Multi-View Decompilation for LLM-Based Malware Classification
Pith reviewed 2026-06-26 17:08 UTC · model grok-4.3
The pith
Feeding LLMs decompiled views from both Ghidra and RetDec raises malicious-class F1 over single-view baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
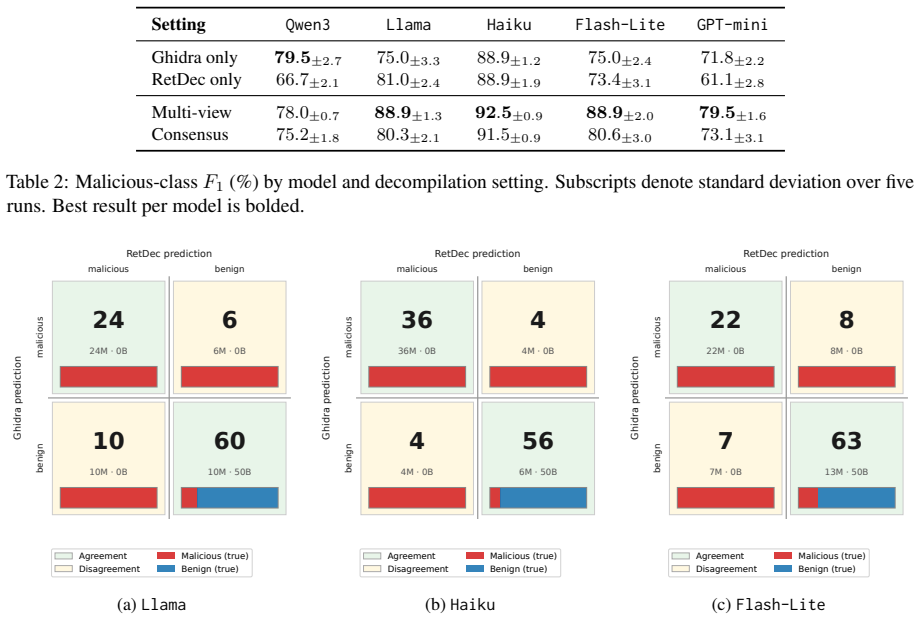
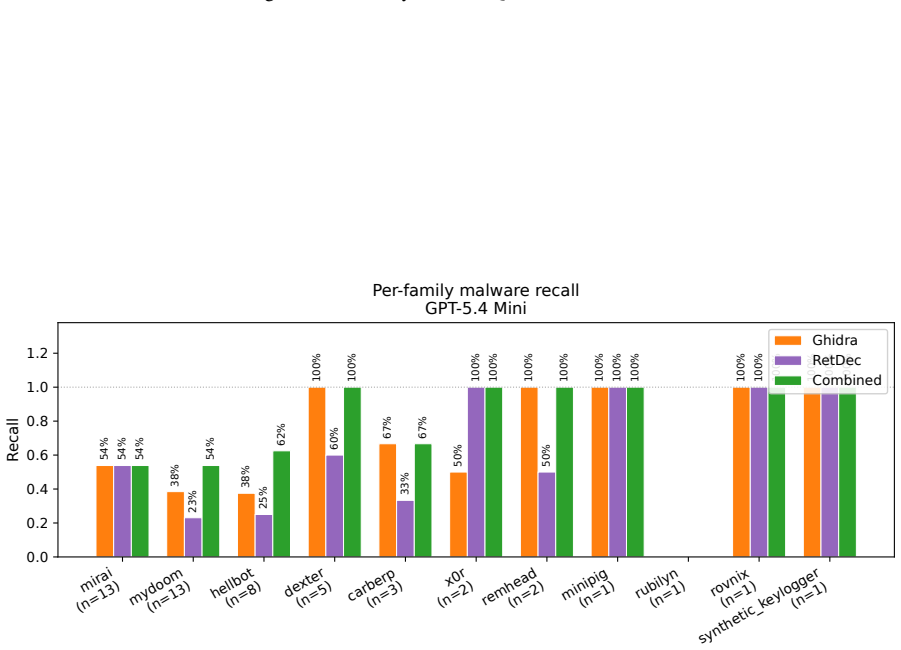
The paper establishes that supplying matched pseudo-C from both Ghidra and RetDec to an LLM classifier produces higher malicious-class F1 scores than either decompiler alone, chiefly by lifting recall on malicious samples, and that the two decompilers commit partially non-overlapping errors on the same binaries.
What carries the argument
Paired pseudo-C outputs from Ghidra and RetDec, supplied together in the LLM prompt as complementary evidence for the benign/malicious decision.
If this is right
- Malicious recall increases when both decompiler views are provided to the LLM.
- Ghidra and RetDec generate classification errors that only partially overlap on the benchmark samples.
- The F1 improvement appears across a range of LLMs without any model changes or additional training.
- Multi-decompiler prompting supplies a training-free route to better malware triage in settings that already use decompiled code.
Where Pith is reading between the lines
- The same pairing of decompiler outputs could be tested on related binary-analysis tasks such as vulnerability discovery or packer identification.
- Adding a third decompiler might produce further recall gains or show diminishing returns once the main sources of disagreement are covered.
- If decompiler diversity helps LLMs overcome individual tool limitations, comparable multi-tool prompting may help on other lossy reverse-engineering problems outside malware.
Load-bearing premise
The curated collection of benign utilities and malicious programs is representative enough that the observed F1 gain will appear on other binaries and threat behaviors.
What would settle it
Applying the identical single-view versus dual-view comparison to a new collection of binaries drawn from different malware families and observing no improvement or a decline in malicious-class F1.
Figures








read the original abstract
Malware analysts often inspect compiled binaries through decompiled pseudo-C, when source code is unavailable. Recent work suggests that large language models (LLMs) can assist this process by classifying decompiled code as benign or malicious, but existing pipelines typically rely on a single decompiler view. We argue that this assumption is fragile: decompilers are lossy heuristic tools, and different decompilers can expose different artefacts of the same binary. We curate a benchmark of benign utilities and malicious programs spanning a range of threat behaviors. Each sample is compiled and decompiled with both Ghidra and RetDec, yielding matched pseudo-C views. Across a range of LLMs from major model families, we find that providing both decompiler views improves malicious-class F1, mainly by increasing recall on malicious samples. Agreement analyses further show that Ghidra and RetDec make partially different errors, supporting the view that decompiler outputs provide complementary evidence. Our results suggest that multi-decompiler prompting is a simple, training-free way to improve LLM-based malware triage in practical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that providing matched pseudo-C views from both Ghidra and RetDec decompilers to LLMs improves malicious-class F1 (primarily via higher recall) over single-decompiler baselines on a curated benchmark of benign utilities and malicious programs; it further claims that agreement analyses show the decompilers make partially different errors, supporting the use of multi-view prompting as a training-free improvement for LLM-based malware triage.
Significance. If the empirical results hold under proper controls and on representative data, the work would demonstrate a low-cost way to exploit decompiler complementarity for better LLM malware classification, which could be directly useful in practical reverse-engineering settings.
major comments (2)
- [Abstract] Abstract: the central claim of improved malicious F1 and complementary errors rests on an empirical measurement, yet the abstract (and by extension the reported evaluation) supplies no dataset size, sample sources, compilation details, model names/sizes, statistical significance tests, or controls for prompt length/ordering; without these the observed directional improvement cannot be verified or reproduced.
- [Abstract] Abstract: the benchmark is described only as spanning 'a range of threat behaviors' with no counts, families, binary sizes, or diversity metrics reported; this directly undermines the load-bearing assumption that the F1 gain (driven by recall) will generalize beyond the specific curated set.
minor comments (1)
- The manuscript would benefit from an explicit experimental-setup subsection detailing the exact prompting templates, LLM inference parameters, and how agreement between decompiler views was quantified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater specificity in the abstract will improve clarity, reproducibility, and support for the claims. We address each comment below and will revise the abstract in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improved malicious F1 and complementary errors rests on an empirical measurement, yet the abstract (and by extension the reported evaluation) supplies no dataset size, sample sources, compilation details, model names/sizes, statistical significance tests, or controls for prompt length/ordering; without these the observed directional improvement cannot be verified or reproduced.
Authors: The full manuscript reports dataset size, sample sources, compilation settings, model names/sizes, and evaluation procedures in Sections 3 and 4. We acknowledge that the abstract itself is insufficiently self-contained. We will revise the abstract to include these elements (dataset cardinality, model families, and note on significance testing). We will also add an explicit ablation on prompt length and ordering effects in the experiments section of the revised manuscript to confirm robustness. revision: yes
-
Referee: [Abstract] Abstract: the benchmark is described only as spanning 'a range of threat behaviors' with no counts, families, binary sizes, or diversity metrics reported; this directly undermines the load-bearing assumption that the F1 gain (driven by recall) will generalize beyond the specific curated set.
Authors: Section 3 of the manuscript already supplies the requested counts, families, size distributions, and diversity metrics for the curated benchmark. The abstract uses a concise phrasing for brevity, but we agree this limits immediate assessment of scope. We will revise the abstract to report these key statistics so that the generalization argument is better grounded. revision: yes
Circularity Check
No circularity: purely empirical measurement on held-out benchmark
full rationale
The paper describes an empirical pipeline: curation of a benchmark of binaries, decompilation via Ghidra and RetDec to produce matched pseudo-C views, and direct measurement of LLM classification performance (F1, recall) when given single vs. dual views. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central result is a straightforward comparison of observed metrics on the curated set; nothing reduces to its own inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decompilers are lossy heuristic tools that can expose different artefacts of the same binary.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint =
A Decompilation-Driven Framework for Malware Detection with Large Language Models , author =. 2026 , eprint =
2026
-
[2]
2024 , eprint =
Enhancing Reverse Engineering: Investigating and Benchmarking Large Language Models for Vulnerability Analysis in Decompiled Binaries , author =. 2024 , eprint =
2024
-
[3]
Large Language Models for Code Analysis: Do
Fang, Chongzhou and Miao, Ning and Srivastav, Shaurya and Liu, Jialin and Zhang, Ruoyu and Fang, Ruijie and Asmita and Tsang, Ryan and Nazari, Najmeh and Wang, Han and Homayoun, Houman , booktitle =. Large Language Models for Code Analysis: Do. 2024 , isbn =
2024
-
[4]
Evaluating the Effectiveness of Decompilers , author =. Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2024) , pages =. 2024 , address =. doi:10.1145/3650212.3652144 , url =
-
[5]
2024 , eprint =
Exploring the Efficacy of Large Language Models (GPT-4) in Binary Reverse Engineering , author =. 2024 , eprint =
2024
-
[6]
2014 , howpublished =
ytisf and contributors , title =. 2014 , howpublished =
2014
-
[7]
Claude Sonnet 4.6 , year =
-
[8]
Ghidra Software Reverse Engineering Framework , year =
-
[9]
2024 , howpublished =
2024
-
[10]
2024 , note =
Gemini: A Family of Highly Capable Multimodal Models , institution =. 2024 , note =
2024
-
[11]
2024 , howpublished =
Vertex. 2024 , howpublished =
2024
-
[12]
Docker: Containerization Platform , year =
-
[13]
Cifuentes, Cristina , title =
-
[14]
Proceedings of the Network and Distributed System Security Symposium (NDSS) , year =
Lee, JongHyup and Avgerinos, Thanassis and Brumley, David , title =. Proceedings of the Network and Distributed System Security Symposium (NDSS) , year =
-
[15]
and Lee, JongHyup and Woo, Maverick and Brumley, David , title =
Schwartz, Edward J. and Lee, JongHyup and Woo, Maverick and Brumley, David , title =. 22nd USENIX Security Symposium (USENIX Security 13) , pages =. 2013 , publisher =
2013
-
[16]
and Vasilescu, Bogdan and Le Goues, Claire , title =
Dramko, Luke and Lacomis, Jeremy and Schwartz, Edward J. and Vasilescu, Bogdan and Le Goues, Claire , title =. 33rd USENIX Security Symposium (USENIX Security 24) , year =
-
[17]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , year =. 2507.06261 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2026 , howpublished =
Introducing. 2026 , howpublished =
2026
-
[19]
Introducing Claude Haiku 4.5 , year =
-
[20]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[21]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
2023 , eprint =
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author =. 2023 , eprint =
2023
-
[23]
2024 , eprint =
Mixture-of-Agents Enhances Large Language Model Capabilities , author =. 2024 , eprint =
2024
-
[24]
Transactions on Machine Learning Research (TMLR) , year =
More Agents Is All You Need , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[25]
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Chen, Zhijun and Li, Jingzheng and Chen, Pengpeng and Li, Zhuoran and Sun, Kai and Luo, Yuankai and Mao, Qianren and Yang, Dingqi and Sun, Hailong and Yu, Philip S. , year =. Harnessing Multiple Large Language Models: A Survey on. 2502.18036 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2022 , eprint =
Malicious Source Code Detection Using Transformer , author =. 2022 , eprint =
2022
-
[27]
2025 , url =
Zhao, Wenxiang and Wu, Juntao and Meng, Zhaoyi , journal =. 2025 , url =
2025
-
[28]
Qian, Xingzhi and Zheng, Xinran and He, Yiling and Yang, Shuo and Cavallaro, Lorenzo , year =. 2502.13055 , archivePrefix =
-
[29]
Feasibility Study for Supporting Static Malware Analysis Using
Fujii, Shota and Yamagishi, Rei , booktitle =. Feasibility Study for Supporting Static Malware Analysis Using. 2025 , url =
2025
-
[30]
Assessing
Patsakis, Constantinos and Casino, Fran and Lykousas, Nikolaos , journal =. Assessing. 2024 , doi =
2024
-
[31]
2024 , eprint =
The. 2024 , eprint =
2024
-
[32]
Proceedings of the 38th Annual Computer Security Applications Conference (ACSAC) , year =
Boosting Neural Networks to Decompile Optimized Binaries , author =. Proceedings of the 38th Annual Computer Security Applications Conference (ACSAC) , year =
-
[33]
2024 , eprint =
Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study , author =. 2024 , eprint =
2024
-
[34]
2024 , eprint =
Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study , author =. 2024 , eprint =
2024
-
[35]
Proceedings of the 45th International Conference on Software Engineering (ICSE) , pages =
Automated Program Repair in the Era of Large Pre-trained Language Models , author =. Proceedings of the 45th International Conference on Software Engineering (ICSE) , pages =. 2023 , doi =
2023
-
[36]
and Bu, H
Zhang, J. and Bu, H. and Wen, H. and Chen, Y. and Li, L. and Zhu, H. , journal =. When. 2025 , doi =
2025
-
[37]
2024 , eprint =
Large Language Models for Cyber Security: A Systematic Literature Review , author =. 2024 , eprint =
2024
-
[38]
2025 , eprint =
Exploring Large Language Models for Semantic Analysis and Categorization of Android Malware , author =. 2025 , eprint =
2025
-
[39]
Lu, Haolang and Peng, Hongrui and Nan, Guoshun and Cui, Jiaoyang and Wang, Cheng and Jin, Weifei and Wang, Songlin and Pan, Shengli and Tao, Xiaofeng , year =. 2406.18379 , archivePrefix =
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.