Hidden Anchors in Multi-Agent LLM Deliberation
Pith reviewed 2026-06-26 20:57 UTC · model grok-4.3
The pith
Multi-agent LLM deliberation is driven by recoverable hidden anchors that let opinions escape the convex hull of initial beliefs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multi-agent deliberation in LLMs follows a closed-loop dynamical system where each agent carries a hidden internal belief, its anchor, that keeps pulling its stated opinion irrespective of its neighbors. The anchor is recoverable from the deliberation trajectory alone. When the anchor lies sufficiently far from the initial opinions, the trajectory can leave the convex hull of those initials, producing confidence increases forbidden by classical DeGroot or Friedkin-Johnsen rules. Whether the recovered anchor also predicts held-out runs supplies a direct test of whether the closed-loop model is operative for a given LLM family.
What carries the argument
The hidden anchor, a fixed internal belief that exerts continuous pull on each agent's output inside a closed-loop dynamical system.
If this is right
- An agent's final can exceed every initial value when its anchor sits outside the starting hull.
- Classical linear consensus models are incomplete once anchors are distant from the initial opinions.
- Anchor position relative to initials determines whether deliberation needs the full closed-loop description.
- Anchor recovery supplies a diagnostic that distinguishes models whose deliberation is truly anchor-driven from those that are not.
Where Pith is reading between the lines
- If anchors are stable across tasks, they could be estimated once and then used to forecast multi-agent performance on unseen problems without running new deliberations.
- Prompting strategies that move an agent's effective anchor closer to the correct answer might raise accuracy more reliably than simply adding more rounds of discussion.
- The spectrum of anchor distances across model families offers a concrete axis along which to compare how different LLMs use multi-agent interaction.
Load-bearing premise
Multi-agent LLM deliberation behaves as a closed-loop dynamical system whose hidden anchors can be recovered from observed opinion trajectories and validated by generalization to new runs.
What would settle it
Recover the candidate anchors from one set of deliberation runs and check whether they correctly predict the full sequence of answers in a second, independent set of runs on the same questions; systematic mismatch would falsify the claim.
Figures

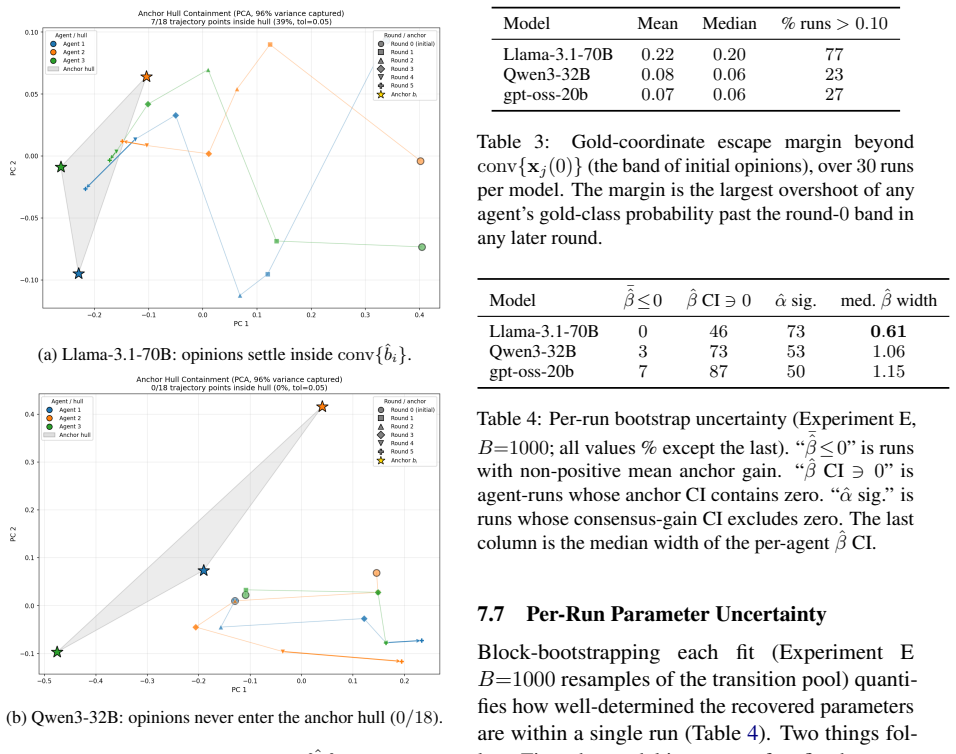

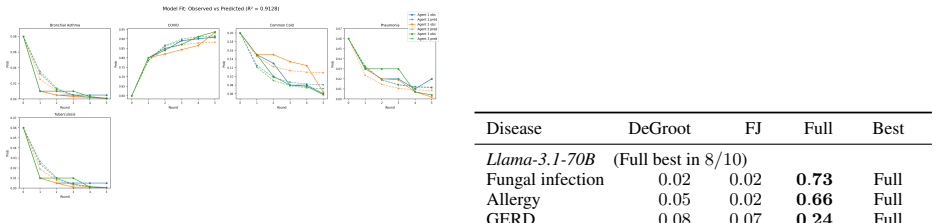

read the original abstract
Multi-agent LLM deliberation, where agents exchange and revise answers over several rounds, is increasingly used to improve reasoning and accuracy, yet how and why it works is rarely modelled. Such deliberation mirrors how humans reach decisions. As social animals we are pulled both by the group, the herd effect that classical opinion-dynamics models such as DeGroot and Friedkin--Johnsen capture, and by our own internal belief, which they do not. We model multi-agent deliberation as a closed-loop dynamical system in which each agent carries a hidden internal belief, its anchor, that continually pulls its opinion regardless of its neighbours. We show this anchor can be recovered from the deliberation alone, and that it explains a behaviour classical consensus rules forbid: an agent's confidence in the correct answer can climb past where any agent started, escaping the space (convexhull) formed by the initial beliefs. Checking whether the recovered anchor also predicts held-out runs (generalizes) gives a simple test for when a model is truly driven bysuch an anchor. Across three open-weight model families this is a spectrum, not all-or-nothing. All anchors' influence are about equally strongly, but they differ in where the anchor sits, and only when it sits far from the initial opinions does deliberation escape the hull and need the full closed-loop model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models multi-agent LLM deliberation as a closed-loop dynamical system in which each agent is pulled by both neighbors and a fixed hidden anchor (internal belief). It claims to recover these anchors directly from observed deliberation trajectories, shows that sufficiently distant anchors explain agents escaping the convex hull of initial beliefs (impossible under DeGroot-style convex combination), and validates the recovered anchors by testing whether they predict held-out deliberation runs. Results across three open-weight model families indicate that anchor influence strength is comparable but anchor location determines whether hull escape occurs.
Significance. If the recovery procedure is robust and the model is shown to be identifiable, the work supplies a concrete mechanistic account for why multi-agent LLM deliberation can produce confidence levels outside the initial belief hull. The held-out generalization test and the spectrum finding (not all models require the full closed-loop form) are methodologically useful. The link to classical opinion dynamics is a strength.
major comments (3)
- [§3] §3 (Model and Recovery Procedure): The anchor is recovered by fitting the assumed closed-loop form to trajectories; the held-out generalization test (reported in §5) confirms that the fitted parameters reproduce new runs, but does not establish identifiability. Alternative generative processes (non-stationary neighbor weights, implicit memory of prior rounds, or different functional forms) could produce identical out-of-hull trajectories without a constant hidden anchor. This is load-bearing for the claim that the recovered anchor is the causal driver of escape.
- [§4] §4 (Hull-Escape Results): The manuscript states that anchors far from initial opinions enable escape, yet provides no quantitative comparison of model fit (e.g., log-likelihood or prediction error on held-out data) between the anchor model and a pure DeGroot baseline on the same trajectories. Without this, it remains unclear whether the anchor term is necessary or merely sufficient to reproduce the observed escape.
- [§5] §5 (Generalization Test): The test treats successful prediction on held-out runs as evidence that the model is 'truly driven by such an anchor.' This only shows that some parameter set in the assumed form reproduces the data; it does not rule out other mechanisms that would pass the same test. An explicit comparison to at least one alternative dynamical system is required to support the uniqueness claim.
minor comments (3)
- Notation for the closed-loop update rule is introduced without an explicit equation number in the main text; adding an equation label would improve traceability when referring to the recovery procedure.
- [§2] The abstract and §2 cite DeGroot and Friedkin–Johnsen but omit more recent extensions (e.g., stubborn-agent or time-varying influence models) that already allow limited out-of-hull movement; a brief discussion of how the anchor model differs would clarify novelty.
- Figure captions for the trajectory plots do not state the number of deliberation rounds or the exact confidence metric used; this makes it difficult to assess the magnitude of hull escape.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important issues around identifiability and the need for explicit model comparisons, which we address point-by-point below. We plan targeted revisions to strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Model and Recovery Procedure): The anchor is recovered by fitting the assumed closed-loop form to trajectories; the held-out generalization test (reported in §5) confirms that the fitted parameters reproduce new runs, but does not establish identifiability. Alternative generative processes (non-stationary neighbor weights, implicit memory of prior rounds, or different functional forms) could produce identical out-of-hull trajectories without a constant hidden anchor. This is load-bearing for the claim that the recovered anchor is the causal driver of escape.
Authors: We agree that held-out prediction alone does not prove uniqueness against all alternatives. In the revision we will add an explicit limitations paragraph in §3 and §5 stating that the constant-anchor model is a parsimonious explanation consistent with hull escape (which DeGroot-style models forbid) but that time-varying or memory-based mechanisms remain possible. We will also note that such alternatives typically require additional parameters and may not generalize as cleanly across model families. revision: partial
-
Referee: [§4] §4 (Hull-Escape Results): The manuscript states that anchors far from initial opinions enable escape, yet provides no quantitative comparison of model fit (e.g., log-likelihood or prediction error on held-out data) between the anchor model and a pure DeGroot baseline on the same trajectories. Without this, it remains unclear whether the anchor term is necessary or merely sufficient to reproduce the observed escape.
Authors: We accept this point. The revised §4 will include a direct quantitative comparison: for each model family we will report held-out log-likelihood (or MSE) for both the full anchor model and a pure DeGroot baseline fitted to the same trajectories. This will quantify the incremental explanatory power of the anchor term. revision: yes
-
Referee: [§5] §5 (Generalization Test): The test treats successful prediction on held-out runs as evidence that the model is 'truly driven by such an anchor.' This only shows that some parameter set in the assumed form reproduces the data; it does not rule out other mechanisms that would pass the same test. An explicit comparison to at least one alternative dynamical system is required to support the uniqueness claim.
Authors: We concur that generalization within the assumed form does not rule out alternatives. The revision will add, in §5, an explicit comparison to one alternative (a model with implicit memory of prior rounds, implemented via an additional state variable). We will report its held-out prediction error relative to the anchor model and discuss implications for when the closed-loop form is required. revision: yes
Circularity Check
No significant circularity; derivation relies on modeling assumption and out-of-sample validation
full rationale
The paper posits a closed-loop model with hidden anchors as an explanatory framework for deliberation trajectories, recovers parameters from observed data, and validates via generalization to held-out runs. This is standard parameter estimation plus predictive checking rather than any reduction by construction. No equations are shown that equate the recovered anchor to the input trajectories tautologically, no self-citations are invoked as load-bearing uniqueness theorems, and the held-out test is independent of the fitting step. The central claim therefore remains falsifiable against alternative generative processes.
Axiom & Free-Parameter Ledger
invented entities (1)
-
hidden anchor
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
Models delayed verification in multi-agent LLMs as graph consensus, derives stability thresholds (inverse golden ratio for delay two) via grounded Laplacian, and gives a supermodular greedy rule for corrector placemen...
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 25th International Conference on Machine Learning (ICML) , pages =
Efficient Projections onto the l1-Ball for Learning in High Dimensions , author =. Proceedings of the 25th International Conference on Machine Learning (ICML) , pages =
-
[5]
Edward Y Chang , year =
-
[6]
Beliefs in Motion: Simulating Opinion Dynamics via LLM-Powered Community Reactions
Liu, Xinyi and Sun, Dachun and Hakkani-Tür, Dilek and Abdelzaher , Tarek. Beliefs in Motion: Simulating Opinion Dynamics via LLM-Powered Community Reactions. Social Networks Analysis and Mining. 2026
2026
-
[7]
2026 , eprint =
Opinion dynamics and mutual influence with LLM agents through dialog simulation , author =. 2026 , eprint =
2026
-
[8]
2024 , eprint =
Simulating Opinion Dynamics with Networks of LLM-based Agents , author =. 2024 , eprint =
2024
-
[9]
Forty-first International Conference on Machine Learning , year =
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author =. Forty-first International Conference on Machine Learning , year =
-
[10]
2024 , eprint =
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. 2024 , eprint =
2024
-
[11]
2023 , eprint =
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate , author =. 2023 , eprint =
2023
-
[12]
2024 , eprint =
Debating with More Persuasive LLMs Leads to More Truthful Answers , author =. 2024 , eprint =
2024
-
[13]
Opinion dynamics and bounded confidence: models, analysis and simulation , author =. J. Artif. Soc. Soc. Simul. , year =
-
[14]
Social Influence Networks and Opinion Change , volume =
Friedkin, Noah and Johnsen, Eugene , year =. Social Influence Networks and Opinion Change , volume =
-
[15]
and Murray, Richard , year =
Åström, K.J. and Murray, Richard , year =. Feedback Systems: An Introduction for Scientists and Engineers , journal =
-
[16]
2020 , note =
Disease Symptom Description Dataset , author =. 2020 , note =
2020
-
[17]
Science , volume =
Amos Tversky and Daniel Kahneman , title =. Science , volume =. 1974 , doi =
1974
-
[18]
Jonas Becker , title =
-
[19]
2024 , howpublished =
2024
-
[21]
Achieving Unanimous Consensus Through Multi-Agent Deliberation , year =
Pokharel, Apurba and Dantu, Ram and Zaman, Shakila and Quach, Vinh and Talapuru, Sirisha , booktitle =. Achieving Unanimous Consensus Through Multi-Agent Deliberation , year =
-
[22]
Jonas Becker. 2024. https://arxiv.org/abs/2410.22932 Multi-agent large language models for conversational task-solving . Preprint, arXiv:2410.22932
arXiv 2024
-
[23]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. https://arxiv.org/abs/2308.07201 Chateval: Towards better llm-based evaluators through multi-agent debate . Preprint, arXiv:2308.07201
Pith/arXiv arXiv 2023
-
[24]
Yun-Shiuan Chuang, Agam Goyal, Nikunj Harlalka, Siddharth Suresh, Robert Hawkins, Sijia Yang, Dhavan Shah, Junjie Hu, and Timothy T. Rogers. 2024. https://arxiv.org/abs/2311.09618 Simulating opinion dynamics with networks of llm-based agents . Preprint, arXiv:2311.09618
arXiv 2024
-
[25]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2024. https://openreview.net/forum?id=zj7YuTE4t8 Improving factuality and reasoning in language models through multiagent debate . In Forty-first International Conference on Machine Learning
2024
-
[26]
John Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra. 2008. Efficient projections onto the l1-ball for learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning (ICML), pages 272--279
2008
-
[27]
Noah Friedkin and Eugene Johnsen. 1999. Social influence networks and opinion change. Advances in Group Processes, 16
1999
-
[28]
Aaron Grattafiori and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[29]
Yulong He, Dutao Zhang, Sergey Kovalchuk, Pengyi Li, and Artem Sedakov. 2026. https://arxiv.org/abs/2602.12583 Opinion dynamics and mutual influence with llm agents through dialog simulation . Preprint, arXiv:2602.12583
arXiv 2026
-
[30]
Rainer Hegselmann and Ulrich Krause. 2002. https://api.semanticscholar.org/CorpusID:8130429 Opinion dynamics and bounded confidence: models, analysis and simulation . J. Artif. Soc. Soc. Simul., 5
2002
-
[31]
itachi9604 . 2020. Disease symptom description dataset. Kaggle. https://www.kaggle.com/datasets/itachi9604/disease-symptom-description-dataset . Processed copy: https://drive.google.com/file/d/1sD2codLGO7GhdpY4NesUgp3WiHaX3AK4/view
2020
-
[32]
LangChain . 2024. LangGraph . https://github.com/langchain-ai/langgraph
2024
-
[33]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. https://arxiv.org/abs/2305.19118 Encouraging divergent thinking in large language models through multi-agent debate . Preprint, arXiv:2305.19118
Pith/arXiv arXiv 2024
-
[34]
Xinyi Liu, Dachun Sun, Dilek Hakkani-Tür, and Tarek Abdelzaher. 2026. Beliefs in motion: Simulating opinion dynamics via llm-powered community reactions. In Social Networks Analysis and Mining, pages 299--314, Cham. Springer Nature Switzerland
2026
-
[35]
OpenAI . 2025. gpt-oss-120b and gpt-oss-20b model card. arXiv preprint arXiv:2508.10925
Pith/arXiv arXiv 2025
-
[36]
Apurba Pokharel, Ram Dantu, Shakila Zaman, Vinh Quach, and Sirisha Talapuru. 2025. https://doi.org/10.1109/BRAINS67003.2025.11302940 Achieving unanimous consensus through multi-agent deliberation . In 2025 7th Conference on Blockchain Research & Applications for Innovative Networks and Services (BRAINS), pages 1--6
-
[37]
Proskurnikov and Roberto Tempo
Anton V. Proskurnikov and Roberto Tempo. 2017. https://doi.org/10.1016/j.arcontrol.2017.03.002 A tutorial on modeling and analysis of dynamic social networks. part i . Annual Reviews in Control, 43:65--79
-
[38]
Amos Tversky and Daniel Kahneman. 1974. https://doi.org/10.1126/science.185.4157.1124 Judgment under uncertainty: Heuristics and biases . Science, 185(4157):1124--1131
-
[39]
An Yang and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[40]
Åström and Richard Murray
K.J. Åström and Richard Murray. 2008. Feedback systems: An introduction for scientists and engineers. Feedback Systems: An Introduction for Scientists and Engineers
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.