Beyond the GUI Paradigm: Do Mobile Agents Need the Phone Screen?
Pith reviewed 2026-06-27 00:20 UTC · model grok-4.3
The pith
Command-line access lets mobile agents outperform screen-based GUI approaches on device tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
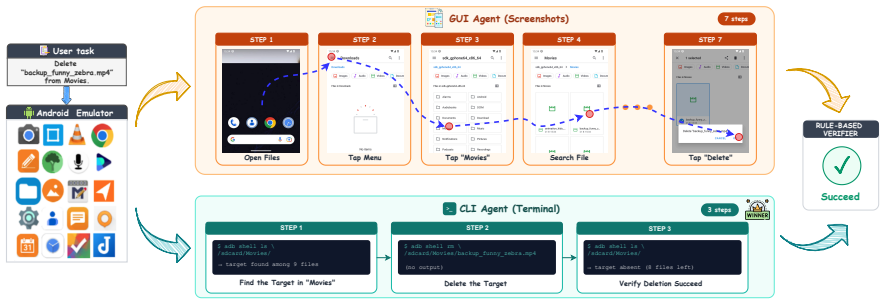
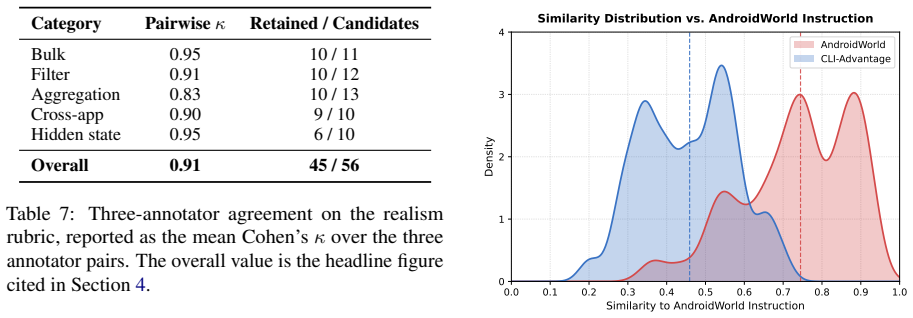
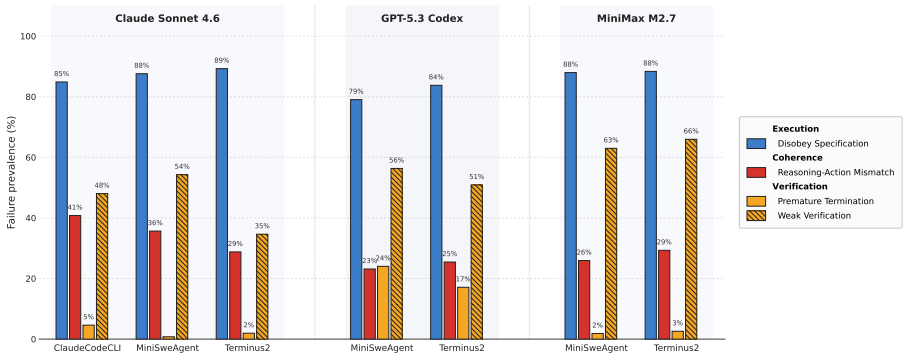
Coding agents equipped with command-line interface access, without any mobile-specific post-training, achieve higher task completion rates than GUI baselines on AndroidWorld and MobileWorld. The strongest configuration reaches 71.8 percent and 51.9 percent success, exceeding GUI results of at most 69.3 percent and 43.2 percent. Oracle CLI solutions solve 103 of 116 AndroidWorld tasks and 101 of 117 MobileWorld tasks. The new CLI-Advantage Task Suite shows uniform CLI superiority across bulk operations, multi-condition filtering, aggregation, cross-app workflows, and hidden device state, with agents using 10.7 steps on average versus 18.6 for GUI agents.
What carries the argument
Command-line interface (CLI) access that grants direct reach to device services and data, allowing coding agents to execute tasks without screen perception or simulated touch input.
If this is right
- Every CLI agent outperforms every GUI baseline across all five categories in the CLI-Advantage Task Suite.
- CLI agents complete tasks in 10.7 steps on average compared with 18.6 steps for GUI agents.
- 103 of 116 AndroidWorld tasks and 101 of 117 MobileWorld tasks are solvable through CLI commands.
- All tested CLI configurations remain competitive with or exceed GUI performance without requiring mobile-specific training.
Where Pith is reading between the lines
- Agents could use CLI for data-heavy tasks and fall back to GUI only when visual details are required.
- Many everyday phone operations such as filtering records or cross-app data movement do not need a visual interface.
- Future agent development may prioritize language-model tool use over vision models for mobile environments.
- The open-sourced oracle solutions and task suite enable direct tests of whether CLI advantages persist across different agent designs.
Load-bearing premise
The command-line access given to the agents supplies equivalent device service and data reach as the perception and interaction capabilities available to the GUI baselines.
What would settle it
A reproducible GUI agent reaching success rates above the reported oracle CLI levels of 88.8 percent on AndroidWorld or 86.3 percent on MobileWorld under matched evaluation conditions.
Figures

read the original abstract
Recent advances in mobile agents are dominated by the GUI paradigm, in which agents perceive UI information and emit screen interactions. However, mobile platforms also expose a command-line interface (CLI) that provides direct access to device services and data. We argue CLI deserves first-class consideration alongside GUI. We evaluate three coding agents (Claude Code, Terminus-2, mini-swe-agent) across four model APIs on AndroidWorld and MobileWorld without any mobile-specific post-training, comparing against three reproducible GUI baselines (GUI-Owl-1.5-32B, MAI-UI, Qwen3-VL-32B). Claude Code (Opus 4.7) reaches 71.8\% and 51.9\%, outperforming every reproducible GUI baseline (69.3/68.1/57.8\% on AndroidWorld; 43.2/26.3/13.3\% on MobileWorld), while every other CLI configuration remains competitive. To establish the paradigm's ceiling, we provide oracle CLI solutions that reach 88.8\% on AndroidWorld (103/116 tasks CLI-solvable) and 86.3\% on MobileWorld (101/117 tasks CLI-solvable), indicating substantial room for future improvement. To cover everyday user intents beyond the GUI scope, we introduce the \textbf{CLI-Advantage Task Suite}, comprising 45 templates across five categories: bulk operations, multi-condition filtering, aggregation, cross-app workflows, and hidden device state. Every CLI agent outperforms every GUI baseline in all five categories, with substantially fewer steps per task (10.7 vs.\ 18.6). To support future research on mobile CLI agents, we will open-source agent implementations, oracle solutions, the CLI-Advantage suite, and evaluation infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the command-line interface (CLI) paradigm deserves first-class status for mobile agents alongside the dominant GUI paradigm. It evaluates three coding agents (Claude Code, Terminus-2, mini-swe-agent) across four model APIs on AndroidWorld and MobileWorld without mobile-specific post-training, reporting that Claude Code (Opus 4.7) achieves 71.8% and 51.9% success rates, outperforming reproducible GUI baselines (69.3/68.1/57.8% on AndroidWorld; 43.2/26.3/13.3% on MobileWorld). Oracle CLI solutions reach 88.8% (103/116 tasks) and 86.3% (101/117 tasks). It introduces the CLI-Advantage Task Suite (45 templates in five categories: bulk operations, multi-condition filtering, aggregation, cross-app workflows, hidden device state) where all CLI agents outperform all GUI baselines with fewer steps (10.7 vs. 18.6), and commits to open-sourcing implementations, oracles, the suite, and evaluation infrastructure.
Significance. If the results hold under clarified conditions, the work provides a substantive empirical challenge to GUI-centric mobile agent research by demonstrating concrete outperformance and efficiency gains on both standard benchmarks and a new task suite focused on everyday intents outside typical GUI scope. Credit is due for the oracle solutions establishing performance ceilings, the category-wise breakdowns, the step-count comparison, and the open-sourcing commitment, all of which directly support reproducibility and future work.
major comments (2)
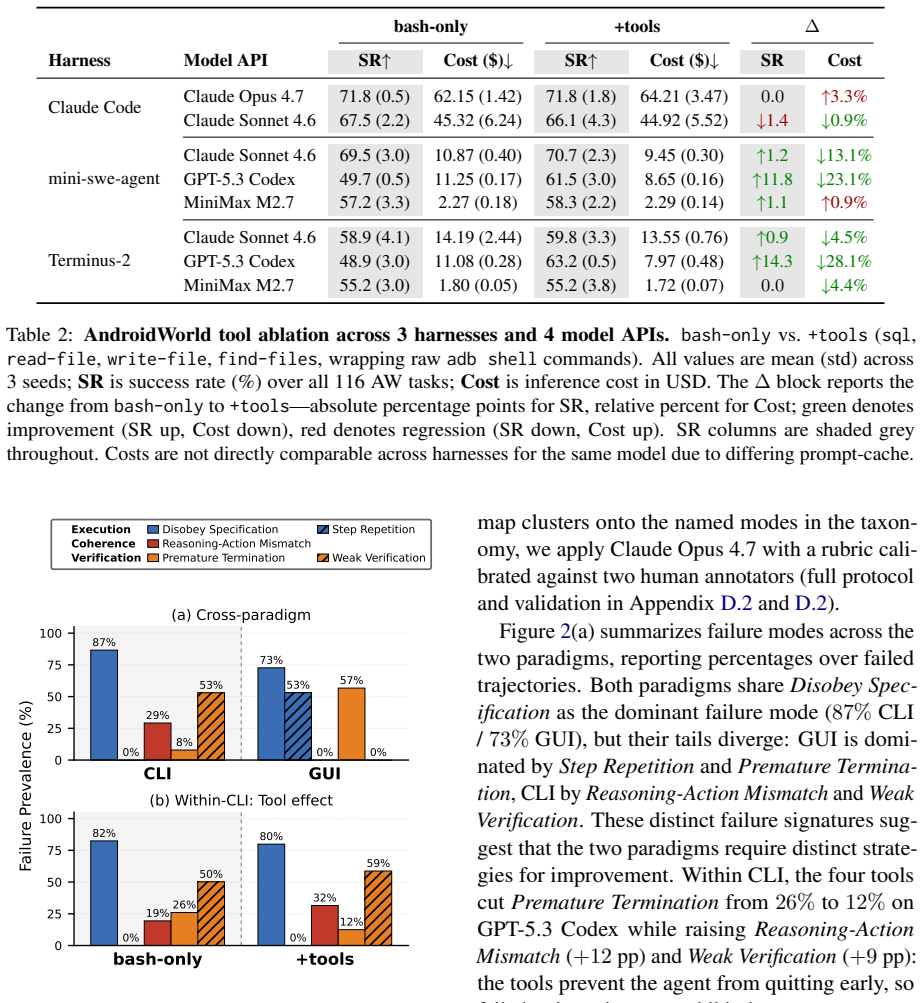
- [Abstract and evaluation setup] Abstract and evaluation setup: the central claim that CLI 'deserves first-class consideration' rests on outperformance, yet the manuscript notes CLI provides 'direct access to device services and data' without explicitly confirming whether the three GUI baselines (GUI-Owl-1.5-32B, MAI-UI, Qwen3-VL-32B) were granted equivalent direct service/data access or were restricted solely to screen perception and UI actions (taps/swipes). This risks confounding paradigm differences with action-space differences; a table or subsection detailing per-agent available actions and data reach in the shared environments is needed to substantiate the comparison.
- [Results reporting] Results reporting (AndroidWorld/MobileWorld tables): success rates are given as point estimates (e.g., 71.8% vs. 69.3%) with no error bars, standard deviations, or number of runs, weakening support for the claim of consistent outperformance, especially given the modest margins and the reader's note on moderate soundness.
minor comments (2)
- The manuscript would benefit from a brief limitations subsection addressing potential drawbacks of CLI access, such as security or permission model differences across devices.
- Figure or table captions for the CLI-Advantage results could more explicitly note the step-count metric definition and how tasks were sampled from the 45 templates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important points for clarifying the evaluation setup and strengthening results reporting. We address each major comment below and commit to revisions that improve the paper without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and evaluation setup] Abstract and evaluation setup: the central claim that CLI 'deserves first-class consideration' rests on outperformance, yet the manuscript notes CLI provides 'direct access to device services and data' without explicitly confirming whether the three GUI baselines (GUI-Owl-1.5-32B, MAI-UI, Qwen3-VL-32B) were granted equivalent direct service/data access or were restricted solely to screen perception and UI actions (taps/swipes). This risks confounding paradigm differences with action-space differences; a table or subsection detailing per-agent available actions and data reach in the shared environments is needed to substantiate the comparison.
Authors: We agree this clarification is necessary to avoid any perception of confounding. The GUI baselines operate exclusively under the standard GUI paradigm: they receive only screen-based perception (screenshots or UI hierarchies) and emit only UI actions (taps, swipes, text entry). In contrast, CLI agents receive shell access granting direct manipulation of device services, files, databases, and system APIs. To make this explicit, we will add a new subsection (Section 3.2) containing a comparison table that lists perception modalities, action spaces, and data reach for each agent category. This revision directly substantiates that observed differences arise from paradigm-level access rather than unequal capabilities within the same action space. revision: yes
-
Referee: [Results reporting] Results reporting (AndroidWorld/MobileWorld tables): success rates are given as point estimates (e.g., 71.8% vs. 69.3%) with no error bars, standard deviations, or number of runs, weakening support for the claim of consistent outperformance, especially given the modest margins and the reader's note on moderate soundness.
Authors: We acknowledge that single-run point estimates limit assessment of variability. All reported success rates reflect single deterministic evaluations over the complete task sets (116 tasks on AndroidWorld; 117 on MobileWorld). Multiple independent runs were not performed owing to the substantial compute cost of full agent trajectories. In revision we will (1) explicitly state the task counts and single-run nature in the tables and text, (2) highlight the oracle ceilings (103/116 and 101/117) and the uniform CLI superiority across all five categories of the CLI-Advantage suite (with step-count comparison) as convergent evidence beyond the main-benchmark margins. We cannot retroactively add error bars without new experiments, but the added transparency and supporting analyses address the concern. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparison
full rationale
The paper reports direct performance measurements of coding agents versus GUI baselines on AndroidWorld and MobileWorld, plus a new CLI-Advantage Task Suite. No derivations, equations, fitted parameters, predictions, or self-referential definitions appear in the abstract or described content. All central claims rest on observed task success rates and step counts rather than any reduction to prior fitted quantities or self-citation chains. The comparison is self-contained against external benchmarks with no load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AndroidWorld and MobileWorld benchmarks are representative of real mobile agent tasks and user intents.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. 2026. Why do multi-agent LLM sys- tems fail? InThe Thirty-ninth Annual Conference on Neural ...
Pith/arXiv arXiv 2026
-
[2]
Llm-powered gui agents in phone automation: Surveying progress and prospects.arXiv preprint arXiv:2504.19838. 9 Ryan Lopopolo. 2026. Harness engineering: leveraging codex in an agent-first world.OpenAI engineering note. Renze Lou, Baolin Peng, Wenlin Yao, Qianhui Wu, Hao Cheng, Suman Nath, Wenpeng Yin, and Jianfeng Gao. 2026. The tool illusion: Rethinking...
arXiv 2026
-
[3]
Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082. Muxin Tian, Zhe Wang, Blair Yang, Zhenwei Tang, Kunlun Zhu, Honghua Dong, Hanchen Li, Xinni Xie, Guangjing Wang, and Jiaxuan You. 2026. Swe-bench mobile: Can large language model agents develop industry-level mobile applications?arXiv preprint arXiv:2602.09540. Harsh Trivedi, Tushar Khot, Mare...
arXiv 2026
-
[4]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076. Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Hu...
Pith/arXiv arXiv 2024
-
[5]
InInternational Conference on Learning Representations, volume 2025, pages 5090– 5108
Os-atlas: Foundation action model for gen- eralist gui agents. InInternational Conference on Learning Representations, volume 2025, pages 5090– 5108. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, and 1 others
2025
-
[6]
Advances in Neural Information Processing Systems, 37:52040–52094
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, and 1 others. 2026. Mobile- agent-v3. 5: Multi-platform fundamental gui agent...
arXiv 2026
-
[7]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu
Springer. Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu
-
[8]
<SQL>" read-file <device_path> write-file <device_path>'<content>' find-files <directory>
Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20. Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, and 1 oth- ers. 2025. Mai-ui technical report: Real-world centric foundation gui agents.ar...
arXiv 2025
-
[9]
When checking multiple plausible locations, batch them into one shell call (e.g.,`ls dirA; ls dirB; cat config`) instead of one probe per turn
**Discover** -- find the relevant app, its data files, database schemas, and content providers. When checking multiple plausible locations, batch them into one shell call (e.g.,`ls dirA; ls dirB; cat config`) instead of one probe per turn. ,→ ,→
-
[11]
Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may see stale state
**Act** -- Android exposes three writing surfaces; pick by what the change has to drive, in this order:,→ (a) **Content providers** (`content insert/update/delete --uri ...`) when the data is exposed by a provider. Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may see s...
-
[17]
,→ ,→ ,→ ,→ ,→
**Find the destination, don't invent it** -- when writing a new file, follow this precedence: (a) find an existing example of the same file type owned by the target app and reuse its directory and naming convention exactly (case, extension, subfolder depth); (b) if no example exists, infer the path from the app's storage (shared_prefs, content provider UR...
-
[21]
Unknown command
**Discover before guessing a verb** -- when you reach for a`cmd <service>`invocation, run`cmd <service> help`first instead of guessing the action name. The wrong verb returns "Unknown command" and looks like the service is unsupported, when in fact the right verb was one line away. ,→ ,→ ,→ ## Shell Escaping The`sql`,`read-file`, and`write-file`tools hand...
-
[23]
<SQL>" # run SQL on a device DB write-file <device_path>
ALWAYS call`finish`when done with a meaningful`--description`. AndroidWorld — mini-SWE-agent harness The mini-SWE-agent prompt is split into asystemtemplate and aninstancetemplate, rendered per turn with{{ task }}filled in by the harness. System template. You are an Android automation agent. You control an Android device by issuing commands through a CLI ...
-
[26]
Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may see stale state
**Act** -- Android exposes three writing surfaces; pick by what the change has to drive, in this order:,→ 14 (a) **Content providers** (`content insert/update/delete --uri ...`) when the data is exposed by a provider. Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may se...
-
[32]
**Find the destination, don't invent it** -- when writing a new file, follow this precedence: (a) find an existing example of the same file type owned by the target app and reuse its directory and naming convention exactly (case, extension, subfolder depth);,→ (b) if no example exists, infer the path from the app's storage (shared_prefs, content provider ...
-
[36]
Unknown command
**Discover before guessing a verb** -- when you reach for a`cmd <service>`invocation, run`cmd <service> help`first instead of guessing the action name. The wrong verb returns "Unknown command" and looks like the service is unsupported, when in fact the right verb was one line away. ,→ ,→ ,→ ## Shell Escaping When a command contains quotes, parentheses, or...
-
[39]
<SQL>" # run SQL on a device DB write-file <device_path>
Respond with required format. </instructions> AndroidWorld — Terminus-2 harness The Terminus-2 harness uses a single template that interleaves task instruction and prior command output via the placeholders%INSTRUCTION%and%COMMAND_OUTPUT%. You are an Android automation agent. You control an Android device by issuing commands through a CLI wrapper.,→ ## Com...
-
[40]
When checking multiple plausible locations, batch them into one command (e.g.,`ls dirA; ls dirB; cat config`) instead of one probe per turn
**Discover** -- find the relevant app, its data files, database schemas, and content providers. When checking multiple plausible locations, batch them into one command (e.g.,`ls dirA; ls dirB; cat config`) instead of one probe per turn. ,→ ,→
-
[42]
Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may see stale state
**Act** -- Android exposes three writing surfaces; pick by what the change has to drive, in this order:,→ (a) **Content providers** (`content insert/update/delete --uri ...`) when the data is exposed by a provider. Direct sqlite to a provider-backed database can skip derived/indexed columns and change notifications, so a ContentResolver consumer may see s...
-
[43]
Once confirmed, do not re-verify
**Verify** -- query back through the same surface a consumer would read from (a content URI, a service`dumpsys`, or the file the app reads), not the underlying row. Once confirmed, do not re-verify. ,→ ,→
-
[44]
## Principles
**Sync** -- force-stop the app so it re-reads from disk on next launch. ## Principles
-
[45]
**Never assume** -- discover paths, package names, schemas, column values, content provider URIs, filename conventions, and extensions from the device. For text->integer mappings inside a database (codes, types, statuses, priorities), recover the mapping by`SELECT DISTINCT <text_field>, <id_field>`from existing rows before inserting new ones. ,→ ,→ ,→
-
[46]
Before any temporal reasoning, get the current date, time, and timezone from the device
**Ground in reality** -- base decisions on observed device state. Before any temporal reasoning, get the current date, time, and timezone from the device. Timestamps in databases are often UTC -- convert to the device's timezone before comparing. Some apps store timestamps in milliseconds, others in seconds; check existing rows to confirm the unit. ,→ ,→ ,→
-
[47]
Do not paraphrase, regenerate, or reformat
**Use exact task values** -- copy names, text, and values EXACTLY from the task description. Do not paraphrase, regenerate, or reformat. For numeric values, preserve full precision from your source -- do not truncate. ,→ ,→
-
[48]
**Find the destination, don't invent it** -- when writing a new file, follow this precedence: (a) find an existing example of the same file type owned by the target app and reuse its directory and naming convention exactly (case, extension, subfolder depth);,→ (b) if no example exists, infer the path from the app's storage (shared_prefs, content provider ...
-
[49]
Forbidden time-sinks: extracting APKs (`unzip`/`xxd`/`strings`on `base.apk`or`classes.dex`), full`dumpsys package`/`pm dump`, recursive`find /`over the whole filesystem
**Probe budget** -- if 2-3 probes have not surfaced the answer, the next probe is unlikely to either; switch tactic. Forbidden time-sinks: extracting APKs (`unzip`/`xxd`/`strings`on `base.apk`or`classes.dex`), full`dumpsys package`/`pm dump`, recursive`find /`over the whole filesystem. If a text->integer mapping isn't recoverable from existing rows or fro...
-
[50]
Do not re-verify, sanity-check, or explore further.,→
**Stop when done** -- once you have a verified answer or a successful write+sync, call`finish` immediately. Do not re-verify, sanity-check, or explore further.,→
-
[51]
After writing, verify through the same path the consumer would use (a content URI, a service's`dumpsys`/`service call`output, or the file the app reads), not the underlying row
**Verify through the surface a consumer reads from** -- the row a setting was written to is not always the surface a consumer queries. After writing, verify through the same path the consumer would use (a content URI, a service's`dumpsys`/`service call`output, or the file the app reads), not the underlying row. If a service-level read disagrees with the s...
-
[52]
Unknown command
**Discover before guessing a verb** -- when you reach for a`cmd <service>`invocation, run`cmd <service> help`first instead of guessing the action name. The wrong verb returns "Unknown command" and looks like the service is unsupported, when in fact the right verb was one line away. ,→ ,→ ,→ 17 ## Android-Specific Patterns These behaviors are non-obvious: ...
-
[53]
Give ONLY what was asked -- no extra commentary.,→
For information-retrieval tasks,`--description`in`finish`IS your answer. Give ONLY what was asked -- no extra commentary.,→
-
[54]
ALWAYS call`finish`when done with a meaningful`--description`
-
[55]
<pattern>
Respond ONLY with valid JSON, no extra text before or after. ## Task %INSTRUCTION% ## Last command output %COMMAND_OUTPUT% MobileWorld — Claude Code SDK harness You are an Android automation agent. You control an Android device through a typed CLI tool suite. You have no access to the screen - no screenshots, no UI hierarchy dumps, no tap/swipe/keyevent i...
-
[58]
during",
**Network backend** -- the app makes outbound HTTP where the endpoint is discoverable from on-device artifacts only. If you cannot observe the endpoint and schema, the backend is not your writing surface -- fall back to on-device state. ,→ ,→ 18 Termination: - Call`finish`when the task is done. For information tasks (find a value, answer a question), the ...
-
[69]
echo'foo (bar) baz'| wc -w
**Stop when done** -- once you have a verified answer or a successful write + sync, call `finish`immediately. Do not re-verify, sanity-check, or explore further.,→ ## Shell Escaping The typed tools (`sql`,`pg`,`read-file`,`write-file`,`json-read`,`json-write`) handle escaping internally -- prefer them. When you must compose raw shell with quotes, parens, ...
-
[71]
<pattern>
ALWAYS call`finish`when done, with a meaningful`--description`. MobileWorld — mini-SWE-agent harness System template. You are an Android automation agent. You control an Android device through a typed CLI tool suite as defined in <command_space>. Format your response as shown in <format_example>.,→ <command_space> # --- on-device tools --- find-files <dir...
-
[74]
during",
**Network backend** -- the app makes outbound HTTP where the endpoint is discoverable from on-device artifacts only. If you cannot observe the endpoint and schema, the backend is not your writing surface -- fall back to on-device state. ,→ ,→ Termination: - Call`finish`when the task is done. For information tasks (find a value, answer a question), the `--...
-
[85]
echo'foo (bar) baz'| wc -w
**Stop when done** -- once you have a verified answer or a successful write + sync, call `finish`immediately. Do not re-verify, sanity-check, or explore further.,→ ## Shell Escaping The typed tools (`sql`,`pg`,`read-file`,`write-file`,`json-read`,`json-write`) handle escaping internally -- prefer them. When you must compose raw shell with quotes, parens, ...
-
[87]
ALWAYS call`finish`when done, with a meaningful`--description`
-
[88]
<pattern>
Respond with required format (THOUGHT line + a single```bash command fence). </instructions> MobileWorld — Terminus-2 harness You are an Android automation agent. You control an Android device through a typed CLI tool suite. You have no access to the screen - no screenshots, no UI hierarchy dumps, no tap/swipe/keyevent input. All interaction is through sh...
-
[89]
Use the typed device tools first;`adb shell`is the escape hatch for`pm`,`am`,`dumpsys`,`settings`, `getprop`, ad-hoc composition
**On-device only** -- device storage, content providers, system settings, intents. Use the typed device tools first;`adb shell`is the escape hatch for`pm`,`am`,`dumpsys`,`settings`, `getprop`, ad-hoc composition. ,→ ,→
-
[90]
Use`pg`/`backend-exec`with a`<backend_grep>`that matches an actual row in `service-status`output
**Container backend** -- the persistent state lives in a container visible to`service-status`. Use`pg`/`backend-exec`with a`<backend_grep>`that matches an actual row in `service-status`output. Do NOT guess names. ,→ ,→
-
[91]
during",
**Network backend** -- the app makes outbound HTTP where the endpoint is discoverable from on-device artifacts only. If you cannot observe the endpoint and schema, the backend is not your writing surface -- fall back to on-device state. ,→ ,→ Termination: - Call`finish`when the task is done. For information tasks (find a value, answer a question), the `--...
-
[92]
**Discover** -- find the relevant app, its data files, database schemas, and content providers through`service-status`or`adb shell "pm list packages | grep <keyword>`.,→
-
[93]
Understand formats, ID mappings, timestamp units, and naming conventions
**Inspect** -- read existing data before modifying. Understand formats, ID mappings, timestamp units, and naming conventions. Match observed patterns exactly when creating new entries.,→
-
[94]
**Act** -- pick the writing surface by what the change has to drive
-
[95]
If a service-level read disagrees with the row, the service-level value is what matters
**Verify** -- query back through the surface a *consumer* would read from (a content URI, `dumpsys`/`service call`output, the file the app reads, an HTTP API response), not the underlying row. If a service-level read disagrees with the row, the service-level value is what matters. ,→ ,→ ,→
-
[96]
## Principles
**Sync** -- force-stop the app so it re-reads on next launch. ## Principles
-
[97]
Do not rely on prior knowledge.,→
**Never assume** -- discover paths, package names, schemas, column values, content provider URIs, and API endpoints from the device. Do not rely on prior knowledge.,→
-
[98]
Timestamps in DBs are often UTC; some apps use seconds, others milliseconds -- check existing rows to confirm the unit
**Ground in reality** --`adb shell date`before any temporal reasoning. Timestamps in DBs are often UTC; some apps use seconds, others milliseconds -- check existing rows to confirm the unit. ,→ ,→
-
[99]
When the answer is extracted from a document/app/DB, copy the literal token verbatim -- do not translate, expand abbreviations, reformat dates, or round numbers
**Use exact task values, exact source tokens** -- copy names, text, and numbers EXACTLY from the task description. When the answer is extracted from a document/app/DB, copy the literal token verbatim -- do not translate, expand abbreviations, reformat dates, or round numbers. Prefer raw units over human-readable ones (`stat -c %s`over`du -sh`). ,→ ,→ ,→
-
[100]
,→ ,→ ,→ ,→
**Find the destination, don't invent it** -- for new files, follow this precedence: (a) a path explicitly named in app source / strings / bundle / manifest / shared_prefs; (b) reuse the directory and naming convention of an existing example of the same file type owned by the target app; (c) infer from content URIs or manifest data dirs; (d) fall back to a...
-
[101]
Forbidden time-sinks: extracting APKs (`unzip`/`xxd`/`strings`on `base.apk`or`classes.dex`), full`dumpsys package`/`pm dump`, recursive`find /`over the whole filesystem
**Probe budget** -- if 2-3 probes haven't surfaced the answer, the next one probably won't either: switch tactic. Forbidden time-sinks: extracting APKs (`unzip`/`xxd`/`strings`on `base.apk`or`classes.dex`), full`dumpsys package`/`pm dump`, recursive`find /`over the whole filesystem. ,→ ,→ ,→
-
[102]
**Stop when done** -- once you have a verified answer or a successful write + sync, call `finish`immediately. Do not re-verify, sanity-check, or explore further.,→ ## Android-Specific Patterns 26 - **Provider notifications**: after`content insert/update/delete`(or a write through a content provider), the provider emits change notifications itself -- manua...
-
[103]
Give ONLY what was asked -- no commentary, no prefixes, exact format.,→
For information tasks,`--description`in`finish`IS your answer. Give ONLY what was asked -- no commentary, no prefixes, exact format.,→
-
[104]
ALWAYS call`finish`when done, with a meaningful`--description`. ## Task %INSTRUCTION% ## Last command output %COMMAND_OUTPUT% 27 Anatomy of a prompt All six prompts share the same skeleton, organised around the four categories of guidance described in Section 3:
-
[105]
what has been observed,
Four-phase interaction cycle:discover rel- evant data, inspect existing state, act through the terminal interface, and verify the result. The cycle appears verbatim under theAp- proachheading in each prompt and is pre- ceded by three preflight questions (“what has been observed,” “what is still an assumption,” “what is the most likely failure mode”). Wher...
-
[106]
On Mo- bileWorld the same hierarchy is restated as three writing surfaces (on-device, container backend, network backend) so the agent picks the layer by where the consumer reads
Prioritised hierarchy of mechanisms for modifying device state.A ranked list of write paths to try in order: content providers first (so derived columns and change notifications fire), then system service commands ( cmd <service>, service call, am broadcast) for live-service effects, then direct SQLite or file writes under /data/data/<pkg>/ for app-privat...
-
[107]
To- gether they cap exploration cost while keeping the agent deliberate per call
Efficiency strategies.Two rules: batch re- lated probes into a single shell call rather than one probe per turn, and respect a small probe budget — if 2–3 probes have not surfaced the answer, switch tactic rather than continuing with forbidden time-sinks (extracting APKs, fulldumpsys package, recursivefind /). To- gether they cap exploration cost while ke...
-
[108]
On MobileWorld this cate- gory also covers the device file-system layout, database discovery patterns, and the half-open range-query convention for UTC timestamps
Platform-specific patterns for file synchro- nisation and data persistence.A short list of non-obvious Android behaviours: media- scanner broadcast after writes to shared stor- age, the content-provider self-notify seman- tics that make manual broadcasts unnecessary for canonical providers, and the recovery pro- cedure for a corrupt SQLite file (remove th...
-
[109]
analysis
Output structure.Each harness imposes a different response shape. The Claude Code SDK harness uses native tool calls and there- fore needs no response-format block — the agent invokes the shim binaries directly via the SDK’s Bash tool. The mini-SWE-agent harness asks for a free-form THOUGHT: line followed by exactly one fenced```bash com- mand. The Termin...
-
[110]
<answer>
Section ordering and partitioning.The Claude SDK prompt is a single block. The mini-SWE-agent prompt is split into a system template (role + command space + format ex- ample) and an instance template (constraint + approach + principles + rules, rendered per turn with the task interpolated) following its original design. The Terminus-2 prompt is a single t...
-
[111]
parameter- 30 bearing attributes on the task class), or any gold-answer file
No verifier-internals leakage.The trajectory must be producible from device state and the task goal alone, without reading the verifier source, its private fixtures (e.g. parameter- 30 bearing attributes on the task class), or any gold-answer file
-
[112]
you skipped the force-stop
No hardcoded answers.Numeric and string answers for information-retrieval tasks must becomputedfrom data the verifier itself reads, not hardcoded as constants in the trajectory. (2) The oracle-agent loop We treat oracle construction itself as a human–LLM collaboration: a separateoracle-agent(Claude Code, running on the host) is given a far richer context ...
-
[113]
shell",
State-check.The grader re-reads device state after the agent finishes and compares it to the post-action expectation. The agent’s natural- language output is ignored. def is_successful(self, env) -> float: rows = adb_utils.issue_generic_request( "shell", "sqlite3 ... 'SELECT ... FROM ... WHERE ...'", env) return 1.0 if matches_expected(rows) else 0.0
-
[114]
Delete all expenses in Pro Expense that are less than $1.00 (less than 100 cents)
Cache-match.The grader inspects the agent’s FINISH(content=...) payload. Every expected substring (computed in initialize_task from the seed) must ap- pear; substring containment, case-sensitive, no whitespace normalization. def is_successful(self, env) -> float: return 1.0 if all( s in env.interaction_cache for s in self._expected ) else 0.0 Example 1Goa...
2026
-
[115]
State the dominant Android failure mechanism in one sentence, in your own words (no taxonomy jargon)
Read the 8 exemplars. State the dominant Android failure mechanism in one sentence, in your own words (no taxonomy jargon)
-
[116]
Which top-level class (Execution, Coherence, or Verification) best describes the failure? Justify in one sentence
Walk the tree top-down. Which top-level class (Execution, Coherence, or Verification) best describes the failure? Justify in one sentence
-
[117]
Within the chosen class, pick the single best-fitting leaf
-
[118]
TB7: timezone misinterpretation -> Disobey Specification, wrong output protocol
If two leaves are equally plausible, consult tie_breakers and cite the rule number that decides (e.g. "TB7: timezone misinterpretation -> Disobey Specification, wrong output protocol")
-
[119]
cluster_id
Optionally record one secondary leaf, only if at least 3 of the 8 exemplars also support it. Never list more than one secondary. OUTPUT (strict JSON, no prose outside the object) { "cluster_id": "...", "mechanism": "one sentence in plain English", "primary_class": "Execution | Coherence | Verification", "primary_leaf": "...", "tie_breaker": "TB# or null",...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.