HilDA: Hierarchical Distillation with Diffusion for Advancing Self-Supervised LiDAR Pre-training
Pith reviewed 2026-06-26 18:04 UTC · model grok-4.3
The pith
HilDA pre-trains LiDAR backbones by distilling multi-layer semantics and global context from vision models plus a temporal occupancy diffusion task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
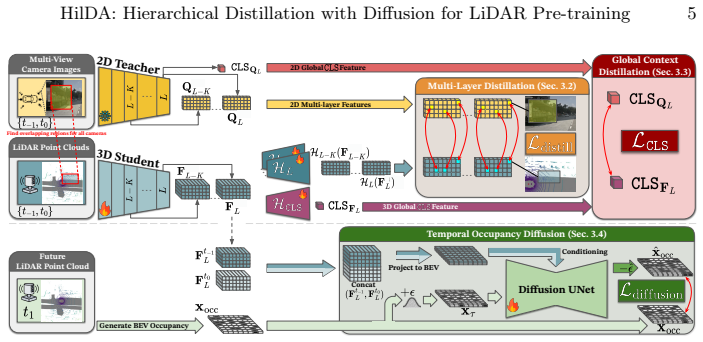
HilDA is a self-supervised pretraining framework for LiDAR backbones that combines hierarchical distillation—multi-layer distillation for progressive semantic alignment and global context distillation for scene-level semantics—with a temporal occupancy diffusion objective to promote spatiotemporal consistency, thereby capturing the semantic what and geometric where needed for downstream driving tasks.
What carries the argument
Hierarchical distillation (multi-layer plus global context) paired with a temporal occupancy diffusion objective.
If this is right
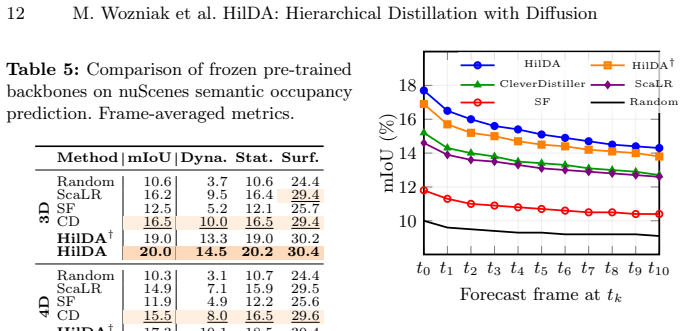
- Models pre-trained with HilDA reach state-of-the-art numbers on cross-modal distillation benchmarks.
- They outperform earlier distillation methods on 3D object detection.
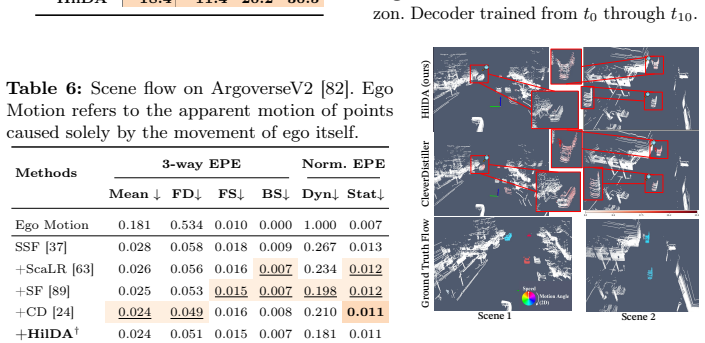
- They improve results on scene flow estimation.
- They raise performance on semantic occupancy prediction.
Where Pith is reading between the lines
- The same hierarchical-plus-diffusion pattern could be tested on other unpaired sensor pairs such as radar-to-camera.
- Adding an explicit rigid-body transform step inside the distillation pipeline might further reduce the modality gap the current method leaves implicit.
- The diffusion objective on occupancy could be replaced by other generative consistency losses to isolate which component drives the reported gains.
Load-bearing premise
Semantic structures and global context extracted from vision foundation models transfer usefully to raw LiDAR geometry without explicit coordinate-frame alignment or special treatment of modality-specific noise.
What would settle it
A controlled experiment in which LiDAR backbones pre-trained with HilDA show no accuracy gain over prior distillation baselines on standard 3D object detection or scene-flow benchmarks would falsify the central claim.
Figures
read the original abstract
Leveraging Vision Foundation Models (VFMs) for camera-to-LiDAR knowledge distillation offers a promising solution to the scarcity of annotated data needed to represent the immense geometric and kinematic diversity of real-world autonomous driving (AD). However, current approaches typically treat VFMs as black-box teachers, relying exclusively on frame-wise feature similarity. Consequently, they do not fully exploit the teacher's layer-wise semantic structure and global context, as well as the rich spatiotemporal information inherent in LiDAR sequences. We propose HilDA, a self-supervised pretraining framework for LiDAR backbones that better captures the semantic what and geometric where needed for driving tasks. HilDA combines hierarchical distillation comprising multi-layer distillation for progressive semantic alignment and global context distillation for scene-level semantics, with a temporal occupancy diffusion objective promoting spatiotemporal consistency. Models pre-trained with HilDA achieve state-of-the-art results on cross-modal distillation benchmarks and outperform models trained via prior distillation approaches on 3D object detection, scene flow, and semantic occupancy prediction. Code available at: https://maxiuw.github.io/hilda.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HilDA, a self-supervised pre-training framework for LiDAR backbones that performs hierarchical distillation from vision foundation models (VFMs). It combines multi-layer distillation for progressive semantic alignment, global context distillation for scene-level semantics, and a temporal occupancy diffusion objective for spatiotemporal consistency. The central claim is that models pre-trained with HilDA achieve state-of-the-art results on cross-modal distillation benchmarks and outperform prior distillation methods on downstream tasks including 3D object detection, scene flow, and semantic occupancy prediction.
Significance. If the empirical claims hold after addressing the noted concerns, the work would meaningfully advance self-supervised LiDAR pre-training by more fully exploiting layer-wise structure and global context from VFMs rather than treating them as black boxes. The public code release is a clear strength that supports reproducibility and follow-up work.
major comments (2)
- [Abstract, §3] Abstract and §3 (Hierarchical Distillation): The transfer of layer-wise semantic structure and global context is described as relying on feature similarity alone, with no explicit treatment of camera-LiDAR coordinate frame calibration, projection geometry, or modality-specific noise (sparsity, range-dependent density). This assumption is load-bearing for the cross-modal distillation claim; without it, performance gains may not generalize.
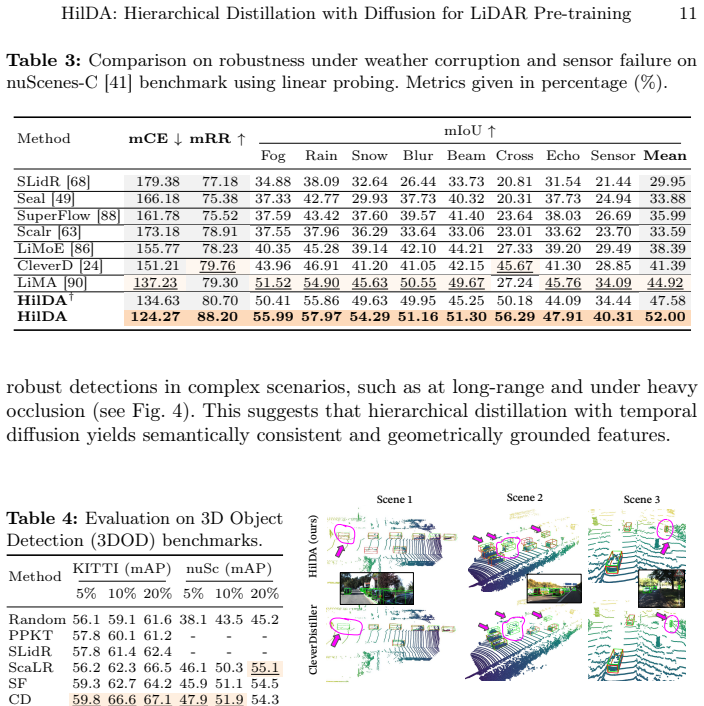
- [§4, Tables 2-3] §4 (Experiments) and Table 2/3: The SOTA and downstream-task superiority claims require verification that gains are not driven by unablated factors such as training schedule differences or post-hoc hyperparameter choices; the abstract-only review leaves open whether ablations isolate the contribution of the hierarchical components versus the diffusion objective.
minor comments (2)
- [§3.3] Notation for the temporal occupancy diffusion loss (Eq. 7 or equivalent) should explicitly define the conditioning variables and the diffusion schedule to avoid ambiguity with standard DDPM formulations.
- [Figure 2] Figure 2 (overview diagram) would benefit from clearer indication of how multi-layer features are aligned across modalities before the distillation loss is applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of cross-modal transfer and experimental rigor that we address point-by-point below. Where revisions are needed to strengthen clarity or provide additional verification, we indicate them explicitly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Hierarchical Distillation): The transfer of layer-wise semantic structure and global context is described as relying on feature similarity alone, with no explicit treatment of camera-LiDAR coordinate frame calibration, projection geometry, or modality-specific noise (sparsity, range-dependent density). This assumption is load-bearing for the cross-modal distillation claim; without it, performance gains may not generalize.
Authors: We appreciate this observation. The full manuscript in §3 describes the use of provided extrinsic calibration matrices to establish point-to-pixel correspondences for feature extraction from VFMs, with LiDAR points projected into image space prior to computing similarity losses. Modality noise is partially mitigated via the temporal occupancy diffusion term, which enforces consistency across frames with varying density. However, we agree that an explicit discussion of projection geometry, handling of out-of-view points, and range-dependent sparsity effects is currently insufficient. We will revise §3 to add a dedicated subsection on these implementation details, including pseudocode for the projection step and a brief analysis of sensitivity to calibration error. revision: yes
-
Referee: [§4, Tables 2-3] §4 (Experiments) and Table 2/3: The SOTA and downstream-task superiority claims require verification that gains are not driven by unablated factors such as training schedule differences or post-hoc hyperparameter choices; the abstract-only review leaves open whether ablations isolate the contribution of the hierarchical components versus the diffusion objective.
Authors: The full paper already reports controlled ablations in Tables 2 and 3 that hold training schedule, optimizer, and data fixed while varying only the distillation components (multi-layer, global context) and the diffusion objective. These tables demonstrate incremental gains from each element. To further address potential concerns about hyperparameter sensitivity, we will add a supplementary table in the revision that re-runs all compared methods under identical hyperparameter settings and reports the resulting performance deltas. This will provide stronger isolation of the proposed contributions. revision: partial
Circularity Check
No circularity in derivation; empirical claims on external benchmarks
full rationale
The paper describes a self-supervised pre-training method (multi-layer distillation + global context + temporal occupancy diffusion) evaluated on cross-modal benchmarks and downstream tasks (3D detection, scene flow, occupancy). No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the claimed SOTA results to inputs by construction. The framework is a standard distillation setup with external validation, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Agro, B., Sykora, Q., Casas, S., Gilles, T., Urtasun, R.: UnO: Unsupervised occupancy fields for perception and forecasting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[2]
IEEE Open Journal of Signal Processing (2026).https: //doi.org/10.1109/OJSP.2025.3650437
Ahn, S., Lee, D., Park, J.: Adaptability of vision foundation models for 3d medical image segmentation. IEEE Open Journal of Signal Processing (2026).https: //doi.org/10.1109/OJSP.2025.3650437
-
[3]
In: NeurIPS
Austin, J., Johnson, D.D., Ho, J., Tarlow, D., van den Berg, R.: Structured denoising diffusion models in discrete state-spaces. In: NeurIPS. vol. 34, pp. 17981– 17993 (2021)
2021
-
[4]
In: Proceedings of the International Conference on Computer Vision (2019)
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C., Gall, J.: SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences. In: Proceedings of the International Conference on Computer Vision (2019)
2019
-
[5]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[6]
In: Advances in Neural Information Processing Systems (2025)
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Bangalath, H., Wang, J., Monteiro, M., Xu, H., Dong, S., Ravi, N., Li, S.W., Dollár, P., Feichtenhofer, C.: Perception encoder: The best visual embeddings are not at the output of the network. In: Advances in Neural Information Processing Systems (2025)
2025
-
[7]
Boulch, A., Sautier, C., Michele, B., Puy, G., Marlet, R.: ALSO: Automotive LiDARself-supervisionbyoccupancyestimation.In:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuScenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
2020
-
[9]
In: Proceedings of the International Conference on Computer Vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the International Conference on Computer Vision. pp. 9650–9660 (2021)
2021
-
[10]
Data-Centric Engineering p
Chan, P.H., Li, B., Baris, G., Sadiq, Q., Donzella, V.: The inconvenient truth of ground truth errors in automotive datasets and DNN-based detection. Data-Centric Engineering p. e34 (2024) 16 M. Wozniak et al. HilDA: Hierarchical Distillation with Diffusion
2024
-
[11]
End-to-End Autonomous Driving: Challenges and Frontiers
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).https://doi.org/10.1109/TPAMI.2024.3435937
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, P., Liu, S., Zhao, H., Jia, J.: Distilling knowledge via knowledge review. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5008–5017 (2021)
2021
-
[13]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
Chen, X., Liu, Z., Xie, S., He, K.: Deconstructing denoising diffusion models for self-supervised learning. In: Proceedings of the International Conference on Learning Representations (ICLR) (2025)
2025
-
[14]
In: Pro- ceedings of the IEEE Winter Conference on Applications of Computer Vision
Chodosh, N., Ramanan, D., Lucey, S.: Re-evaluating lidar scene flow. In: Pro- ceedings of the IEEE Winter Conference on Applications of Computer Vision. pp. 6005–6015 (January 2024)
2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
Choy, C., Gwak, J., Savarese, S.: 4D spatio-temporal ConvNets: Minkowski con- volutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[16]
Contributors,P.:Pointcept:Acodebaseforpointcloudperceptionresearch.GitHub repository (2023)
2023
-
[17]
Proceedings of the International Conference on Learning Representations (2024)
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need registers. Proceedings of the International Conference on Learning Representations (2024)
2024
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Diehl, C., Sykora, Q., Agro, B., Gilles, T., Casas, S., Urtasun, R.: Dio: Decompos- able implicit 4d occupancy-flow world model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27456–27466 (2025)
2025
-
[19]
In: Proceedings of the International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: Proceedings of the International Conference on Learning Representations (2021)
2021
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
El Banani, M., Raj, A., Maninis, K.K., Kar, A., Li, Y., Rubinstein, M., Sun, D., Guibas, L., Johnson, J., Jampani, V.: Probing the 3d awareness of visual foundation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21795–21806 (2024)
2024
-
[21]
IEEE Robotics and Automation Letters5(2), 1931–1938 (2020)
Fang, J., Zhou, D., Yan, F., Zhao, T., Zhang, F., Ma, Y., Wang, L., Yang, R.: Aug- mented lidar simulator for autonomous driving. IEEE Robotics and Automation Letters5(2), 1931–1938 (2020)
1931
-
[22]
In: Proceedings of the International Conference on Computer Vision
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. In: Proceedings of the International Conference on Computer Vision. pp. 24823–24834. IEEE (2025)
2025
-
[23]
Vision meets robotics: The kitti dataset.Int
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The KITTI dataset. The International Journal of Robotics Research (2013).https://doi. org/10.1177/0278364913491297
-
[24]
In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025
Govindarajan, H., Wozniak, M., Klingner, M., Maurice, C., Kiran, B.R., Yogamani, S.: Cleverdistiller: Simple and spatially consistent cross-modal distillation. In: 36th British Machine Vision Conference 2025, BMVC 2025, Sheffield, UK, November 24-27, 2025. BMVA (2025)
2025
-
[25]
In: NeurIPS (2020)
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al.: Bootstrap your own latent-a new approach to self-supervised learning. In: NeurIPS (2020)
2020
-
[26]
Gu, S., Yin, W., Jin, B., Guo, X., Wang, J., Li, H., Zhang, Q., Long, X.: Dome: Taming diffusion model into high-fidelity controllable occupancy world model. arXiv preprint arXiv:2410.10429 (2024) HilDA: Hierarchical Distillation with Diffusion for LiDAR Pre-training 17
arXiv 2024
-
[27]
In: The Thirteenth International Conference on Learning Representations (2025)
He, J., Li, H., Yin, W., Liang, Y., Li, L., Zhou, K., Zhang, H., Liu, B., Chen, Y.C.: Lotus: Diffusion-based visual foundation model for high-quality dense prediction. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2016)
2016
-
[29]
5: Improved baselines for agglomerative vision founda- tion models
Heinrich, G., Ranzinger, M., Yin, H., Lu, Y., Kautz, J., Tao, A., Catanzaro, B., Molchanov, P.: Radiov2. 5: Improved baselines for agglomerative vision founda- tion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22487–22497 (2025)
2025
-
[30]
In: NeurIPS
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS. vol. 33 (2020)
2020
-
[31]
Hudson, D.A., Zoran, D., Malinowski, M., Lampinen, A.K., Jaegle, A., McClelland, J.L., Matthey, L., Hill, F., Lerchner, A.: Soda: Bottleneck diffusion models for representationlearning.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR). pp. 23115–23127 (2024)
2024
-
[32]
Contact-GraspNet: Efficient 6-dof grasp generation in cluttered scenes
Jiang, P., Osteen, P., Wigness, M., Saripalli, S.: RELLIS-3D dataset: Data, bench- marks and analysis. In: 2021 IEEE International Conference on Robotics and Au- tomation (ICRA) (2021).https://doi.org/10.1109/ICRA48506.2021.9561251
-
[33]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Justo Miro, A., af Klinteberg, L., Timus, B., Asefaw, A., Khoche, A., Gustafsson, T., Mansouri, S.S., Daneshtalab, M.: Correcting and Quantifying Systematic Errors in 3D Box Annotations for Autonomous Driving. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 6724–6732 (March 2026)
2026
-
[34]
Keetha, N., Mishra, A., Karhade, J., Jatavallabhula, K.M., Scherer, S., Krishna, M., Garg, S.: AnyLoc: Towards universal visual place recognition. IEEE Robotics and Automation Letters9(2), 1286–1293 (2024).https://doi.org/10.1109/LRA. 2023.3343602
work page doi:10.1109/lra 2024
-
[35]
Khatri, I., Vedder, K., Peri, N., Ramanan, D., Hays, J.: I Can’t Believe It’s Not Scene Flow! In: Proceedings of the European Conference on Computer Vision (2024).https://doi.org/10.1007/978-3-031-72649-1_14
-
[36]
In: 2024 European Control Conference (ECC)
Khoche, A., Asefaw, A., González, A., Timus, B., Mansouri, S.S., Jensfelt, P.: Addressing data annotation challenges in multiple sensors: A solution for scania collected datasets. In: 2024 European Control Conference (ECC). pp. 1032–1038 (2024)
2024
-
[37]
doi: 10.1109/ICRA55743.2025.11128816
Khoche, A., Zhang, Q., Sánchez, L.P., Asefaw, A., Mansouri, S.S., Jensfelt, P.: SSF: Sparse long-range scene flow for autonomous driving. In: Proceedings of the IEEE International Conference on Robotics and Automation (2025).https: //doi.org/10.1109/ICRA55743.2025.11128770
-
[38]
In: Interna- tional Conference on Learning Representations (ICLR) (2015)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Interna- tional Conference on Learning Representations (ICLR) (2015)
2015
-
[39]
In: Proceedings of the International Conference on Computer Vision (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the International Conference on Computer Vision (2023)
2023
-
[40]
IEEE Access11, 79341–79356 (2023)
Klokov, A.A., Pak, D.U., Khorin, A., Yudin, D.A., Kochiev, L., Luchinskiy, V.D., Bezuglyj, V.D.: DAPS3D: Domain adaptive projective segmentation of 3D LiDAR point clouds. IEEE Access11, 79341–79356 (2023)
2023
-
[41]
In: Proceedings of the International Conference on Computer Vision (2023) 18 M
Kong, L., Liu, Y., Li, X., Chen, R., Zhang, W., Ren, J., Pan, L., Chen, K., Liu, Z.: Robo3D: Towards robust and reliable 3D perception against corruptions. In: Proceedings of the International Conference on Computer Vision (2023) 18 M. Wozniak et al. HilDA: Hierarchical Distillation with Diffusion
2023
-
[42]
GitHub repository (2026), accessed 2026-01-09
KTH-RPL, contributors: Opensceneflow: A codebase for point cloud scene flow estimation research. GitHub repository (2026), accessed 2026-01-09
2026
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, B., Guo, J., Liu, H., Zou, Y., Ding, Y., Chen, X., Zhu, H., Tan, F., Zhang, C., Wang, T., Zhou, S., Zhang, L., Qi, X., Zhao, H., Yang, M., Zeng, W., Jin, X.: Uniscene: Unified occupancy-centric driving scene generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11971–11981 (June 2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, J., Saltori, C., Poiesi, F., Sebe, N.: Cross-modal and uncertainty-aware ag- glomeration for open-vocabulary 3d scene understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19390– 19400 (June 2025)
2025
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., Wang, X.: Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12037–12047. IEEE (2025)
2025
-
[46]
arXiv preprint arXiv:1805.06334 (2018)
Liebel, L., Körner, M.: Auxiliary tasks in multi-task learning. arXiv preprint arXiv:1805.06334 (2018)
Pith/arXiv arXiv 2018
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, J., Wang, G., Ye, W., Jiang, C., Han, J., Liu, Z., Zhang, G., Du, D., Wang, H.: Difflow3d: Toward robust uncertainty-aware scene flow estimation with iterative diffusion-based refinement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15109–15119 (2024)
2024
-
[48]
a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \
Liu, X., Gong, M., Fang, Q., Xie, H., Li, Y., Zhao, H., Feng, C.: LiDAR-based 4D occupancy completion and forecasting. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2024).https://doi.org/ 10.1109/IROS58592.2024.10801302
-
[49]
In: Advances in Neural Information Processing Systems
Liu, Y., Kong, L., Cen, J., Chen, R., Zhang, W., Pan, L., Chen, K., Liu, Z.: Segment any point cloud sequences by distilling vision foundation models. In: Advances in Neural Information Processing Systems. vol. 36 (2023)
2023
-
[50]
arXiv preprint arXiv:2104.04687 (2021)
Liu, Y.C., Huang, Y.K., Chiang, H.Y., Su, H.T., Liu, Z.Y., Chen, C.T., Tseng, C.Y., Hsu, W.H.: Learning from 2D: Contrastive pixel-to-point knowledge transfer for 3D pretraining. arXiv preprint arXiv:2104.04687 (2021)
arXiv 2021
-
[51]
In: Proceedings of the International Conference on Computer Vision (2025)
Liu, Y., Fu, J., Wu, Y., Wu, K., Li, P., Wu, J., Zhou, S., Xin, J.: Mind the gap: Aligning vision foundation models to image feature matching. In: Proceedings of the International Conference on Computer Vision (2025)
2025
-
[52]
In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (2026)
Ljungbergh, W., Lilja, A., Tonderski, A., Ling, A.L., Lindström, C., Verbeke, W., Fu, J., Petersson, C., Hammarstrand, L., Felsberg, M.: GASP: Unifying geometric and semantic self-supervised pre-training for autonomous driving. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (2026)
2026
-
[53]
In: International Conference on Learning Representations (ICLR) (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (ICLR) (2019)
2019
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ma, J., Chen, X., Huang, J., Xu, J., Luo, Z., Xu, J., Gu, W., Ai, R., Wang, H.: Cam4docc: Benchmark for camera-only 4d occupancy forecasting in autonomous driving applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21486–21495 (2024)
2024
-
[55]
Meng, Q., Wang, W., Zhou, T., Shen, J., Jia, Y., Van Gool, L.: Towards a weakly supervised framework for 3D point cloud object detection and annotation. IEEE Transactions on Pattern Analysis and Machine Intelligence44(8), 4454–4468 (2022).https://doi.org/10.1109/TPAMI.2021.3063611
-
[56]
MMDetection3D Contributors: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection (2020) HilDA: Hierarchical Distillation with Diffusion for LiDAR Pre-training 19
2020
-
[57]
Murrugarra-Llerena, J., Kirsten, L., Jung, C.R.: Can we trust bounding box annotations for object detection? In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 4812–4821 (2022)
2022
-
[58]
In: International Conference on Machine Learning
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8162–8171. PMLR (2021)
2021
-
[59]
In: Proceedings of the 35th Conference on Neural Information Processing Systems Track on Datasets and Benchmarks (December 2021)
Northcutt, C.G., Athalye, A., Mueller, J.: Pervasive label errors in test sets destabilize machine learning benchmarks. In: Proceedings of the 35th Conference on Neural Information Processing Systems Track on Datasets and Benchmarks (December 2021)
2021
-
[60]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Nunes, L., Marcuzzi, R., Mersch, B., Behley, J., Stachniss, C.: Scaling diffusion models to real-world 3d lidar scene completion. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14770–14780. IEEE (2024)
2024
-
[61]
Transactions on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[62]
In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Preechakul, K., Chatthee, N., Wizadwongsa, S., Suwajanakorn, S.: Diffusion autoencoders: Toward a meaningful and decodable representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).https://doi.org/10.1109/CVPR52688.2022.01036
-
[63]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Puy, G., Gidaris, S., Boulch, A., Siméoni, O., Sautier, C., Pérez, P., Bursuc, A., Marlet, R.: Three pillars improving vision foundation model distillation for LiDAR. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[64]
In: International Conference on Machine Learning (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (2021)
2021
-
[65]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ranzinger, M., Heinrich, G., Kautz, J., Molchanov, P.: Am-radio: Agglomerative vision foundation model reduce all domains into one. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12490– 12500 (2024)
2024
-
[66]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[67]
In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. Lecture Notes in Computer Science, vol. 9351, pp. 234–241. Springer, Cham (2015)
2015
-
[68]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
Sautier, C., Puy, G., Gidaris, S., Boulch, A., Bursuc, A., Marlet, R.: Image-to- LiDAR self-supervised distillation for autonomous driving data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[69]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
Shi, S., Wang, X., Li, H.: PointRCNN: 3D object proposal generation and detection from point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[70]
Wozniak et al
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., 20 M. Wozniak et al. HilDA: Hierarchical Distillation with Diffusion Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in pe...
2020
-
[71]
Tian, H., Xu, B., Li, S.: Distillation dynamics: Towards understanding feature- based distillation in vision transformers. Proceedings of the AAAI Conference on Artificial Intelligence (2026).https://doi.org/10.1609/aaai.v40i11.37913
-
[72]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021)
2021
-
[73]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Unal, O., Dai, D., Van Gool, L.: Scribble-supervised LiDAR semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2697–2707 (2022)
2022
-
[74]
In: NeurIPS (2022)
Voleti, V., Jolicoeur-Martineau, A., Pal, C.: Mcvd: Masked conditional video diffusion for prediction, generation, and interpolation. In: NeurIPS (2022)
2022
-
[75]
In: Proceedings of the European Conference on Computer Vision
Wang, G., Wang, Z., Tang, P., Zheng, J., Ren, X., Feng, B., Ma, C.: Occgen: Generative multi-modal 3d occupancy prediction for autonomous driving. In: Proceedings of the European Conference on Computer Vision. pp. 95–112. Springer (2024)
2024
-
[76]
Drive- dreamer: Towards real-world-drive world models for autonomous driving
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-drive world models for autonomous driving. In: Computer Vision – ECCV 2024 (2025).https://doi.org/10.1007/978-3-031-73195-2_4
-
[77]
In: Proceedings of the International Conference on Computer Vision
Wang, X., Zhu, Z., Xu, W., Zhang, Y., Wei, Y., Chi, X., Ye, Y., Du, D., Lu, J., Wang, X.: Openoccupancy: A large scale benchmark for surrounding semantic oc- cupancy perception. In: Proceedings of the International Conference on Computer Vision. pp. 17850–17859 (October 2023)
2023
-
[78]
arXiv preprint arXiv:2511.00088 (2025)
Wang, Y., Luo, W., Bai, J., Cao, Y., Che, T., Chen, K., Chen, Y., Diamond, J., Ding, Y., Ding, W., et al.: Alpamayo-r1: Bridging reasoning and action pre- diction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088 (2025)
Pith/arXiv arXiv 2025
-
[79]
doi: 10.1109/ICRA55743.2025.11128816
Wang, Y., Liu, Y., Yuan, T., Mao, Y., Liang, Y., Yang, X., Zhang, H., Zhao, H.: Diffusion-based generative models for 3D occupancy prediction in autonomous driving. In: 2025 IEEE International Conference on Robotics and Automation (ICRA) (2025).https://doi.org/10.1109/ICRA55743.2025.11128716
-
[80]
In: Proceedings of the International Conference on Computer Vision
Wei, C., Mangalam, K., Huang, P.Y., Li, Y., Fan, H., Xu, H., Wang, H., Xie, C., Yuille, A.L., Feichtenhofer, C.: Diffusion models as masked autoencoders. In: Proceedings of the International Conference on Computer Vision. pp. 16238–16248 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.