Multi-LCB: Extending LiveCodeBench to Multiple Programming Languages
Pith reviewed 2026-06-26 17:36 UTC · model grok-4.3
The pith
Multi-LCB converts LiveCodeBench problems to twelve languages to evaluate LLM code generation beyond Python.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
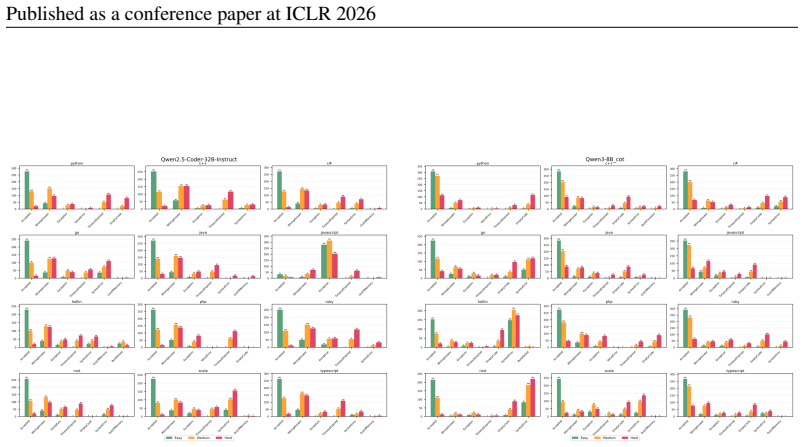
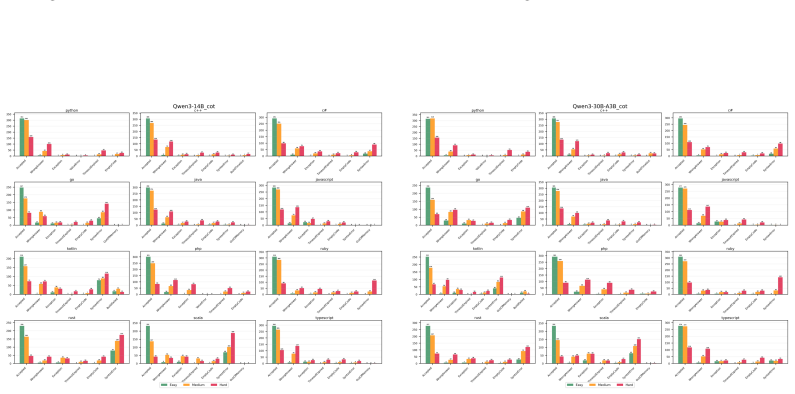
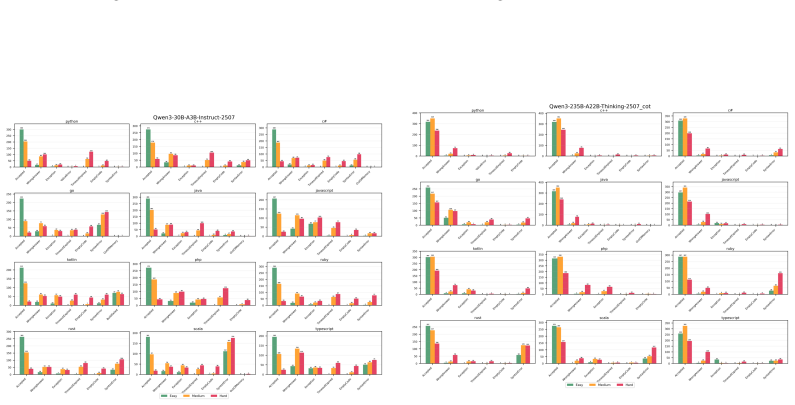
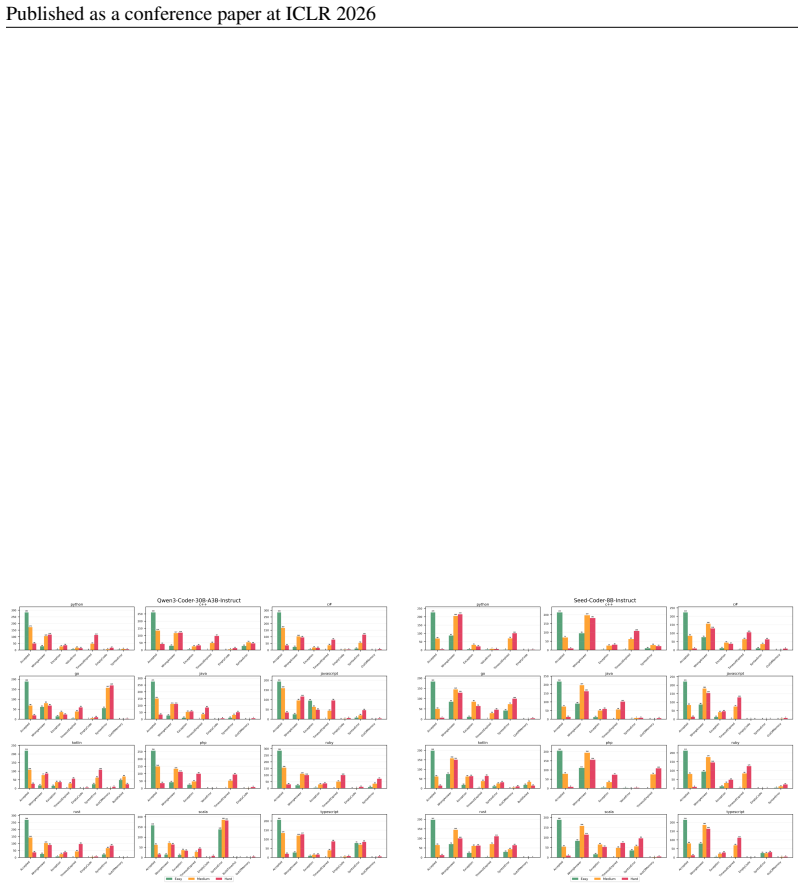
Multi-LCB transforms Python tasks from the LCB dataset into equivalent tasks in other languages while preserving LCB's contamination controls and evaluation protocol. Because it is fully compatible with the original LCB format, Multi-LCB will automatically track future LCB updates, enabling systematic assessment of cross-language code generation competence and requiring models to sustain performance well beyond Python. Evaluations of twenty-four LLMs uncover evidence of Python overfitting, language-specific contamination, and substantial disparities in multilingual performance.
What carries the argument
Translation of Python competitive programming tasks into equivalent tasks in other languages that preserves contamination controls and the original evaluation protocol.
If this is right
- LLMs display Python overfitting in code generation performance.
- Language-specific contamination affects evaluation results for different languages.
- Performance exhibits substantial disparities across the twelve programming languages.
- Multi-LCB remains compatible with ongoing LiveCodeBench updates for continued tracking.
Where Pith is reading between the lines
- Training data for LLMs may need more balanced exposure to non-Python languages to reduce the observed gaps.
- Future benchmarks could benefit from including problems written natively in each target language rather than relying solely on translations.
- The size of the performance gaps may indicate limits in how current model architectures share representations across languages.
Load-bearing premise
Translating Python competitive programming tasks into other languages preserves the original difficulty, contamination controls, and evaluation validity without introducing language-specific artifacts or changes in problem semantics.
What would settle it
A side-by-side comparison in which human programmers solve both the original Python problems and their translations in another language at materially different rates would show that equivalence does not hold.
Figures
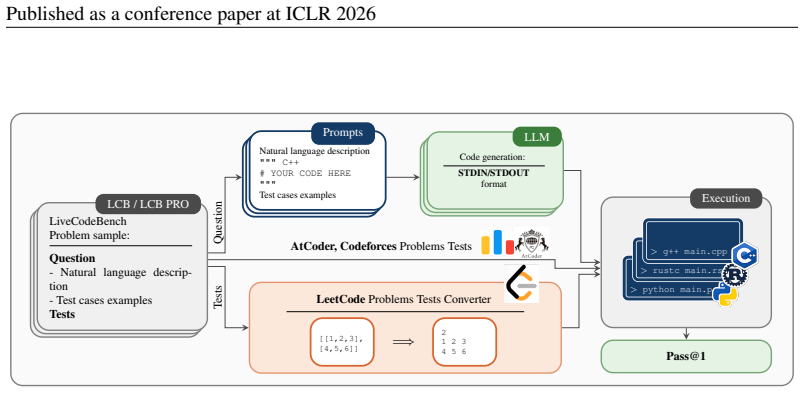

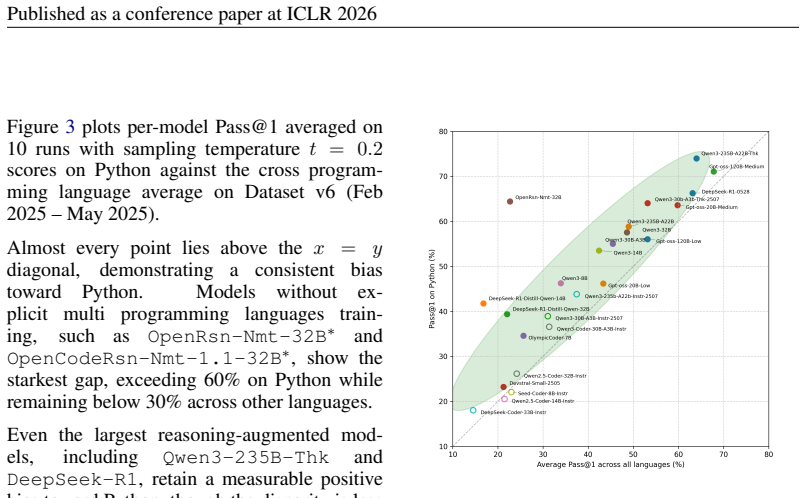
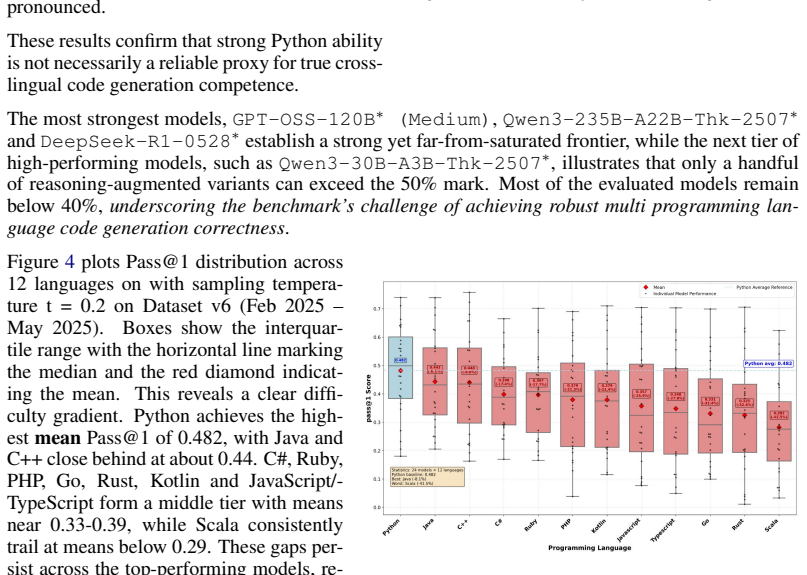
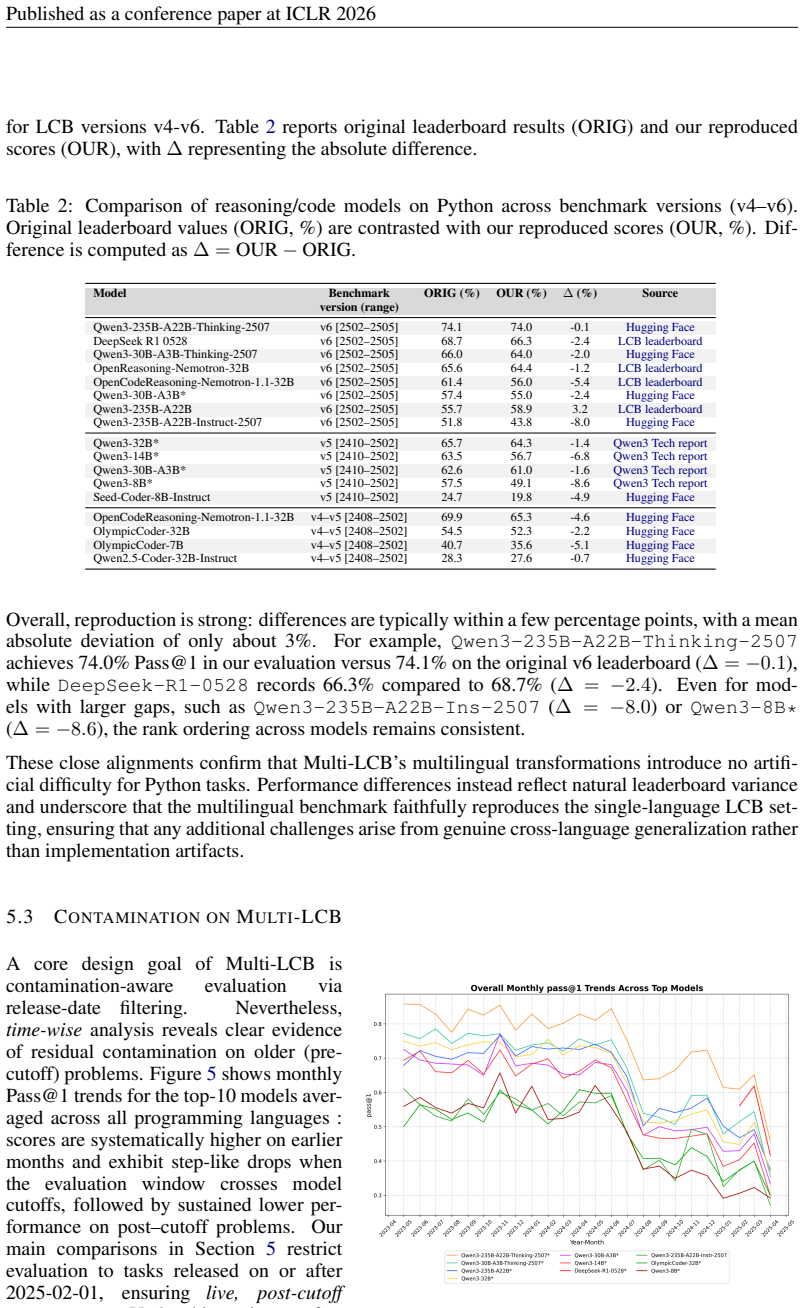


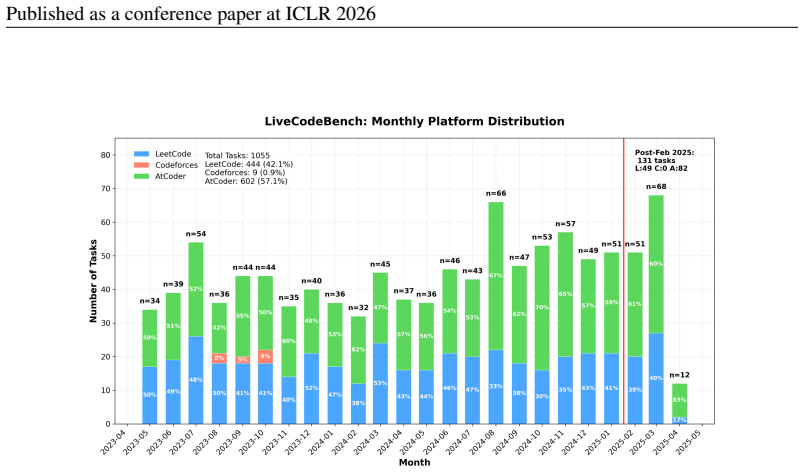
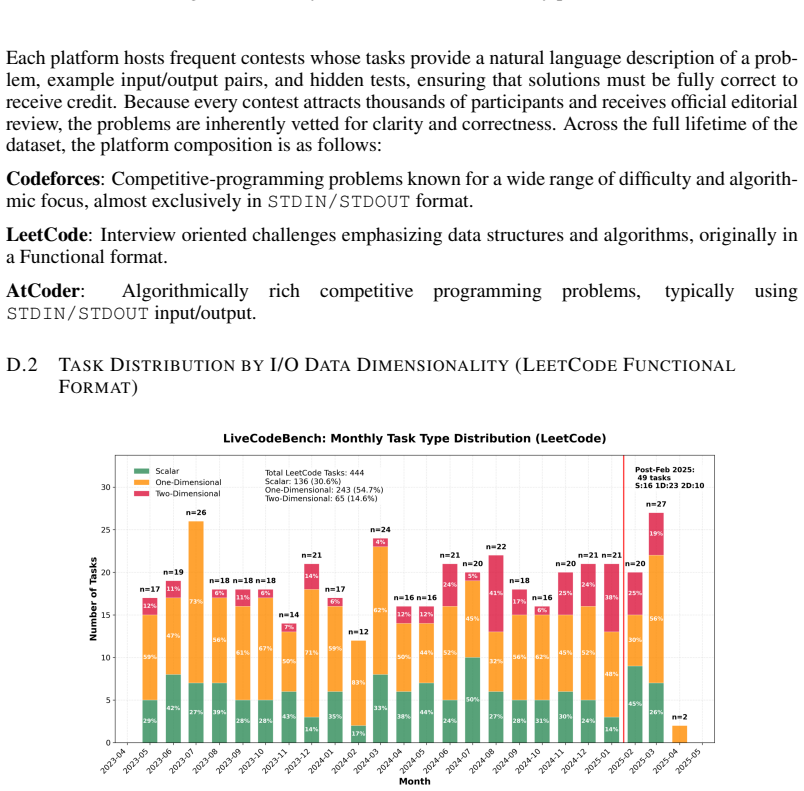

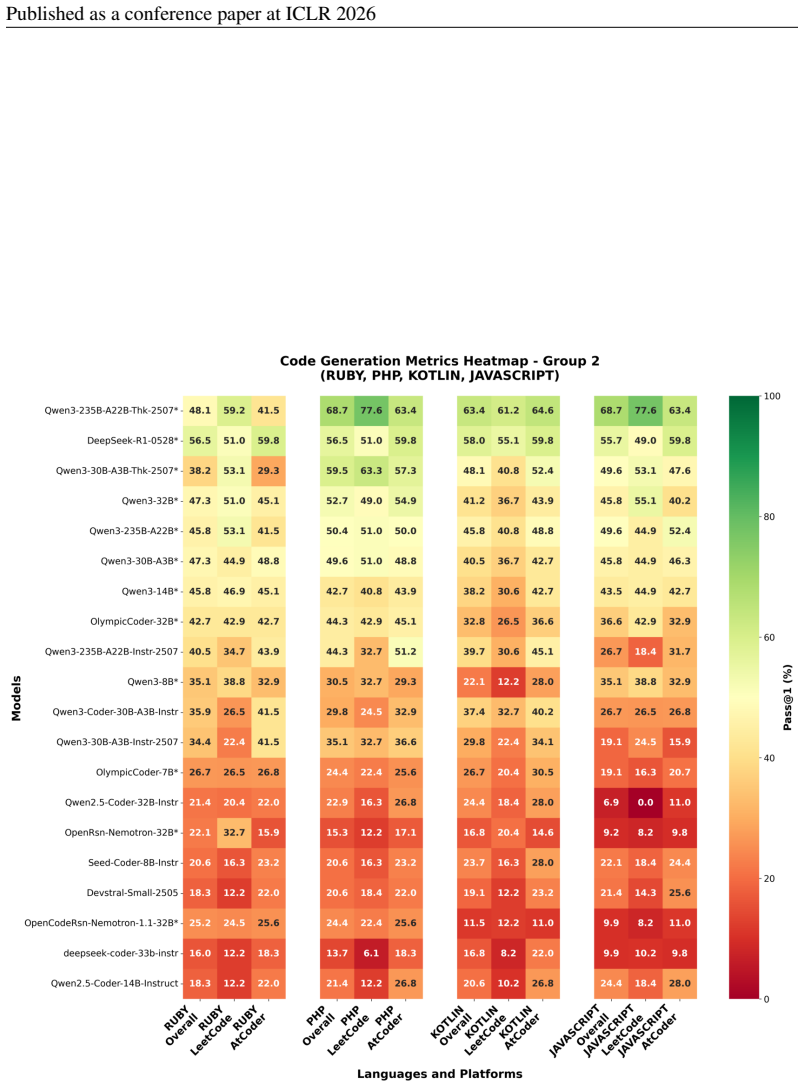
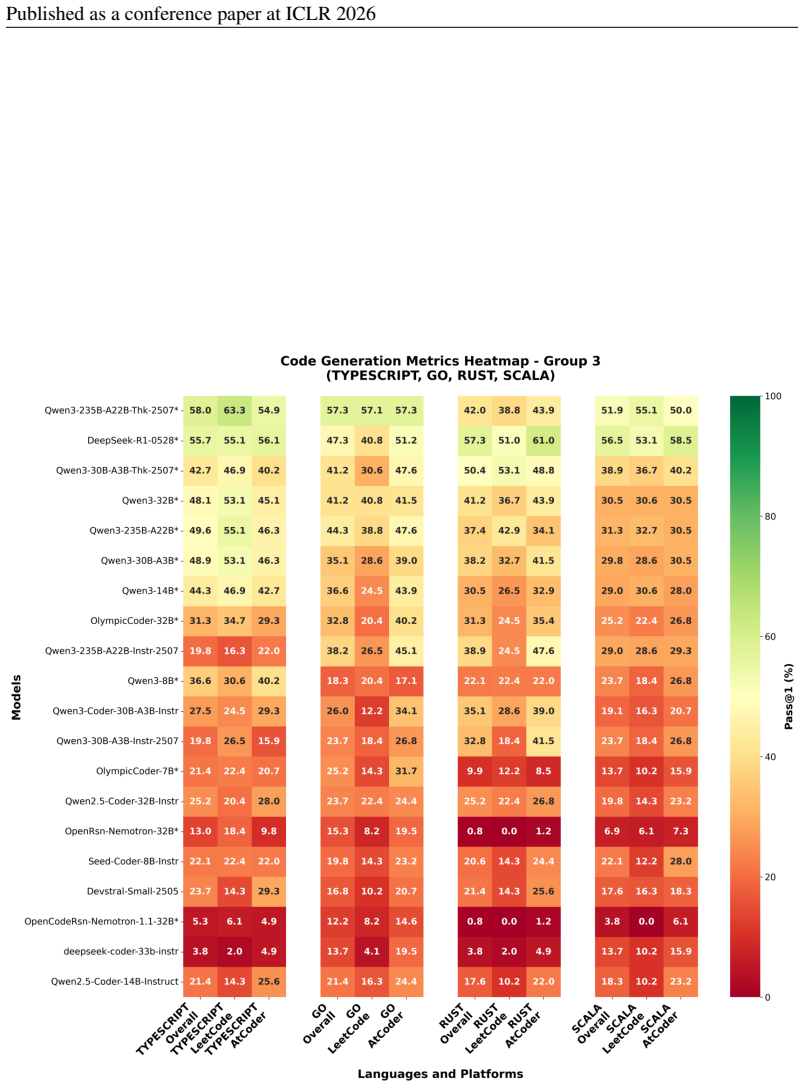
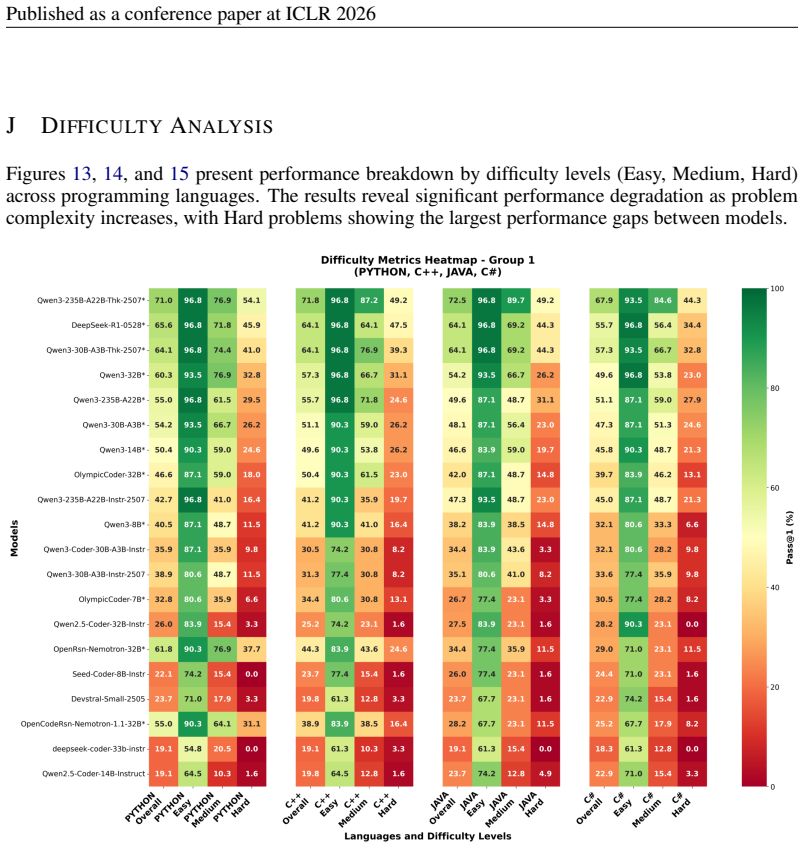
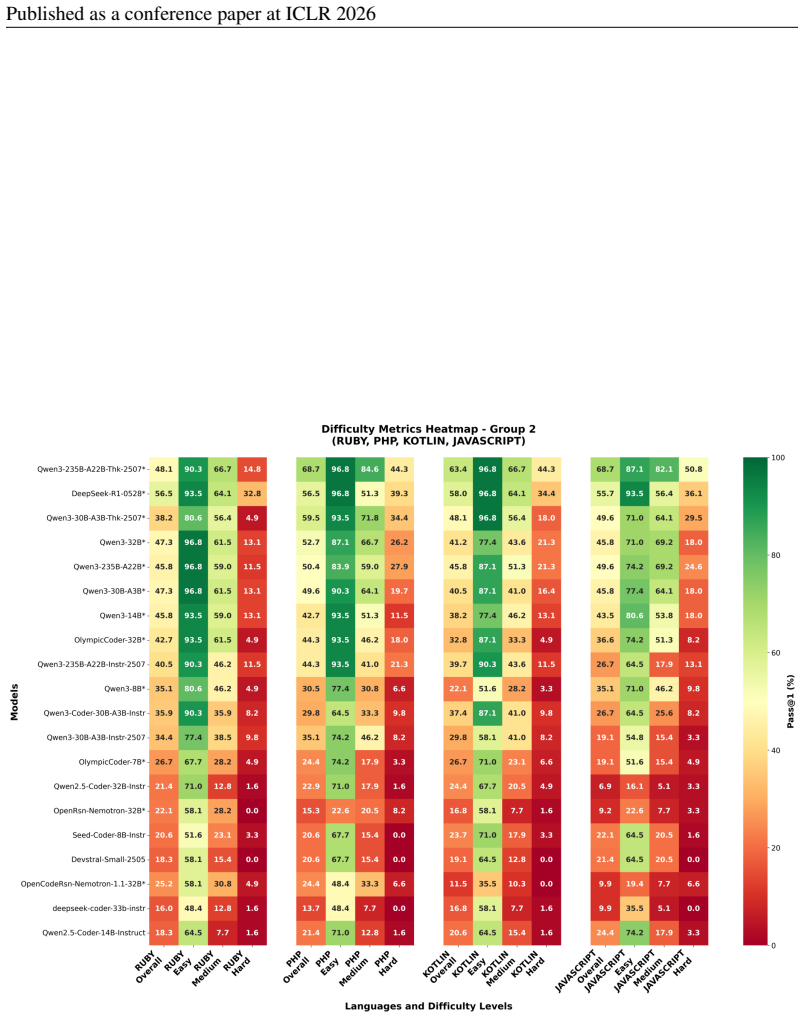
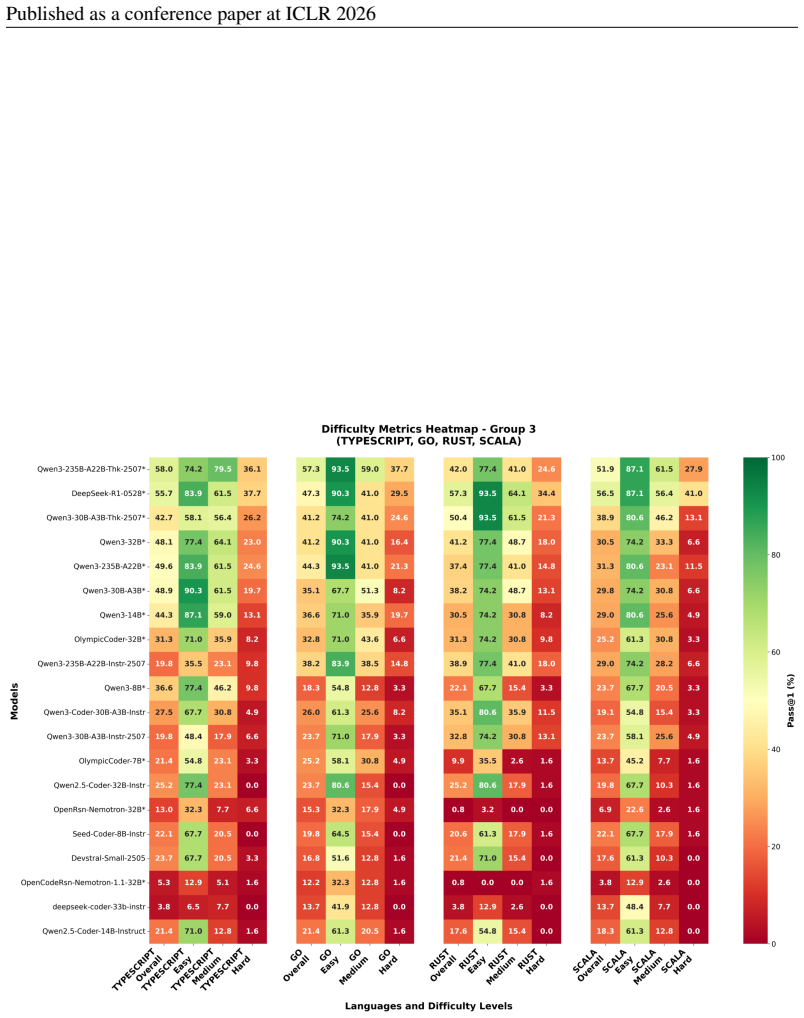
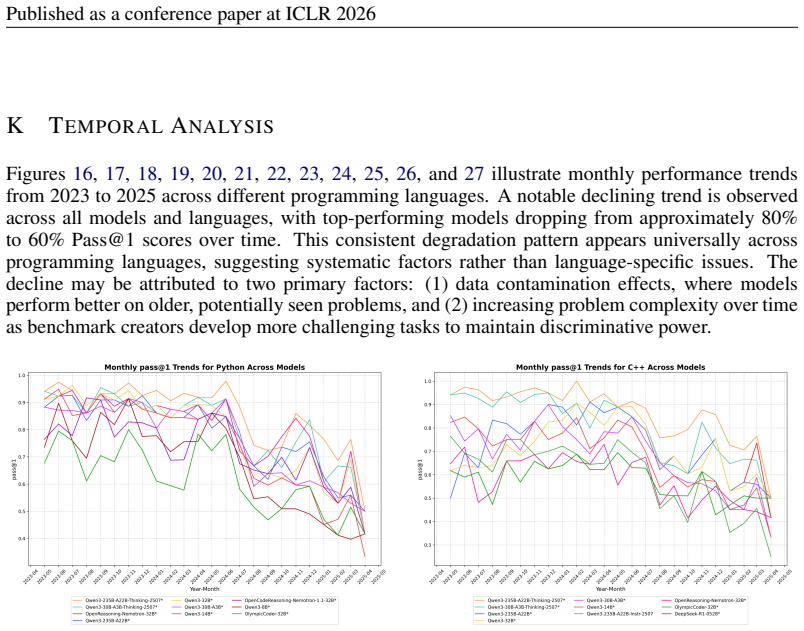
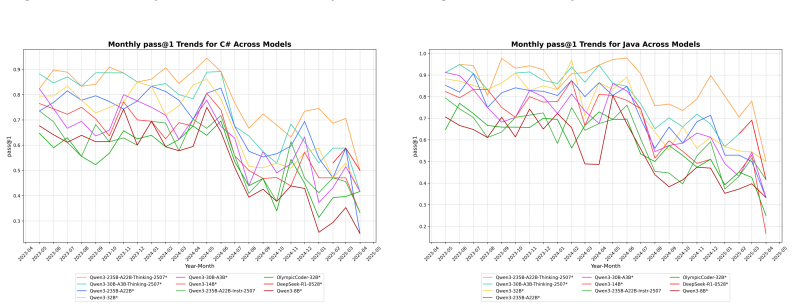
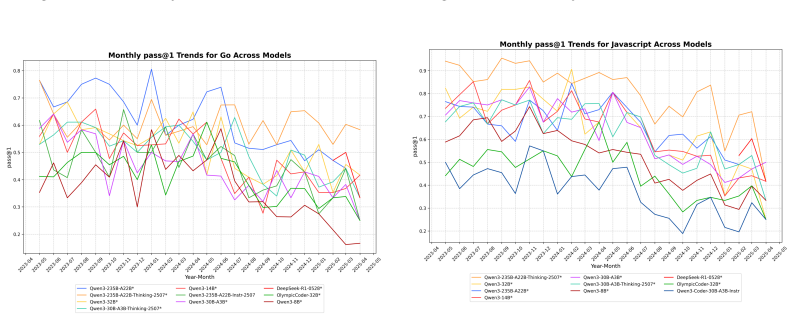
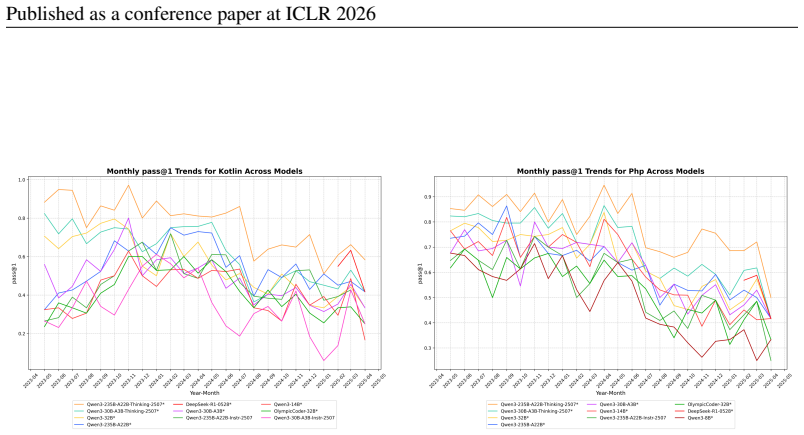
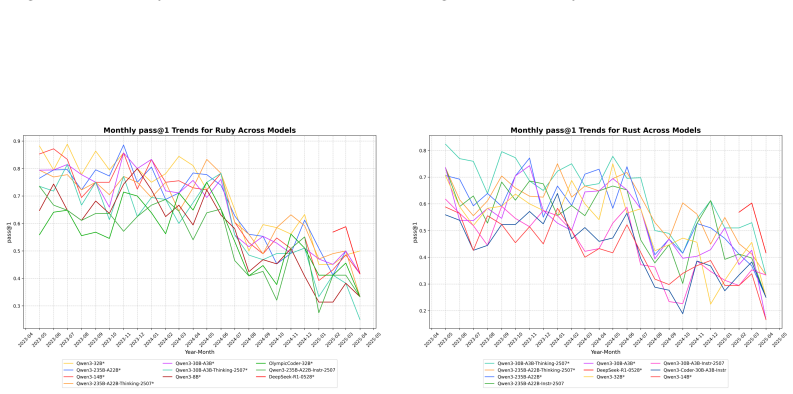
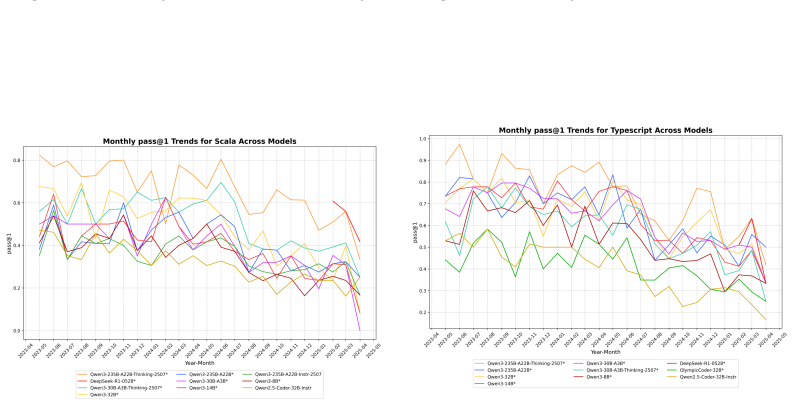

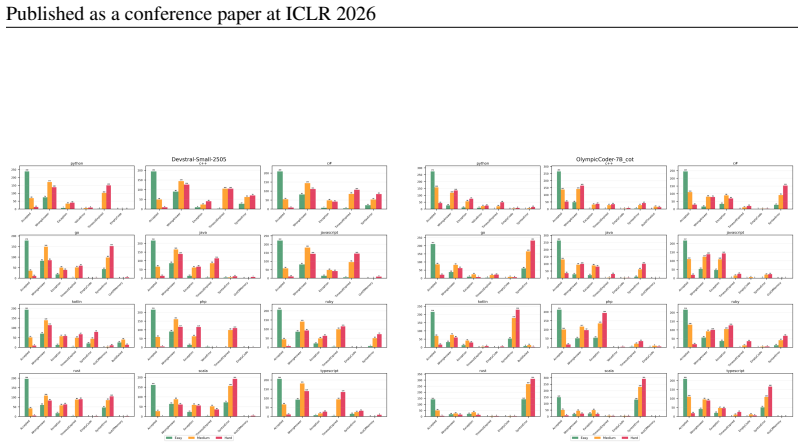
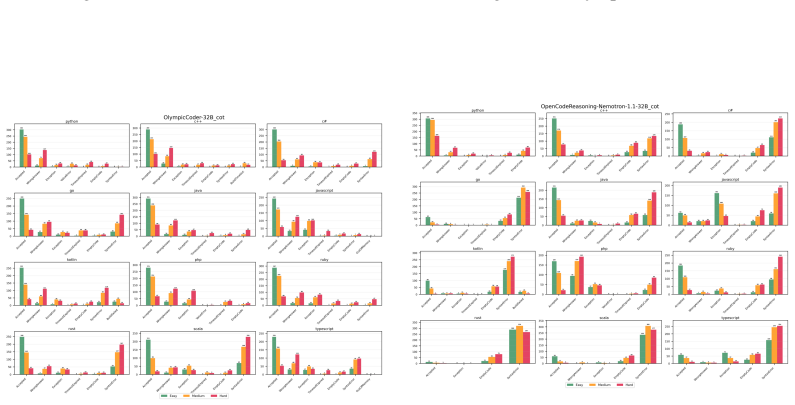
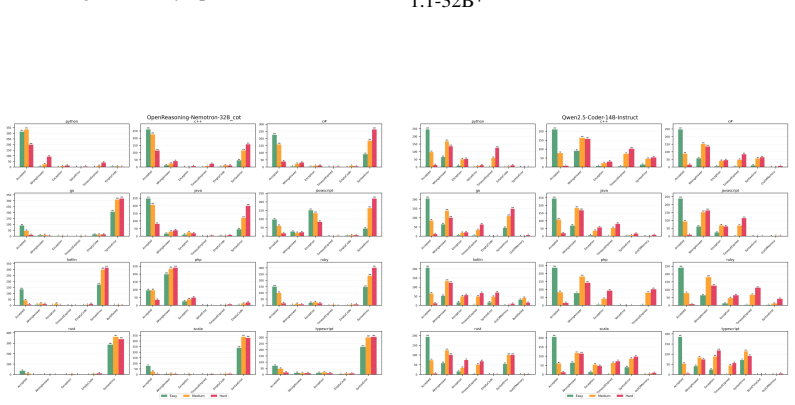
read the original abstract
LiveCodeBench (LCB) has recently become a widely adopted benchmark for evaluating large language models (LLMs) on code-generation tasks. By curating competitive programming problems, constantly adding fresh problems to the set, and filtering them by release dates, LCB provides contamination-aware evaluation and offers a holistic view of coding capability. However, LCB remains restricted to Python, leaving open the question of whether LLMs can generalize across the diverse programming languages required in real-world software engineering. We introduce Multi-LCB, a benchmark for evaluating LLMs across twelve programming languages, including Python. Multi-LCB transforms Python tasks from the LCB dataset into equivalent tasks in other languages while preserving LCB's contamination controls and evaluation protocol. Because it is fully compatible with the original LCB format, Multi-LCB will automatically track future LCB updates, enabling systematic assessment of cross-language code generation competence and requiring models to sustain performance well beyond Python. We evaluated 24 LLMs for instruction and reasoning on Multi-LCB, uncovering evidence of Python overfitting, language-specific contamination, and substantial disparities in multilingual performance. Our results establish Multi-LCB as a rigorous new benchmark for multi-programming-language code evaluation, directly addressing LCB's primary limitation and exposing critical gaps in current LLM capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Multi-LCB, an extension of LiveCodeBench to twelve programming languages obtained by translating Python competitive-programming tasks while claiming to preserve LCB's contamination controls and evaluation protocol. It reports an evaluation of 24 LLMs that uncovers Python overfitting, language-specific contamination, and cross-language performance disparities, positioning Multi-LCB as a rigorous multilingual benchmark that will automatically track future LCB updates.
Significance. If the translation procedure can be shown to maintain problem difficulty, semantics, and contamination status, the resulting benchmark would supply a needed contamination-aware instrument for measuring cross-language code generation and would enable systematic tracking of multilingual competence beyond Python-only evaluation.
major comments (3)
- [Abstract] Abstract and translation-procedure section: the central claim that translated tasks remain 'equivalent' and preserve 'evaluation validity' rests on an untested invariance assumption; no quantitative checks (human solve-rate parity, test-case coverage equivalence, or matched-pair performance correlation) are supplied to confirm that language-specific idioms and library differences do not alter difficulty or semantics.
- [Evaluation] Evaluation section (24-model results): reported evidence of Python overfitting and language disparities cannot be assessed for robustness because the manuscript supplies no controls or ablation that isolate translation-induced artifacts from genuine model limitations.
- [Benchmark construction] Benchmark-construction description: the statement that Multi-LCB 'automatically track[s] future LCB updates' presupposes that the translation pipeline can be reapplied without reintroducing contamination or difficulty drift; no protocol or validation for this ongoing process is described.
minor comments (2)
- [Abstract] The abstract states 'twelve programming languages, including Python' but does not enumerate the languages; a table or explicit list would improve clarity.
- [Introduction] Consider adding a short related-work paragraph contrasting Multi-LCB with existing multilingual code benchmarks to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging where the manuscript requires strengthening and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and translation-procedure section: the central claim that translated tasks remain 'equivalent' and preserve 'evaluation validity' rests on an untested invariance assumption; no quantitative checks (human solve-rate parity, test-case coverage equivalence, or matched-pair performance correlation) are supplied to confirm that language-specific idioms and library differences do not alter difficulty or semantics.
Authors: We agree that the current description relies on an untested assumption of equivalence. The translations were performed manually by experienced programmers following semantic-preserving guidelines, but no quantitative validation (such as human solve-rate parity or performance correlation) was reported. In revision we will add a dedicated subsection on the translation procedure that includes: (1) explicit handling rules for language-specific idioms and libraries, (2) a small-scale human study comparing perceived difficulty on a random subset of 50 problems across languages, and (3) test-case coverage statistics before and after translation. These additions will directly test the invariance claim. revision: yes
-
Referee: [Evaluation] Evaluation section (24-model results): reported evidence of Python overfitting and language disparities cannot be assessed for robustness because the manuscript supplies no controls or ablation that isolate translation-induced artifacts from genuine model limitations.
Authors: The referee correctly notes the absence of controls for translation artifacts. We will add two analyses in the revised evaluation section: (1) an ablation translating a subset of Python problems back into Python and measuring performance drop relative to the original, and (2) correlation of per-problem scores across language pairs for models with documented strong multilingual training. These controls will help separate translation effects from intrinsic model limitations and increase confidence in the reported overfitting and disparity findings. revision: yes
-
Referee: [Benchmark construction] Benchmark-construction description: the statement that Multi-LCB 'automatically track[s] future LCB updates' presupposes that the translation pipeline can be reapplied without reintroducing contamination or difficulty drift; no protocol or validation for this ongoing process is described.
Authors: We acknowledge that the claim of automatic tracking requires an explicit, repeatable protocol. The revised manuscript will include a new subsection that formalizes the pipeline: (a) reuse of LCB's release-date filtering to maintain contamination controls, (b) mandatory equivalence checks (test-case coverage and semantic review) on every new batch, and (c) a schedule for periodic human validation to detect difficulty drift. This protocol will be presented as part of the benchmark release so that future updates remain rigorous. revision: yes
Circularity Check
No circularity detected; benchmark construction is self-contained
full rationale
The manuscript describes the creation of Multi-LCB via translation of existing LCB Python problems into twelve languages while asserting preservation of contamination controls and evaluation protocol. No equations, derivations, fitted parameters, or predictions appear in the provided text. Claims rest on the independent translation process rather than reducing to self-citations, self-definitions, or renamed inputs. The central premise does not invoke load-bearing prior results by the same authors that would create a circular chain; external LCB is treated as given input without the paper's own results feeding back into its validity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2401.08500 , year=
Code generation with alphacodium: From prompt engineering to flow engineering , author=. arXiv preprint arXiv:2401.08500 , year=
-
[6]
StarCoder 2 and The Stack v2: The Next Generation
Starcoder 2 and the stack v2: The next generation , author=. arXiv preprint arXiv:2402.19173 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Codegen: An open large language model for code with multi-turn program synthesis , author=. arXiv preprint arXiv:2203.13474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[10]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gemini 2.5: Our most intelligent AI model , year =
-
[13]
DeepSeek-R1-0528 Release , year =
-
[14]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2506.11928 , year=
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming? , author=. arXiv preprint arXiv:2506.11928 , year=
-
[16]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[17]
Advances in neural information processing systems , volume=
Sglang: Efficient execution of structured language model programs , author=. Advances in neural information processing systems , volume=
-
[18]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2404.00599 , year=
Evocodebench: An evolving code generation benchmark aligned with real-world code repositories , author=. arXiv preprint arXiv:2404.00599 , year=
-
[22]
arXiv preprint arXiv:2508.04865 , year=
Agnostics: Learning to Code in Any Programming Language via Reinforcement with a Universal Learning Environment , author=. arXiv preprint arXiv:2508.04865 , year=
-
[23]
arXiv preprint arXiv:2303.03004 , year=
xcodeeval: A large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval , author=. arXiv preprint arXiv:2303.03004 , year=
-
[24]
arXiv preprint arXiv:2406.07436 , year=
Mceval: Massively multilingual code evaluation , author=. arXiv preprint arXiv:2406.07436 , year=
-
[25]
IEEE Transactions on Software Engineering , volume=
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation , author=. IEEE Transactions on Software Engineering , volume=. 2023 , publisher=
2023
-
[26]
arXiv preprint arXiv:2402.16694 , year=
Humaneval-xl: A multilingual code generation benchmark for cross-lingual natural language generalization , author=. arXiv preprint arXiv:2402.16694 , year=
-
[27]
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Codexglue: A machine learning benchmark dataset for code understanding and generation , author=. arXiv preprint arXiv:2102.04664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions , author=. arXiv preprint arXiv:2406.15877 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2210.14868 , year=
Multi-lingual evaluation of code generation models , author=. arXiv preprint arXiv:2210.14868 , year=
-
[30]
Information Discovery and Delivery , volume=
Introducing mathqa: a math-aware question answering system , author=. Information Discovery and Delivery , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.