What Makes Effective Supervision in Latent Chain-of-Thought: An Information-Theoretic Analysis
Pith reviewed 2026-06-26 18:22 UTC · model grok-4.3
The pith
Reasoning accuracy in latent chain-of-thought depends on the mutual information preserved between hidden states and explicit steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
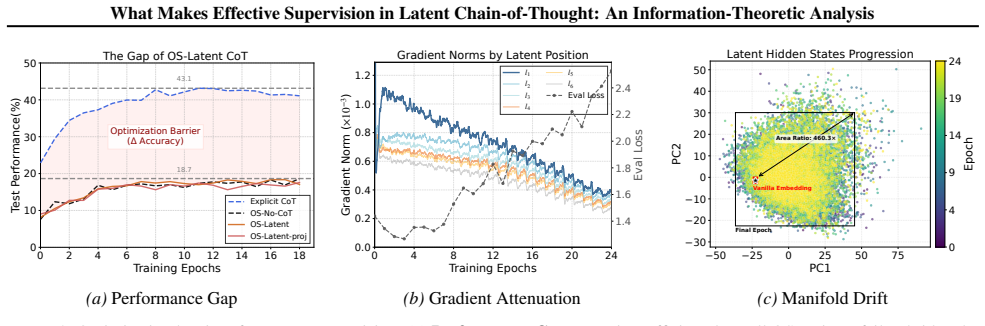
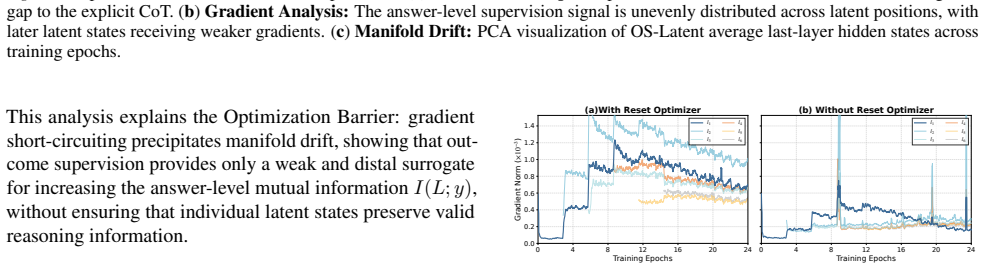
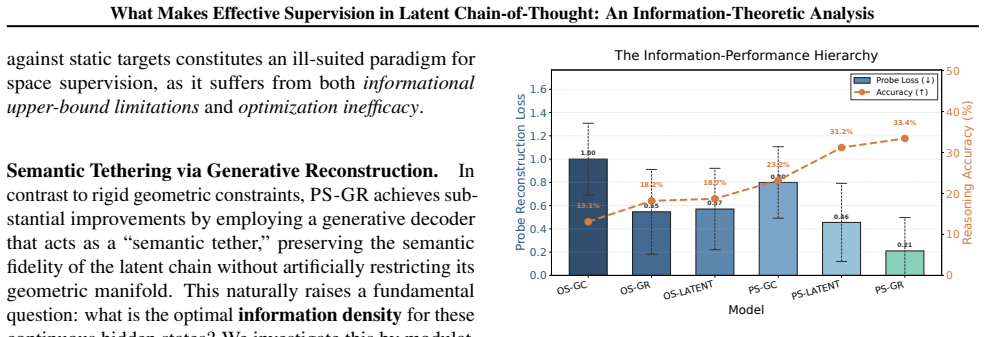
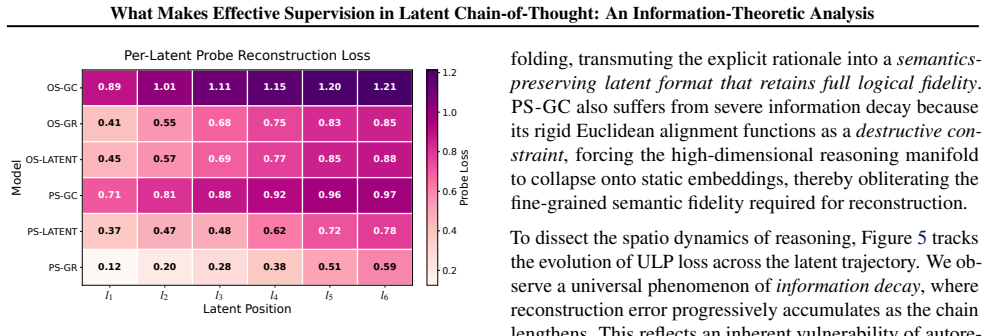
The authors establish an Information-Performance Binding in which reasoning accuracy depends on the information fidelity preserved in the latent chain, quantified as mutual information between latent trajectories and explicit reasoning steps via the Unified Latent Probe. They identify dual collapse under weak supervision and show that space supervision through generative reconstruction preserves semantic capacity better than geometric compression, while trajectory supervision supplies dense stepwise signals.
What carries the argument
The Unified Latent Probe (ULP), which quantifies mutual information between latent trajectories and explicit reasoning steps to assess information fidelity in the latent chain.
If this is right
- Process supervision must combine trajectory signals with space preservation to prevent both gradient attenuation and representational drift.
- Generative reconstruction as space supervision maintains higher information capacity than geometric compression.
- Outcome supervision alone produces semantic drift and lower accuracy in latent chains.
- Supervision design should shift toward mutual information maximization rather than geometric imitation of explicit traces.
Where Pith is reading between the lines
- The binding could be tested directly by optimizing a mutual information term as an auxiliary loss in latent reasoning training.
- The probe might be applied to measure information flow in other continuous-state models outside the tested latent CoT setups.
- Scaling experiments could check whether the required fidelity level changes with model size or task complexity.
Load-bearing premise
The Unified Latent Probe provides an unbiased quantification of mutual information between latent trajectories and explicit reasoning steps without confounds from model architecture or optimization choices.
What would settle it
An experiment finding high reasoning accuracy despite low ULP mutual information scores, or low accuracy despite high scores, would falsify the Information-Performance Binding.
Figures

read the original abstract
Latent Chain-of-Thought (CoT) internalizes reasoning within continuous hidden states, offering a promising alternative to verbose discrete reasoning traces. However, robust latent reasoning remains difficult because outcome supervision provides weak learning signals and leaves latent trajectories prone to semantic drift. In this work, we analyze Latent CoT from an information-theoretic perspective and identify this failure as a dual collapse: gradient attenuation along the optimization path and representational drift in the latent space. We further decompose process supervision into two complementary dimensions: Trajectory Supervision, which injects dense stepwise reasoning signals, and Space Supervision, which preserves the semantic structure of the latent manifold. Our analysis shows that rigid geometric compression can collapse the reasoning space, whereas generative reconstruction provides a more flexible semantic anchor that better preserves information capacity. To measure these effects, we introduce the Unified Latent Probe (ULP), which quantifies the mutual information between latent trajectories and explicit reasoning steps. Experiments reveal a clear Information-Performance Binding: reasoning accuracy depends on the information fidelity preserved in the latent chain. These findings provide a principled framework for latent reasoning supervision and suggest shifting from geometric imitation toward mutual information maximization. Our code is available at \href{https://github.com/EIT-NLP/Supervision-in-Latent-CoT}{this repository}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes latent chain-of-thought (CoT) from an information-theoretic perspective, identifying a 'dual collapse' (gradient attenuation along the optimization path and representational drift in latent space) as the cause of weak outcome supervision. It decomposes process supervision into Trajectory Supervision (dense stepwise signals) and Space Supervision (semantic manifold preservation), argues that generative reconstruction outperforms rigid geometric compression for preserving information capacity, introduces the Unified Latent Probe (ULP) to quantify mutual information between latent trajectories and explicit reasoning steps, and reports an 'Information-Performance Binding' in which reasoning accuracy tracks preserved information fidelity. Experiments support shifting supervision toward mutual information maximization rather than geometric imitation; code is released.
Significance. If the ULP delivers an architecture-independent MI estimate and the binding is shown to be robust rather than estimator-dependent, the work supplies a principled framework for designing supervision in latent reasoning models. The decomposition into trajectory vs. space dimensions and the contrast between generative and geometric anchors are potentially useful distinctions. Code release aids reproducibility.
major comments (2)
- [Abstract and Unified Latent Probe definition] The central Information-Performance Binding claim (abstract and experiments section) rests on ULP providing an unbiased, architecture- and optimizer-independent estimate of mutual information. No derivation or ablation is supplied showing that the probe's MI estimate remains stable across model families, sampling strategies for trajectories, or variational estimator choices; any dependence would render the reported correlation an artifact of the measurement tool rather than evidence of the proposed mechanism.
- [Methods / Supervision decomposition] The decomposition of supervision into Trajectory Supervision and Space Supervision (methods section) is presented as complementary, yet the paper supplies no quantitative separation (e.g., controlled ablations isolating each component's contribution to the MI term or to downstream accuracy) that would establish the decomposition as load-bearing rather than descriptive.
minor comments (2)
- [Introduction] Notation for the dual-collapse terms (gradient attenuation and representational drift) is introduced without explicit equations linking them to standard information-theoretic quantities such as I(trajectory; label) or KL divergence terms.
- [Experiments] The abstract states that 'generative reconstruction provides a more flexible semantic anchor'; the corresponding experimental comparison (table or figure) should report effect sizes and confidence intervals rather than qualitative statements.
Simulated Author's Rebuttal
Thank you for the detailed review of our manuscript. We address the major comments below, clarifying our approach and outlining revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Unified Latent Probe definition] The central Information-Performance Binding claim (abstract and experiments section) rests on ULP providing an unbiased, architecture- and optimizer-independent estimate of mutual information. No derivation or ablation is supplied showing that the probe's MI estimate remains stable across model families, sampling strategies for trajectories, or variational estimator choices; any dependence would render the reported correlation an artifact of the measurement tool rather than evidence of the proposed mechanism.
Authors: We thank the referee for highlighting this important aspect of our claims. The ULP employs established variational bounds for mutual information estimation, and our experimental results demonstrate the Information-Performance Binding consistently across the evaluated settings. To address concerns about estimator dependence, we will include in the revised manuscript additional ablations varying the variational estimator and trajectory sampling strategies, along with a brief derivation of the probe's properties. This will substantiate the robustness of the binding observation. revision: partial
-
Referee: [Methods / Supervision decomposition] The decomposition of supervision into Trajectory Supervision and Space Supervision (methods section) is presented as complementary, yet the paper supplies no quantitative separation (e.g., controlled ablations isolating each component's contribution to the MI term or to downstream accuracy) that would establish the decomposition as load-bearing rather than descriptive.
Authors: The decomposition arises directly from our information-theoretic analysis of the dual collapse phenomenon, distinguishing between optimization-path issues (addressed by Trajectory Supervision) and latent-space drift (addressed by Space Supervision). While the main experiments focus on their joint application, we agree that isolating their effects would strengthen the presentation. In the revision, we will add controlled ablations that separately apply each supervision type and measure their impact on both mutual information and reasoning accuracy. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract introduces ULP as a new probe for mutual information and reports an experimental Information-Performance Binding, but provides no equations, fitted parameters renamed as predictions, or self-citations that reduce the central claims to their own inputs by construction. No load-bearing step matches any enumerated circularity pattern; the analysis remains an independent information-theoretic framing with a proposed measurement tool.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual information is a valid and sufficient measure of semantic fidelity between latent trajectories and explicit reasoning steps
invented entities (4)
-
Dual collapse
no independent evidence
-
Trajectory Supervision
no independent evidence
-
Space Supervision
no independent evidence
-
Unified Latent Probe (ULP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
A Survey of Large Language Models , author=. 2025 , eprint=
2025
-
[2]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[3]
2025 , eprint=
Reasoning in the Dark: Interleaved Vision-Text Reasoning in Latent Space , author=. 2025 , eprint=
2025
-
[4]
Transactions on Machine Learning Research , issn=
Efficient Reasoning Models: A Survey , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[5]
2025 , eprint=
Emergence of Superposition: Unveiling the Training Dynamics of Chain of Continuous Thought , author=. 2025 , eprint=
2025
-
[6]
Soft Thinking: Unlocking the Reasoning Potential of
Zhen Zhang and Xuehai He and Weixiang Yan and Ao Shen and Chenyang Zhao and Xin Eric Wang , booktitle=. Soft Thinking: Unlocking the Reasoning Potential of. 2025 , url=
2025
-
[7]
Nature , volume =
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , title =. Nature , volume =. 2025 , doi =
2025
-
[8]
2025 , eprint=
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models , author=. 2025 , eprint=
2025
-
[9]
Second Conference on Language Modeling , year=
Training Large Language Models to Reason in a Continuous Latent Space , author=. Second Conference on Language Modeling , year=
-
[10]
2025 , eprint=
Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Implicit Reasoning in Large Language Models: A Comprehensive Survey , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint=
Dynamics Within Latent Chain-of-Thought: An Empirical Study of Causal Structure , author=. 2026 , eprint=
2026
-
[13]
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Chen, Xinghao and Sun, Zhijing and Wenjin, Guo and Zhang, Miaoran and Chen, Yanjun and Sun, Yirong and Su, Hui and Pan, Yijie and Klakow, Dietrich and Li, Wenjie and Shen, Xiaoyu. Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.782
-
[14]
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
Yao, Yuekun and Du, Yupei and Zhu, Dawei and Hahn, Michael and Koller, Alexander. Language models can learn implicit multi-hop reasoning, but only if they have lots of training data. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.490
-
[15]
2024 , eprint=
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step , author=. 2024 , eprint=
2024
-
[16]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[17]
2025 , eprint=
SIM-CoT: Supervised Implicit Chain-of-Thought , author=. 2025 , eprint=
2025
-
[18]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[19]
2026 , eprint=
Parallel Test-Time Scaling for Latent Reasoning Models , author=. 2026 , eprint=
2026
-
[20]
2025 , eprint=
Soft Tokens, Hard Truths , author=. 2025 , eprint=
2025
-
[21]
The Eleventh International Conference on Learning Representations , year=
Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought , author=. The Eleventh International Conference on Learning Representations , year=
-
[22]
2022 , url=
A Path Towards Autonomous Machine Intelligence , author=. 2022 , url=
2022
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
2026 , eprint=
LLM Latent Reasoning as Chain of Superposition , author=. 2026 , eprint=
2026
-
[25]
ArXiv , year=
Latent Chain-of-Thought for Visual Reasoning , author=. ArXiv , year=
-
[26]
Shannon, C. E. , journal=. A mathematical theory of communication , year=
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[28]
2025 , eprint=
Latent Collaboration in Multi-Agent Systems , author=. 2025 , eprint=
2025
-
[29]
Think Silently, Think Fast: Dynamic Latent Compression of
Wenhui Tan and Jiaze Li and Jianzhong Ju and Zhenbo Luo and Ruihua Song and Jian Luan , booktitle=. Think Silently, Think Fast: Dynamic Latent Compression of. 2025 , url=
2025
-
[30]
2024 , eprint=
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations , author=. 2024 , eprint=
2024
-
[31]
2023 , eprint=
Implicit Chain of Thought Reasoning via Knowledge Distillation , author=. 2023 , eprint=
2023
-
[32]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[33]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[34]
Advances in Neural Information Processing Systems , editor=
Gradient Starvation: A Learning Proclivity in Neural Networks , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[35]
What Happened in LLM s Layers when Trained for Fast vs
Li, Ming and Li, Yanhong and Zhou, Tianyi. What Happened in LLM s Layers when Trained for Fast vs. Slow Thinking: A Gradient Perspective. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1545
-
[36]
CODI : Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Shen, Zhenyi and Yan, Hanqi and Zhang, Linhai and Hu, Zhanghao and Du, Yali and He, Yulan. CODI : Compressing Chain-of-Thought into Continuous Space via Self-Distillation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.36
-
[37]
39th Conference on Neural Information Processing Systems (NeurIPS 2025) , year=
SemCoT: Accelerating Chain-of-Thought Reasoning through Semantically-Aligned Implicit Tokens , author=. 39th Conference on Neural Information Processing Systems (NeurIPS 2025) , year=
2025
-
[38]
2025 , eprint=
Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
KaVa: Latent Reasoning via Compressed KV-Cache Distillation , author=. 2025 , eprint=
2025
-
[40]
2025 , eprint=
SpiralThinker: Latent Reasoning through an Iterative Process with Text-Latent Interleaving , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
Exploring System 1 and 2 communication for latent reasoning in LLMs , author=. 2025 , eprint=
2025
-
[42]
2025 , eprint=
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs , author=. 2025 , eprint=
2025
-
[43]
Understanding Chain-of-Thought in
Jean-Francois Ton and Muhammad Faaiz Taufiq and Yang Liu , booktitle=. Understanding Chain-of-Thought in. 2025 , url=
2025
-
[44]
2025 , eprint=
A Formal Comparison Between Chain-of-Thought and Latent Thought , author=. 2025 , eprint=
2025
-
[45]
Analyzing Chain-of-thought Prompting in Black-Box Large Language Models via Estimated V -information
Wang, Zecheng and Li, Chunshan and Yang, Zhao and Liu, Qingbin and Hao, Yanchao and Chen, Xi and Chu, Dianhui and Sui, Dianbo. Analyzing Chain-of-thought Prompting in Black-Box Large Language Models via Estimated V -information. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COL...
2024
-
[46]
The Twelfth International Conference on Learning Representations , year=
Think before you speak: Training Language Models With Pause Tokens , author=. The Twelfth International Conference on Learning Representations , year=
-
[47]
First Conference on Language Modeling , year=
Guiding Language Model Reasoning with Planning Tokens , author=. First Conference on Language Modeling , year=
-
[48]
Bowman , booktitle=
Jacob Pfau and William Merrill and Samuel R. Bowman , booktitle=. Let. 2024 , url=
2024
-
[49]
2025 , eprint=
Meaningless Tokens, Meaningful Gains: How Activation Shifts Enhance LLM Reasoning , author=. 2025 , eprint=
2025
-
[50]
2025 , eprint=
Parallel Continuous Chain-of-Thought with Jacobi Iteration , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
Hybrid Latent Reasoning via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
Do LLMs Really Think Step-by-step In Implicit Reasoning? , author=. 2025 , eprint=
2025
-
[53]
Implicit Reasoning in Transformers is Reasoning through Shortcuts
Lin, Tianhe and Xie, Jian and Yuan, Siyu and Yang, Deqing. Implicit Reasoning in Transformers is Reasoning through Shortcuts. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.493
-
[54]
2025 , eprint=
Hierarchical Reasoning Model , author=. 2025 , eprint=
2025
-
[55]
2025 , eprint=
Less is More: Recursive Reasoning with Tiny Networks , author=. 2025 , eprint=
2025
-
[56]
2025 , eprint=
Scaling Latent Reasoning via Looped Language Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.