ROSE: Benchmarking the Perception-to-Action Gap in Multimodal Models
Pith reviewed 2026-06-26 18:35 UTC · model grok-4.3
The pith
Multimodal models lose up to 44.5 points when shifting from counting objects to executing region-conditioned actions on the same scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
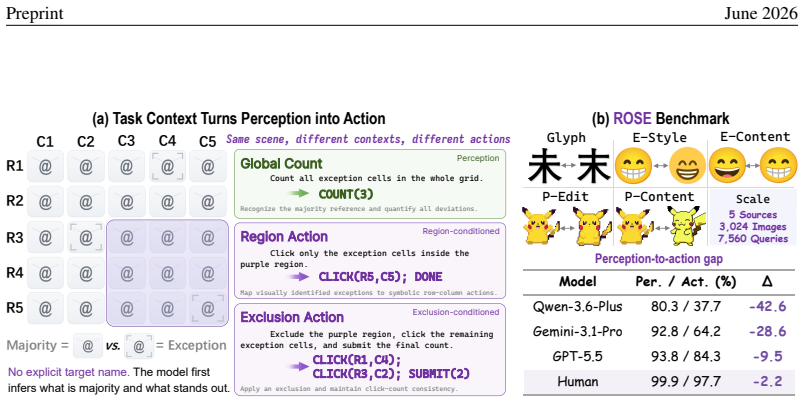
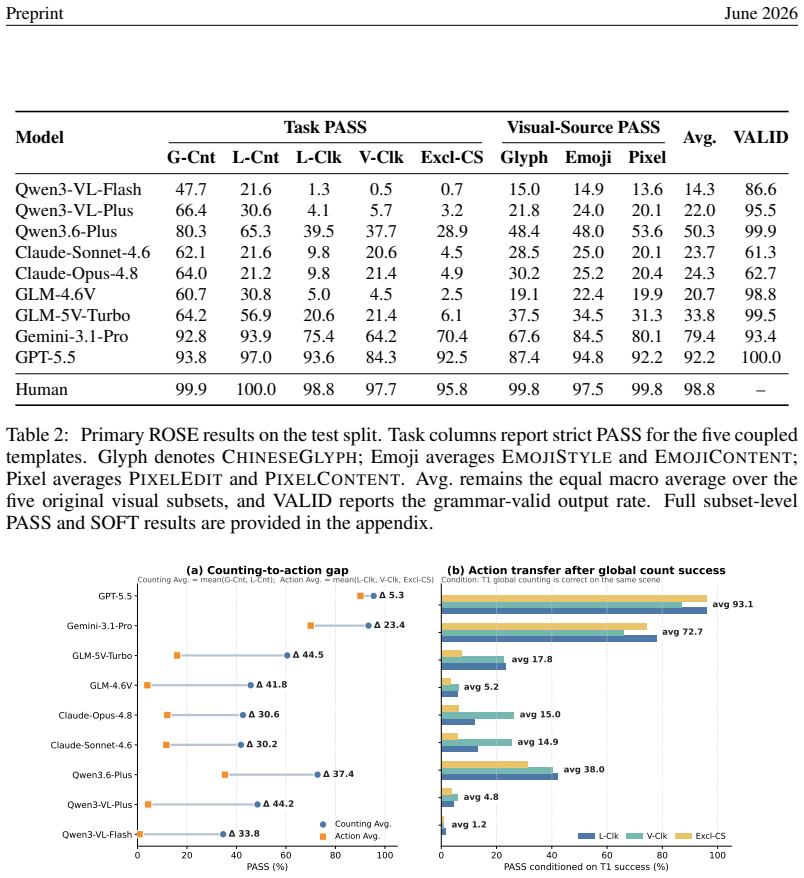
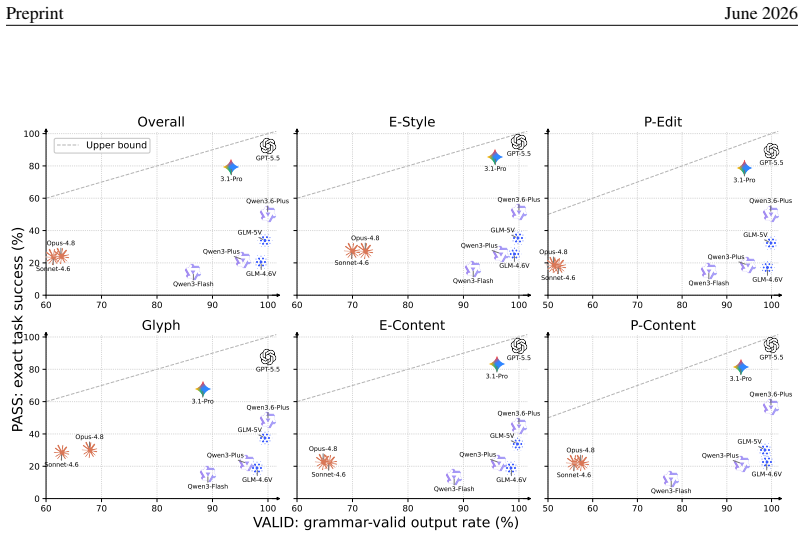
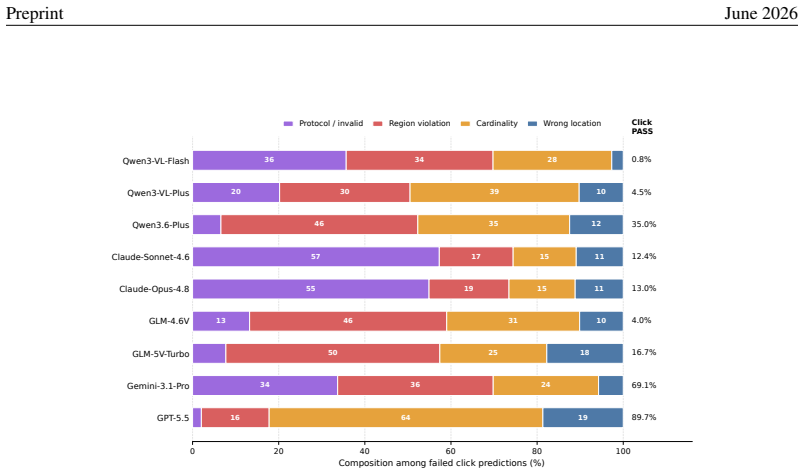
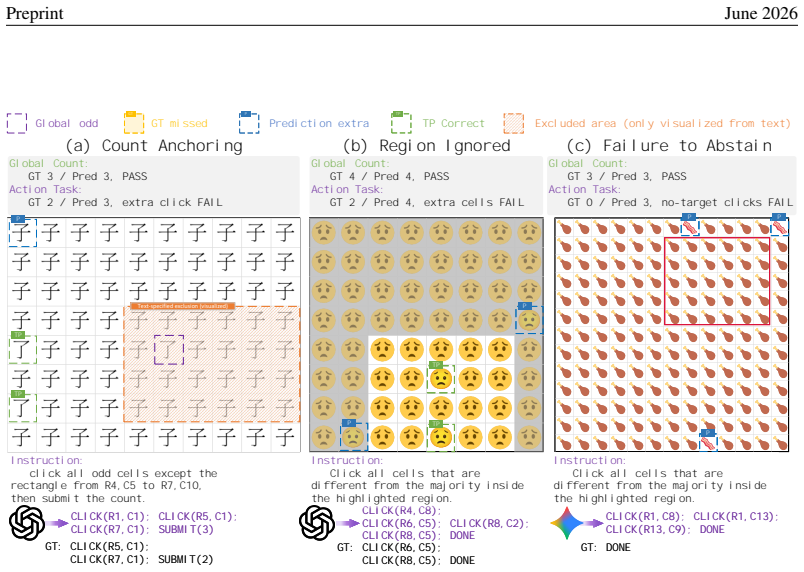
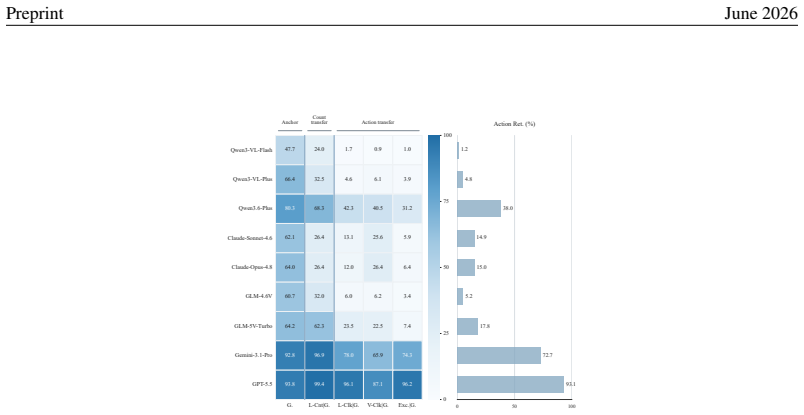
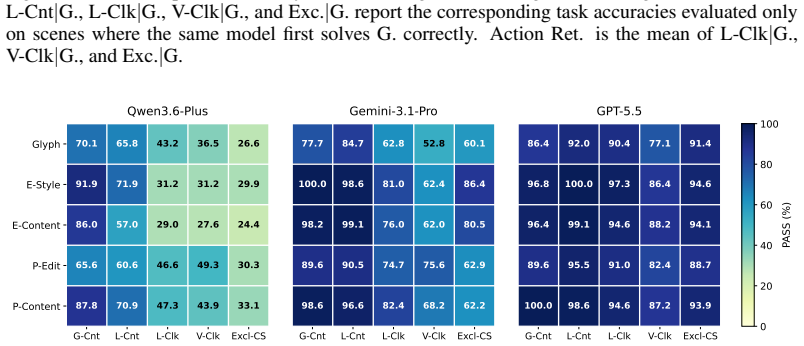
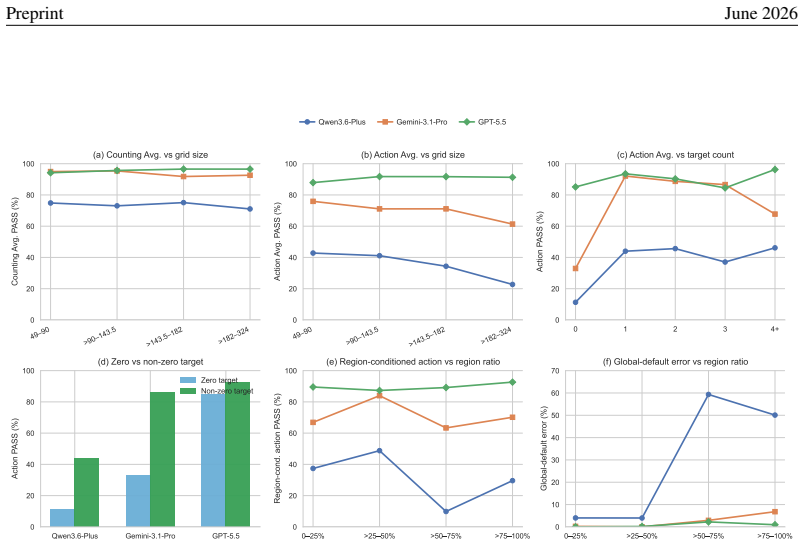
Across nine recent MLLMs, performance drops by as much as 44.5 percentage points from counting-oriented tasks to region-conditioned action on the same visual evidence, and the gap remains on paired scenes where the model returns the correct count; global-click and matched-local controls indicate that coordinate grounding explains only part of the loss, exposing a distinct perception-to-action bottleneck.
What carries the argument
The ROSE benchmark, which couples counting tasks with coordinate-action tasks on fixed scenes while varying region constraints and required symbolic outputs to test reference-conditioned execution.
If this is right
- Coordinate grounding alone does not explain the full performance loss on action tasks.
- The perception-to-action gap is model-dependent and appears even when the underlying count is correct.
- Global-click controls reduce but do not eliminate the drop, pointing to an additional context-integration failure.
- Human performance near 98.8 percent on the same tasks indicates the gap is not inherent to the visual evidence.
Where Pith is reading between the lines
- Training regimes may under-emphasize explicit reference conditioning when mapping counts to actions.
- The benchmark design could be reused to test whether scaling or new architectures close the gap without task-specific fine-tuning.
- Similar controlled pairings could expose analogous bottlenecks in non-visual modalities or in embodied settings.
Load-bearing premise
The benchmark tasks and controls are assumed to isolate a distinct perception-to-action bottleneck rather than prompt sensitivity or training-data overlap with test scenes.
What would settle it
A model that shows no accuracy drop between the paired counting task and the region-conditioned action task on identical scenes and regions would falsify the claimed gap.
Figures

read the original abstract
Multimodal large language models (MLLMs) are increasingly expected to act on visual information, yet the same scene may require different actions under different task contexts. How reliably can a model turn the same visual evidence into the action required by the current context? To answer this question, we introduce \textsc{ROSE} (\textbf{R}eference-conditioned \textbf{O}ddity and \textbf{S}ymbolic \textbf{E}xecution), a controlled benchmark that holds the visual scene fixed while varying region constraints and required symbolic outputs. Through coupled counting and coordinate-action tasks, \textsc{ROSE} tests whether models can infer an implicit majority reference and act on the resulting fine-grained visual evidence under changing contexts. Across nine recent MLLMs, performance drops by as much as 44.5 percentage points from counting-oriented tasks to region-conditioned action, despite 98.8\% human performance. The gap persists on paired scenes and regions for which the same model returns the correct count, while global-click and matched local controls show that coordinate grounding explains only part of the loss, revealing a distinct, model-dependent bottleneck in turning shared visual evidence into context-specific actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ROSE benchmark to measure a perception-to-action gap in multimodal LLMs. It pairs counting-oriented tasks with region-conditioned action tasks on fixed visual scenes, reporting performance drops of up to 44.5 percentage points across nine MLLMs (versus 98.8% human performance). The gap persists even on scenes where the model counts correctly; global-click and matched-local controls are said to show that coordinate grounding accounts for only part of the loss, indicating a distinct model-dependent bottleneck.
Significance. If the benchmark isolates a genuine perception-to-action bottleneck rather than prompt or format confounds, the result would be useful for diagnosing limitations in current MLLMs on context-dependent action tasks. The empirical scope (nine models, human baseline, paired-scene analysis) is a strength; the work is falsifiable and could inform targeted improvements in instruction following and grounding.
major comments (2)
- [Abstract] Abstract: The central claim that the observed drop reflects a distinct perception-to-action bottleneck (rather than prompt sensitivity) rests on the assertion that 'global-click and matched local controls show that coordinate grounding explains only part of the loss.' No details are supplied on whether the counting and action prompts were matched for lexical complexity, instruction length, output format, or pre-training alignment; without such matching the gap need not indicate a new bottleneck.
- [Abstract] Abstract / paired-scenes analysis: The persistence claim on 'paired scenes and regions for which the same model returns the correct count' assumes that the two tasks are otherwise equivalent once the count is known. The manuscript provides no evidence that other task-specific factors (e.g., required output vocabulary or reasoning depth) have been equalized, leaving open the possibility that the residual gap is still attributable to prompt differences.
minor comments (1)
- [Abstract] The abstract states '98.8% human performance' but does not specify the number of human subjects, inter-annotator agreement, or exact task instructions given to humans; these details belong in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on potential prompt confounds and the paired-scene analysis. We respond point by point below, drawing on the manuscript's methods and controls while noting where additional documentation will be added for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the observed drop reflects a distinct perception-to-action bottleneck (rather than prompt sensitivity) rests on the assertion that 'global-click and matched local controls show that coordinate grounding explains only part of the loss.' No details are supplied on whether the counting and action prompts were matched for lexical complexity, instruction length, output format, or pre-training alignment; without such matching the gap need not indicate a new bottleneck.
Authors: Section 3.2 and Appendix B describe the prompt templates, which were constructed with parallel phrasing, comparable sentence lengths, and identical reference descriptions to reduce lexical and structural differences. Output formats necessarily differ by task (numeric vs. coordinate lists) but are processed with the same parser. The global-click and matched-local controls hold prompt wording fixed while varying only the coordinate requirement. We agree that an explicit side-by-side comparison of prompt metrics would strengthen the presentation and will insert a table of token counts, sentence lengths, and vocabulary overlap in the revision. revision: partial
-
Referee: [Abstract] Abstract / paired-scenes analysis: The persistence claim on 'paired scenes and regions for which the same model returns the correct count' assumes that the two tasks are otherwise equivalent once the count is known. The manuscript provides no evidence that other task-specific factors (e.g., required output vocabulary or reasoning depth) have been equalized, leaving open the possibility that the residual gap is still attributable to prompt differences.
Authors: The paired analysis fixes the visual scene, reference object, and model-generated count, varying only the required output action. Both tasks require the same reference inference step; the additional coordinate output is isolated by the matched-local control. While output vocabulary differs by design, this is the variable under test. We will add quantitative prompt-similarity metrics and an explicit enumeration of reasoning steps in the methods section to document equivalence more transparently. revision: partial
Circularity Check
Empirical benchmark with no derivation chain or circular steps
full rationale
This is a purely empirical benchmark paper that introduces ROSE, runs controlled tests on nine MLLMs, and reports measured performance gaps (e.g., up to 44.5 pp drop) against human baselines. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central claims rest on direct task execution and paired-scene controls rather than any reduction to prior author work or definitional equivalence. The results are externally falsifiable via replication on the benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[5]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[6]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[7]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[8]
arXiv preprint arXiv:2604.15804 , year=
Qwen3.5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yang, Senqiao and Chen, Yukang and Tian, Zhuotao and Wang, Chengyao and Li, Jingyao and Yu, Bei and Jia, Jiaya , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[10]
Ref-Adv: Exploring
Qihua Dong and Kuo Yang and Lin Ju and Handong Zhao and Yitian Zhang and Yizhou Wang and Huimin Zeng and Jianglin Lu and Yun Fu , booktitle=. Ref-Adv: Exploring. 2026 , url=
2026
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Xu, Beining and Zhu, Siting and Jin, Zhao and Li, Junxian and Wang, Hesheng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DomainCQA: Crafting Knowledge-Intensive QA from Domain-Specific Charts , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
arXiv preprint arXiv:2602.10138 , year=
Multimodal Information Fusion for Chart Understanding: A Survey of MLLMs--Evolution, Limitations, and Cognitive Enhancement , author=. arXiv preprint arXiv:2602.10138 , year=
-
[15]
arXiv preprint arXiv:2511.15090 , year=
BBox DocVQA: A Large Scale Bounding Box Grounded Dataset for Enhancing Reasoning in Document Visual Question Answer , author=. arXiv preprint arXiv:2511.15090 , year=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
The Fourteenth International Conference on Learning Representations , year=
CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
Xie, Peijin and Xu, Zhen and Liu, Bingquan and Wang, Baoxun , journal=
-
[19]
arXiv preprint arXiv:2602.12196 , year=
Visual Reasoning Benchmark: Evaluating Multimodal LLMs on Classroom-Authentic Visual Problems from Primary Education , author=. arXiv preprint arXiv:2602.12196 , year=
-
[20]
arXiv preprint arXiv:2508.14160 , year=
Rynnec: Bringing mllms into embodied world , author=. arXiv preprint arXiv:2508.14160 , year=
-
[21]
arXiv preprint arXiv:2602.14979 , year=
Rynnbrain: Open embodied foundation models , author=. arXiv preprint arXiv:2602.14979 , year=
-
[22]
Proceedings of The 8th Conference on Robot Learning , pages =
OpenVLA: An Open-Source Vision-Language-Action Model , author =. Proceedings of The 8th Conference on Robot Learning , pages =. 2025 , editor =
2025
-
[23]
2026 , url=
Wulin Xie and YiFan Zhang and Chaoyou Fu and Yang Shi and Jianshu Zeng and Bingyan Nie and Hongkai Chen and Zhang Zhang and Liang Wang , booktitle=. 2026 , url=
2026
-
[24]
The Fourteenth International Conference on Learning Representations , year=
OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[25]
The Fourteenth International Conference on Learning Representations , year=
VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
arXiv preprint arXiv:2503.23064 , year=
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models , author=. arXiv preprint arXiv:2503.23064 , year=
-
[27]
Forty-second International Conference on Machine Learning , year=
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents , author=. Forty-second International Conference on Machine Learning , year=
-
[28]
2026 , url=
Chaoyou Fu and Peixian Chen and Yunhang Shen and Yulei Qin and Mengdan Zhang and Xu Lin and Jinrui Yang and Xiawu Zheng and Ke Li and Xing Sun and Yunsheng Wu and Rongrong Ji and Caifeng Shan and Ran He , booktitle=. 2026 , url=
2026
-
[29]
2024 , editor =
Yu, Weihao and Yang, Zhengyuan and Li, Linjie and Wang, Jianfeng and Lin, Kevin and Liu, Zicheng and Wang, Xinchao and Wang, Lijuan , booktitle =. 2024 , editor =
2024
-
[30]
Proceedings of CVPR , year=
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. Proceedings of CVPR , year=
-
[31]
and Ma, Wei-Chiu and Krishna, Ranjay
Fu, Xingyu and Hu, Yushi and Li, Bangzheng and Feng, Yu and Wang, Haoyu and Lin, Xudong and Roth, Dan and Smith, Noah A. and Ma, Wei-Chiu and Krishna, Ranjay. BLINK: Multimodal Large Language Models Can See but Not Perceive. Computer Vision -- ECCV 2024. 2025
2024
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Huynh, Ngoc Dung and Le-Khac, Phuc H and Para, Wamiq Reyaz and Singh, Ankit and Narayan, Sanath , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[34]
arXiv preprint arXiv:2401.13311 , year=
Contextual: Evaluating context-sensitive text-rich visual reasoning in large multimodal models , author=. arXiv preprint arXiv:2401.13311 , year=
-
[35]
CODIS : Benchmarking Context-dependent Visual Comprehension for Multimodal Large Language Models
Luo, Fuwen and Chen, Chi and Wan, Zihao and Kang, Zhaolu and Yan, Qidong and Li, Yingjie and Wang, Xiaolong and Wang, Siyu and Wang, Ziyue and Mi, Xiaoyue and Li, Peng and Ma, Ning and Sun, Maosong and Liu, Yang. CODIS : Benchmarking Context-dependent Visual Comprehension for Multimodal Large Language Models. Proceedings of the 62nd Annual Meeting of the ...
-
[36]
International Conference on Learning Representations , volume=
Navigating the digital world as humans do: Universal visual grounding for gui agents , author=. International Conference on Learning Representations , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.