RIVET: Robust Idempotent Voice Attribute Editing
Pith reviewed 2026-06-26 18:49 UTC · model grok-4.3
The pith
Enforcing idempotency during training makes voice attribute editing models less sensitive to noisy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that idempotency provides an effective mechanism for improving robustness to noisy labels in conditional generative models for voice attribute editing. An idempotent operator satisfies f(f(x)) = f(x), and enforcing this property during training reduces sensitivity to mislabeled examples, yielding more stable edits that better preserve speaker identity than models trained without the objective.
What carries the argument
The idempotency objective, which enforces that repeated application of the attribute editing function produces no further change.
If this is right
- Models trained with the objective become less sensitive to mislabeled attribute annotations.
- Editing success rates rise compared with standard training under both synthetic and natural noise.
- Speaker identity is preserved more reliably across repeated or noisy edits.
- The same regularizer works on datasets with naturally occurring annotation inconsistencies.
Where Pith is reading between the lines
- The same objective might stabilize other conditional generation tasks that rely on noisy attribute labels.
- Idempotency training could serve as a lightweight alternative to explicit noise modeling or data cleaning pipelines.
- The approach might interact with convergence behavior or hyperparameter choices in ways the current experiments do not measure.
Load-bearing premise
An idempotency objective can be added to the training of conditional generative models for voice editing without degrading performance on clean data or introducing optimization instabilities.
What would settle it
A controlled experiment showing that models trained with the idempotency objective achieve no higher editing success or speaker similarity than standard models when both are tested on datasets containing verified label noise would falsify the central claim.
Figures

read the original abstract
Voice attribute editing models modify characteristics such as age and gender while preserving speaker identity. In large-scale speech datasets, however, attribute annotations are often noisy or inconsistent, which can cause conditional generative models to produce unstable edits. In this work, we show that idempotency provides an effective mechanism for improving robustness to noisy labels. An idempotent operator is one for which repeated application does not change the result, i.e., f(f(x)) = f(x). Enforcing this property acts as an implicit regularizer that reduces sensitivity to mislabeled examples. We introduce RIVET, a training framework that incorporates an idempotency objective to improve robustness to label noise. We evaluate RIVET under controlled label noise and on the GLOBE dataset with naturally noisy annotations. RIVET improves editing success and better preserves speaker identity than standard training, showing that idempotency improves robustness in voice editing models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RIVET, a training framework for conditional generative models in voice attribute editing that adds an idempotency objective (f(f(x)) = f(x)) to improve robustness to noisy or inconsistent attribute labels. It claims this acts as an implicit regularizer, yielding higher editing success and better speaker identity preservation than standard training, with evaluations under controlled label noise and on the naturally noisy GLOBE dataset.
Significance. If substantiated with quantitative evidence, the result would demonstrate a lightweight consistency-regularization technique applicable to label-noise issues common in large-scale speech datasets. The approach builds on standard ideas from consistency regularization but applies them specifically to idempotent operators in voice editing, which could extend to other conditional generation tasks.
major comments (1)
- [Abstract] Abstract: the claim that 'RIVET improves editing success and better preserves speaker identity than standard training' is asserted without any reported metrics, baselines, statistical tests, or experimental protocol. This absence is load-bearing for the central contribution, as the soundness of the performance gains cannot be assessed from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the central claims require clearer quantitative grounding even in the abstract and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'RIVET improves editing success and better preserves speaker identity than standard training' is asserted without any reported metrics, baselines, statistical tests, or experimental protocol. This absence is load-bearing for the central contribution, as the soundness of the performance gains cannot be assessed from the given text.
Authors: We agree that the abstract should include concrete quantitative support for the performance claims. In the revised version we will add a sentence reporting the key improvements (e.g., absolute gains in editing success rate and speaker similarity on GLOBE) together with a brief reference to the evaluation setting. The full experimental protocol, baselines, and statistical details remain in Section 4; the abstract revision will simply make the headline result verifiable at a glance. revision: yes
Circularity Check
No significant circularity; idempotency objective is an independent training term
full rationale
The paper introduces an idempotency objective f(f(x)) = f(x) as an additional loss term for training conditional generative models on noisy voice attribute labels. This is presented as a standard consistency regularization technique applied to the editing task, with evaluation on controlled noise and the GLOBE dataset showing empirical gains in editing success and speaker preservation. No derivation reduces a claimed prediction or uniqueness result back to fitted parameters or self-citations; the central claim rests on the external definition of idempotency and standard training dynamics rather than any self-referential construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recent generative models have made significant progress in enabling controllable speech editing through conditional synthesis and disentangled representations [1, 2, 3]
Introduction V oice attribute editing aims to modify specific characteristics of a speech signal, such as age, gender, or accent, while pre- serving the speaker’s underlying identity. Recent generative models have made significant progress in enabling controllable speech editing through conditional synthesis and disentangled representations [1, 2, 3]. In ...
-
[2]
Our ex- periments focus on two attributes, age and gender
with controlled levels of synthetic label noise. Our ex- periments focus on two attributes, age and gender. The results show that RIVET improves editing success rates compared to strong baselines while preserving speaker identity. Although our evaluation focuses on these two attributes, the principle of enforcing idempotency is model-agnostic and can be a...
Pith/arXiv arXiv 2026
-
[3]
V oice Editing V oice editing aims to modify attributes of a speech signal, such as age, gender, or accent, while preserving speaker identity and linguistic content [1, 2, 15]
Related Work 2.1. V oice Editing V oice editing aims to modify attributes of a speech signal, such as age, gender, or accent, while preserving speaker identity and linguistic content [1, 2, 15]. A common approach is to learn representations that separate factors of variation so that one at- tribute can be modified without affecting others. Prior work en- ...
-
[4]
Other approaches enforce idempotency through al- gorithmic updates that progressively move a model toward an idempotent operator during training [11]
and using idempotency as a general optimization objec- tive for test-time adaptation in place of auxiliary self-supervised tasks [10]. Other approaches enforce idempotency through al- gorithmic updates that progressively move a model toward an idempotent operator during training [11]. Most existing work focuses on image generation and assumes clean superv...
-
[5]
Idempotent Training LetF(·)denote the overall editing model
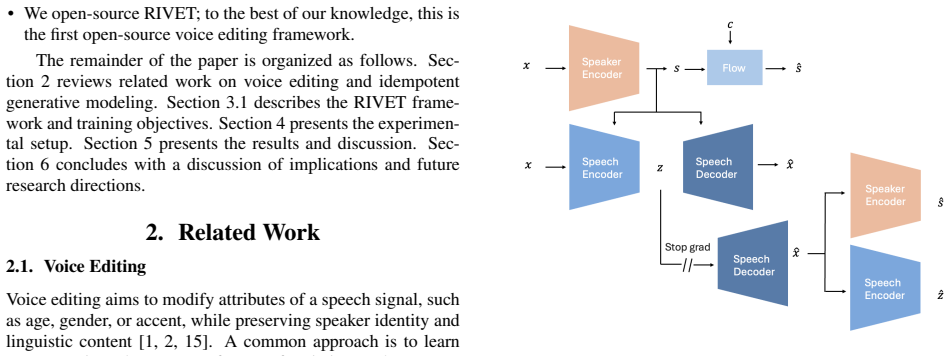
Method 3.1. Idempotent Training LetF(·)denote the overall editing model. The model first en- codes the input speech signalxusing an encoderE(·)and then reconstructs or edits the speech using a decoderD(·): F(x) =D(E(x)).(1) An operatorFis calledidempotentif repeated application does not change the result: F(F(x)) =F(x).(2) Substituting the encoder–decoder...
-
[6]
The baseline includes the ECAPA-TDNN speaker encoder, the conditional invertible flow, and the VITS generative backbone, trained jointly using the same objectives
Experimental Setup To evaluate the effect of idempotent training, we compare RIVET against a baseline model with identical architecture and training configuration, but without the idempotency constraint. The baseline includes the ECAPA-TDNN speaker encoder, the conditional invertible flow, and the VITS generative backbone, trained jointly using the same o...
1910
-
[7]
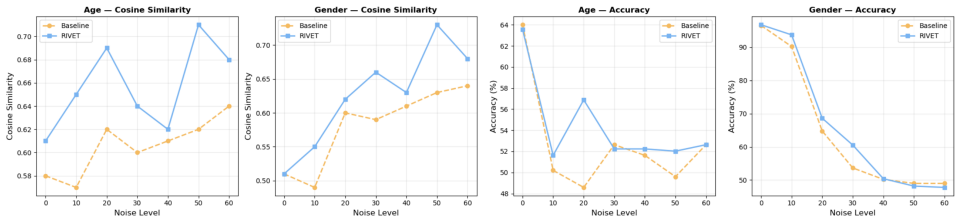
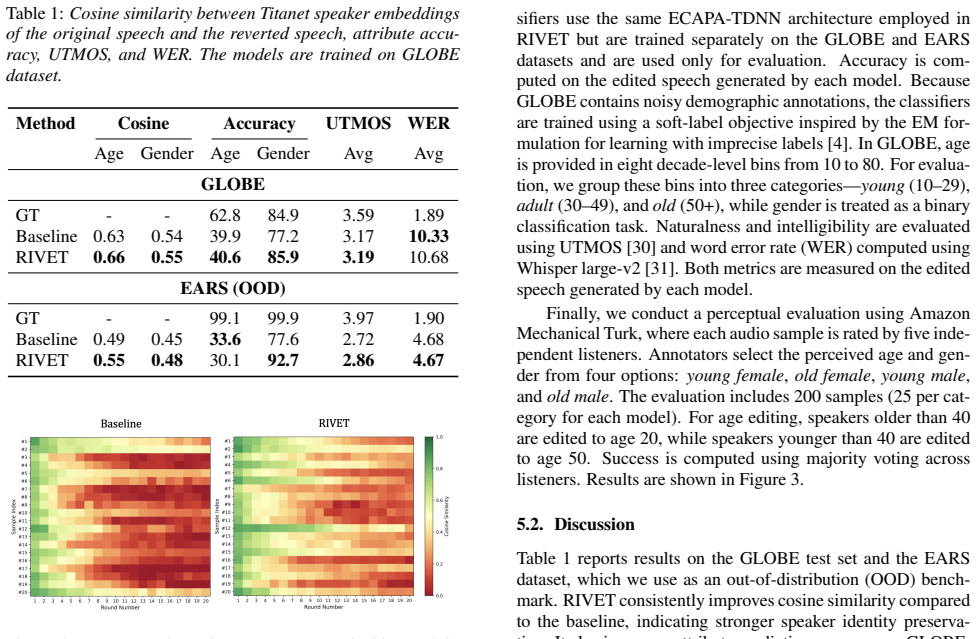
Results and Discussion 5.1. Evaluation Metrics We measure speaker identity preservation using cosine similar- ity between Titanet speaker embeddings [29] extracted from the original speech and the reverted speech. The reverted speech is obtained by first editing an attribute (e.g., age or gender) and then reversing the edit back to its original value. Thi...
-
[8]
We introduced RIVET, an end-to- end training framework that incorporates an idempotency con- straint into the latent representations of a conditional voice edit- ing model
Conclusion In this work, we studied how idempotency can improve ro- bustness in attribute-conditioned voice editing when training data contains noisy labels. We introduced RIVET, an end-to- end training framework that incorporates an idempotency con- straint into the latent representations of a conditional voice edit- ing model. Experiments on the GLOBE a...
-
[9]
All scientific content, including ideas, methods, experimental design, analysis, and results, was developed and verified by the authors
Generative AI Use Disclosure Large language model (LLM) tools were used to assist with proofreading and improving the clarity and fluency of the manuscript. All scientific content, including ideas, methods, experimental design, analysis, and results, was developed and verified by the authors. No generative AI tool is listed as a co- author, and the author...
-
[10]
V oiceshop: A unified speech-to-speech framework for identity-preserving zero-shot voice editing,
P. Anastassiou, Z. Tang, K. Peng, D. Jia, J. Li, M. Tu, Y . Wang, Y . Wang, and M. Ma, “V oiceshop: A unified speech-to-speech framework for identity-preserving zero-shot voice editing,”arXiv preprint arXiv:2404.06674, 2024
arXiv 2024
-
[11]
V oice at- tribute editing with text prompt,
Z.-Y . Sheng, L.-J. Liu, Y . Ai, J. Pan, and Z.-H. Ling, “V oice at- tribute editing with text prompt,”IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[12]
Flashspeech: Efficient zero-shot speech synthesis,
Z. Ye, Z. Ju, H. Liu, X. Tan, J. Chen, Y . Lu, P. Sun, J. Pan, W. Bian, S. Heet al., “Flashspeech: Efficient zero-shot speech synthesis,” inProceedings of the 32nd ACM International Con- ference on Multimedia, 2024, pp. 6998–7007
2024
-
[13]
Imprecise label learning: A unified framework for learning with various imprecise label con- figurations,
H. Chen, A. Shah, J. Wang, R. Tao, Y . Wang, X. Li, X. Xie, M. Sugiyama, R. Singh, and B. Raj, “Imprecise label learning: A unified framework for learning with various imprecise label con- figurations,”Advances in Neural Information Processing Systems, vol. 37, pp. 59 621–59 654, 2024
2024
-
[14]
W. Wang, Y . Song, and S. Jha, “Globe: A high-quality english corpus with global accents for zero-shot speaker adaptive text-to- speech,”arXiv preprint arXiv:2406.14875, 2024
arXiv 2024
-
[15]
Classification in the presence of label noise: a survey,
B. Fr ´enay and M. Verleysen, “Classification in the presence of label noise: a survey,”IEEE transactions on neural networks and learning systems, vol. 25, no. 5, pp. 845–869, 2013
2013
-
[16]
Guiding noisy la- bel conditional diffusion models with score-based discriminator correction,
D. N. Cong, H. T. Bao, and T. Hoang-Thanh, “Guiding noisy la- bel conditional diffusion models with score-based discriminator correction,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision, 2025, pp. 18 531–18 541
2025
-
[17]
Label-noise robust diffusion models,
B. Na, Y . Kim, H. Bae, J. H. Lee, S. J. Kwon, W. Kang, and I.- C. Moon, “Label-noise robust diffusion models,”arXiv preprint arXiv:2402.17517, 2024
arXiv 2024
-
[18]
Idempotent generative network,
A. Shocher, A. Dravid, Y . Gandelsman, I. Mosseri, M. Rubinstein, and A. A. Efros, “Idempotent generative network,”arXiv preprint arXiv:2311.01462, 2023
arXiv 2023
-
[19]
It 3: Idempotent test-time training,
N. Durasov, A. Shocher, D. Oner, G. Chechik, A. A. Efros, and P. Fua, “It 3: Idempotent test-time training,”arXiv preprint arXiv:2410.04201, 2024
arXiv 2024
-
[20]
Enforcing idempotency in neural networks,
N. B. Jensen and J. Vicary, “Enforcing idempotency in neural networks,” inForty-second International Conference on Machine Learning, 2025
2025
-
[21]
Score-based idempotent distilla- tion of diffusion models,
S. Zaman, C. Liu, and K. Chiu, “Score-based idempotent distilla- tion of diffusion models,”arXiv preprint arXiv:2509.21470, 2025
arXiv 2025
-
[22]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 32 211–32 252
2023
-
[23]
EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and derever- beration,
J. Richter, Y .-C. Wu, S. Krenn, S. Welker, B. Lay, S. Watan- abe, A. Richard, and T. Gerkmann, “EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and derever- beration,” inISCA Interspeech, 2024, pp. 4873–4877
2024
-
[24]
V oxgene- sis: Unsupervised discovery of latent speaker manifold for speech synthesis,
W. Lin, C. He, M.-W. Mak, J. Lian, and K. A. Lee, “V oxgene- sis: Unsupervised discovery of latent speaker manifold for speech synthesis,”arXiv preprint arXiv:2403.00529, 2024
arXiv 2024
-
[25]
Understanding disentangling inβ-vae,
C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Des- jardins, and A. Lerchner, “Understanding disentangling inβ-vae,” arXiv preprint arXiv:1804.03599, 2018
Pith/arXiv arXiv 2018
-
[26]
Semantic unfolding of stylegan latent space,
M. Shukor, X. Yao, B. B. Damodaran, and P. Hellier, “Semantic unfolding of stylegan latent space,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 221– 225
2022
-
[27]
Disenbooth: Identity-preserving disentangled tun- ing for subject-driven text-to-image generation,
H. Chen, Y . Zhang, S. Wu, X. Wang, X. Duan, Y . Zhou, and W. Zhu, “Disenbooth: Identity-preserving disentangled tun- ing for subject-driven text-to-image generation,”arXiv preprint arXiv:2305.03374, 2023
arXiv 2023
-
[28]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty- first international conference on machine learning, 2024
2024
-
[29]
Semantic image inversion and editing us- ing rectified stochastic differential equations,
L. Rout, Y . Chen, N. Ruiz, C. Caramanis, S. Shakkottai, and W.-S. Chu, “Semantic image inversion and editing us- ing rectified stochastic differential equations,”arXiv preprint arXiv:2410.10792, 2024
arXiv 2024
-
[30]
Don’t drop your samples! coherence-aware training benefits conditional dif- fusion,
N. Dufour, V . Besnier, V . Kalogeiton, and D. Picard, “Don’t drop your samples! coherence-aware training benefits conditional dif- fusion,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 6264–6273
2024
-
[31]
Label-noise robust gen- erative adversarial networks,
T. Kaneko, Y . Ushiku, and T. Harada, “Label-noise robust gen- erative adversarial networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 2467–2476
2019
-
[32]
Consistency regulariza- tion can improve robustness to label noise,
E. Englesson and H. Azizpour, “Consistency regulariza- tion can improve robustness to label noise,”arXiv preprint arXiv:2110.01242, 2021
arXiv 2021
-
[33]
Class-dependent label-noise learning with cycle- consistency regularization,
D. Cheng, Y . Ning, N. Wang, X. Gao, H. Yang, Y . Du, B. Han, and T. Liu, “Class-dependent label-noise learning with cycle- consistency regularization,”Advances in Neural Information Pro- cessing Systems, vol. 35, pp. 11 104–11 116, 2022
2022
-
[34]
Learning with neighbor consistency for noisy labels. 2022 ieee,
A. Iscen, J. Valmadre, A. Arnab, and C. Schmid, “Learning with neighbor consistency for noisy labels. 2022 ieee,” inCVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4662–4671
2022
-
[35]
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa- tdnn: Emphasized channel attention, propagation and ag- gregation in tdnn based speaker verification,”arXiv preprint arXiv:2005.07143, 2020
arXiv 2005
-
[36]
Flow++: Improving flow-based generative models with variational dequan- tization and architecture design,
J. Ho, X. Chen, A. Srinivas, Y . Duan, and P. Abbeel, “Flow++: Improving flow-based generative models with variational dequan- tization and architecture design,” inInternational conference on machine learning. PMLR, 2019, pp. 2722–2730
2019
-
[37]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inInter- national Conference on Machine Learning. PMLR, 2021, pp. 5530–5540
2021
-
[38]
Titanet: Neural model for speaker representation with 1d depth-wise separable convo- lutions and global context,
N. R. Koluguri, T. Park, and B. Ginsburg, “Titanet: Neural model for speaker representation with 1d depth-wise separable convo- lutions and global context,” inICASSP 2022-2022 IEEE inter- national conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 8102–8106
2022
-
[39]
Utmos: Utokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,”arXiv preprint arXiv:2204.02152, 2022
arXiv 2022
-
[40]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.