NRITYAM: Language Models Meet Art and Heritage of Dance
Pith reviewed 2026-06-26 17:55 UTC · model grok-4.3
The pith
NRITYAM supplies 9,260 question-answer pairs across 12 languages to test language models on cultural knowledge of global dance traditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
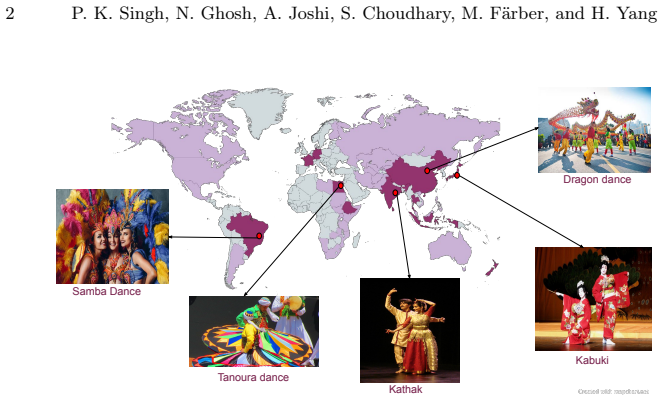
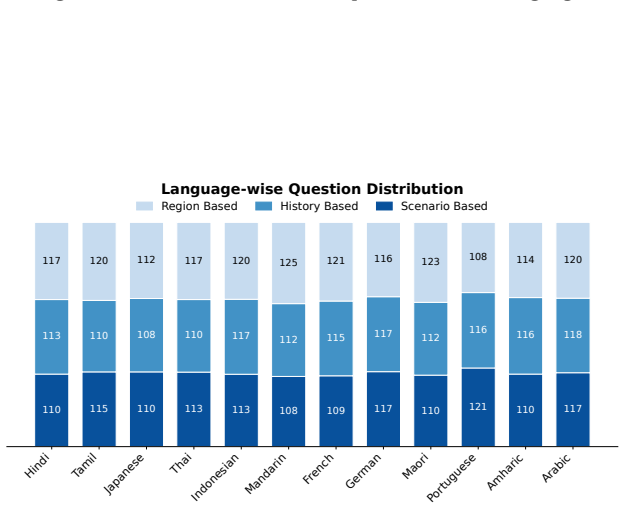
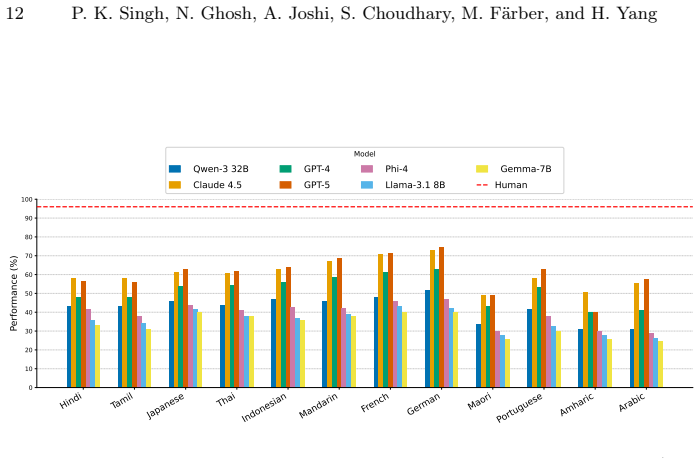
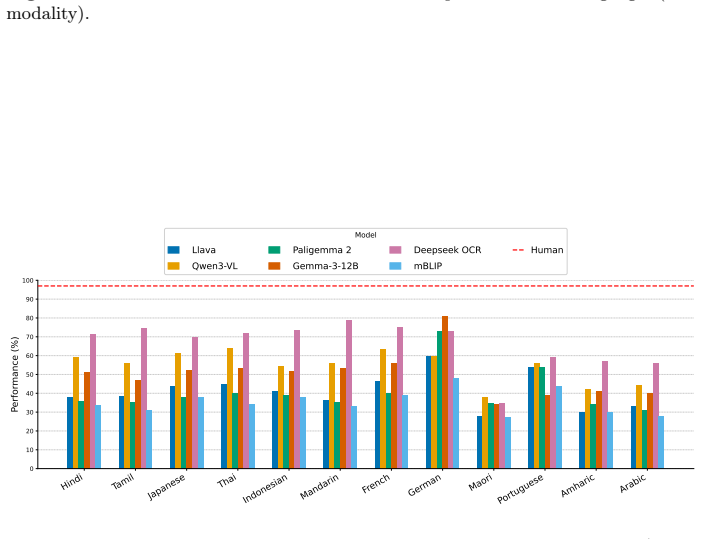
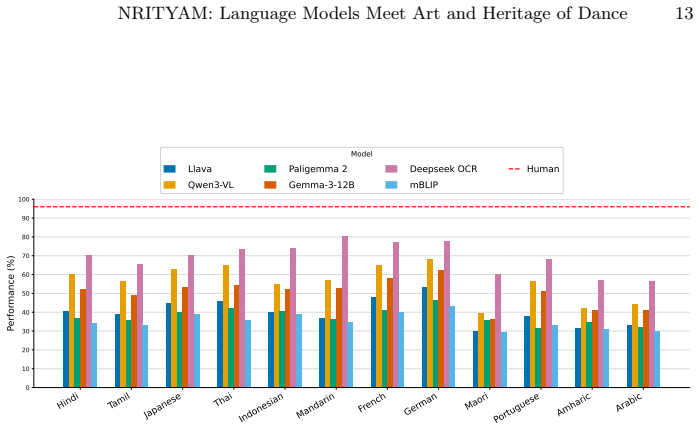
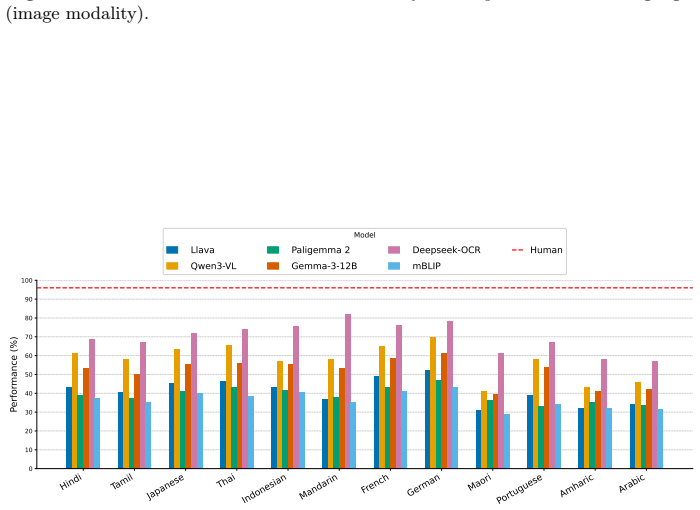
NRITYAM comprises 9,260 carefully curated question-answer pairs spanning 12 languages, making it the largest dataset dedicated to evaluating cultural knowledge in dance, developed from the ground up through close collaboration with native dance artists and native speakers of the languages, who authored and validated culturally relevant questions specific to their regions, and it sets a new standard for evaluating the ability of AI systems to understand and reason about traditional performing arts.
What carries the argument
The NRITYAM dataset of 9,260 culturally relevant question-answer pairs authored and validated by native dance artists and speakers.
If this is right
- Models can be ranked by their ability to answer questions about specific regional dance traditions and cultural contexts.
- Gaps in performance between large language models, small language models, multimodal models, and small multimodal models become measurable on dance-related cultural tasks.
- The dataset supplies a baseline that future model training can target to improve multicultural reasoning.
- Native-expert involvement provides a repeatable method for building similar benchmarks in other cultural domains.
Where Pith is reading between the lines
- The same native-collaboration approach could extend to benchmarks on music, theater, or visual arts to cover broader performing and heritage domains.
- Model developers might use low scores on NRITYAM to prioritize adding region-specific cultural data during training.
- Public release of the dataset at the linked repository allows direct replication and extension by other researchers.
Load-bearing premise
Questions authored and validated by native dance artists and speakers accurately capture the cultural comprehension capabilities required for language models to reason about traditional performing arts.
What would settle it
If a fresh set of questions written independently by different native artists on the same dance topics produces markedly different model rankings or scores, the original benchmark's validity as a measure of cultural comprehension would be challenged.
Figures




read the original abstract
Language models have become essential tools in shaping modern workflows. However, their global effectiveness hinges on a nuanced understanding of local socio-cultural contexts. To address this gap, we present NRITYAM, a comprehensive benchmark for evaluating the cultural comprehension capabilities of language models in the context of global dance traditions. NRITYAM comprises 9,260 carefully curated question-answer pairs spanning 12 languages, making it the largest dataset dedicated to evaluating cultural knowledge in dance. The dataset has been developed from the ground up through close collaboration with native dance artists and native speakers of the languages, who authored and validated culturally relevant questions specific to their regions. We evaluate a broad set of models, including large language models, small language models, multimodal large language models, and small multimodal language models. As a multilingual and multicultural benchmark, NRITYAM sets a new standard for evaluating the ability of AI systems to understand and reason about traditional performing arts. Detailed dataset samples are available at~\url{https://github.com/niladrighosh03/NRITYAM}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NRITYAM, a benchmark of 9,260 curated question-answer pairs spanning 12 languages for evaluating language models' cultural comprehension capabilities in global dance traditions. The dataset is developed through collaboration with native dance artists and native speakers who authored and validated the questions; the paper evaluates a range of LLMs, SLMs, MLLMs, and small multimodal models and positions NRITYAM as setting a new standard for assessing AI understanding of traditional performing arts.
Significance. If the dataset construction and validation were shown to reliably probe cultural reasoning rather than surface facts, NRITYAM would constitute a substantial contribution as the largest dedicated multilingual resource for dance heritage, addressing a clear gap in multicultural and socio-cultural evaluation benchmarks for language models.
major comments (2)
- [Abstract] Abstract: the central claim that NRITYAM measures 'cultural comprehension capabilities' and the ability to 'reason about traditional performing arts' rests on the unexamined assumption that native-artist-authored questions necessarily test the intended depth; the abstract supplies no definition of cultural comprehension, no taxonomy distinguishing factual recall from inference over heritage practices, and no quantitative validation results such as inter-annotator agreement or expert review of reasoning demands.
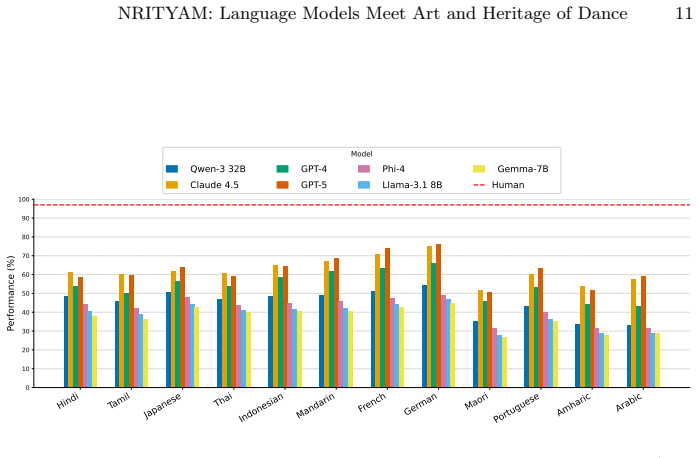
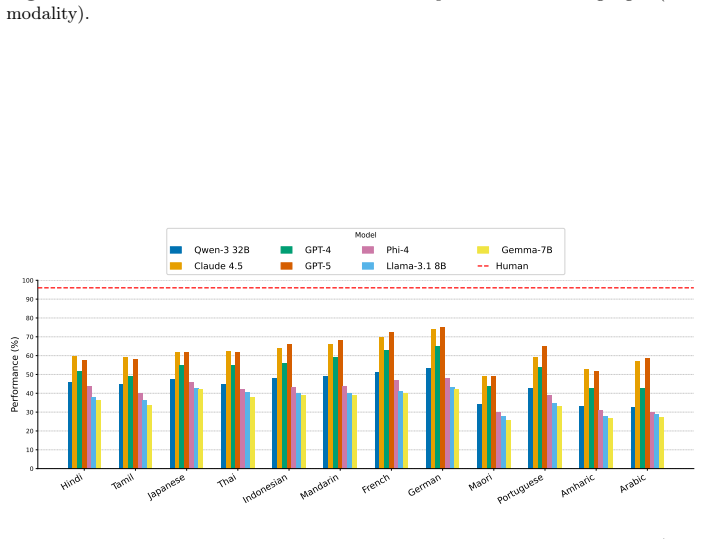
- [Abstract] Abstract: although the manuscript states that 'we evaluate a broad set of models,' no performance numbers, baselines, or quantitative results appear in the provided text, leaving the claim that NRITYAM 'sets a new standard' unsupported by evidence of model behavior on the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that NRITYAM measures 'cultural comprehension capabilities' and the ability to 'reason about traditional performing arts' rests on the unexamined assumption that native-artist-authored questions necessarily test the intended depth; the abstract supplies no definition of cultural comprehension, no taxonomy distinguishing factual recall from inference over heritage practices, and no quantitative validation results such as inter-annotator agreement or expert review of reasoning demands.
Authors: We acknowledge that the abstract lacks an explicit definition of cultural comprehension and a taxonomy of question types. The dataset construction (detailed in Section 3) involved native artists authoring questions that span factual recall and inference over heritage practices, with validation by native speakers. We will add a brief definition and note on question categories to the abstract. Regarding quantitative validation, we will include inter-annotator agreement statistics from the curation process in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: although the manuscript states that 'we evaluate a broad set of models,' no performance numbers, baselines, or quantitative results appear in the provided text, leaving the claim that NRITYAM 'sets a new standard' unsupported by evidence of model behavior on the benchmark.
Authors: The abstract is intentionally concise; full model evaluations, baselines, and quantitative results appear in Sections 4 and 5. To better support the 'new standard' claim within the abstract itself, we will incorporate key performance highlights (e.g., accuracy ranges across model categories) in the revision. revision: yes
Circularity Check
No circularity: benchmark construction relies on external expert curation, not self-referential definitions or fitted predictions
full rationale
The paper presents NRITYAM as a curated dataset of 9,260 QA pairs authored and validated by native artists and speakers. No equations, parameters, or derivations are described. The central claim (dataset size, multilingual coverage, and expert involvement establishing a 'new standard' for cultural comprehension) does not reduce to any self-definition, fitted input renamed as prediction, or self-citation chain. External expert input is independent of the paper's own outputs. No load-bearing self-citations or ansatzes appear in the provided text. This is a standard dataset paper with no mathematical derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A.A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., et al.: Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Advanced Journal of Theatre and Film Studies2(1), 39–45 (2024)
Afolaranmi, V.B., Afolaranmi, A.O.: Cultural revitalization through dance as a panacea for peacebuilding. Advanced Journal of Theatre and Film Studies2(1), 39–45 (2024)
2024
-
[4]
AlKhamissi, B., ElNokrashy, M.N., Alkhamissi, M., Diab, M.T.: Investigating cul- tural alignment of large language models. In: ACL. pp. 12404–12422 (2024)
2024
-
[5]
In: Euro- graphics 2022-43nd Annual Conference of the European Association for Computer Graphics
Aristidou, A., Chalmers, A., Chrysanthou, Y., Loscos, C., Multon, F., Parkins, J., Sarupuri, B., Stavrakis, E.: Safeguarding our dance cultural heritage. In: Euro- graphics 2022-43nd Annual Conference of the European Association for Computer Graphics. pp. 1–6 (2022)
2022
-
[6]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dance Research32(1), 65–80 (2014)
Bannerman, H.: Is dance a language? movement, meaning and communication. Dance Research32(1), 65–80 (2014)
2014
-
[9]
Bender, E.M., Gebru, T., McMillan-Major, A., Shmitchell, S.: On the dangers of stochastic parrots: Can language models be too big? In: Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. pp. 610–623 (2021)
2021
-
[10]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., et al.: Paligemma: A ver- satile 3b vlm for transfer. arXiv preprint arXiv:2407.07726 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[12]
In: Find- ingsoftheAssociationforComputationalLinguistics:EMNLP2023.pp.2667–2682 (2023)
Changpinyo, S., Xue, L., Yarom, M., Thapliyal, A., Szpektor, I., Amelot, J., Chen, X., Soricut, R.: Maxm: Towards multilingual visual question answering. In: Find- ingsoftheAssociationforComputationalLinguistics:EMNLP2023.pp.2667–2682 (2023)
2023
-
[13]
In: International Conference on Learning Representations
Deng, Y., Zhang, W., Pan, S.J., Bing, L.: Multilingual jailbreak challenges in large language models. In: International Conference on Learning Representations. vol. 2024, pp. 24634–24651 (2024)
2024
-
[14]
Cul- tural Critique (26), 33–63 (1993)
Desmond, J.C.: Embodying difference: Issues in dance and cultural studies. Cul- tural Critique (26), 33–63 (1993)
1993
-
[15]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
State Institute of Education, Allahabad30, 171– 182 (2024)
Dwivedi, S.K., Patel, R.: Exploring the intersections: Anthropological insights into studying language and culture. State Institute of Education, Allahabad30, 171– 182 (2024)
2024
-
[17]
Advances in neural information processing systems28(2015) NRITYAM: Language Models Meet Art and Heritage of Dance 17
Gao, H., Mao, J., Zhou, J., Huang, Z., Wang, L., Xu, W.: Are you talking to a machine? dataset and methods for multilingual image question. Advances in neural information processing systems28(2015) NRITYAM: Language Models Meet Art and Heritage of Dance 17
2015
-
[18]
arXiv preprint arXiv:2307.06930 (2023)
Geigle, G., Jain, A., Timofte, R., Glavaš, G.: mblip: Efficient bootstrapping of multilingual vision-llms. arXiv preprint arXiv:2307.06930 (2023)
-
[19]
In: Proceedings of the 3rd International Sym- posium on Movement and Computing
Grammalidis, N., Dimitropoulos, K., Tsalakanidou, F., Kitsikidis, A., Roussel, P., Denby, B., Chawah, P., Buchman, L., Dupont, S., Laraba, S., et al.: The i-treasures intangible cultural heritage dataset. In: Proceedings of the 3rd International Sym- posium on Movement and Computing. pp. 1–8 (2016)
2016
-
[20]
Cultura: International Journal of Philosophy of Culture and Axiology22(2), 422– 440 (2025)
Guo, C., Li, Z.: The impact of dance culture learning on students’ cultural values. Cultura: International Journal of Philosophy of Culture and Axiology22(2), 422– 440 (2025)
2025
-
[21]
Gupta, D., Lenka, P., Ekbal, A., Bhattacharyya, P.: A unified framework for mul- tilingual and code-mixed visual question answering. In: Proceedings of the 1st conference of the Asia-Pacific chapter of the association for computational linguis- tics and the 10th international joint conference on natural language processing. pp. 900–913 (2020)
2020
-
[22]
arXiv preprint arXiv:2203.07785 (2022)
Johnson, R.L., Pistilli, G., Menédez-González, N., Duran, L.D.D., Panai, E., Kalpokiene, J., Bertulfo, D.J.: The ghost in the machine has an american accent: value conflict in gpt-3. arXiv preprint arXiv:2203.07785 (2022)
-
[23]
In: Findings of the Association for Computational Linguistics: ACL
Kabra, A., Liu, E., Khanuja, S., Aji, A.F., Winata, G.I., Cahyawijaya, S., Aremu, A., Ogayo, P., Neubig, G.: Multi-lingual and multi-cultural figurative language understanding. In: Findings of the Association for Computational Linguistics: ACL
-
[24]
8269–8284 (2023)
pp. 8269–8284 (2023)
2023
-
[25]
In: The First Conference on Language Modeling (2024)
Kwok, L., Bravansky, M., Griffin, L.: Evaluating cultural adaptability of a large language model via simulation of synthetic personas. In: The First Conference on Language Modeling (2024)
2024
-
[26]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Li,W.,Zhang,C.,Li,J.,Peng,Q.,Tang,R.,Zhou,L.,Zhang,W.,Hu,G.,Yuan,Y., Søgaard, A., et al.: Foodieqa: A multimodal dataset for fine-grained understand- ing of chinese food culture. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 19077–19095 (2024)
2024
-
[27]
In: NAACL
Liu, C., Koto, F., Baldwin, T., Gurevych, I.: Are multilingual llms culturally- diverse reasoners? an investigation into multicultural proverbs and sayings. In: NAACL. pp. 2016–2039 (2024)
2016
-
[28]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Liu, F., Bugliarello, E., Ponti, E.M., Reddy, S., Collier, N., Elliott, D.: Visually grounded reasoning across languages and cultures. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 10467– 10485 (2021)
2021
-
[29]
Advances in Neural Information Processing Systems36(2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in Neural Information Processing Systems36(2023)
2023
-
[30]
Integrative Psycholog- ical and Behavioral Science59(1), 31 (2025)
Lucchi Basili, L., Sacco, P.L.: Dance and the embodied social cognition of mating: Carlos saura’s tango in the perspective of the tie-up theory. Integrative Psycholog- ical and Behavioral Science59(1), 31 (2025)
2025
-
[31]
arXiv preprint arXiv:2405.03178 (2024)
Luo, Z., Ren, M., Hu, X., et al.: Popdg: Popular 3d dance generation with pop- danceset. arXiv preprint arXiv:2405.03178 (2024)
-
[32]
In: International Conference on Future Data and Security Engineering
Ma, T., Ngo, T., Tran, H.N., Ton, M.L., Ha, N.L., Phan, B.C., Do, T.N.: Vimva: Innovative multimodal recognition in vietnamese folk dance video analysis. In: International Conference on Future Data and Security Engineering. pp. 283–298. Springer (2024)
2024
-
[33]
arXiv preprint arXiv:2406.09496 (2024) 18 P
Magomere, J., Ishida, S., Afonja, T., Salama, A., Kochin, D., Yuehgoh, F., Hamza- oui, I., Sefala, R., Alaagib, A., Semenova, E., et al.: You are what you eat? feeding foundation models a regionally diverse food dataset of world wide dishes. arXiv preprint arXiv:2406.09496 (2024) 18 P. K. Singh, N. Ghosh, A. Joshi, S. Choudhary, M. Färber, and H. Yang
-
[34]
In: The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2024)
Mogrovejo, D.O.R., Lyu, C., Wibowo, H.A., Góngora, S., Mandal, A., Purkayastha, S., Ortiz-Barajas, J.G., Cueva, E.V., Baek, J., Jeong, S., et al.: Cvqa: Culturally- diverse multilingual visual question answering benchmark. In: The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2024)
2024
-
[35]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Nayak, S., Jain, K., Awal, R., Reddy, S., Van Steenkiste, S., Hendricks, L.A., Stańczak, K., Agrawal, A.: Benchmarking vision language models for cultural un- derstanding. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 5769–5790 (2024)
2024
-
[36]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[37]
Herança7(1), 88–99 (2024)
Peng, X.: Historical development and cross-cultural influence of dance creation: Evolution of body language. Herança7(1), 88–99 (2024)
2024
-
[38]
In: Findings of the association for computational linguistics: ACL 2022
Pfeiffer, J., Geigle, G., Kamath, A., Steitz, J.M.O., Roth, S., Vulić, I., Gurevych, I.: xgqa: Cross-lingual visual question answering. In: Findings of the association for computational linguistics: ACL 2022. pp. 2497–2511 (2022)
2022
-
[39]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Singh, P.K., Kumar, N., Ghosh, A., Pasad, K., Soni, K., Jaishwal, M., Saha, S., Alfarozi, S.A.I., Abagissa, A.T., Pasupa, K., et al.: Let’s play across cultures: A large multilingual, multicultural benchmark for assessing language models’ under- standing of sports. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing....
2025
-
[41]
In: Findings of the Association for Computational Linguistics: ACL
Tang, J., Liu, Q., Ye, Y., Lu, J., Wei, S., Wang, A.L., Lin, C., Feng, H., Zhao, Z., Wang, Y., et al.: Mtvqa: Benchmarking multilingual text-centric visual question answering. In: Findings of the Association for Computational Linguistics: ACL
-
[42]
7748–7763 (2025)
pp. 7748–7763 (2025)
2025
-
[43]
Gemma: Open Models Based on Gemini Research and Technology
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M.S., Love, J., et al.: Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
In: Proceed- ings of the 3rd Workshop on Advances in Language and Vision Research (ALVR)
Urailertprasert, N., Limkonchotiwat, P., Suwajanakorn, S., Nutanong, S.: Sea-vqa: Southeast asian cultural context dataset for visual question answering. In: Proceed- ings of the 3rd Workshop on Advances in Language and Vision Research (ALVR). pp. 173–185 (2024)
2024
-
[45]
Vayani, A., Dissanayake, D., Watawana, H., Ahsan, N., Sasikumar, N., Thawakar, O., Ademtew, H.B., Hmaiti, Y., Kumar, A., Kuckreja, K., et al.: All languages matter: Evaluating lmms on culturally diverse 100 languages. arXiv preprint arXiv:2411.16508 (2024)
-
[46]
DeepSeek-OCR: Contexts Optical Compression
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Winata, G.I., Hudi, F., Irawan, P.A., Anugraha, D., Putri, R.A., Yutong, W., Nohejl, A., Prathama, U.A., Ousidhoum, N., Amriani, A., et al.: Worldcuisines: A massive-scale benchmark for multilingual and multicultural visual question an- swering on global cuisines. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.