Boundary Embedding Shaping with Adaptive Contrastive Learning for Graph Structural Disentanglement
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
Boundary Embedding Shaping disentangles graph structures by targeting class boundaries with adaptive contrastive learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
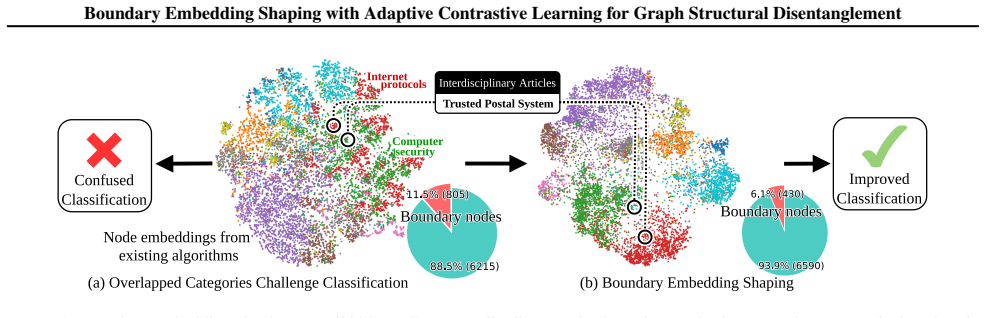
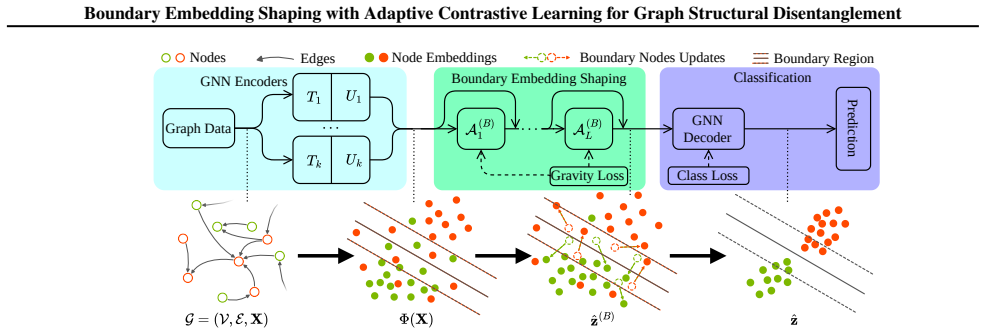
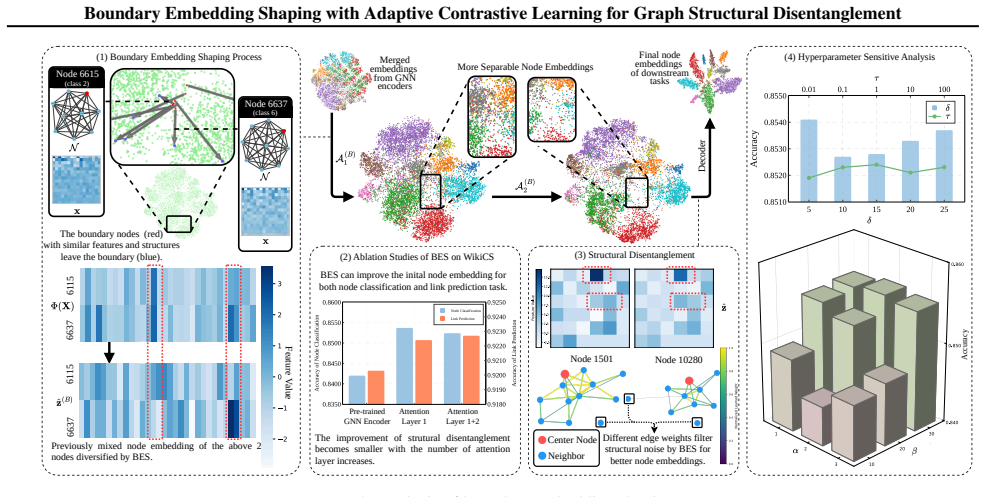
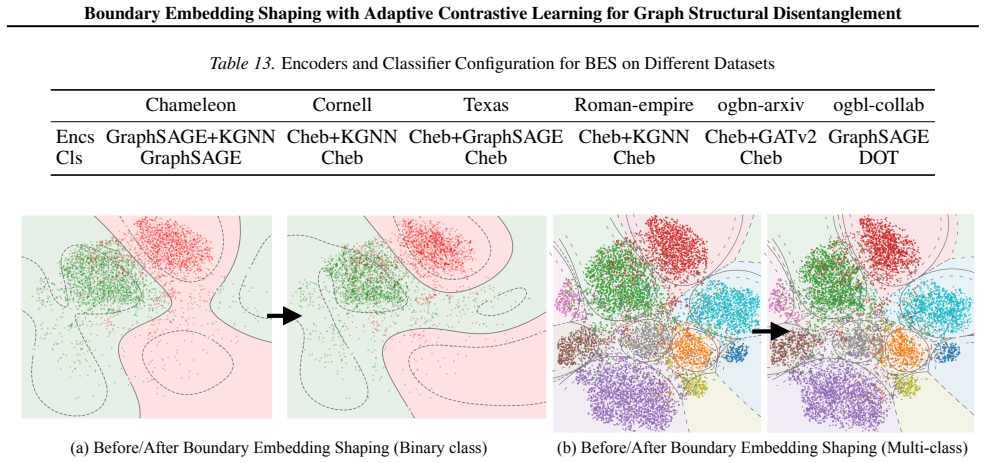
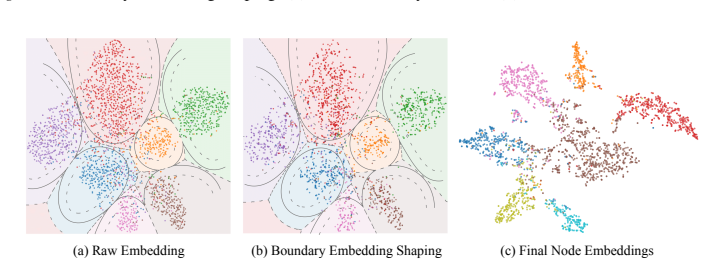
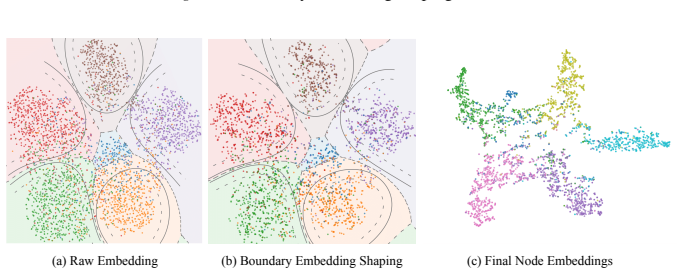
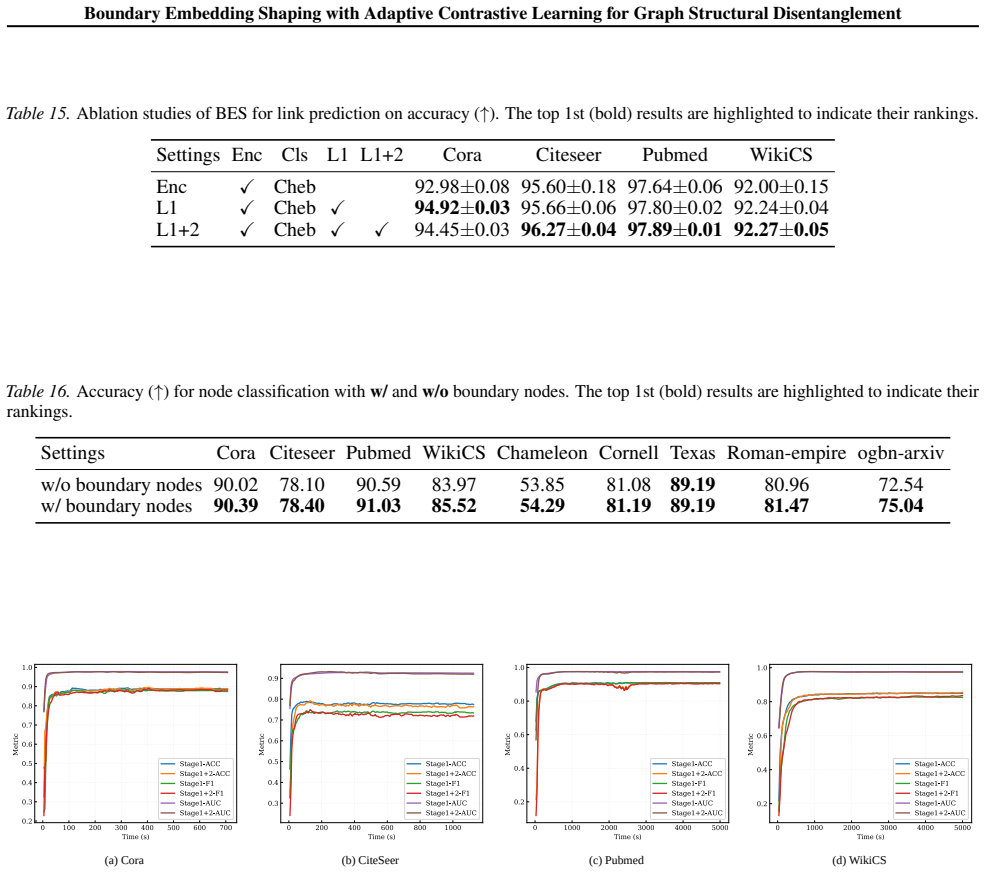
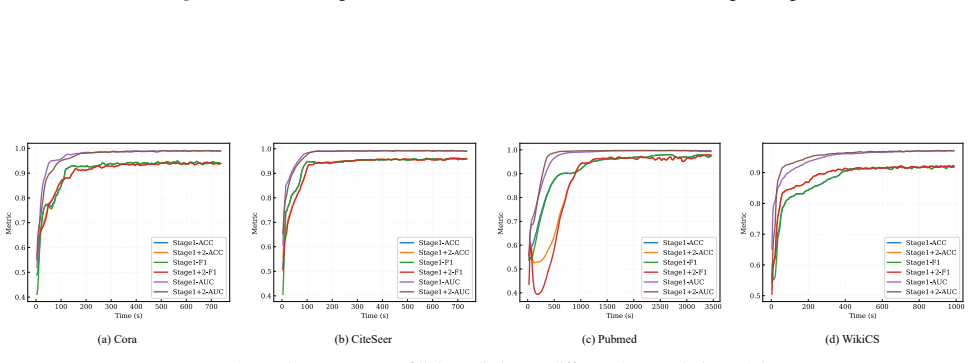
The paper claims that graph structural entanglement is most acute near class boundaries in the embedding space and that Boundary Embedding Shaping (BES), an adaptive contrastive learning plug-in, selectively suppresses spurious structural noise at decision boundaries, thereby improving boundary discrimination and raising accuracy in node classification and link prediction with minimal parameter perturbation.
What carries the argument
Boundary Embedding Shaping (BES): an adaptive contrastive learning plug-in module that identifies boundary regions and shapes embeddings to reduce structural noise there.
If this is right
- BES consistently improves boundary discrimination in GNN embeddings.
- BES outperforms existing leading robust GNN methods on standard benchmarks.
- BES boosts GCN node classification accuracy by an average of 3.3 percent, reaching 5.0 percent on WikiCS.
- BES delivers higher accuracy on link prediction tasks.
Where Pith is reading between the lines
- The boundary-focused approach could be adapted to reduce feature entanglement in non-graph settings such as image or sequence models.
- Because BES adds little parameter change, it could be stacked with other GNN improvements without requiring full retraining.
- Graph datasets might be pre-processed by first detecting and labeling boundary nodes to enable more targeted disentanglement methods.
Load-bearing premise
Boundary-region entanglement is the primary performance bottleneck and can be fixed by selectively suppressing noise there without harming embeddings away from the boundaries.
What would settle it
An experiment on a graph dataset where noise is distributed uniformly rather than concentrated at boundaries, measuring whether BES gains disappear when the boundary-specific targeting is disabled.
Figures

read the original abstract
Graph neural networks (GNNs) excel at aggregating neighbor information for classification, yet their performance is hindered by graph structural entanglement, where spurious correlations from semantically irrelevant neighbors contaminate node embeddings. This challenge is most acute for nodes near class boundaries in the embedding space, where amplified structural noise blurs decision boundaries and destabilizes predictions. Existing robust GNN methods largely treat all nodes uniformly, ignoring boundary vulnerabilities. In this paper, to improve classification performance, we tackle graph structural disentanglement by identifying boundary-region entanglement as the primary bottleneck and propose Boundary Embedding Shaping (BES), an adaptive contrastive learning GNN plug-in module that selectively suppresses spurious structural noise at decision boundaries with minimal model parameter perturbation. Extensive experiments demonstrate that BES consistently improves boundary discrimination and outperforms existing leading methods. Notably, BES boosts GCN performance by an average of 3.3% in node classification (up to 5.0% on WikiCS) and achieves superior accuracy in link prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that graph structural entanglement is most problematic at class boundaries in GNN embeddings and proposes Boundary Embedding Shaping (BES), an adaptive contrastive learning plug-in module that selectively suppresses spurious structural noise at those boundaries with minimal parameter perturbation. It reports that BES improves boundary discrimination, boosts GCN node classification by 3.3% on average (up to 5.0% on WikiCS), and yields superior link prediction accuracy over leading methods.
Significance. If the targeted boundary treatment proves robust and generalizes beyond the reported datasets, BES could offer a lightweight, plug-in improvement for GNN robustness without uniform regularization across all nodes. The emphasis on decision-boundary vulnerabilities addresses a plausible but under-examined source of structural noise.
major comments (2)
- [Abstract] Abstract: the central empirical claims (3.3% average gain, 5.0% on WikiCS, superior link prediction) are stated without any reference to datasets, baselines, number of runs, or error bars, making it impossible to assess whether the reported improvements are statistically meaningful or reproducible.
- [Abstract] Abstract: no equations, algorithm pseudocode, or formal definition of the adaptive contrastive loss or boundary identification procedure are supplied, so the claim that BES 'selectively suppresses spurious structural noise at decision boundaries with minimal model parameter perturbation' cannot be evaluated for correctness or side effects on non-boundary nodes.
Simulated Author's Rebuttal
We thank the referee for these comments on the abstract. We respond to each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (3.3% average gain, 5.0% on WikiCS, superior link prediction) are stated without any reference to datasets, baselines, number of runs, or error bars, making it impossible to assess whether the reported improvements are statistically meaningful or reproducible.
Authors: We agree that the abstract would be clearer with additional context. In the revised manuscript we will add a concise clause noting that results are reported on standard citation and co-authorship benchmarks (averaged over 10 runs) while keeping the abstract within length limits; full tables with baselines, run counts, and standard deviations remain in Section 4. revision: yes
-
Referee: [Abstract] Abstract: no equations, algorithm pseudocode, or formal definition of the adaptive contrastive loss or boundary identification procedure are supplied, so the claim that BES 'selectively suppresses spurious structural noise at decision boundaries with minimal model parameter perturbation' cannot be evaluated for correctness or side effects on non-boundary nodes.
Authors: Abstracts conventionally omit equations and pseudocode due to space constraints; the formal definitions of the boundary identification procedure and the adaptive contrastive loss appear in Section 3, together with the analysis of parameter perturbation and effects on non-boundary nodes. The abstract only summarizes the high-level contribution, which is substantiated in the main text. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and available context contain no equations, derivations, fitted parameters presented as predictions, or self-citations that serve as load-bearing premises. The paper proposes BES as an adaptive contrastive learning module and reports empirical performance gains (e.g., 3.3% average boost on GCN) as experimental outcomes rather than results derived by construction from inputs. No self-definitional steps, renamed known results, or uniqueness theorems imported from prior author work appear. The derivation chain is therefore self-contained against external benchmarks, with the central claim resting on empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Boundary-region entanglement is the primary bottleneck for graph structural disentanglement
invented entities (1)
-
Boundary Embedding Shaping (BES) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z., van den Hengel, A., and Qi, Y
Bao, S., Xue, Z., Chen, Q., Ou, S., Beheshti, A., Sheng, Q. Z., van den Hengel, A., and Qi, Y. Causal MVC : Causal content-style representation learning for deep multi-view clustering. In Proceedings of the International Conference on Multimedia (MM), pp.\ 1598--1606, 2025
2025
-
[2]
Bishop, C. M. Latent variable models. In Learning in Graphical Models, volume 89, pp.\ 371--403. Springer, 1998
1998
-
[3]
How attentive are graph attention networks? In Proceedings of the International Conference on Learning Representations (ICLR), 2022
Brody, S., Alon, U., and Yahav, E. How attentive are graph attention networks? In Proceedings of the International Conference on Learning Representations (ICLR), 2022
2022
-
[4]
Cai, Y., Liu, Y., Gao, E., Jiang, T., Zhang, Z., van den Hengel, A., and Shi, J. Q. On the value of cross-modal misalignment in multimodal representation learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[5]
Nodeimport: Imbalanced node classification with node importance assessment
Chen, N., Liu, Z., Hooi, B., He, B., Hu, J., and Chen, J. Nodeimport: Imbalanced node classification with node importance assessment. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pp.\ 94--105, 2025 a
2025
-
[6]
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. E. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 1597--1607, 2020
2020
-
[7]
Improving graph contrastive learning with community structure
Chen, X., Yue, K., Duan, L., and Yu, L. Improving graph contrastive learning with community structure. In Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), pp.\ 568--585, 2025 b
2025
-
[8]
Daunhawer, I., Bizeul, A., Palumbo, E., Marx, A., and Vogt, J. E. Identifiability results for multimodal contrastive learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[9]
Convolutional neural networks on graphs with fast localized spectral filtering
Defferrard, M., Bresson, X., and Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 3837--3845, 2016
2016
-
[10]
Imagenet: A large-scale hierarchical image database
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 248--255, 2009
2009
-
[11]
The mnist database of handwritten digit images for machine learning research
Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29 0 (6): 0 141--142, 2012
2012
-
[12]
L., Bollacker, K
Giles, C. L., Bollacker, K. D., and Lawrence, S. Citeseer: An automatic citation indexing system. In Proceedings of the ACM International Conference on Digital Libraries (DL), pp.\ 89--98, 1998
1998
-
[13]
L., Ying, Z., and Leskovec, J
Hamilton, W. L., Ying, Z., and Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 1024--1034, 2017
2017
-
[14]
Hoang, V. T. and Lee, O. Transitivity-preserving graph representation learning for bridging local connectivity and role-based similarity. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp.\ 12456--12465, 2024
2024
-
[15]
Open graph benchmark: Datasets for machine learning on graphs
Hu, W., Fey, M., Zitnik, M., Dong, Y., Ren, H., Liu, B., Catasta, M., and Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[16]
Supervised contrastive learning
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., and Krishnan, D. Supervised contrastive learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[17]
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR), 2017
2017
-
[18]
Koh, P. W. and Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 1885--1894, 2017
2017
-
[19]
Li, J., Zhou, P., Xiong, C., and Hoi, S. C. Prototypical contrastive learning of unsupervised representations. In Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[20]
Kolmogorov--arnold graph neural networks for molecular property prediction
Li, L., Zhang, Y., Wang, G., and Xia, K. Kolmogorov--arnold graph neural networks for molecular property prediction. Nature Machine Intelligence, 7 0 (8): 0 1346--1354, 2025
2025
-
[21]
Liu, Y., Zhang, Z., Gong, D., Gong, M., Huang, B., van den Hengel, A., Zhang, K., and Shi, J. Q. Identifiable latent polynomial causal models through the lens of change. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[22]
Liu, Y., Zhang, Z., Gong, D., Gong, M., Huang, B., van den Hengel, A., Zhang, K., and Shi, J. Q. Latent covariate shift: Unlocking partial identifiability for multi-source domain adaptation. Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
-
[23]
Liu, Y., Gong, D., Cai, Y., Gao, E., Zhang, Z., Huang, B., Gong, M., van den Hengel, A., and Shi, J. Q. I predict therefore i am: Is next token prediction enough to learn human-interpretable concepts from data? In Proceedings of the International Conference on Learning Representations (ICLR), 2026 a
2026
-
[24]
Liu, Y., Zhang, Z., Gong, D., Gao, E., Huang, B., Gong, M., van den Hengel, A., Zhang, K., and Shi, J. Q. Beyond DAG s: A latent partial causal model for multimodal learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2026 b
2026
-
[25]
Liu, Y., Zhang, Z., Gong, D., Gong, M., Huang, B., van den Hengel, A., Zhang, K., and Shi, J. Q. Identifying weight-variant latent causal models. Journal of Machine Learning Research, 27 0 (4): 0 1--49, 2026 c
2026
-
[26]
Classic gnns are strong baselines: Reassessing gnns for node classification
Luo, Y., Shi, L., and Wu, X.-M. Classic gnns are strong baselines: Reassessing gnns for node classification. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 97650--97669, 2024
2024
-
[27]
Enhancing robustness of graph neural networks on social media with explainable inverse reinforcement learning
Lyu, Y., Li, C., Xie, S., and Zhang, X. Enhancing robustness of graph neural networks on social media with explainable inverse reinforcement learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 31736--31758, 2024
2024
-
[28]
Disentangled graph convolutional networks
Ma, J., Cui, P., Kuang, K., Wang, X., and Zhu, W. Disentangled graph convolutional networks. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 4212--4221, 2019
2019
-
[29]
K., Nigam, K., Rennie, J., and Seymore, K
McCallum, A. K., Nigam, K., Rennie, J., and Seymore, K. Automating the construction of internet portals with machine learning. Information Retrieval, 3: 0 127--163, 2000
2000
-
[30]
Mernyei, P. and Cangea, C. Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901, 2020
arXiv 2007
-
[31]
Interpretable and generalizable graph learning via stochastic attention mechanism
Miao, S., Liu, M., and Li, P. Interpretable and generalizable graph learning via stochastic attention mechanism. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 15524--15543, 2022
2022
-
[32]
L., Lenssen, J
Morris, C., Ritzert, M., Fey, M., Hamilton, W. L., Lenssen, J. E., Rattan, G., and Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp.\ 4602--4609, 2019
2019
-
[33]
C.-C., Lei, Y., and Yang, B
Pei, H., Wei, B., Chang, K. C.-C., Lei, Y., and Yang, B. Geom-gcn: Geometric graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[34]
Pennington, J., Socher, R., and Manning, C. D. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 1532--1543, 2014
2014
-
[35]
A critical look at the evaluation of gnns under heterophily: Are we really making progress? In Proceedings of the International Conference on Learning Representations (ICLR), 2023
Platonov, O., Kuznedelev, D., Diskin, M., Babenko, A., and Prokhorenkova, L. A critical look at the evaluation of gnns under heterophily: Are we really making progress? In Proceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[36]
Rusch, T. K., Bronstein, M. M., and Mishra, S. A survey on oversmoothing in graph neural networks. arXiv preprint arXiv:2303.10993, 2023
arXiv 2023
-
[37]
Collective classification in network data
Sen, P., Namata, G., Bilgic, M., Getoor, L., Galligher, B., and Eliassi-Rad, T. Collective classification in network data. AI Magazine, 29 0 (3): 0 93--106, 2008
2008
-
[38]
Training region-based object detectors with online hard example mining
Shrivastava, A., Gupta, A., and Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 761--769, 2016
2016
-
[39]
Networked inequality: Preferential attachment bias in graph neural network link prediction
Subramonian, A., Sagun, L., and Sun, Y. Networked inequality: Preferential attachment bias in graph neural network link prediction. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 46891--46925, 2024
2024
-
[40]
Sun, L., Huang, Z., Wang, Z., Wang, F., Peng, H., and Yu, P. S. Motif-aware riemannian graph neural network with generative-contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp.\ 9044--9052, 2024
2024
-
[41]
Graph attention networks
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Li \` o , P., and Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations (ICLR), 2018
2018
-
[42]
u gelgen, J., Sharma, Y., Gresele, L., Brendel, W., Sch \
von K \" u gelgen, J., Sharma, Y., Gresele, L., Brendel, W., Sch \" o lkopf, B., Besserve, M., and Locatello, F. Self-supervised learning with data augmentations provably isolates content from style. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 16451--16467, 2021
2021
-
[43]
Generalizing aggregation functions in gnns: Building high capacity and robust gnns via nonlinear aggregation
Wang, B., Jiang, B., Tang, J., and Luo, B. Generalizing aggregation functions in gnns: Building high capacity and robust gnns via nonlinear aggregation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 0 (11): 0 13454--13466, 2023
2023
-
[44]
Disentangled graph collaborative filtering
Wang, X., Jin, H., Zhang, A., He, X., Xu, T., and Chua, T. Disentangled graph collaborative filtering. In Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pp.\ 1001--1010, 2020
2020
-
[45]
Simplifying graph convolutional networks
Wu, F., Souza, A., Zhang, T., Fifty, C., Yu, T., and Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 6861--6871, 2019
2019
-
[46]
Graph neural networks in recommender systems: A survey
Wu, S., Sun, F., Zhang, W., Xie, X., and Cui, B. Graph neural networks in recommender systems: A survey. ACM Computing Surveys, 55 0 (5): 0 1--37, 2022
2022
-
[47]
Xia, J., Wu, L., Wang, G., Chen, J., and Li, S. Z. Pro GCL : Rethinking hard negative mining in graph contrastive learning. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 24332--24346, 2022
2022
-
[48]
C., Wang, S., and Honavar, V
Xiao, T., Zhu, H., Zhang, Z., Guo, Z., Aggarwal, C. C., Wang, S., and Honavar, V. G. Efficient contrastive learning for fast and accurate inference on graphs. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 54363--54381, 2024
2024
-
[49]
Revisiting semi-supervised learning with graph embeddings
Yang, Z., Cohen, W., and Salakhudinov, R. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 40--48, 2016
2016
-
[50]
v., and Locatello, F
Yao, D., Xu, D., Lachapelle, S., Magliacane, S., Taslakian, P., Martius, G., K \"u gelgen, J. v., and Locatello, F. Multi-view causal representation learning with partial observability. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[51]
Do transformers really perform badly for graph representation? In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 28877--28888, 2021
Ying, C., Cai, T., Luo, S., Zheng, S., Ke, G., He, D., Shen, Y., and Liu, T. Do transformers really perform badly for graph representation? In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 28877--28888, 2021
2021
-
[52]
Graph contrastive learning with augmentations
You, Y., Chen, T., Sui, Y., Chen, T., Wang, Z., and Shen, Y. Graph contrastive learning with augmentations. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 5812--5823, 2020
2020
-
[53]
Zeng, H., Zhou, H., Srivastava, A., Kannan, R., and Prasanna, V. K. Graph SAINT : Graph sampling based inductive learning method. In Proceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[54]
Decouple graph neural networks: Train multiple simple gnns simultaneously instead of one
Zhang, H., Zhu, Y., and Li, X. Decouple graph neural networks: Train multiple simple gnns simultaneously instead of one. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 0 (11): 0 7451--7462, 2024 a
2024
-
[55]
Graph neural networks in modern ai-aided drug discovery
Zhang, O., Lin, H., Zhang, X., Wang, X., Wu, Z., Ye, Q., Zhao, W., Wang, J., Ying, K., Kang, Y., et al. Graph neural networks in modern ai-aided drug discovery. Chemical Reviews, 125 0 (20): 0 10001--10103, 2025
2025
-
[56]
Trans GNN : Harnessing the collaborative power of transformers and graph neural networks for recommender systems
Zhang, P., Yan, Y., Zhang, X., Li, C., Wang, S., Huang, F., and Kim, S. Trans GNN : Harnessing the collaborative power of transformers and graph neural networks for recommender systems. In Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pp.\ 1285--1295, 2024 b
2024
-
[57]
and Koniusz, P
Zhu, H. and Koniusz, P. Simple spectral graph convolution. In Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[58]
Beyond homophily in graph neural networks: Current limitations and effective designs
Zhu, J., Yan, Y., Zhao, L., Heimann, M., Akoglu, L., and Koutra, D. Beyond homophily in graph neural networks: Current limitations and effective designs. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), pp.\ 7793--7804, 2020
2020
-
[59]
Graph contrastive learning with adaptive augmentation
Zhu, Y., Xu, Y., Yu, F., Liu, Q., Wu, S., and Wang, L. Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference (WWW), pp.\ 2069--2080, 2021
2069
-
[60]
S., Sharma, Y., Schneider, S., Bethge, M., and Brendel, W
Zimmermann, R. S., Sharma, Y., Schneider, S., Bethge, M., and Brendel, W. Contrastive learning inverts the data generating process. In Proceedings of the International Conference on Machine Learning (ICML), pp.\ 12979--12990, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.