Toten: A Knowledge-Based System For Structure-Preserving Representation Of Physical Quantities And Technical Notation In Brazilian Portuguese
Pith reviewed 2026-06-26 20:32 UTC · model grok-4.3
The pith
A knowledge-based system using a formal ontology of engineering entities preserves physical quantities and technical notation as whole typed units in Brazilian Portuguese text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
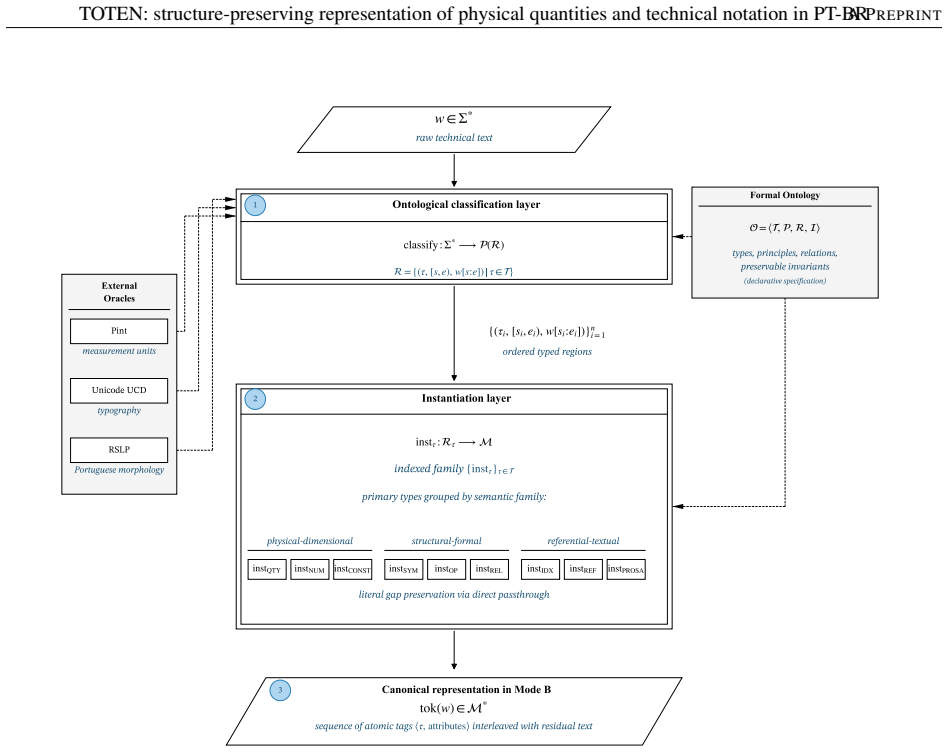
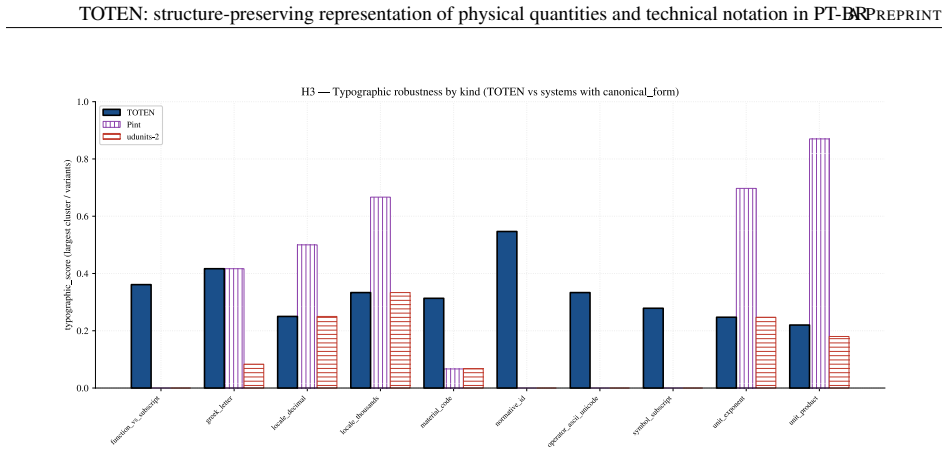
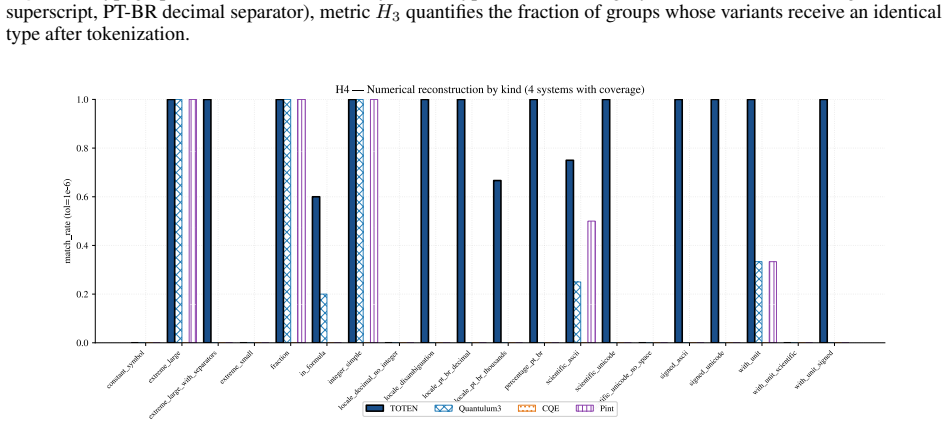
TOTEN reaches unit atomicity across all contrasts through the triple of ontology O, classifier, and instantiators that map raw text into typed regions and produce self-descriptive representations, with deterministic links to Pint for dimensional consistency, the Unicode Character Database for typographic robustness, and RSLP for Portuguese morphology; the resulting input layer supports verifiable atomicity, dimensional equivalence, typographic robustness, and numerical reconstruction.
What carries the argument
The triple <O, classify, {inst_tau}> consisting of the formal ontology of engineering entities, a classifier that maps text to typed regions, and instantiators that yield self-descriptive units, with deterministic coupling to Pint, Unicode Character Database, and RSLP.
If this is right
- Technical text can be prepared for quantitative AI reasoning without loss of entity integrity at the token level.
- The representation remains auditable because every classification step traces to explicit ontology principles and external authorities.
- Dimensional equivalence matches that of Pint while adding language-specific handling for Brazilian Portuguese.
- The input layer operates at low computational cost without requiring generative models.
Where Pith is reading between the lines
- The same ontology-plus-deterministic-coupling pattern could be adapted to technical text in other languages that share similar morphology challenges.
- Downstream models trained on TOTEN output may show reduced error rates on tasks that require accurate quantity manipulation.
- The internal EngQuant benchmark could serve as a reusable control set for comparing future structure-preserving tokenizers.
Load-bearing premise
The formal ontology of engineering entities together with deterministic coupling to Pint, the Unicode Character Database, and RSLP is sufficient to classify and instantiate every relevant technical entity in Brazilian Portuguese technical text without omission or misclassification.
What would settle it
A single technical quantity or symbolic expression appearing in Brazilian Portuguese text that the system either splits across multiple tokens or fails to reconstruct to its original numerical or dimensional form.
Figures
read the original abstract
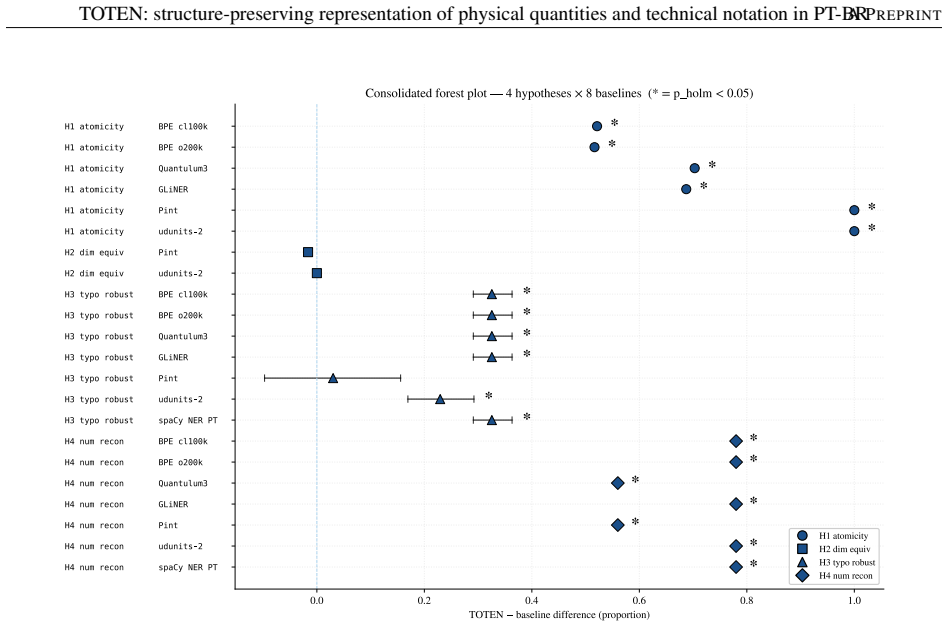
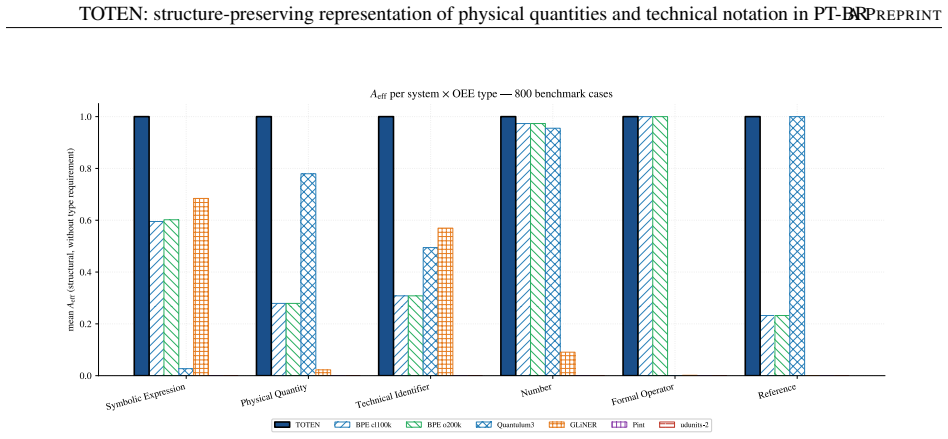
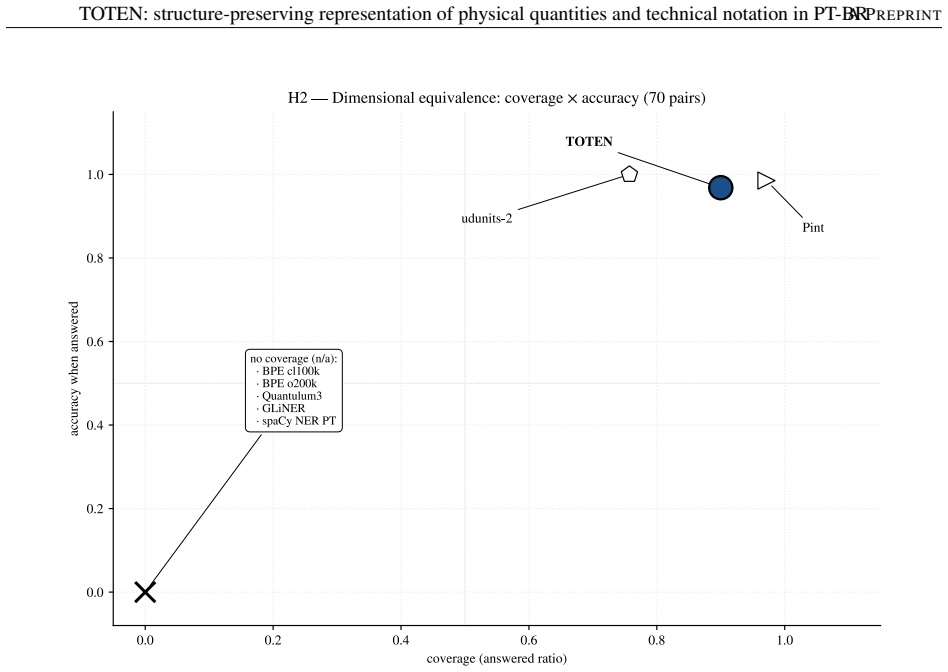
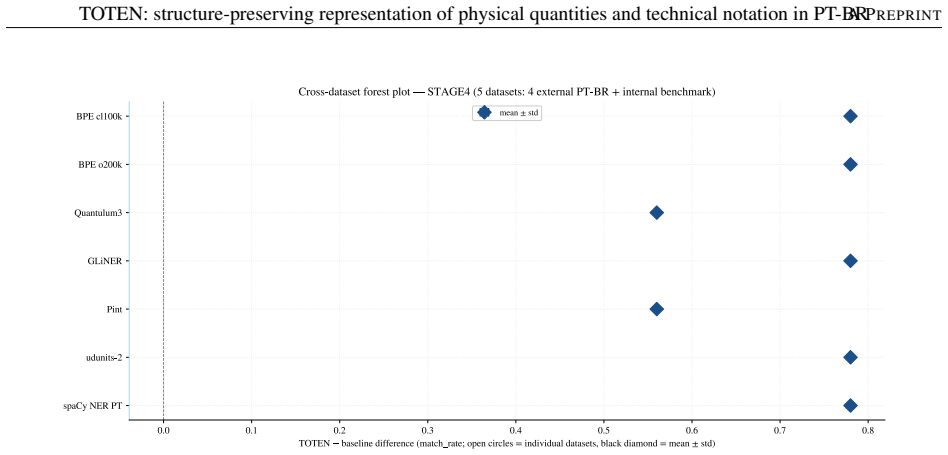
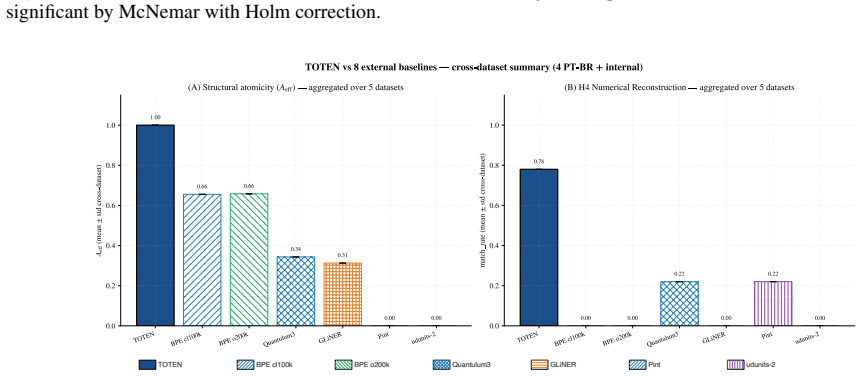
AI pipelines that reason quantitatively over technical text depend on input where physical quantities, numbers, units, and symbolic expressions arrive intact; when these entities fragment at tokenization, errors propagate downstream. Byte-Pair Encoding, optimized for vocabulary compression, is blind to such entities and fragments them into arbitrary subwords -- a problem aggravated in technical Brazilian Portuguese. We present TOTEN, a knowledge-based system whose input representation preserves each technical entity as a whole, typed unit: vocabulary is not derived statistically but classified declaratively under a formal ontology of engineering entities (OEE). The core is the triple <O, classify, {inst_tau}>: types, principles, and invariants; a classifier mapping raw text into typed regions; and instantiators yielding a self-descriptive representation. Integrity rests on deterministic coupling to three external authorities: Pint (dimensional), Unicode Character Database (typographic), and RSLP (Portuguese morphology). We evaluate four properties verifiable by construction -- atomicity, dimensional equivalence, typographic robustness, numerical reconstruction -- on an internal benchmark (EngQuant, N=800) and four Brazilian Portuguese external corpora (N=1771 eligible cases), and report detection recall. Against eight state-of-the-art baselines, TOTEN reaches unit atomicity in all contrasts and reconstruction of 0.775-0.904 externally vs. 0.627-0.703 for the best (Quantulum3); on EngQuant, 0.780 vs. 0.340. Differences are significant (McNemar, Holm-corrected). Spearman correlation between internal and external rankings confirms concurrent validity of the control benchmark. TOTEN shows statistical parity with Pint in dimensional equivalence. The result is a structurally faithful, auditable, low-cost input layer for intelligent systems on technical knowledge, without generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TOTEN, a knowledge-based system for structure-preserving representation of physical quantities and technical notation in Brazilian Portuguese. It relies on a formal ontology of engineering entities (OEE) to declaratively classify raw text into typed regions via the triple <O, classify, {inst_tau}>, with instantiators producing self-descriptive representations. Integrity is ensured by deterministic coupling to Pint (dimensional), Unicode Character Database (typographic), and RSLP (morphological). Four properties verifiable by construction—atomicity, dimensional equivalence, typographic robustness, numerical reconstruction—are evaluated on an internal benchmark (EngQuant, N=800) and four external BP corpora (N=1771 eligible cases). TOTEN achieves unit atomicity in all contrasts and reconstruction rates of 0.775-0.904 externally (vs. 0.627-0.703 for best baseline Quantulum3) and 0.780 vs. 0.340 on EngQuant, with significant differences per McNemar tests (Holm-corrected) and concurrent validity via Spearman correlation between internal/external rankings; it shows statistical parity with Pint on dimensional equivalence.
Significance. If the central claims hold, the work supplies a low-cost, auditable, non-generative input layer for quantitative reasoning over technical text that avoids BPE fragmentation. Credit is due for the deterministic external couplings, properties stated as verifiable by construction, concrete metrics with statistical tests (McNemar, Holm-corrected, Spearman), and explicit comparison to eight baselines. This could matter for AI pipelines in engineering domains where entity integrity is load-bearing.
major comments (2)
- [OEE description and evaluation sections] The central claim requires that the declarative OEE ontology, coupled deterministically to Pint, UCD and RSLP, classifies every relevant technical entity in Brazilian Portuguese technical text without omission or misclassification. The manuscript provides no description of OEE scope, construction method, or argument that the type inventory is closed under possible technical notation (domain-specific symbols, compound units, orthographic variants not captured by RSLP). Empirical results on the chosen corpora therefore do not establish the required universal coverage.
- [Evaluation section] Evaluation section: reconstruction and atomicity metrics are reported with statistical tests, but the manuscript must supply full methodological details, error analysis, and dataset descriptions (including how the N=800 and N=1771 cases were selected and annotated) to verify that the reported gains are attributable to the ontology rather than unstated factors.
minor comments (2)
- [Title and abstract] Title uses 'Toten' while abstract and body use 'TOTEN'; consistent capitalization is needed.
- [Throughout] Ensure first-use definitions for all acronyms (OEE, RSLP, UCD) and clarify any notation for the <O, classify, {inst_tau}> triple.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript describing TOTEN. The comments highlight important areas for clarification regarding the OEE ontology and evaluation methodology. We address each major comment below, indicating revisions where appropriate while maintaining the integrity of our claims about the system's design and empirical results.
read point-by-point responses
-
Referee: [OEE description and evaluation sections] The central claim requires that the declarative OEE ontology, coupled deterministically to Pint, UCD and RSLP, classifies every relevant technical entity in Brazilian Portuguese technical text without omission or misclassification. The manuscript provides no description of OEE scope, construction method, or argument that the type inventory is closed under possible technical notation (domain-specific symbols, compound units, orthographic variants not captured by RSLP). Empirical results on the chosen corpora therefore do not establish the required universal coverage.
Authors: We agree that the manuscript would benefit from expanded description of the OEE. The ontology is introduced via the <O, classify, {inst_tau}> triple with types grounded in engineering entities and coupled to Pint, UCD, and RSLP for deterministic integrity; however, explicit details on construction (e.g., iterative definition from standards like ISO and ABNT) and scope are not fully elaborated. We will add a subsection detailing the OEE development process, type inventory rationale, and how the external authorities handle common variants and compounds in BP technical text. We do not claim or require universal coverage for all conceivable notations, as the system targets practical engineering domains; the reported results establish performance on the evaluated corpora rather than exhaustive closure. A formal completeness proof is outside the paper's scope. revision: partial
-
Referee: [Evaluation section] Evaluation section: reconstruction and atomicity metrics are reported with statistical tests, but the manuscript must supply full methodological details, error analysis, and dataset descriptions (including how the N=800 and N=1771 cases were selected and annotated) to verify that the reported gains are attributable to the ontology rather than unstated factors.
Authors: We concur that additional methodological transparency is warranted. The manuscript already specifies the EngQuant benchmark (N=800), external BP corpora (N=1771 eligible cases), metrics (atomicity, reconstruction, etc.), and statistical procedures (McNemar with Holm correction, Spearman correlation). We will revise the evaluation section to include explicit descriptions of case selection criteria, annotation protocols, inter-annotator agreement if applicable, and a dedicated error analysis breaking down failure modes by category. This will more clearly attribute performance differences to the ontology-driven classification versus baselines. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external couplings and empirical evaluation
full rationale
The paper defines TOTEN via a declarative ontology (OEE) with deterministic, non-fitted coupling to three external authorities (Pint, UCD, RSLP) and reports direct empirical measurements of atomicity, reconstruction, etc., on fixed benchmarks (N=800 internal, N=1771 external) against independent baselines. No equations, parameters, or results are shown to reduce to the inputs by construction; no self-citations are load-bearing; no uniqueness theorems or ansatzes from prior author work are invoked. The central performance claims rest on observable contrasts (McNemar-tested) rather than self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The external authorities (Pint, Unicode Character Database, RSLP) provide complete and accurate classification for all technical entities in Brazilian Portuguese.
invented entities (1)
-
OEE (Ontology of Engineering Entities)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725. Association for Computational Linguistics, 2016. doi:10.18653/v1/P16-1162
-
[2]
Taku Kudo and John Richardson. SentencePiece: a simple and language independent subword tokenizer and detokenizer for neural text processing. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71. Association for Computational Linguistics, 2018. doi:10.18653/v1/D18-2012
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[3]
Singh and DJ Strouse
Aaditya K. Singh and DJ Strouse. Tokenization counts: the impact of tokenization on arithmetic in frontier large language models.Transactions on Machine Learning Research, 2024. Featured Certification
2024
-
[4]
Number cookbook: number understanding of language models and how to improve it
Haotong Yang, Yi Yu, Wei Zhang, et al. Number cookbook: number understanding of language models and how to improve it. InProceedings of the International Conference on Learning Representations (ICLR), pages 1–22, 2025
2025
-
[5]
CQE: a comprehensive quantity extractor
Satya Almasian, Vivian Kazakova, Philipp Göldner, and Michael Gertz. CQE: a comprehensive quantity extractor. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12845–12859. Association for Computational Linguistics, 2023. doi:10.18653/v1/2023.emnlp-main.792. URL https://aclanthology.org/2023.emnlp-main.792
-
[6]
GLiNER: generalist model for named entity recognition using bidirectional transformer
Urchade Zaratiana, Nadi Tomeh, Pierre Holat, and Thierry Charnois. GLiNER: generalist model for named entity recognition using bidirectional transformer. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5364–5376. Association for Computational Linguistic...
-
[7]
Grecco, Jonas L
Hernan E. Grecco, Jonas L. Chase, Lisandro D. Dalcin, et al. Pint: a Python package to define, operate and manipulate physical quantities.GitHub repository, 2022. URLhttps://github.com/hgrecco/pint
2022
-
[8]
Robin K. S. Hankin. The udunits package for dimensional analysis in R.Journal of Statistical Software, 93:1–14,
-
[9]
doi:10.18637/jss.v093.i06
-
[10]
spaCy: industrial-strength natural language processing in Python, 2020
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. spaCy: industrial-strength natural language processing in Python, 2020
2020
-
[11]
Prentice Hall, 2nd edition, 1997
Bertrand Meyer.Object-Oriented Software Construction. Prentice Hall, 2nd edition, 1997. ISBN 978-0-13- 629155-8
1997
-
[12]
Thomas R. Gruber. A translation approach to portable ontology specifications.Knowledge Acquisition, 5(2): 199–220, 1993. doi:10.1006/knac.1993.1008
-
[13]
Richard Benjamins, and Dieter Fensel
Rudi Studer, V . Richard Benjamins, and Dieter Fensel. Knowledge engineering: principles and methods.Data & Knowledge Engineering, 25(1–2):161–197, 1998. doi:10.1016/S0169-023X(97)00056-6
-
[14]
Formal ontology and information systems
Nicola Guarino. Formal ontology and information systems. InProceedings of the First International Conference on Formal Ontology in Information Systems (FOIS ’98), pages 3–15. IOS Press, 1998
1998
-
[15]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Association for Computational Linguistics, 201...
-
[16]
Byte pair encoding is suboptimal for language model pretraining
Kaj Bostrom and Greg Durrett. Byte pair encoding is suboptimal for language model pretraining. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4617–4624. Association for Computational Linguistics, 2020. doi:10.18653/v1/2020.findings-emnlp.414
-
[17]
doi: 10.18653/v1/2021.acl-long.243
Phillip Rust, Jonas Pfeiffer, Ivan Vuli´c, Sebastian Ruder, and Iryna Gurevych. How good is your tokenizer? on the monolingual performance of multilingual language models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Pape...
-
[18]
Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner
Craig W. Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner. Tokenization is more than compression. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 678–702. Association for Computational Linguistics, 2024. doi:10.18653/v1/2024.emnlp-main.40
-
[19]
Aleksandar Petrov, Emanuele La Malfa, Philip H. S. Torr, and Adel Bibi. Language model tokenizers introduce unfairness between languages. InAdvances in Neural Information Processing Systems, volume 36, pages 36963–36990, 2023
2023
-
[20]
Tokenization is sensitive to language variation
Anna Wegmann, Dong Nguyen, and David Jurgens. Tokenization is sensitive to language variation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10958–10983. Association for Computational Linguistics, 2025
2025
-
[21]
Cagri Toraman, Eyup Halit Yilmaz, Furkan ¸ Sahinuç, and Oguzhan Ozcelik. Impact of tokenization on language models: an analysis for Turkish.ACM Transactions on Asian and Low-Resource Language Information Processing, 22(4):116:1–116:21, 2023. doi:10.1145/3578707
-
[22]
doi: 10.18653/v1/2024.emnlp-main.649
Sander Land and Max Bartolo. Fishing for Magikarp: automatically detecting under-trained tokens in large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11631–11646. Association for Computational Linguistics, 2024. doi:10.18653/v1/2024.emnlp-main.649
-
[23]
Representing numbers in NLP: a survey and a vision
Avijit Thawani, Jay Pujara, Filip Ilievski, and Pedro Szekely. Representing numbers in NLP: a survey and a vision. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 644–656. Association for Computational Linguistics, 2021. doi:10.18653/v1/2021.naacl-main.53
-
[24]
Spithourakis and Sebastian Riedel
Georgios P. Spithourakis and Sebastian Riedel. Numeracy for language models: evaluating and improving their ability to predict numbers. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2104–2115. Association for Computational Linguistics, 2018. doi:10.18653/v1/P18-1196
-
[25]
Do NLP models know numbers? Probing numeracy in embeddings
Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, and Matt Gardner. Do NLP models know numbers? Probing numeracy in embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 5307–5315. Association for Computational...
-
[26]
Injecting numerical reasoning skills into language models
Mor Geva, Ankit Gupta, and Jonathan Berant. Injecting numerical reasoning skills into language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 946–958. Association for Computational Linguistics, 2020. doi:10.18653/v1/2020.acl-main.89
-
[27]
Subhro Roy, Tim Vieira, and Dan Roth. Reasoning about quantities in natural language.Transactions of the Association for Computational Linguistics, 3:1–13, 2015. doi:10.1162/tacl_a_00118
-
[28]
Bootstrapping for numerical Open IE
Swarnadeep Saha, Harinder Pal, and Mausam. Bootstrapping for numerical Open IE. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 317–323. Association for Computational Linguistics, 2017. doi:10.18653/v1/P17-2050
-
[29]
Daya C. Wimalasuriya and Dejing Dou. Ontology-based information extraction: an introduction and a survey of current approaches.Journal of Information Science, 36(3):306–323, 2010. doi:10.1177/0165551509360123
-
[30]
Ontology learning for the Semantic Web.IEEE Intelligent Systems, 16(2): 72–79, 2001
Alexander Maedche and Steffen Staab. Ontology learning for the Semantic Web.IEEE Intelligent Systems, 16(2): 72–79, 2001. doi:10.1109/5254.920602
-
[31]
Philipp Cimiano.Ontology Learning and Population from Text: Algorithms, Evaluation and Applications. Springer, New York, NY , 2006. ISBN 978-0-387-30632-2. doi:10.1007/978-0-387-39252-3
-
[32]
Towards a standard upper ontology
Ian Niles and Adam Pease. Towards a standard upper ontology. InProceedings of the 2nd International Conference on Formal Ontology in Information Systems (FOIS ’01), pages 2–9. ACM, 2001. doi:10.1145/505168.505170
-
[33]
Emily M. Bender and Alexander Koller. Climbing towards NLU: on meaning, form, and understanding in the age of data. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5185–5198. Association for Computational Linguistics, 2020. doi:10.18653/v1/2020.acl-main.463
-
[34]
Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. Building machines that learn and think like people.Behavioral and Brain Sciences, 40:e253, 2017. doi:10.1017/S0140525X16001837
-
[35]
Neuro-symbolic approaches in artificial intelligence.National Science Review, 9(6):nwac035, 2022
Pascal Hitzler, Aaron Eberhart, Monireh Ebrahimi, Md Kamruzzaman Sarker, and Lu Zhou. Neuro-symbolic approaches in artificial intelligence.National Science Review, 9(6):nwac035, 2022. doi:10.1093/nsr/nwac035
-
[36]
Kamrul Hasan Sarker and Lu Zhou and Aaron Eberhart and Pascal Hitzler , title =
Md Kamruzzaman Sarker, Lu Zhou, Aaron Eberhart, and Pascal Hitzler. Neuro-symbolic artificial intelligence: current trends.AI Communications, 34(3):197–209, 2021. doi:10.3233/AIC-210084
-
[37]
Andrew Cropper and Sebastijan Dumanˇci´c. Inductive logic programming at 30: a new introduction.Journal of Artificial Intelligence Research, 74:765–850, 2022. doi:10.1613/jair.1.13507
-
[38]
Fábio Souza, Rodrigo Nogueira, and Roberto Lotufo. BERTimbau: pretrained BERT models for Brazilian Portuguese.Lecture Notes in Computer Science, 12319:403–417, 2020. doi:10.1007/978-3-030-61377-8_28
-
[39]
Visão geral da avaliação de similaridade semântica e inferência textual.Linguamática, 8(2):3–13, 2016
Erick Fonseca, Leandro Santos, Marcelo Criscuolo, and Sandra Aluísio. Visão geral da avaliação de similaridade semântica e inferência textual.Linguamática, 8(2):3–13, 2016
2016
-
[40]
The ASSIN 2 shared task: a quick overview
Livy Real, Erick Fonseca, and Hugo Gonçalo Oliveira. The ASSIN 2 shared task: a quick overview. In Computational Processing of the Portuguese Language — 14th International Conference, PROPOR 2020, pages 406–412. Springer, 2020. doi:10.1007/978-3-030-41505-1_39
-
[41]
Pedro H. Luz de Araujo, Teófilo E. de Campos, Renato R. R. de Oliveira, Matheus Stauffer, Samuel Couto, and Paulo Bermejo. LeNER-Br: a dataset for named entity recognition in Brazilian legal text. InComputational Processing of the Portuguese Language — 13th International Conference, PROPOR 2018, pages 313–323. Springer, 2018. doi:10.1007/978-3-319-99722-3_32
-
[42]
BLUEX: a benchmark based on Brazilian leading universities entrance examinations
Thales Sales Almeida, Thiago Laitz, Giovana Kerche Bonas, and Rodrigo Nogueira. BLUEX: a benchmark based on Brazilian leading universities entrance examinations. InIntelligent Systems. BRACIS 2023, volume 14195 of Lecture Notes in Computer Science, pages 337–347. Springer, Cham, 2023. doi:10.1007/978-3-031-45368-7_22
-
[43]
Evaluating GPT-3.5 and GPT-4 models on Brazilian university admission exams, 2023
Desnes Nunes, Ricardo Primi, Ramon Pires, Roberto Lotufo, and Rodrigo Nogueira. Evaluating GPT-3.5 and GPT-4 models on Brazilian university admission exams, 2023
2023
-
[44]
Sabiá: Portuguese large language models
Ramon Pires, Hugo Abonizio, Thales Sales Almeida, and Rodrigo Nogueira. Sabiá: Portuguese large language models. InIntelligent Systems. BRACIS 2023, volume 14197 ofLecture Notes in Computer Science, pages 226–240. Springer, Cham, 2023. doi:10.1007/978-3-031-45392-2_15
-
[45]
BIPM, 9th edition, 2019
Bureau International des Poids et Mesures.The International System of Units (SI). BIPM, 9th edition, 2019
2019
-
[46]
Unicode Consortium, 2024
Unicode Consortium.The Unicode Standard, Version 16.0. Unicode Consortium, 2024
2024
-
[47]
Viviane Moreira Orengo and Christian R. Huyck. A stemming algorithm for the Portuguese language. In Proceedings of the Eighth International Symposium on String Processing and Information Retrieval (SPIRE), pages 186–193. IEEE, 2001. doi:10.1109/SPIRE.2001.989755. 18 TOTEN: structure-preserving representation of physical quantities and technical notation i...
-
[48]
Thomas G. Dietterich. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Computation, 10(7):1895–1923, 1998. doi:10.1162/089976698300017197
-
[49]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.Journal of the American Statistical Association, 22(158):209–212, 1927. doi:10.1080/01621459.1927.10502953
-
[50]
Lawrence Erlbaum Associates, 2nd edition, 1988
Jacob Cohen.Statistical power analysis for the behavioral sciences. Lawrence Erlbaum Associates, 2nd edition, 1988
1988
-
[51]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2): 65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2): 65–70, 1979
1979
-
[52]
Minjie Zhu, Frank McKenna, and Michael H. Scott. OpenSeesPy: Python library for the OpenSees finite element framework.SoftwareX, 7:6–11, 2018. doi:10.1016/j.softx.2017.10.009
-
[53]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InProceedings of the International Conference on Learning Representations (ICLR), pages 1–27, 2021
2021
-
[54]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[55]
Pascal Hitzler, Adila Krisnadhi, and Krzysztof Janowicz. Towards a simple but useful ontology design pattern representation language.Lecture Notes in Computer Science, 11136:2–17, 2018. doi:10.1007/978-3-030-00671- 6_1. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.