DF-ExpEnse: Diffusion Filtered Exploration for Sample Efficient Finetuning
Pith reviewed 2026-06-26 20:17 UTC · model grok-4.3
The pith
DF-ExpEnse filters diffusion policy candidates with critic ensembles to raise sample efficiency when finetuning robotic controllers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
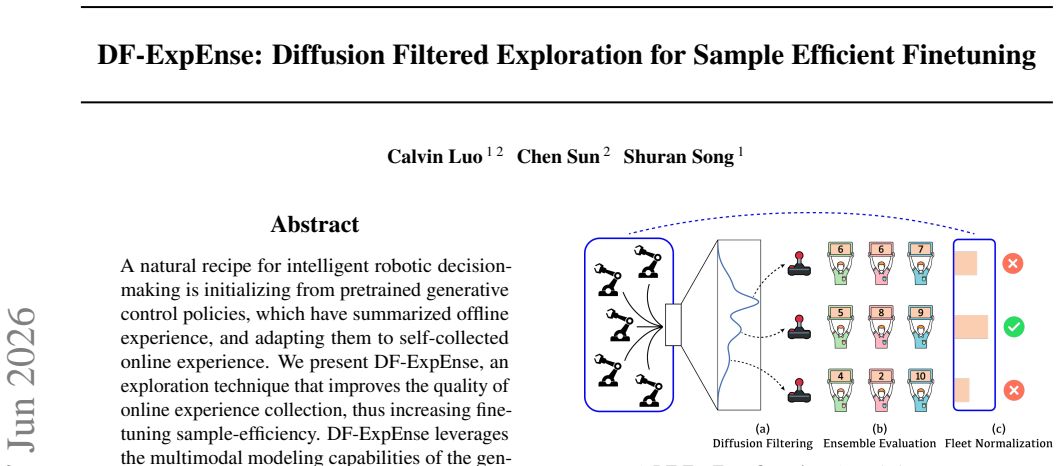
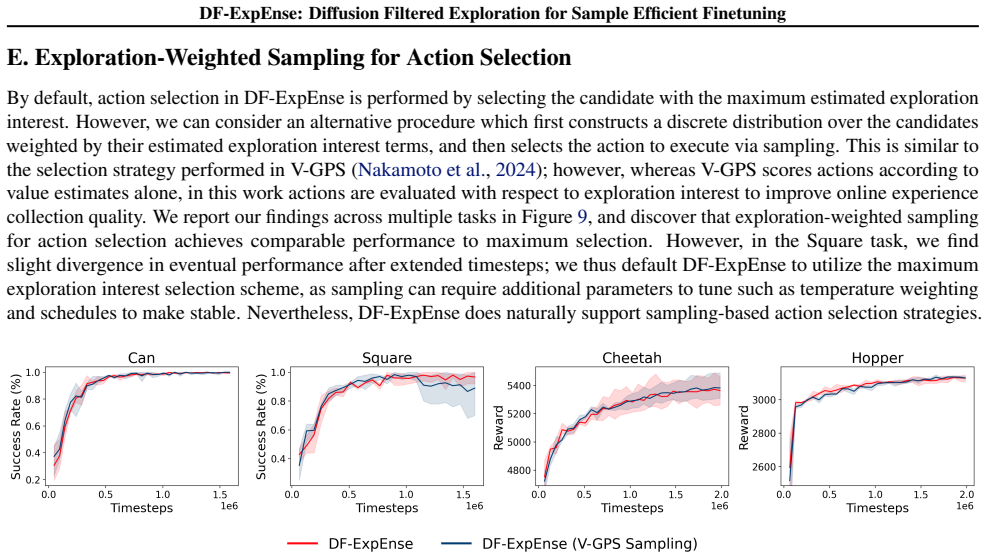
DF-ExpEnse leverages the multimodal modeling capabilities of the generative control policy to create an expressive and tractably evaluatable candidate set. It then utilizes an ensemble of critics to identify the action that best balances quality with high exploration interest. In fleet settings, DF-ExpEnse further enables cross-agent communication to facilitate collaborative exploration as a group. The approach can be seamlessly integrated with existing strategies that finetune pretrained generative control policies via reinforcement learning.
What carries the argument
Diffusion-generated candidate set filtered by an ensemble of critics that scores each action for quality versus exploration interest.
If this is right
- Finetuning loops that use DF-ExpEnse collect higher-quality online experience than default random or greedy selection.
- The same procedure applies without modification to both manipulation and locomotion domains.
- In multi-robot fleets the method enables explicit sharing of selected actions across agents.
- DF-ExpEnse slots directly into existing reinforcement-learning finetuning pipelines for generative policies.
Where Pith is reading between the lines
- The technique may lower the engineering effort needed to design task-specific exploration bonuses.
- Similar candidate-filtering logic could be tested on other generative policy architectures beyond diffusion models.
- If the critic ensemble generalizes across environments, it could reduce reliance on per-task hyperparameter search for exploration.
Load-bearing premise
An ensemble of critics can reliably pick actions that balance quality and exploration interest from the diffusion candidates without extra environment-specific tuning.
What would settle it
A controlled comparison in which DF-ExpEnse produces no measurable reduction in the number of environment steps needed to reach a target performance level on standard manipulation or locomotion benchmarks would falsify the central efficiency claim.
Figures
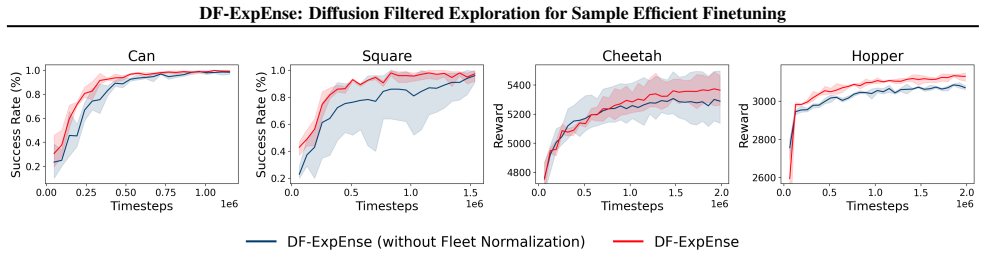
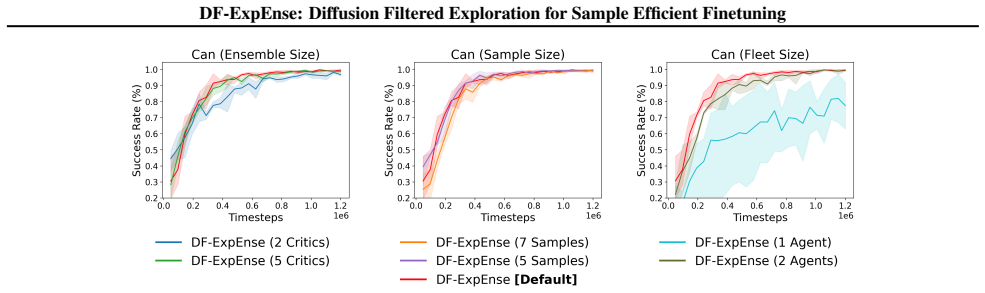
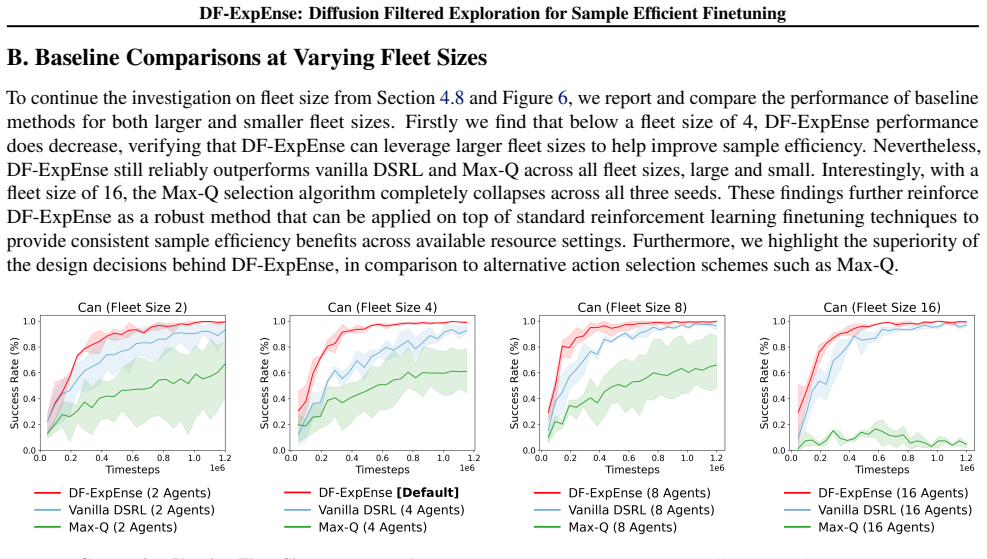
read the original abstract
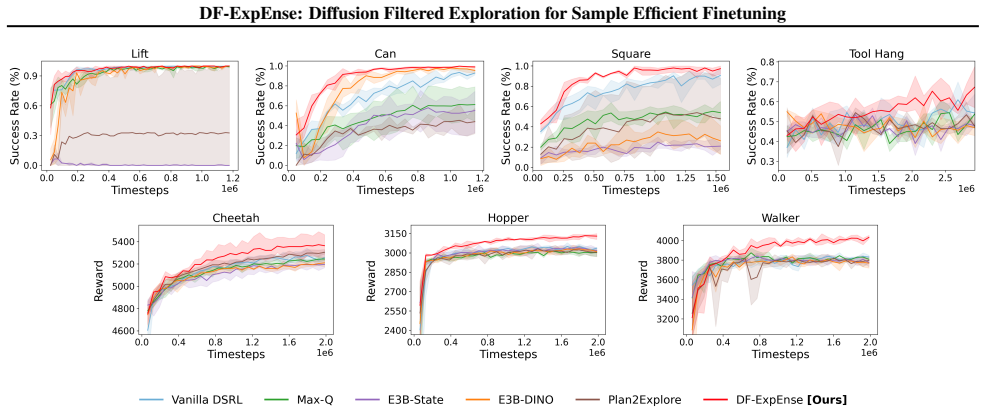
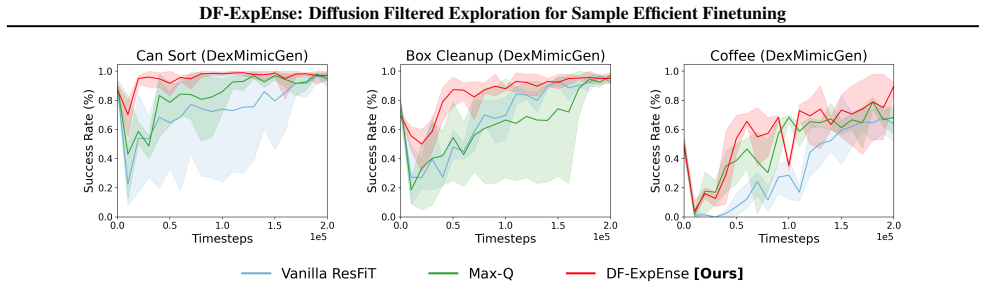
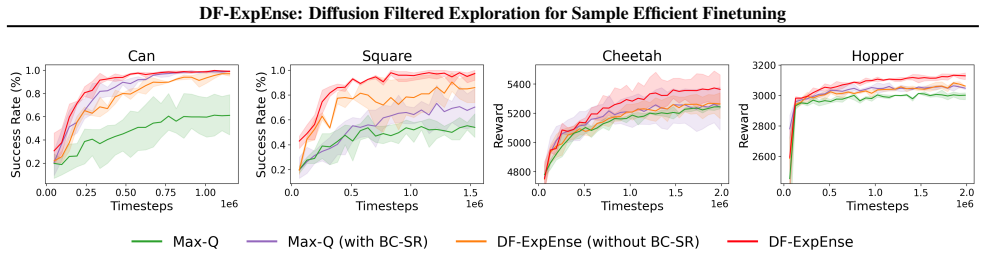
A natural recipe for intelligent robotic decision-making is initializing from pretrained generative control policies, which have summarized offline experience, and adapting them to self-collected online experience. We present DF-ExpEnse, an exploration technique that improves the quality of online experience collection, thus increasing finetuning sample-efficiency. DF-ExpEnse leverages the multimodal modeling capabilities of the generative control policy to create an expressive and tractably evaluatable candidate set. It then utilizes an ensemble of critics to identify the action that best balances quality with high exploration interest. In fleet settings, DF-ExpEnse further enables cross-agent communication to facilitate collaborative exploration as a group. DF-ExpEnse can be seamlessly integrated with existing strategies that finetune pretrained generative control policies via reinforcement learning. We experimentally validate consistent sample-efficiency benefits through DF-ExpEnse across a variety of manipulation and locomotion tasks, compared to default finetuning and alternative action selection schemes. Project can be found at https://df-expense.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DF-ExpEnse, an exploration method for finetuning pretrained generative (diffusion) control policies in robotics. Candidate actions are generated from the diffusion policy; an ensemble of critics then selects the action balancing predicted quality against exploration interest. The approach also supports cross-agent communication for collaborative exploration in fleet settings and is designed to integrate with existing RL finetuning pipelines. Experiments on manipulation and locomotion tasks are reported to show consistent sample-efficiency gains relative to default finetuning and alternative action-selection baselines.
Significance. If the empirical gains are robust, the work offers a practical way to improve online data quality when adapting offline-trained diffusion policies, a setting of growing importance in robotic RL. The combination of multimodal candidate generation with uncertainty-aware selection and the fleet extension are straightforward but potentially useful engineering contributions.
minor comments (3)
- The abstract states that DF-ExpEnse 'can be seamlessly integrated' with existing RL finetuning strategies, but no concrete integration details, pseudocode, or hyper-parameter settings are visible in the provided text.
- No quantitative results (e.g., success rates, sample counts, statistical tests, or error bars) appear in the abstract; the claim of 'consistent sample-efficiency benefits' therefore cannot be evaluated from the supplied material.
- The project URL is given, yet the manuscript text does not indicate whether code, trained models, or environment configurations will be released.
Simulated Author's Rebuttal
We thank the referee for their review and for accurately summarizing the DF-ExpEnse method, its integration with RL finetuning pipelines, and the reported sample-efficiency gains on manipulation and locomotion tasks. The significance assessment is appreciated. No specific major comments were enumerated in the report, so we have no point-by-point responses to provide at this stage. We remain available to supply further experimental details or clarifications should the editor or referee request them.
Circularity Check
No significant circularity; method is algorithmic combination without self-referential derivation
full rationale
The paper describes DF-ExpEnse as a technique that generates action candidates from a pretrained diffusion policy and selects via critic ensemble for quality-exploration balance, with optional fleet communication. No equations, derivations, or parameter-fitting steps are referenced in the provided abstract or description that would reduce any prediction or result to its own inputs by construction. The central claim is an empirical improvement in sample efficiency, supported by experiments rather than any internal mathematical chain. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing elements. This is a standard self-contained algorithmic proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
G., Chua, A., Nemade, M., Thattai, C., et al
Agaskar, A., Siva, S., Pickering, W., O’Brien, K., Kekeh, C., Li, A., Sarker, B. G., Chua, A., Nemade, M., Thattai, C., et al. Deepfleet: Multi-agent foundation models for mobile robots.arXiv preprint arXiv:2508.08574,
-
[2]
Ankile, L., Jiang, Z., Duan, R., Shi, G., Abbeel, P., and Nagabandi, A. Residual off-policy rl for finetuning be- havior cloning policies.arXiv preprint arXiv:2509.19301, 2025a. Ankile, L., Simeonov, A., Shenfeld, I., Torne, M., and Agrawal, P. From imitation to refinement-residual rl for precise assembly. In2025 IEEE International Conference on Robotics ...
-
[3]
π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[4]
Y ., Sidor, S., Abbeel, P., and Schulman, J
Chen, R. Y ., Sidor, S., Abbeel, P., and Schulman, J. Ucb exploration via q-ensembles.arXiv preprint arXiv:1706.01502,
-
[5]
Goecks, V . G., Gremillion, G. M., Lawhern, V . J., Valasek, J., and Waytowich, N. R. Integrating behavior cloning and reinforcement learning for improved performance in dense and sparse reward environments.arXiv preprint arXiv:1910.04281,
arXiv 1910
-
[6]
G., Xiao, T., Kappler, D., et al
Herzog, A., Rao, K., Hausman, K., Lu, Y ., Wohlhart, P., Yan, M., Lin, J., Arenas, M. G., Xiao, T., Kappler, D., et al. Deep rl at scale: Sorting waste in office build- ings with a fleet of mobile manipulators.arXiv preprint arXiv:2305.03270,
-
[7]
Kalashnikov, D., Varley, J., Chebotar, Y ., Swanson, B., Jonschkowski, R., Finn, C., Levine, S., and Hausman, K. Mt-opt: Continuous multi-task robotic reinforcement learning at scale.arXiv preprint arXiv:2104.08212,
-
[8]
URL https://openreview.net/forum? id=XUks1Y96NR. Makoviychuk, V ., Wawrzyniak, L., Guo, Y ., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
-
[9]
Awac: Accel- erating online reinforcement learning with offline datasets
Nair, A., Gupta, A., Dalal, M., and Levine, S. Awac: Accel- erating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359,
Pith/arXiv arXiv 2006
-
[10]
Nakamoto, M., Mees, O., Kumar, A., and Levine, S. Steer- ing your generalists: Improving robotic foundation mod- els via value guidance.arXiv preprint arXiv:2410.13816,
-
[11]
cc/paper_files/paper/1988/file/ 812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper
URL https://proceedings.neurips. cc/paper_files/paper/1988/file/ 812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper. pdf. Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus, M., and Dormann, N. Stable-baselines3: Reliable rein- forcement learning implementations.Journal of Machine Learning Research, 22(268):1–8,
1988
-
[12]
URL http: //jmlr.org/papers/v22/20-1364.html. Ren, A. Z., Lidard, J., Ankile, L. L., Simeonov, A., Agrawal, P., Majumdar, A., Burchfiel, B., Dai, H., and Simchowitz, M. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588,
-
[13]
Waymo public road safety performance data.arXiv preprint arXiv:2011.00038,
Schwall, M., Daniel, T., Victor, T., Favaro, F., and Hohnhold, H. Waymo public road safety performance data.arXiv preprint arXiv:2011.00038,
arXiv 2011
-
[14]
Resid- ual policy learning.arXiv preprint arXiv:1812.06298,
Silver, T., Allen, K., Tenenbaum, J., and Kaelbling, L. Resid- ual policy learning.arXiv preprint arXiv:1812.06298,
-
[15]
Sapg: Split and aggregate policy gradients
Singla, J., Agarwal, A., and Pathak, D. Sapg: Split and aggregate policy gradients. InProceedings of the 41st International Conference on Machine Learning (ICML 2024), Proceedings of Machine Learning Research, Vi- enna, Austria, July
2024
-
[16]
URL https://openreview. net/forum?id=IL71c1z7et. Zhao, Y ., Boney, R., Ilin, A., Kannala, J., and Pajarinen, J. Adaptive behavior cloning regularization for stable offline-to-online reinforcement learning.arXiv preprint arXiv:2210.13846,
-
[17]
When DF-ExpEnse is applied on top of DSRL as the underlying reinforcement learning algorithm of choice, it is only utilized during the online experience collection step. As such, many of the optimization hyperparameters of DSRL are untouched, to maintain base performance and attribute any performance improvements directly to the quality of experience coll...
2048
-
[18]
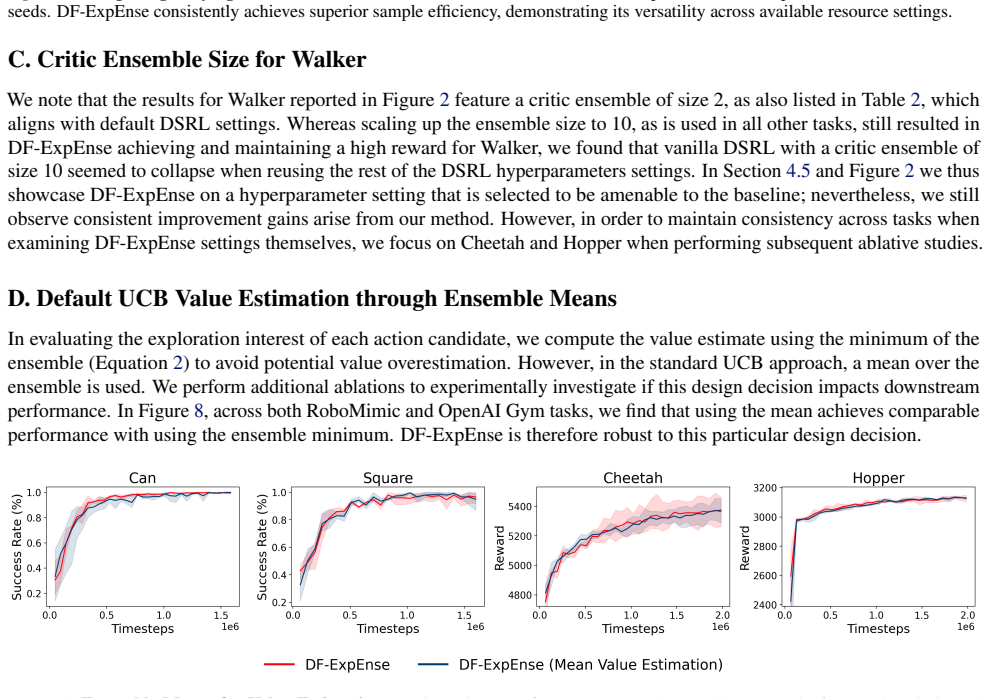
However, in the standard UCB approach, a mean over the ensemble is used
to avoid potential value overestimation. However, in the standard UCB approach, a mean over the ensemble is used. We perform additional ablations to experimentally investigate if this design decision impacts downstream performance. In Figure 8, across both RoboMimic and OpenAI Gym tasks, we find that using the mean achieves comparable performance with usi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.