Library-Aware Doubles and Iterative Repair for Large Language Model-Generated Unit Tests in OpenSIL Firmware
Pith reviewed 2026-06-26 17:03 UTC · model grok-4.3
The pith
LLM multi-agent workflow with iterative repair produces compilable unit tests for 73 of 76 OpenSIL firmware functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
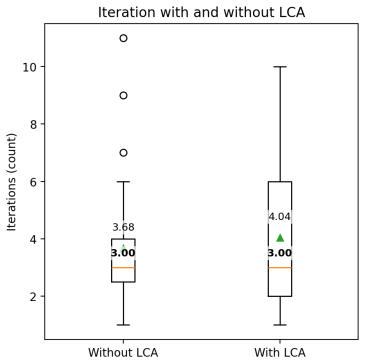
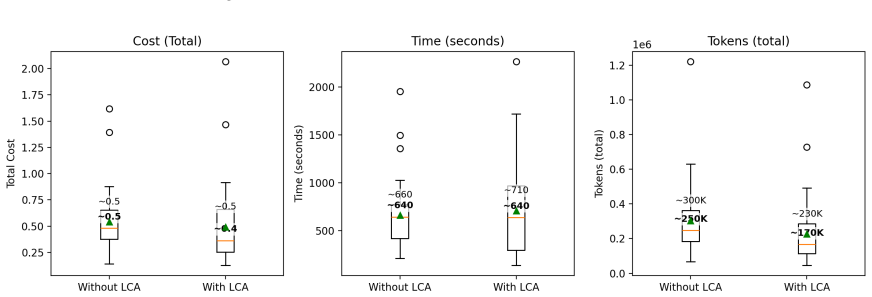
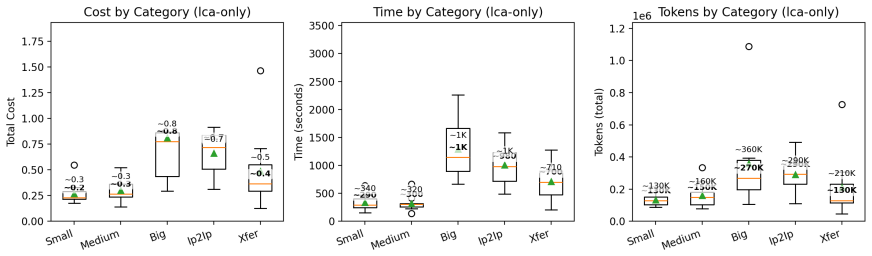
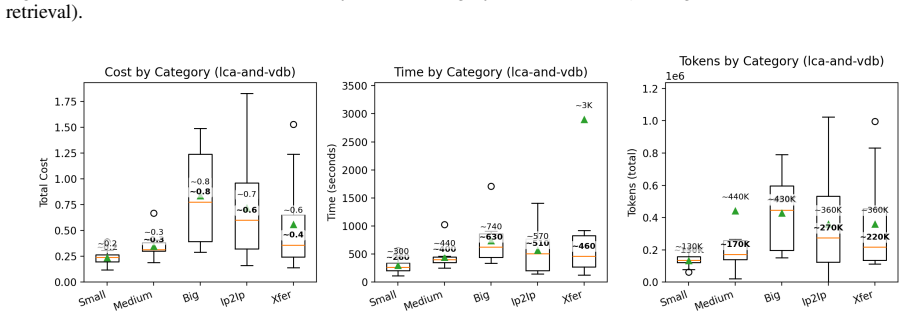
The study shows that an LLM-guided multi-agent pipeline can generate unit test scaffolds, apply library-aware doubles, and iteratively repair them via build logs and coverage feedback until the tests compile and achieve high line coverage. On 76 OpenSIL functions the pipeline produced compilable tests for 73. Without line coverage guidance mean coverage was 73.9 percent; with guidance alone on a 48-function subset it reached 98.8 percent, and 94.7 percent when combined with retrieval augmentation.
What carries the argument
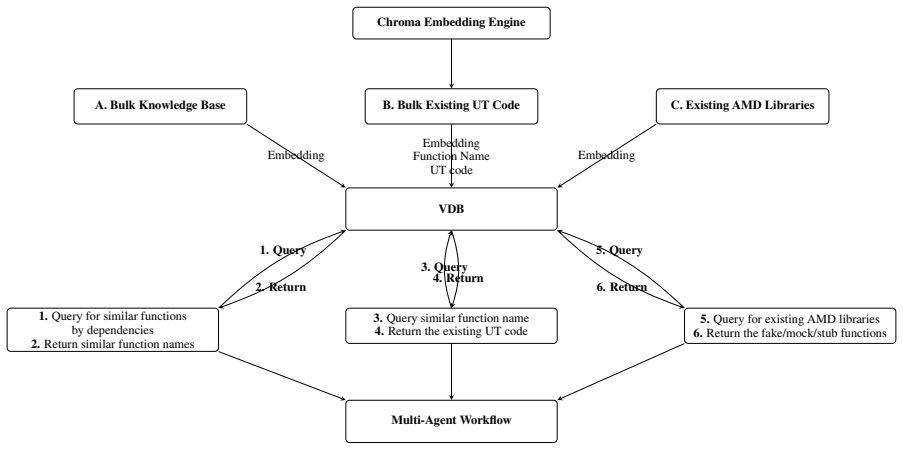
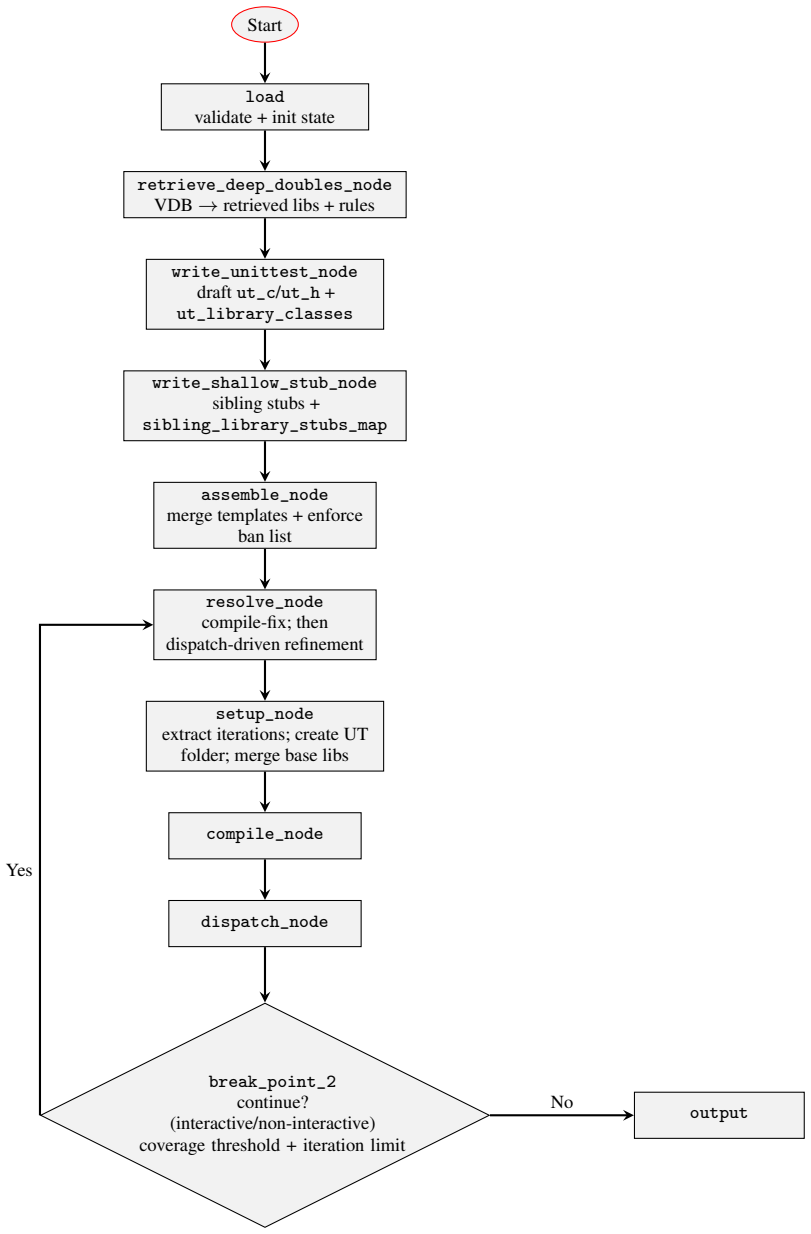
The iterative compile-dispatch repair loop driven by build logs and line-coverage feedback together with library-aware creation or reuse of stubs, mocks, and fakes.
If this is right
- Automated generation-and-repair pipelines can substantially improve unit test creation efficiency in constrained firmware environments.
- Line-coverage guidance alone raises mean coverage to 98.8 percent on evaluated subsets.
- The approach reduces manual debugging effort compared with purely manual test authoring.
- Results hold across configurations with and without vector-database retrieval augmentation.
Where Pith is reading between the lines
- The same loop structure could be tested on other low-level C libraries that share similar header and symbol constraints.
- Extending the agents to handle more complex dependency graphs might increase the fraction of functions that succeed without any retrieval step.
- If coverage feedback continues to drive repair, the method could be applied to legacy firmware where existing tests are sparse.
Load-bearing premise
The iterative repair loop driven by build logs and line-coverage feedback will converge to compilable high-coverage tests for most functions without human-written fixes.
What would settle it
Applying the workflow to additional OpenSIL functions or a different firmware codebase and finding that many tests still fail to compile after several repair iterations or require human intervention would falsify the central claim.
Figures




read the original abstract
Validating changes in low-level C firmware is expensive because unit tests (UTs) are fragile under strict build constraints, where missing headers, unresolved symbols, and dependency mismatches frequently prevent compilation and linking. This study introduces an automated UT authoring workflow for the Open-Source Silicon Initialization Library (openSIL) firmware codebase maintained by Advanced Micro Devices (AMD) that reduces manual effort through a large language model (LLM) guided multi-agent pipeline. The workflow combines automated generation of test scaffolds, library-aware creation or reuse of stubs, mocks, and fakes, and an iterative compile-dispatch repair loop driven by build logs and line-coverage feedback. We evaluate the approach using compilation success, repair iterations, dispatch success, and line coverage, with time, cost, and token usage as secondary measures. Across 76 functions under test, the workflow generated compilable UTs for 73 functions. In a configuration without line coverage guidance or retrieval augmentation, mean line coverage reached 73.9%. On a 48-function subset evaluated under both configurations, mean line coverage reached 98.8% with line-coverage guidance alone and reached 94.7% when combined with vector-database retrieval. Results show that automated generation-and-repair pipelines can substantially improve UT creation efficiency and coverage for constrained firmware environments while reducing manual debugging effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a multi-agent LLM workflow for generating unit tests in the OpenSIL firmware codebase. It combines test scaffold generation, library-aware stub/mock creation, and an iterative compile-dispatch-repair loop using build logs and line-coverage feedback. Empirical results on 76 functions report 73 compilable tests; mean line coverage is 73.9% without guidance and reaches 98.8% with line-coverage guidance on a 48-function subset.
Significance. If the results hold, the work addresses a practical pain point in low-level firmware validation under strict build constraints and supplies concrete, reproducible metrics (compilation counts, coverage, token/cost usage) on a real AMD-maintained codebase. These strengths make the contribution potentially useful for SE practitioners working with constrained C environments.
major comments (3)
- [Evaluation] Evaluation section: the 73/76 compilation success and the 98.8% coverage figures are reported only for the full multi-agent + iterative-repair workflow. No control arm applies an otherwise identical initial prompt (same model, same library stubs, same context) in a single forward pass, so the incremental contribution of the repair loop cannot be isolated.
- [Evaluation] Function selection paragraph (near the start of the evaluation): the criteria used to choose the 76 functions and the precise exclusion rules are not fully specified, which limits reproducibility and makes it impossible to judge whether the reported rates generalize beyond the selected set.
- [Evaluation] 48-function subset comparison: the paper reports mean coverage of 98.8% (line-coverage guidance) versus 94.7% (with retrieval) but supplies neither per-function variance, statistical tests, nor confidence intervals, weakening the claim that guidance alone produces a reliable improvement.
minor comments (2)
- The abstract states secondary measures (time, cost, token usage) but the main text should tabulate them explicitly alongside the primary metrics for each configuration.
- Clarify the exact LLM model, temperature, and maximum repair iterations in the workflow description so that the experiment is fully replicable.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the 73/76 compilation success and the 98.8% coverage figures are reported only for the full multi-agent + iterative-repair workflow. No control arm applies an otherwise identical initial prompt (same model, same library stubs, same context) in a single forward pass, so the incremental contribution of the repair loop cannot be isolated.
Authors: We agree that a single-pass baseline would strengthen the evaluation by isolating the repair loop's contribution. The manuscript presents the results for the complete workflow, which includes the iterative repair as an essential component for achieving compilable tests under firmware constraints. In the revision, we will expand the evaluation discussion to note the typical number of repair iterations required and the common failure modes observed in initial generations, thereby providing indirect evidence for the loop's value. revision: partial
-
Referee: [Evaluation] Function selection paragraph (near the start of the evaluation): the criteria used to choose the 76 functions and the precise exclusion rules are not fully specified, which limits reproducibility and makes it impossible to judge whether the reported rates generalize beyond the selected set.
Authors: We will revise the function selection paragraph to fully specify the criteria used to choose the 76 functions, including the precise exclusion rules and the rationale for selection from the OpenSIL codebase. revision: yes
-
Referee: [Evaluation] 48-function subset comparison: the paper reports mean coverage of 98.8% (line-coverage guidance) versus 94.7% (with retrieval) but supplies neither per-function variance, statistical tests, nor confidence intervals, weakening the claim that guidance alone produces a reliable improvement.
Authors: We agree with this observation. The revised manuscript will include per-function coverage data for the 48-function subset, along with variance measures, and we will conduct and report appropriate statistical tests with confidence intervals to substantiate the comparison. revision: yes
Circularity Check
No circularity; all claims are direct empirical measurements
full rationale
The manuscript presents an empirical workflow evaluation on a fixed set of 76 openSIL functions, reporting observed outcomes such as 73/76 compilation success and line-coverage percentages (73.9%, 98.8%, 94.7%) under different configurations. No equations, fitted parameters, predictions, or derivations appear in the text that reduce by construction to inputs, self-definitions, or self-citations. Results are measured quantities from running the described pipeline, with no load-bearing theoretical steps or renamings that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can interpret build logs and coverage reports to generate effective repairs
Reference graph
Works this paper leans on
-
[1]
On the evaluation of large language models in unit test generation
Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, and Junjie Chen. On the evaluation of large language models in unit test generation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2024. arXiv:2406.18181. 18
-
[2]
An evaluation of code coverage adequacy in automatic testing using control flow graph visualization
Ani Rahmani, Joe Lian Min, and Asri Maspupah. An evaluation of code coverage adequacy in automatic testing using control flow graph visualization. InProceedings of the 2020 IEEE 10th Symposium on Computer Applications and Industrial Electronics (ISCAIE), pages 239–244. IEEE, 2020
2020
-
[3]
Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: A survey.IEEE Transactions on Software Engineering, 41(5):507–525, 2015
2015
-
[4]
EDK II build system, 2025
Tianocore. EDK II build system, 2025. Accessed: 2025-06-14
2025
-
[5]
Addison-Wesley Professional, 2004
Michael Feathers.Working Effectively with Legacy Code. Addison-Wesley Professional, 2004
2004
-
[6]
An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering, 50(1):85–105, January 2024
Michael Schäfer, Sarah Nadi, Armin Eghbali, and Frank Tip. An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering, 50(1):85–105, January 2024
2024
-
[7]
ASTER: Natural and multi- language unit test generation with LLMs
Rangeet Pan, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, and Saurabh Sinha. ASTER: Natural and multi- language unit test generation with LLMs. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 413–424, 2025
2025
-
[8]
Evaluating and improving ChatGPT for unit test generation
Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. Evaluating and improving ChatGPT for unit test generation. InProceedings of the ACM on Software Engineering (ESEC/FSE), 2024
2024
-
[9]
LCOV: Code coverage report generator, 2025
Linux Test Project. LCOV: Code coverage report generator, 2025. Accessed: 2025
2025
-
[10]
Whalen, and Mats P
Matt Staats, Michael W. Whalen, and Mats P. E. Heimdahl. Programs, tests, and oracles: The foundations of testing revisited. InProceedings of the 33rd International Conference on Software Engineering (ICSE), pages 391–400. ACM, 2011
2011
-
[11]
ld: The GNU linker (Options: --wrap), 2025
GNU Binutils. ld: The GNU linker (Options: --wrap), 2025. Accessed: 2025
2025
-
[12]
Ceedling: BDD-style unit testing for C, 2025
Ceedling. Ceedling: BDD-style unit testing for C, 2025. Accessed: 2025
2025
-
[13]
KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs
Cristian Cadar, Daniel Dunbar, and Dawson Engler. KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs. InProceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 209–224. USENIX, 2008
2008
-
[14]
An analysis and survey of the development of mutation testing.IEEE Transactions on Software Engineering, 37(5):649–678, 2011
Yue Jia and Mark Harman. An analysis and survey of the development of mutation testing.IEEE Transactions on Software Engineering, 37(5):649–678, 2011
2011
-
[15]
EvoSuite: Automatic test suite generation for object-oriented software
Gordon Fraser and Andrea Arcuri. EvoSuite: Automatic test suite generation for object-oriented software. In Proceedings of the 19th ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE), pages 416–419. ACM, 2011
2011
-
[16]
Leveraging large language models for enhancing the understandability of generated unit tests
Amirhossein Deljouyi, Roham Koohestani, Maliheh Izadi, and Andy Zaidman. Leveraging large language models for enhancing the understandability of generated unit tests. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering (ICSE), 2025
2025
-
[17]
Desmarais
Arghavan Moradi Dakhel, Amin Nikanjam, Vahid Majdinasab, Foutse Khomh, and Michel C. Desmarais. Effective test generation using pre-trained large language models and mutation testing.Information and Software Technology, 171:107468, July 2024
2024
-
[18]
Harnessing the power of LLMs: Automating unit test generation for high-performance computing, 2024
Rabimba Karanjai, Aftab Hussain, Md Rafiqul Islam Rabin, Lei Xu, Weidong Shi, and Mohammad Amin Alipour. Harnessing the power of LLMs: Automating unit test generation for high-performance computing, 2024
2024
-
[19]
Large language models for unit testing: A systematic literature review, 2025
Quanjun Zhang, Chunrong Fang, Siqi Gu, Ye Shang, Zhenyu Chen, and Liang Xiao. Large language models for unit testing: A systematic literature review, 2025
2025
-
[20]
Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering, 50(4):911–936, April 2024
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering, 50(4):911–936, April 2024
2024
-
[21]
Large language models: A survey, 2024
Shervin Minaee, Tomás Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2024
2024
-
[22]
Introducing OpenAI o3 and o4-mini, 2025
OpenAI. Introducing OpenAI o3 and o4-mini, 2025. Accessed: 2025-06-26
2025
-
[23]
Fenton and James Bieman.Software Metrics: A Rigorous and Practical Approach
Norman E. Fenton and James Bieman.Software Metrics: A Rigorous and Practical Approach. CRC Press, 3 edition, 2014
2014
-
[24]
CITYW ALK: Enhancing LLM-based C++ unit test generation via project-dependency awareness and language-specific knowledge, 2025
Yuwei Zhang, Qingyuan Lu, Kai Liu, Wensheng Dou, Jiaxin Zhu, Li Qian, Chunxi Zhang, Zheng Lin, and Jun Wei. CITYW ALK: Enhancing LLM-based C++ unit test generation via project-dependency awareness and language-specific knowledge, 2025. 19
2025
-
[25]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459–9474, 2020
2020
-
[26]
RepoCoder: Repository-level code completion through iterative retrieval and generation, 2023
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. RepoCoder: Repository-level code completion through iterative retrieval and generation, 2023
2023
-
[27]
CodeRAG: Finding relevant and necessary knowledge for retrieval-augmented repository-level code completion
Siyuan Zhang, Ying Ding, Shuaijun Lian, Shuai Song, and Hao Li. CodeRAG: Finding relevant and necessary knowledge for retrieval-augmented repository-level code completion. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[28]
Lahiri, and Sanjit Sen
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K. Lahiri, and Sanjit Sen. CodaMosa: Escaping coverage plateaus in test generation with pre-trained large language models. InProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE), pages 919–931. IEEE, 2023
2023
-
[29]
Automatically finding patches using genetic programming
Westley Weimer, ThanhVu Nguyen, Claire Le Goues, and Stephanie Forrest. Automatically finding patches using genetic programming. InProceedings of the 31st International Conference on Software Engineering (ICSE), pages 364–374. IEEE, 2009
2009
-
[30]
Automatic software repair: A bibliography, 2018
Martin Monperrus. Automatic software repair: A bibliography, 2018
2018
-
[31]
Valentin J. M. Manès, HyungSeok Han, Choongwoo Han, Sang Kil Cha, Manuel Egele, Edward J. Schwartz, and Maverick Woo. The art, science, and engineering of fuzzing: A survey.IEEE Transactions on Software Engineering, 47(11):2312–2331, 2021
2021
-
[32]
Aider LLM leaderboards, 2025
Aider. Aider LLM leaderboards, 2025. Accessed: 2025-09-06. 20
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.