BIM-Edit: Benchmarking Large Language Models for IFC-Based Building Information Modeling
Pith reviewed 2026-06-26 17:39 UTC · model grok-4.3
The pith
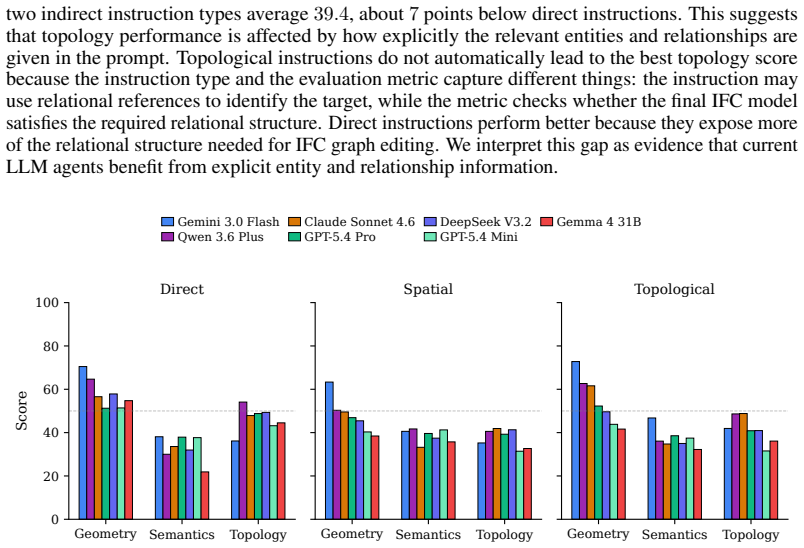
Large language models achieve at most 49.5 percent average score when editing building information models in IFC format.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
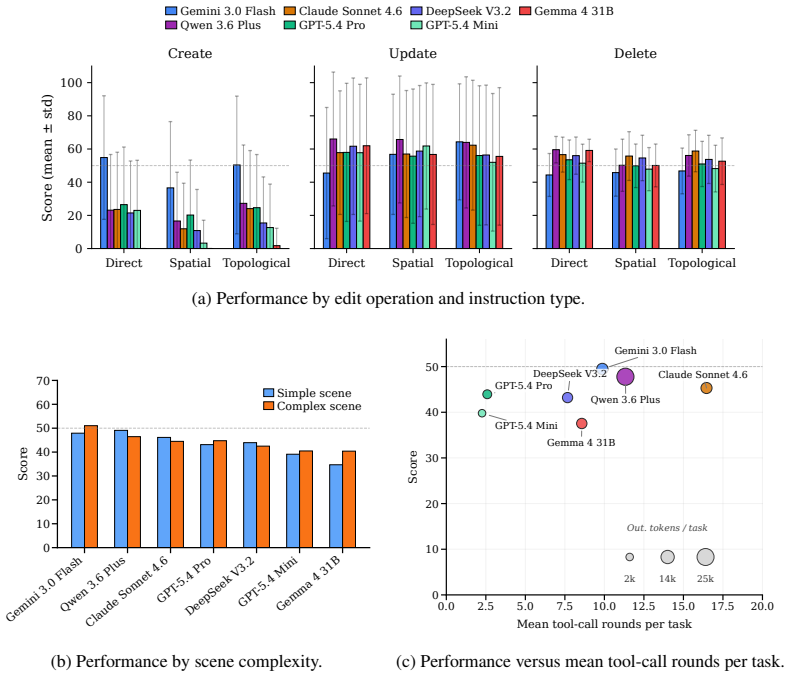
BIM-Edit demonstrates that current LLMs cannot reliably edit IFC-based building models while maintaining geometric accuracy, semantic validity, and topological consistency. No evaluated model fully solves more than 3.4 percent of the 324 tasks, and the highest average score across metrics is 49.5 percent.
What carries the argument
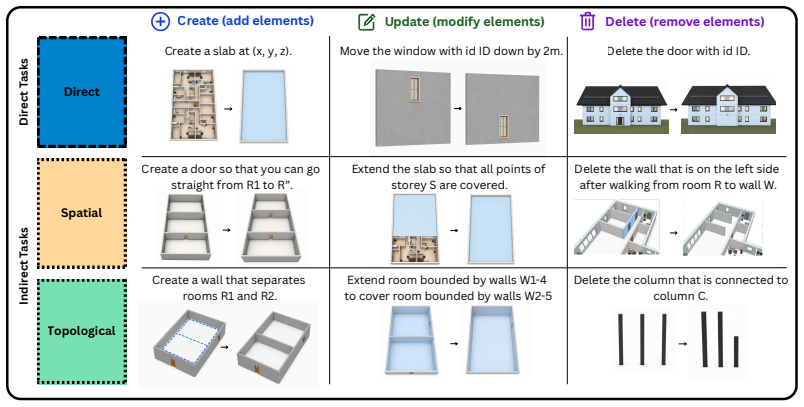
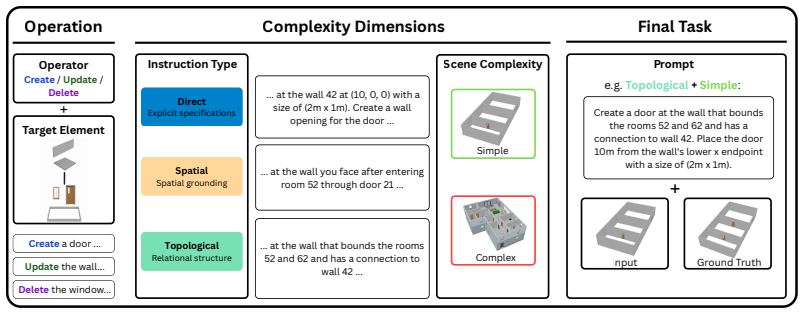
The BIM-Edit benchmark, consisting of 324 tasks from 11 realistic models and 36 synthetic scenes in three instruction categories, evaluated along geometric accuracy, semantic validity, and topological consistency.
If this is right
- LLMs require substantial improvements to handle the relational and semantic structure of BIM models.
- Current models are insufficient for production use in engineering design workflows.
- Future LLM development for CAD should prioritize preserving topology and semantics in edits.
- Benchmarks like BIM-Edit can guide progress toward reliable model editing capabilities.
Where Pith is reading between the lines
- Integrating LLMs with specialized BIM tools or structured data parsers might bridge the performance gap.
- Training on larger IFC datasets could improve performance on topological consistency.
- Real-world BIM editing often involves iterative changes; this benchmark could be extended to multi-turn interactions.
- The gap suggests that hybrid systems combining LLMs with rule-based validation are needed for practical applications.
Load-bearing premise
The 324 tasks drawn from realistic and synthetic scenes represent the full range of editing demands in actual BIM engineering practice.
What would settle it
An LLM that achieves over 80 percent average score across the three metrics and fully solves more than 10 percent of the tasks would indicate the gap is smaller than claimed.
Figures



read the original abstract
Large language models (LLMs) are increasingly applied to computer-aided design (CAD) to generate design artifacts from textual instructions. In engineering practice, this requires more than creating new geometry, models must also understand existing scenes, edit them correctly, and preserve semantics and relations. However, many CAD benchmarks focus on creating new models rather than editing existing ones, and mostly evaluate geometric correctness. We introduce BIM-Edit, a benchmark for evaluating LLMs on natural-language editing of Building Information Models (BIM) represented in the Industry Foundation Classes (IFC) format. BIM provides a challenging testbed because building models encode geometry together with semantic and relational structure. BIM-Edit contains 324 editing tasks spanning 11 realistic building models and 36 synthetic scenes. Tasks are expressed using three instruction categories - direct, spatial, and topological - covering both explicit and scene-grounded edits. We evaluate outputs along three dimensions: geometric accuracy, semantic validity, and topological consistency. Across evaluated LLMs, the best-performing model achieves only 49.5% average score across the three metrics, and no model fully solves more than 3.4% of tasks. These results demonstrate a substantial gap between current LLM capabilities and the requirements of structured engineering design workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BIM-Edit, a benchmark for evaluating LLMs on natural-language editing of IFC-based Building Information Models. It comprises 324 tasks drawn from 11 realistic building models and 36 synthetic scenes, partitioned into direct, spatial, and topological instruction categories. Outputs are scored on three dimensions—geometric accuracy, semantic validity, and topological consistency—with results showing the strongest model at 49.5% average across metrics and no model fully solving more than 3.4% of tasks, from which the authors conclude a substantial gap between current LLM capabilities and structured engineering design workflows.
Significance. If the task set is representative of real BIM editing demands, the benchmark would constitute a useful contribution by extending CAD evaluation beyond pure geometric generation to include semantic and relational constraints; the three-dimensional scoring and mix of realistic/synthetic scenes are positive design choices. The work supplies concrete empirical measurements rather than fitted parameters or self-referential definitions.
major comments (2)
- [Abstract / §1] Abstract and opening claim: the assertion that the 49.5% average and ≤3.4% full-solve rates demonstrate a 'substantial gap' between LLMs and 'the requirements of structured engineering design workflows' is load-bearing on the premise that the 324 tasks are representative of actual BIM practice; the manuscript supplies no external anchor such as comparison against industry edit logs, frequency statistics from real projects, or expert ratings of task realism and coverage (see also the description of task construction).
- [§3] §3 (Benchmark Construction) and evaluation protocol: without reported details on how the 11 realistic models and 36 synthetic scenes were selected or on any data-exclusion rules, it is impossible to assess whether the reported performance gap could be an artifact of atypical task complexity or distribution rather than a general capability limitation.
minor comments (2)
- [Abstract] The abstract states concrete performance numbers yet does not define the precise aggregation formula for the 'average score across the three metrics'; a short clarification would improve reproducibility.
- [Tables/Figures] Figure or table captions describing the 324 tasks could explicitly list the per-category counts (direct/spatial/topological) to allow readers to judge balance without consulting the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments and indicate the revisions planned for the next manuscript version.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and opening claim: the assertion that the 49.5% average and ≤3.4% full-solve rates demonstrate a 'substantial gap' between LLMs and 'the requirements of structured engineering design workflows' is load-bearing on the premise that the 324 tasks are representative of actual BIM practice; the manuscript supplies no external anchor such as comparison against industry edit logs, frequency statistics from real projects, or expert ratings of task realism and coverage (see also the description of task construction).
Authors: The 324 tasks were constructed from common BIM editing operations (direct, spatial, and topological) using 11 models drawn from real building projects and 36 synthetic scenes designed to isolate specific reasoning demands. We agree that the manuscript lacks external anchors such as industry edit-log comparisons or expert realism ratings. In the revision we will expand the task-construction description and add an explicit limitations paragraph that qualifies the 'substantial gap' claim, notes the absence of such anchors, and identifies industry validation as future work. This provides a more measured framing without altering the empirical results. revision: partial
-
Referee: [§3] §3 (Benchmark Construction) and evaluation protocol: without reported details on how the 11 realistic models and 36 synthetic scenes were selected or on any data-exclusion rules, it is impossible to assess whether the reported performance gap could be an artifact of atypical task complexity or distribution rather than a general capability limitation.
Authors: We will revise §3 to supply the requested details: the 11 realistic models were selected from public IFC repositories to span residential, commercial, and institutional building types with varying sizes and complexities; the 36 synthetic scenes were procedurally generated to systematically vary geometric density, semantic label diversity, and relational depth. We will also document the exclusion rules applied during task creation (e.g., removal of ill-defined or degenerate edits). These additions will allow readers to evaluate whether the observed performance distribution is representative. revision: yes
Circularity Check
No circularity: direct empirical measurements on fixed benchmark tasks
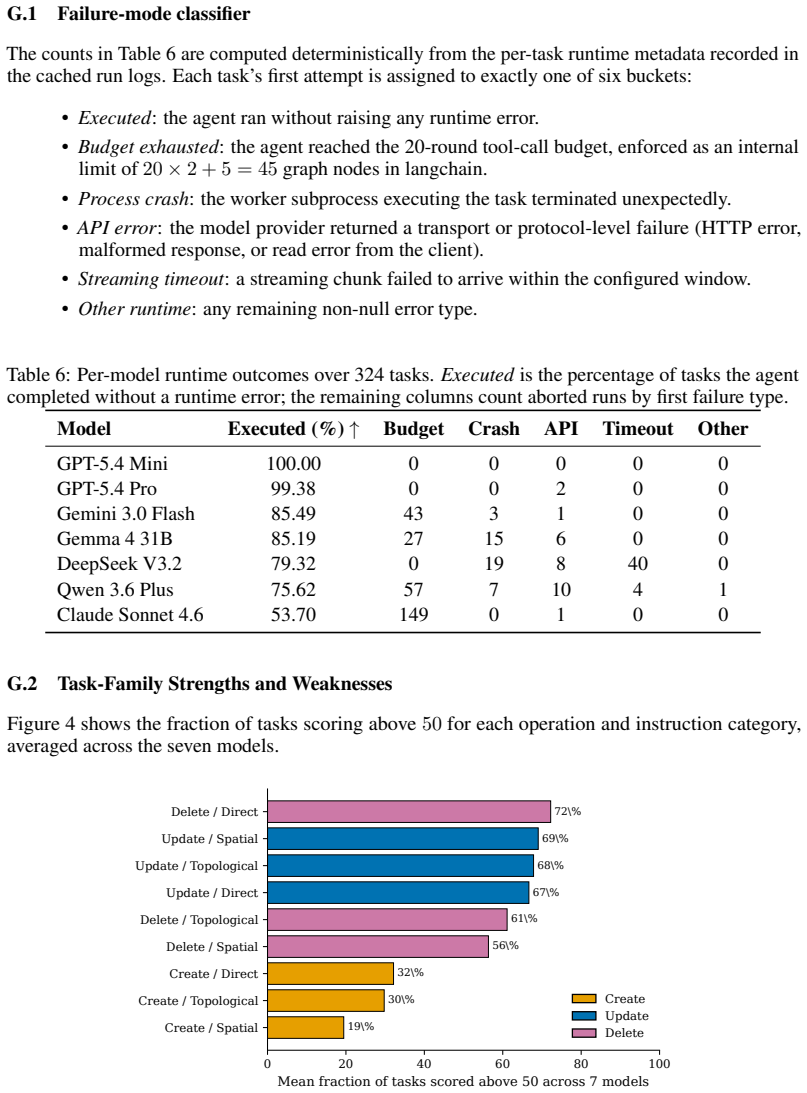
full rationale
The paper introduces BIM-Edit with 324 tasks across 11 realistic models and 36 synthetic scenes, evaluates LLMs on geometric accuracy, semantic validity, and topological consistency, and reports direct performance numbers (49.5% best average, ≤3.4% full solves). These figures are obtained by running models on the tasks and scoring outputs against the defined metrics; no equations, fitted parameters, self-definitional relations, or load-bearing self-citations reduce the results to the inputs by construction. The representativeness of the task set is an external assumption about coverage of real BIM practice but does not create circularity in the reported scores or derivation chain, which remains self-contained empirical evaluation.
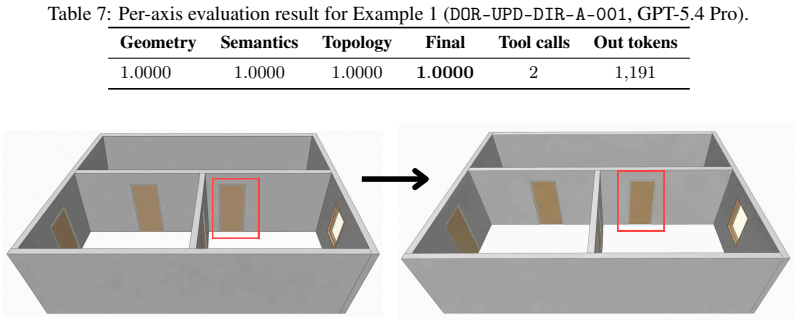
Axiom & Free-Parameter Ledger
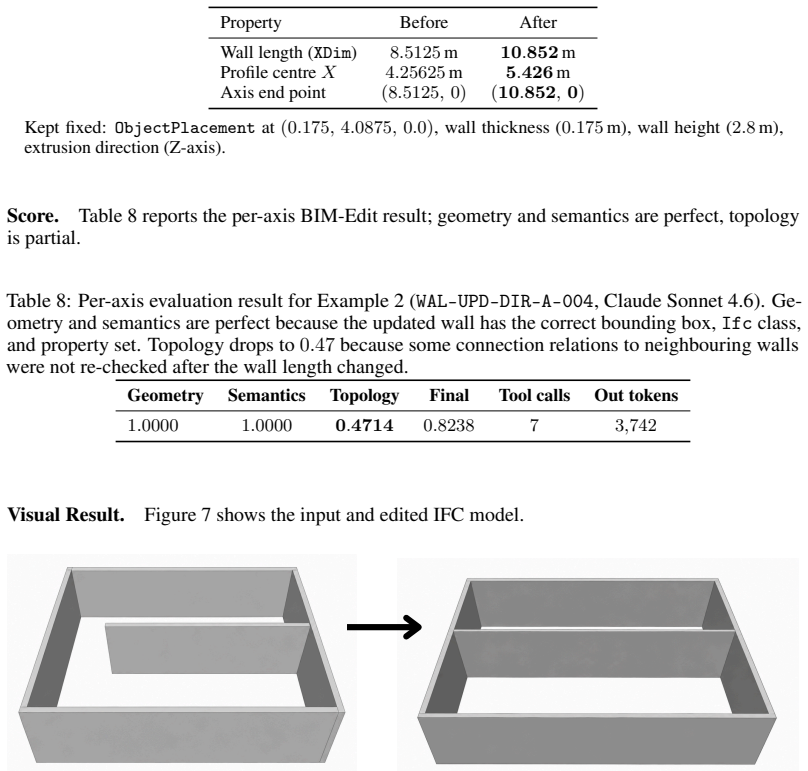
axioms (2)
- domain assumption The chosen 11 realistic building models and 36 synthetic scenes, together with the three instruction categories, adequately sample the space of realistic BIM editing requests.
- domain assumption Geometric accuracy, semantic validity, and topological consistency are the three most important dimensions for judging the correctness of an IFC edit.
Reference graph
Works this paper leans on
-
[1]
ScanQA: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. ScanQA: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022
2022
-
[2]
Engineering design: a systematic approach.Mrs Bulletin, 71 (30):3, 1996
W Beitz, G Pahl, and K Grote. Engineering design: a systematic approach.Mrs Bulletin, 71 (30):3, 1996
1996
-
[3]
Industry foundation classes: A standardized data model for the vendor-neutral exchange of digital building models
André Borrmann, Jakob Beetz, Christian Koch, Thomas Liebich, and Sergej Muhic. Industry foundation classes: A standardized data model for the vendor-neutral exchange of digital building models. InBuilding information modeling: Technology foundations and industry practice, pages 81–126. Springer, 2018
2018
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Cadcrafter: Generating computer-aided design models from unconstrained images
Cheng Chen, Jiacheng Wei, Tianrun Chen, Chi Zhang, Xiaofeng Yang, Shangzhan Zhang, Bingchen Yang, Chuan-Sheng Foo, Guosheng Lin, Qixing Huang, et al. Cadcrafter: Generating computer-aided design models from unconstrained images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11073–11082, 2025
2025
-
[6]
Liguo Chen, Qi Guo, Hongrui Jia, Zhengran Zeng, Xin Wang, Yijiang Xu, Jian Wu, Yidong Wang, Qing Gao, Jindong Wang, et al. A survey on evaluating large language models in code generation tasks.arXiv preprint arXiv:2408.16498, 2024
-
[7]
Recent progress, challenges and outlook for multidisciplinary structural optimization of aircraft and aerial vehicles.Progress in Aerospace Sciences, 135:100861, 2022
G Corrado, G Ntourmas, M Sferza, N Traiforos, A Arteiro, L Brown, D Chronopoulos, F Daoud, F Glock, J Ninic, et al. Recent progress, challenges and outlook for multidisciplinary structural optimization of aircraft and aerial vehicles.Progress in Aerospace Sciences, 135:100861, 2022
2022
-
[8]
Zihan Deng, Changyu Du, Stavros Nousias, and André Borrmann. BIMgent: Towards au- tonomous building modeling via computer-use agents.arXiv preprint arXiv:2506.07217, 2025
-
[9]
Text2BIM: Generat- ing building models using a large language model-based multiagent framework.Journal of Computing in Civil Engineering, 40(2):04025142, 2026
Changyu Du, Sebastian Esser, Stavros Nousias, and André Borrmann. Text2BIM: Generat- ing building models using a large language model-based multiagent framework.Journal of Computing in Civil Engineering, 40(2):04025142, 2026
2026
-
[10]
Yuhao Du, Shunian Chen, Wenbo Zan, Peizhao Li, Mingxuan Wang, Dingjie Song, Bo Li, Yan Hu, and Benyou Wang. BlenderLLM: Training large language models for computer-aided design with self-improvement.arXiv preprint arXiv:2412.14203, 2024
-
[11]
Transcad: A hierarchical transformer for cad sequence inference from point clouds
Elona Dupont, Kseniya Cherenkova, Dimitrios Mallis, Gleb Gusev, Anis Kacem, and Djamila Aouada. Transcad: A hierarchical transformer for cad sequence inference from point clouds. In European Conference on Computer Vision, pages 19–36. Springer, 2024
2024
-
[12]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 605–613, 2017
2017
-
[13]
A gpt-powered assistant for real-time interaction with building information models.Buildings, 14(8):2499, 2024
David Fernandes, Sahej Garg, Matthew Nikkel, and Gursans Guven. A gpt-powered assistant for real-time interaction with building information models.Buildings, 14(8):2499, 2024
2024
-
[14]
GIFT: Bootstrapping image-to-cad program synthesis via geometric feedback
Giorgio Giannone, Anna Clare Doris, Amin Heyrani Nobari, Kai Xu, Akash Srivastava, and Faez Ahmed. GIFT: Bootstrapping image-to-cad program synthesis via geometric feedback. arXiv preprint arXiv:2603.27448, 2026. 10
-
[15]
On the effectiveness of large language models in domain-specific code generation.ACM Transactions on Software Engineering and Methodology, 34(3):1–22, 2025
Xiaodong Gu, Meng Chen, Yalan Lin, Yuhan Hu, Hongyu Zhang, Chengcheng Wan, Zhao Wei, Yong Xu, and Juhong Wang. On the effectiveness of large language models in domain-specific code generation.ACM Transactions on Software Engineering and Methodology, 34(3):1–22, 2025
2025
-
[16]
BlenderGym: bench- marking foundational model systems for graphics editing
Yunqi Gu, Ian Huang, Jihyeon Je, Guandao Yang, and Leonidas Guibas. BlenderGym: bench- marking foundational model systems for graphics editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18574–18583, 2025
2025
-
[17]
CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward
Yandong Guan, Xilin Wang, Ximing Xing, Jing Zhang, Dong Xu, and Qian Yu. CAD- Coder: Text-to-cad generation with chain-of-thought and geometric reward.arXiv preprint arXiv:2505.19713, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
SCOPE: Spatially-constrained parametric editing for text-guided cad models.Efficient Spatial Reasoning Workshop at ICLR, 2026
Md Zahid Hasan and Soumalya Sarkar. SCOPE: Spatially-constrained parametric editing for text-guided cad models.Efficient Spatial Reasoning Workshop at ICLR, 2026
2026
-
[19]
Natural language information retrieval from bim models: An llm-based multi-agent system approach
Sylvain Hellin, Stavros Nousias, and André Borrmann. Natural language information retrieval from bim models: An llm-based multi-agent system approach. InEC3 Conference 2025, volume 6. European Council on Computing in Construction, 2025
2025
-
[20]
IfcOpenShell: The open source ifc toolkit and geometry engine
IfcOpenShell Contributors. IfcOpenShell: The open source ifc toolkit and geometry engine. https://ifcopenshell.org/, 2026. Accessed: 2026-05-05
2026
-
[21]
International Organization for Standardization. ISO 16739-1:2024 industry foundation classes (ifc) for data sharing in the construction and facility management industries – part 1: Data schema.https://www.iso.org/standard/84123.html, 2024. Accessed: 2026-05-05
2024
-
[22]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contam- ination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Automated detailing of exterior walls using nadia: Natural-language-based architectural detailing through interaction with ai.Advanced Engineering Informatics, 61:102532, 2024
Suhyung Jang, Ghang Lee, Jiseok Oh, Junghun Lee, and Bonsang Koo. Automated detailing of exterior walls using nadia: Natural-language-based architectural detailing through interaction with ai.Advanced Engineering Informatics, 61:102532, 2024
2024
-
[24]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Text2CAD: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
Mohammad S Khan, Sankalp Sinha, Talha U Sheikh, Didier Stricker, Sk A Ali, and Muham- mad Z Afzal. Text2CAD: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
2024
-
[26]
QueryCAD: Grounded question answering for cad models
Claudius Kienle, Benjamin Alt, Darko Katic, Rainer Jäkel, and Jan Peters. QueryCAD: Grounded question answering for cad models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5798–5805. IEEE, 2025
2025
-
[27]
ABC: A big cad model dataset for geometric deep learning
Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, Denis Zorin, and Daniele Panozzo. ABC: A big cad model dataset for geometric deep learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9601–9611, 2019
2019
-
[28]
Harold W. Kuhn. The Hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1–2):83–97, 1955
1955
-
[29]
CAD-Llama: leveraging large language models for computer-aided design parametric 3d model generation
Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, and Xiangdong Zhou. CAD-Llama: leveraging large language models for computer-aided design parametric 3d model generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18563–18573, 2025
2025
-
[30]
LLM4CAD: Multi-modal large language models for 3d computer-aided design generation
Xingang Li, Yuewan Sun, and Zhenghui Sha. LLM4CAD: Multi-modal large language models for 3d computer-aided design generation. InInternational Design Engineering Technical Conferences and Computers and Information in Engineering Conference, volume 88407, page V006T06A015. American Society of Mechanical Engineers, 2024. 11
2024
-
[31]
BIMCoder: A comprehensive large language model fusion framework for natural language-based bim information retrieval.Applied Sciences, 15(14): 7647, 2025
Bingru Liu and Hainan Chen. BIMCoder: A comprehensive large language model fusion framework for natural language-based bim information retrieval.Applied Sciences, 15(14): 7647, 2025
2025
-
[32]
Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yinan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. Can multimodal large language models understand spatial relations? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 620–632, 2025
2025
-
[33]
3DSRBench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3DSRBench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025
2025
-
[34]
Multidisciplinary design optimization: a survey of architectures.AIAA journal, 51(9):2049–2075, 2013
Joaquim RRA Martins and Andrew B Lambe. Multidisciplinary design optimization: a survey of architectures.AIAA journal, 51(9):2049–2075, 2013
2049
-
[35]
Building foundation models-potentials, challenges and research directions for using llm and lvm in aec
Joern Ploennigs, Markus Berger, Thomas Wortmann, Jakob Kirchner, Jakob Beetz, Alina Roitberg, Karsten Menzel, and Björn Ommer. Building foundation models-potentials, challenges and research directions for using llm and lvm in aec. InEC3 Conference 2025, volume 6. European Council on Computing in Construction, 2025
2025
-
[36]
A statistical tolerance analysis approach for over-constrained mechanism based on optimization and monte carlo simulation.Computer-Aided Design, 44(2):132–142, 2012
Ahmed Jawad Qureshi, Jean-Yves Dantan, Vahid Sabri, Paul Beaucaire, and Nicolas Gayton. A statistical tolerance analysis approach for over-constrained mechanism based on optimization and monte carlo simulation.Computer-Aided Design, 44(2):132–142, 2012
2012
-
[37]
Vitruvion: A generative model of parametric cad sketches.arXiv preprint arXiv:2109.14124, 2021
Ari Seff, Wenda Zhou, Nick Richardson, and Ryan P Adams. Vitruvion: A generative model of parametric cad sketches.arXiv preprint arXiv:2109.14124, 2021
-
[38]
Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to-cad generation through infusing visual feedback in large language models.arXiv preprint arXiv:2501.19054, 2025
-
[39]
From 2d cad drawings to 3d parametric models: A vision-language approach
Xilin Wang, Jia Zheng, Yuanchao Hu, Hao Zhu, Qian Yu, and Zihan Zhou. From 2d cad drawings to 3d parametric models: A vision-language approach. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7961–7969, 2025
2025
-
[40]
A framework for generic semantic enrichment of bim models.Journal of Computing in Civil Engineering, 38 (1):04023038, 2024
Zijian Wang, Rafael Sacks, Boyuan Ouyang, Huaquan Ying, and André Borrmann. A framework for generic semantic enrichment of bim models.Journal of Computing in Civil Engineering, 38 (1):04023038, 2024
2024
-
[41]
Text-to-code generation for modular building layouts in building information modeling
Yinyi Wei and Xiao Li. Text-to-code generation for modular building layouts in building information modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[42]
Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences.ACM Transactions on Graphics (TOG), 40(4):1–24, 2021
Karl DD Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences.ACM Transactions on Graphics (TOG), 40(4):1–24, 2021
2021
-
[43]
Deepcad: A deep generative network for computer- aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer- aided design models. InProceedings of the IEEE/CVF international conference on computer vision, pages 6772–6782, 2021
2021
-
[44]
Luyu Yang, Yutong Dai, An Yan, Viraj Prabhu, Ran Xu, and Zeyuan Chen. How far are vision-language models from constructing the real world? a benchmark for physical generative reasoning.arXiv preprint arXiv:2603.24866, 2026. doi: 10.48550/arXiv.2603.24866. URL https://arxiv.org/abs/2603.24866
-
[45]
Yu Yuan, Shizhao Sun, Qi Liu, and Jiang Bian. CAD-Editor: A locate-then-infill framework with automated training data synthesis for text-based cad editing.arXiv preprint arXiv:2502.03997, 2025
-
[46]
Large language models for computer-aided design: A survey.ACM Computing Surveys, 58(9):1–39, 2026
Licheng Zhang, Bach Le, Naveed Akhtar, Siew-Kei Lam, and Duc Ngo. Large language models for computer-aided design: A survey.ACM Computing Surveys, 58(9):1–39, 2026. 12
2026
-
[47]
Weichen Zhang, Zile Zhou, Xin Zeng, Xuchen Liu, Jianjie Fang, Chen Gao, Yong Li, Jin- qiang Cui, Xinlei Chen, and Xiao-Ping Zhang. Open3D-VQA: A benchmark for comprehen- sive spatial reasoning with multimodal large language model in open space.arXiv preprint arXiv:2503.11094, 2025
-
[48]
Junwen Zheng and Martin Fischer. BIM-GPT: A prompt-based virtual assistant framework for bim information retrieval.arXiv preprint arXiv:2304.09333, 2023. 13 A Limitations BIM-Edit makes several choices that should be considered when interpreting the results. First of all, each task uses a single human-authored ground-truth IFC model. This makes scoring de...
-
[49]
proposed a benchmark for evaluating the physical plausibility of 3D house generation using Vision-Language Model (VLM) agents. Although their setting focuses on reconstructing houses from images, the benchmark is closely related to our work because it evaluates not only geometric reconstruction quality, but also physical constraints such as the structural...
-
[50]
For example, a predicted IfcWall matched to a reference IfcWall receives 1.0, while a predicted IfcSlab or a proxy element matched to a reference IfcWall receives 0.0
Class score: The score is 1.0 if the class type of c′ n matches the IFC class of n∗ n, and 0.0 otherwise. For example, a predicted IfcWall matched to a reference IfcWall receives 1.0, while a predicted IfcSlab or a proxy element matched to a reference IfcWall receives 0.0
-
[51]
Property score: The score is the fraction of task-relevant property keys whose values ina ′ n match the corresponding values in n∗ n within a relative tolerance of 5%. The properties Tag, Description, andLongNameare excluded from this comparison. The per-pair semantic score is the average of the class score and the property score. The task-level semantic ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.