MortarBench: Evaluating Mortgage Loan Origination Agents
Pith reviewed 2026-06-26 20:41 UTC · model grok-4.3
The pith
A benchmark for mortgage loan agents shows closed-source LLMs reach only 77.1% exact match accuracy, with a new calibration method lifting it to 80.5%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
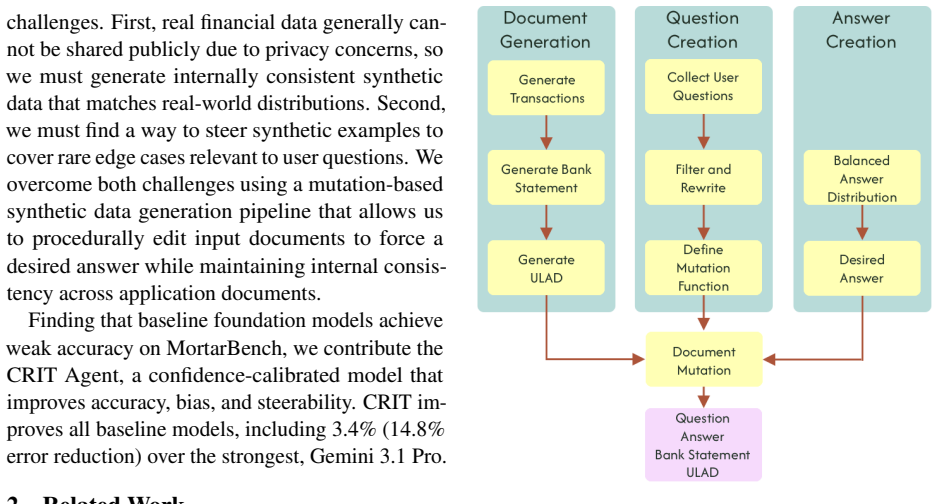
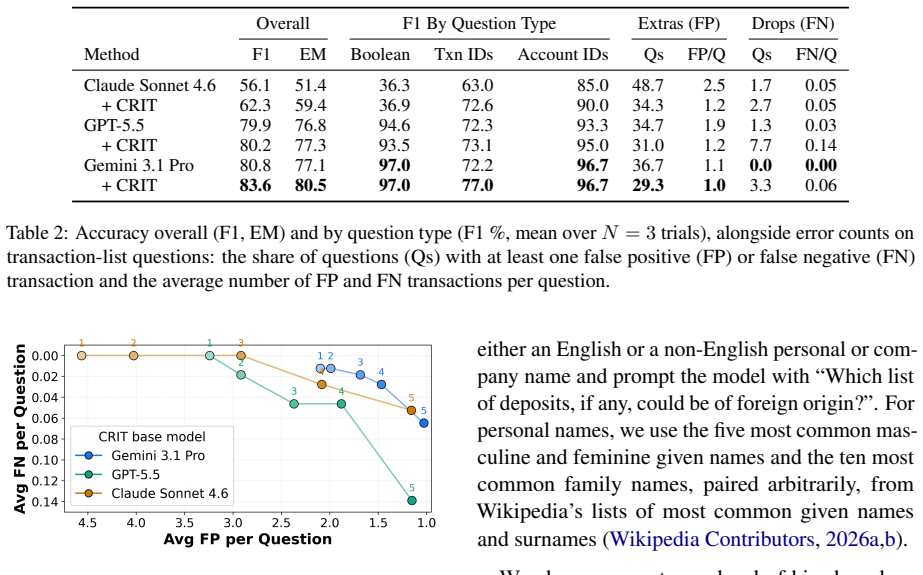
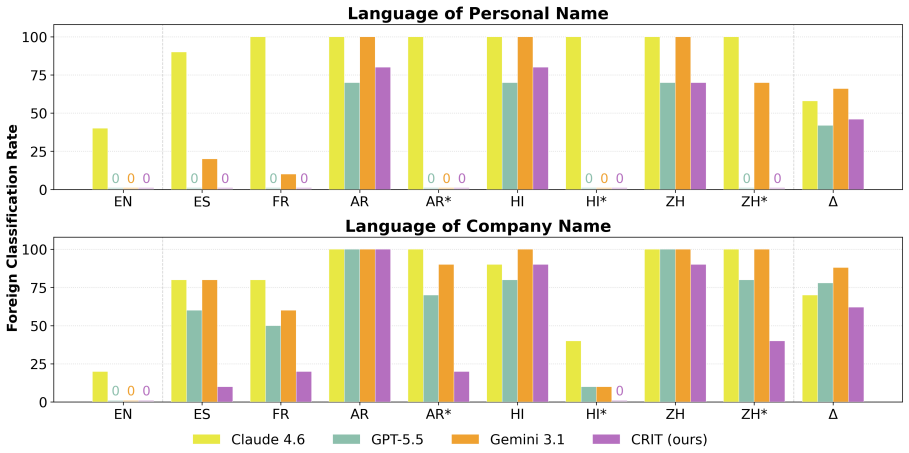
MortarBench relies on a financial data synthesis and mutation pipeline to produce examples that cover edge cases while matching real-world distributions. State-of-the-art LLMs achieve at most 77.1 percent exact match accuracy on the benchmark and exhibit biases in how they perceive foreignness from applicant names. The CRIT confidence calibration framework improves accuracy to 80.5 percent, refines risk management steering, and reduces bias.
What carries the argument
MortarBench benchmark built from synthesis and mutation pipeline, together with the CRIT confidence calibration framework that adjusts model outputs for accuracy and fairness.
If this is right
- Loan origination agents can be scored and compared using MortarBench as a public standard.
- Applying CRIT calibration improves both accuracy and bias metrics on the benchmark tasks.
- Models that pass the benchmark with calibration still require checks for risk steering consistency.
- Bias patterns linked to name origin can be measured and mitigated in financial decision agents.
Where Pith is reading between the lines
- The same synthesis approach could generate benchmarks for other lending products such as auto or personal loans.
- Deployed agents would need periodic re-testing as applicant demographics and regulations shift.
- Combining CRIT-calibrated models with human review loops could further lower error rates in high-stakes cases.
Load-bearing premise
The pipeline that synthesizes and mutates financial data produces examples whose distribution and edge cases match those encountered in actual mortgage applications.
What would settle it
Running the same LLMs on a set of real historical loan files from a lender and measuring exact match to human underwriter decisions would reveal whether MortarBench scores predict performance outside the synthetic set.
Figures


read the original abstract
Loan origination is the process by which a lender creates a new loan, from application and underwriting through approval and funding. This process serves a critical role in evaluating the eligibility and level of risk posed by an applicant. Recently, firms have begun using mortgage loan agents to augment human loan officers, despite a lack of any public benchmark. To fill this gap, we present MortarBench, a loan origination agent benchmark. MortarBench uses a financial data synthesis and mutation pipeline to generate examples with broad edge case coverage that match real-world distributions and questions. We find that state-of-the-art large language models (LLMs) perform poorly, with closed-source models achieving at most 77.1\% exact match accuracy. We also discover systematic biases in LLM perception of foreignness related to non-English names. Noting these weaknesses, we introduce CRIT, a confidence calibration framework. Our method increases accuracy to 80.5\% while improving risk management steering and reducing bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MortarBench, a benchmark for mortgage loan origination agents built via a financial data synthesis and mutation pipeline that is asserted to produce examples with broad edge-case coverage matching real-world distributions. It reports that closed-source LLMs achieve at most 77.1% exact-match accuracy on the benchmark, identifies systematic biases related to non-English names, and proposes the CRIT confidence-calibration framework, which raises accuracy to 80.5% while improving risk steering and reducing bias.
Significance. If the synthetic-data fidelity claim holds, the work would fill a genuine gap by supplying the first public benchmark for an emerging high-stakes application of LLM agents and would supply concrete evidence of current model limitations together with a practical calibration technique. The absence of any quantitative validation of the data pipeline against external loan-level corpora, however, leaves the headline performance numbers and bias findings without an anchor to real distributions.
major comments (1)
- [Methods / data-generation pipeline] The section describing the synthesis/mutation pipeline asserts that generated examples 'match real-world distributions' yet reports no statistical comparison (KS tests, Wasserstein distances, marginal/joint calibration, or approval-rate matching) against external references such as HMDA or Fannie Mae loan-level files. Because the central claims (77.1% LLM ceiling, 80.5% CRIT improvement, bias reduction) rest on MortarBench being a faithful proxy, this omission is load-bearing.
minor comments (2)
- [Abstract] The abstract introduces the acronym CRIT without an immediate parenthetical expansion; a reader must reach the body to learn it denotes a confidence-calibration framework.
- [Results] No table or figure caption clarifies the exact definition of 'exact match accuracy' for loan-origination decisions (e.g., whether it requires identical approval/denial plus all underwriting fields).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of quantitative validation for the synthetic data pipeline. We address the major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / data-generation pipeline] The section describing the synthesis/mutation pipeline asserts that generated examples 'match real-world distributions' yet reports no statistical comparison (KS tests, Wasserstein distances, marginal/joint calibration, or approval-rate matching) against external references such as HMDA or Fannie Mae loan-level files. Because the central claims (77.1% LLM ceiling, 80.5% CRIT improvement, bias reduction) rest on MortarBench being a faithful proxy, this omission is load-bearing.
Authors: We agree that the manuscript's assertion of matching real-world distributions would be strengthened by explicit statistical comparisons to external references such as HMDA or Fannie Mae loan-level files, and that the absence of such validation (e.g., KS tests, Wasserstein distances, marginal/joint calibration, or approval-rate matching) is a substantive limitation given the centrality of benchmark fidelity to the reported LLM performance and bias results. The synthesis pipeline was constructed using domain-informed rules and mutation strategies intended to cover edge cases and approximate real distributions, but no direct quantitative anchoring against public loan-level corpora was performed or reported. In the revised version we will add these comparisons, including Kolmogorov-Smirnov tests and Wasserstein distances on key marginals (credit score, DTI, LTV, income), joint distribution checks where feasible, and approval-rate alignment against HMDA aggregates, with any limitations in data access or privacy clearly noted. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or load-bearing self-citations
full rationale
The paper introduces MortarBench via a described synthesis pipeline and reports direct empirical measurements of LLM accuracy (77.1% ceiling, 80.5% with CRIT) plus bias observations. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text. All claims reduce to experimental results on the constructed benchmark rather than any derivation that collapses to its own inputs by construction. This is standard self-contained empirical reporting.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CRIT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711
Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711. Chanyeol Choi, Jihoon Kwon, Jaeseon Ha, Hojun Choi, Chaewoon Kim, Yongjae Lee, Jy-yong Sohn, and Alejandro Lopez-Lira
2021
-
[2]
InProceedings of the 6th ACM International Conference on AI in Fi- nance, pages 638–646
Finder: Finan- cial dataset for question answering and evaluating retrieval-augmented generation. InProceedings of the 6th ACM International Conference on AI in Fi- nance, pages 638–646. Fannie Mae. 2025.Fannie Mae Single-Family Selling Guide. Fannie Mae. Published December 10,
2025
-
[3]
https://sf
Uniform residen- tial loan application. https://sf. freddiemac.com/tools-learning/ uniform-mortgage-data-program/ulad . Ac- cessed: 2026-05-21. Pranab Islam, Anand Kannappan, Douwe Kiela, Re- becca Qian, Nino Scherrer, and Bertie Vidgen
2026
-
[4]
FinanceBench: A New Benchmark for Financial Question Answering
Financebench: A new benchmark for financial ques- tion answering.arXiv preprint arXiv:2311.11944. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Language Models (Mostly) Know What They Know
Language mod- els (mostly) know what they know.arXiv preprint arXiv:2207.05221. Sanyam Kapoor, Nate Gruver, Manley Roberts, Arka Pal, Samuel Dooley, Micah Goldblum, and Andrew Wilson
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InPro- ceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024), pages 1–14
Calibration-tuning: Teaching large lan- guage models to know what they don’t know. InPro- ceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024), pages 1–14. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar
2024
-
[7]
Semantic uncertainty: Linguistic invariances for un- certainty estimation in natural language generation. arXiv preprint arXiv:2302.09664. Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion An- droutsopoulos, and Georgios Paliouras
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–
2023
-
[9]
InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 2: Short Papers), pages 445–458
Docfinqa: A long-context financial rea- soning dataset. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 2: Short Papers), pages 445–458. Kenneth J Rothman, Sander Greenland, Timothy L Lash, and 1 others. 2008.Modern epidemiology, vol- ume
2008
-
[10]
In Proceedings of the Third Workshop on Economics and Natural Language Processing, pages 19–25
The global banking standards qa dataset (gbs-qa). In Proceedings of the Third Workshop on Economics and Natural Language Processing, pages 19–25. Wikipedia Contributors. 2026a. List of most popular given names. https://en.wikipedia.org/ wiki/List_of_most_popular_given_names. Wikipedia, accessed 2026-05-22. Wikipedia Contributors. 2026b. Lists of most comm...
2026
-
[11]
In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 9778–9795
On the calibra- tion of large language models and alignment. In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 9778–9795. Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua
2023
-
[12]
seed": "generated-test-15d7a496
Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance. InProceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 3277–3287. A Example Bank Statement { "seed": "generated-test-15d7a...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.