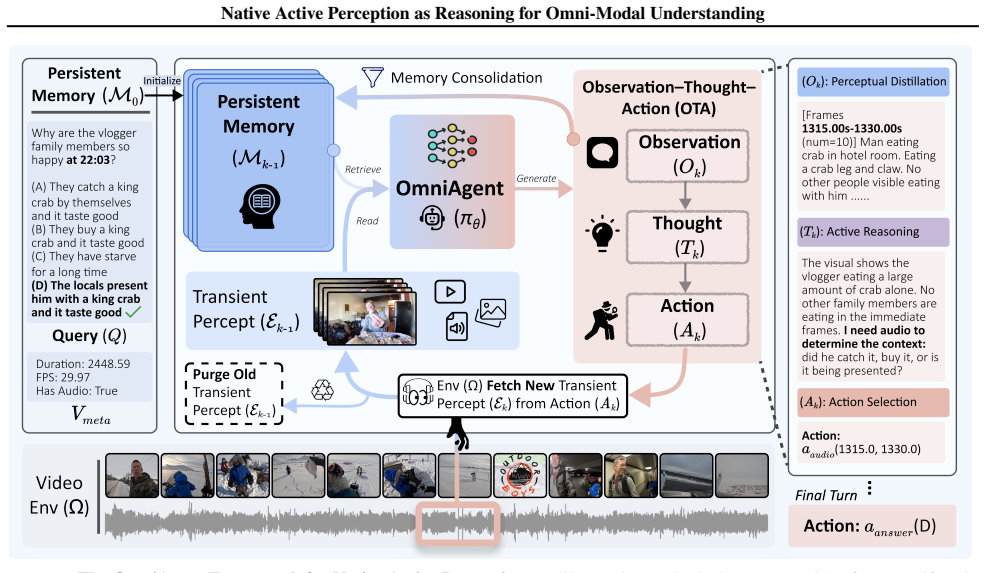
OmniAgent is the first native omni-modal agent that formulates video understanding as a POMDP-based iterative Observation-Thought-Action cycle, executing on-demand actions to selectively distill audio-visual cues into a persistent textual memory and thereby decoupling reasoning complexity from raw video duration.
What carries the argument
POMDP-based Observation-Thought-Action cycle that enables selective on-demand distillation of audio-visual cues into persistent textual memory, trained via Agentic SFT with best-of-N synthesis and TAURA RL.
If this is right
- Performance improves as the number of reasoning turns increases at test time.
- Reasoning cost no longer scales linearly with video length because only selected cues are retained.
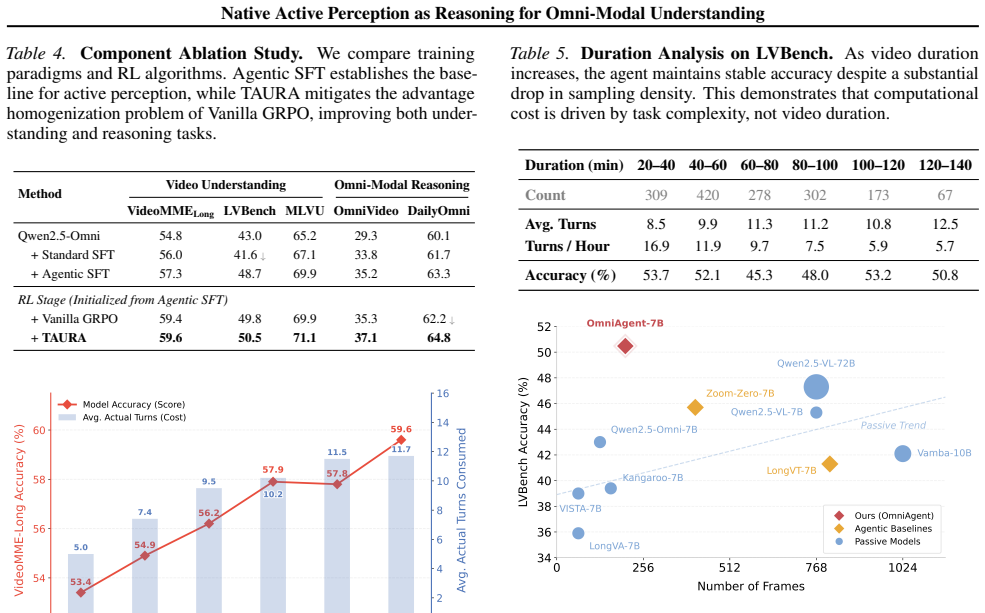
- A 7B model reaches 50.5 percent on LVBench while a 72B baseline reaches 47.3 percent.
- State-of-the-art results among open-source models are obtained across ten omni-modal benchmarks.
Where Pith is reading between the lines
- The same selective-memory cycle could be applied to other long sequential inputs such as audio streams or multi-turn dialogues.
- Positive test-time scaling implies that allocating more inference turns may continue to improve results without retraining.
- Native training of the perception loop may be required for the behavior to emerge reliably rather than relying on external tool interfaces.
Load-bearing premise
The POMDP formulation together with Agentic SFT and TAURA RL are what produce the active perception behavior and performance gains rather than the base model, data mixture, or evaluation protocol.
What would settle it
An ablation that removes action selection or replaces TAURA with standard advantage estimation and still matches or exceeds the reported accuracy and test-time scaling on LVBench and VideoMME would falsify the claim.
Figures




read the original abstract
Passive models for long video understanding typically rely on a "watch-it-all" paradigm, processing frames uniformly regardless of query difficulty, causing computational cost to grow with video duration. Although interactive frameworks have emerged, they often rely on global pre-scanning, and their context cost still scales with video length. We propose OmniAgent, the first native omni-modal agent that formulates video understanding as a POMDP-based iterative Observation-Thought-Action cycle. OmniAgent executes on-demand actions to selectively distill audio-visual cues into a persistent textual memory, effectively decoupling reasoning complexity from raw video duration. To operationalize this, we introduce (1) Agentic Supervised Fine-Tuning to bootstrap native active perception via best-of-N trajectory synthesis with dual-stage quality control, and (2) Agentic Reinforcement Learning with TAURA (Turn-aware Adaptive Uncertainty Rescaled Advantage), which leverages turn-level entropy to steer credit assignment toward pivotal discovery turns. Crucially, OmniAgent exhibits positive test-time scaling, where performance improves as the number of reasoning turns increases, validating the efficacy of active perception. Empirical results across ten benchmarks (e.g., VideoMME, LVBench) demonstrate that OmniAgent achieves state-of-the-art performance among open-source models. Notably, on LVBench, our 7B agent outperforms the 10$\times$ larger Qwen2.5-VL-72B (50.5% vs. 47.3%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce OmniAgent, the first native omni-modal agent that formulates video understanding as a POMDP-based iterative Observation-Thought-Action cycle. It introduces Agentic SFT via best-of-N trajectory synthesis with dual-stage quality control and Agentic RL with TAURA (leveraging turn-level entropy for credit assignment) to enable selective distillation of audio-visual cues into persistent textual memory. The work reports SOTA results among open-source models across ten benchmarks (e.g., VideoMME, LVBench), with a 7B model achieving 50.5% on LVBench to outperform Qwen2.5-VL-72B at 47.3%, and positive test-time scaling as the number of reasoning turns increases.
Significance. If the attribution of gains and active-perception behavior to the POMDP cycle plus TAURA holds (rather than base model or data mixture), the approach could meaningfully advance efficient long-video omni-modal understanding by decoupling compute from duration. The reported positive test-time scaling constitutes a falsifiable prediction that, if robustly shown, would strengthen the central claim.
major comments (2)
- [Abstract] Abstract and method description: the headline claim that the POMDP Observation-Thought-Action cycle together with Agentic SFT and TAURA produce both the active perception behavior and the numerical gains (including 7B outperforming 72B on LVBench) rests on an untested premise; no ablations are described that isolate the iterative action mechanism from passive processing on identical trajectories or data.
- [Empirical results] Empirical results section: the absence of controls comparing the full agent against the base model with the same data mixture but without the POMDP formulation or TAURA leaves the attribution of the reported SOTA performance unverified and load-bearing for the central thesis.
minor comments (1)
- [Abstract] The acronym TAURA is introduced without an explicit expansion or derivation of the turn-aware uncertainty rescaling formula in the provided abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of isolating the contributions of the POMDP formulation, Agentic SFT, and TAURA. We respond to each major comment below and commit to revisions that directly address the attribution concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the headline claim that the POMDP Observation-Thought-Action cycle together with Agentic SFT and TAURA produce both the active perception behavior and the numerical gains (including 7B outperforming 72B on LVBench) rests on an untested premise; no ablations are described that isolate the iterative action mechanism from passive processing on identical trajectories or data.
Authors: We agree that the manuscript would benefit from explicit ablations isolating the iterative POMDP cycle. The reported positive test-time scaling provides supporting evidence that performance improves with additional reasoning turns, which is inconsistent with purely passive processing on fixed trajectories. To directly verify the premise, we will add new experiments in the revision comparing the full agent against a passive baseline that processes identical trajectories and data without the Observation-Thought-Action cycle. revision: yes
-
Referee: [Empirical results] Empirical results section: the absence of controls comparing the full agent against the base model with the same data mixture but without the POMDP formulation or TAURA leaves the attribution of the reported SOTA performance unverified and load-bearing for the central thesis.
Authors: We concur that controls holding the data mixture fixed while removing the POMDP formulation and TAURA are necessary to strengthen attribution claims. The current results include comparisons to larger base models, but we will incorporate additional baselines in the revised manuscript that apply the same data mixture to the base model without the agentic components, allowing clearer isolation of the proposed methods' contributions. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks, not internal reductions
full rationale
The paper formulates video understanding as a POMDP Observation-Thought-Action cycle, introduces Agentic SFT via best-of-N synthesis and TAURA RL using turn-level entropy, then reports empirical SOTA results on ten external benchmarks (e.g., LVBench 50.5% for 7B model). No equations, self-citations, or uniqueness theorems are invoked that reduce any prediction or performance claim to fitted inputs by construction. Positive test-time scaling is presented as an observed experimental outcome rather than a definitional tautology. The derivation chain is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video understanding can be usefully cast as a POMDP whose observations are selectively chosen audio-visual cues.
invented entities (1)
-
TAURA (Turn-aware Adaptive Uncertainty Rescaled Advantage)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
3 Fu, C., Dai, Y ., Luo, Y ., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y ., Zhang, M., et al. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InConference on Computer Vision and Pattern Recognition (CVPR), pp. 24108–24118, 2025. 6 Gemini Team. Gemini: a family of highly capable multi- modal ...
Pith/arXiv arXiv 2025
-
[2]
Video-LLaV A: Learning united visual representation by alignment before projection
3 Lin, B., Ye, Y ., Zhu, B., Cui, J., Ning, M., Jin, P., and Yuan, L. Video-LLaV A: Learning united visual representation by alignment before projection. InAnnual Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5971–5984, 2024. 1 Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tuning. InAdvances in Neural Informatio...
arXiv 2024
-
[3]
GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
6 OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024. URL https://openai .com/index/hello-gpt-4o/. 3, 4, 6, 7 Rasheed, H., Zumri, M., Maaz, M., Yang, M., Khan, F. S., and Khan, S. H. Video-CoM: Interactive video reasoning via chain of manipulations. InConference on Computer Vision and Pattern Recognition (CVPR), 2026. 3, 6 Ren, W., Ma, W., Y...
Pith/arXiv arXiv 2024
-
[4]
Vide- oRFT: Incentivizing video reasoning capability in mllms via reinforced fine-tuning
6, 7 Wang, Q., Yu, Y ., Yuan, Y ., Mao, R., and Zhou, T. Vide- oRFT: Incentivizing video reasoning capability in mllms via reinforced fine-tuning. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2025a. 6 Wang, S., Yu, L., Gao, C., Zheng, C., Liu, S., Lu, R., Dang, K., Chen, X.-H., Yang, J., Zhang, Z., Liu, Y ., Yang, A., Zhao, A., Yue, Y ...
-
[5]
LifelongMemory: Lever- aging llms for answering queries in egocentric videos
3 Wang, Y ., Yang, Y ., and Ren, M. LifelongMemory: Lever- aging llms for answering queries in egocentric videos. CoRR, abs/2312.05269, 2023. 3 Wang, Z., Yu, S., Stengel-Eskin, E., Yoon, J., Cheng, F., Bertasius, G., and Bansal, M. VideoTree: Adaptive tree- based video representation for LLM reasoning on long videos. InConference on Computer Vision and Pa...
arXiv 2023
-
[6]
VCA: video curious agent for long video understanding
3 Yang, Z., Chen, D., Yu, X., Shen, M., and Gan, C. VCA: video curious agent for long video understanding. In International Conference on Computer Vision (ICCV), 2025c. 3 Yang, Z., Wang, S., Zhang, K., Wu, K., Leng, S., Zhang, Y ., Li, B., Qin, C., Lu, S., Li, X., and Bing, L. LongVT: Incentivizing ”thinking with long videos” via native tool calling. InCo...
arXiv 2026
-
[7]
For every user message containing multimodal content, the environmentdeletesthe dictionary entries of typeimage,video, oraudio
Media Removal:Once a sensing turn k is completed and its textual distillation Ok is recorded, the environment iterates through the previous chat history. For every user message containing multimodal content, the environmentdeletesthe dictionary entries of typeimage,video, oraudio
-
[8]
Frames 10.0s-20.0s. Timestamps: [10.00s, 12.50s, 15.00s] [MEDIA OMITTED...]
Metadata-Preserving Rewrite:To maintain the semantic integrity of the reasoning trace, the deleted media objects are replaced with a text-based summary appended with the marker [MEDIA OMITTED - Refer to Observation Ok]: • ForVisual Sampling( aframes), the environment recompiles the exact timestamps of all purged frames from the prior message content (e.g....
-
[9]
- Scanning: Use wide ranges (e.g., start=0, end=duration, num={max_frames_len}) to discover the overall timeline and identify key milestones or potential scene cuts
Visual Search (get_frames): (Max {max_frames_len} frames). - Scanning: Use wide ranges (e.g., start=0, end=duration, num={max_frames_len}) to discover the overall timeline and identify key milestones or potential scene cuts. - Precision: Use narrow windows (1-2s) with high num for micro-details (logos, text, fast motions, or subtle object state changes)
-
[10]
Person_A at [20, 45]
Counting & Re-ID: Assign approximate spatial locations [y, x] (0-100 scale; [0,0] is top-left) to each unique instance (e.g., " Person_A at [20, 45]") in your observation. This spatial ID prevents re-counting the same object across different frames/steps
-
[11]
Temporal Bisection: Find ’start’ and ’end’ boundary frames where a state changes, then iteratively narrow the interval to locate the exact transition second or frame
-
[12]
- Verbatim Logging: Identify speakers and transcribe speech near-verbatim
Audio Analysis (get_audio): (Max {max_audio_len}s). - Verbatim Logging: Identify speakers and transcribe speech near-verbatim. CRITICAL: Do not paraphrase or infer words to fit your hypothesis. - Acoustic Context: Identify critical off-screen or background sounds (e.g., footsteps, sirens, clicks) that provide environmental clues for temporal reasoning
-
[13]
Who moved first?
Multi-Modal Action Analysis (get_clip): (Max {max_clip_len}s). - Action & Temporal Dynamics: Analyze the nature of movement (speed, direction, continuity) and precise sequencing to solve "Who moved first?" or "Was the motion deliberate?". - Process Logic: Use when the continuous process of a state change (e.g., an object falling) is more critical than dis...
-
[14]
type": "get_frames
{"type": "get_frames", "start": float, "end": float, "num": int}
-
[15]
type": "get_audio
{"type": "get_audio", "start": float, "end": float}
-
[16]
type": "get_clip
{"type": "get_clip", "start": float, "end": float}
-
[17]
type": "answer
{"type": "answer", "content": "string"} - MCQ: Letter only (e.g., "A"). - TR: JSON array of one or more pairs, e.g., "[[10.5, 20.0], [35.0, 40.0]]". - NUM/SIZE: A single number string, e.g., "10.3". - FF: Detailed descriptive text. ============= STRICT EXECUTION PROTOCOL ============= - Forensic Rigor: Answering incorrectly is a failure. Rule out every po...
-
[18]
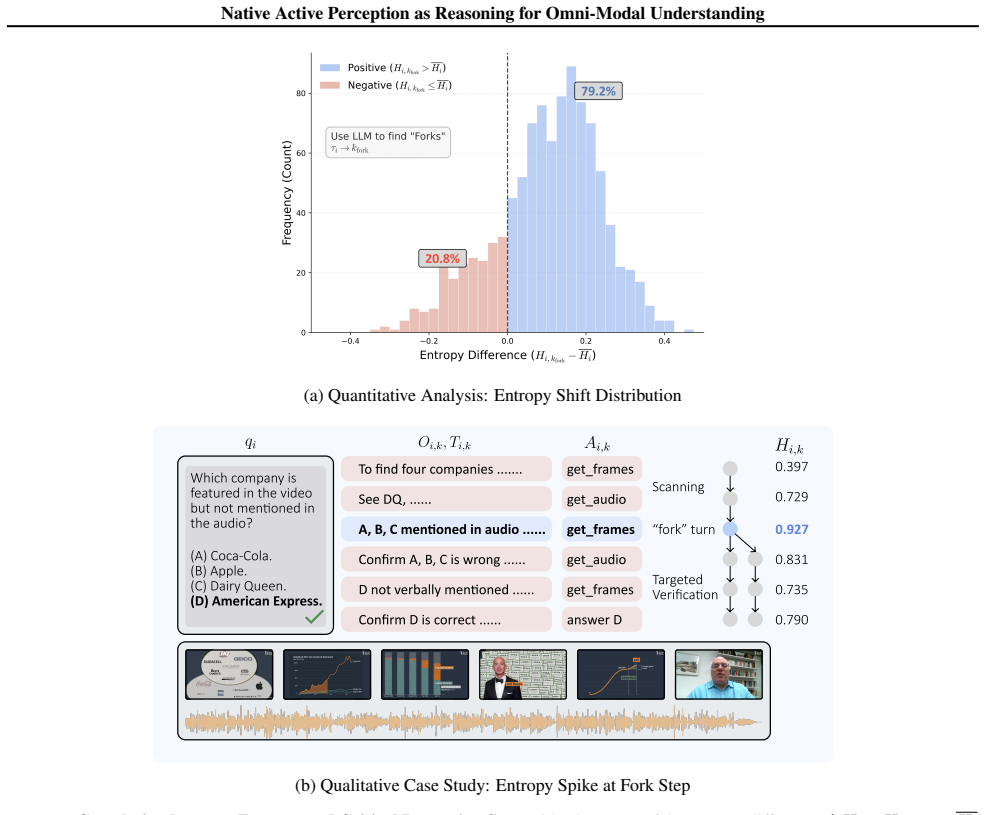
The policy is confident in this information gathering, resulting in low entropy (H≈0.397)
Routine Scanning:The agent performs standard scanning. The policy is confident in this information gathering, resulting in low entropy (H≈0.397)
-
[19]
This observation acts as a critical filter, ruling out these candidates
The Fork Step:A distinct entropy spike ( H≈0.927 ) occurs when the agent identifies that options A, B, and C are explicitly mentioned in the audio. This observation acts as a critical filter, ruling out these candidates. The spike reflects the agent’s pivotal decision to switch modalities (‘getframes‘) to visually verify the presence of the remaining opti...
-
[20]
Nish Parkar
Resolution:Subsequent verification resolves the ambiguity, returning the agent to a lower entropy state ( H≈0.790 ). This confirms that entropy spikes serve as a reliable signal for identifying high-value reasoning steps that warrant amplified reinforcement. 16 Native Active Perception as Reasoning for Omni-Modal Understanding (a) Quantitative Analysis: E...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.