UNIEGO: Proxies as Mediators for Unified Egocentric Video Representation Learning
Pith reviewed 2026-06-26 18:23 UTC · model grok-4.3
The pith
Proxy models translate knowledge from nine heterogeneous teachers into a unified egocentric video encoder that outperforms direct distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
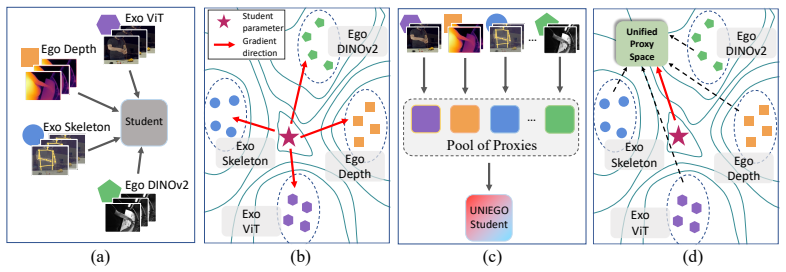
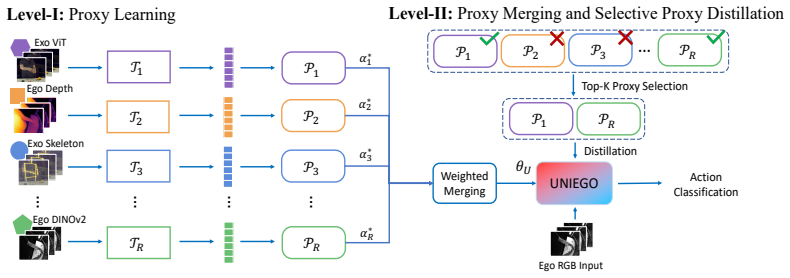
A unified egocentric encoder can be trained by first mapping nine teachers spanning ego-exo views, RGB, depth, skeleton, and foundation models into representation-specific proxy models that create a homogeneous space, then applying selective proxy distillation that retains only reliable signals per sample, with the student initialized as a learned convex combination of the proxies; this structured mediation yields richer egocentric representations than direct multi-teacher distillation.
What carries the argument
Representation-specific Proxy models that convert heterogeneous teacher knowledge into a homogeneous egocentric space, paired with Selective Proxy Distillation that adaptively keeps only correct and confident signals.
If this is right
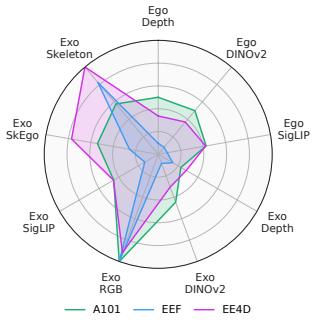
- UNIEGO exceeds naive multi-teacher distillation on action recognition, video retrieval, and action segmentation across three ego-exo benchmarks.
- The two-stage proxy mediation followed by selective distillation produces more discriminative egocentric features than unmediated transfer.
- Initializing the student as a convex combination of proxy parameters places the optimization in a better-conditioned region of the loss landscape.
- The framework remains deployable from egocentric video alone while subsuming complementary knowledge from exo, depth, skeleton, and foundation-model sources.
Where Pith is reading between the lines
- The proxy-mediation pattern could be applied to other multi-source distillation settings where direct fusion produces gradient conflicts.
- Selective per-sample filtering may reduce sensitivity to the choice or quality of individual teachers in large-scale distillation.
- If the convex-combination initialization proves critical, similar warm-start strategies might stabilize other multi-teacher training regimes.
Load-bearing premise
The proxy models can convert knowledge from teachers with different architectures and feature geometries into a single homogeneous space without substantial distortion or conflicting gradients.
What would settle it
An experiment in which direct distillation from the same nine teachers without any proxy layer produces equal or higher accuracy than the full UNIEGO pipeline on the three reported benchmarks.
Figures
read the original abstract
Egocentric video understanding is inherently limited by the narrow perspective of wearable cameras: a single viewpoint, a single modality, a single model cannot capture the full richness of human action. We argue that a truly expressive egocentric representation must subsume complementary knowledge across viewpoints, modalities, and foundation model representations, yet remain deployable from egocentric video alone. To this end, we introduce a hierarchical multi-teacher distillation framework that produces UNIEGO, a unified egocentric encoder trained with nine teachers spanning ego-exo viewpoints, RGB, depth, and skeleton modalities, and four foundation models. Rather than distilling directly from heterogeneous teachers whose incompatible architectures and feature geometries induce conflicting gradients, our framework interposes a layer of representation-specific Proxy models that translate diverse teacher knowledge into a homogeneous egocentric space. A second distillation stage, Selective Proxy Distillation (SPD), then adaptively selects, for each training sample, the subset of proxies that are both correct and confident, distilling exclusively from reliable supervision and suppressing erroneous signals. SPD is further stabilized by initializing UNIEGO as a learned convex combination of proxy parameters, placing the unified model in a well-conditioned region of the loss landscape before distillation begins. UNIEGO achieves state-of-the-art performance across three egocentric video understanding tasks - action recognition, video retrieval, and action segmentation on three challenging ego-exo benchmarks, outperforming naive multi-teacher distillation baselines and demonstrating that structured, proxy-mediated knowledge transfer yields richer and more discriminative egocentric representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UNIEGO, a unified egocentric video encoder trained via hierarchical multi-teacher distillation from nine teachers spanning ego-exo viewpoints, RGB/depth/skeleton modalities, and four foundation models. Representation-specific Proxy models first translate the heterogeneous teacher knowledge into a homogeneous egocentric space; Selective Proxy Distillation (SPD) then adaptively selects per-sample reliable and confident proxy signals while suppressing erroneous ones. The unified model is initialized as a learned convex combination of the proxy parameters. The paper claims this yields state-of-the-art performance on action recognition, video retrieval, and action segmentation across three ego-exo benchmarks, outperforming naive multi-teacher distillation baselines.
Significance. If the empirical superiority holds and the proxy-mediated transfer demonstrably avoids distortion, the work would offer a practical route to richer egocentric representations that remain deployable from single-view video alone. The two-stage structure with selective per-sample distillation and convex initialization provides a concrete mechanism for managing heterogeneous supervision that could generalize beyond the reported benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that UNIEGO achieves SOTA performance and outperforms naive multi-teacher distillation is asserted without any reported metrics, dataset identifiers, ablation numbers, or error analysis, so the performance advantage cannot be evaluated from the provided text.
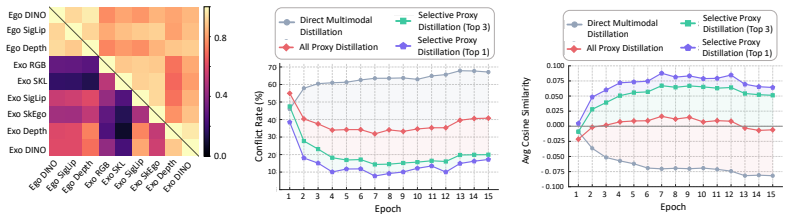
- [Abstract] Proxy-model and SPD description (abstract): the claim that structured proxy-mediated transfer yields richer representations rests on the untested premise that the representation-specific Proxies map heterogeneous teachers into homogeneous space without substantial distortion or conflicting gradients; no alignment, reconstruction-error, or gradient-norm evidence is supplied to support this load-bearing assumption.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the three ego-exo benchmarks and the nine teachers explicitly rather than describing them generically.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will incorporate revisions to strengthen the presentation of results and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that UNIEGO achieves SOTA performance and outperforms naive multi-teacher distillation is asserted without any reported metrics, dataset identifiers, ablation numbers, or error analysis, so the performance advantage cannot be evaluated from the provided text.
Authors: We agree that the abstract would be more informative with quantitative support. The full manuscript contains tables reporting exact metrics (e.g., top-1 accuracy on Ego4D, EPIC-Kitchens, and Charades-Ego), dataset names, and ablation results comparing UNIEGO to naive multi-teacher distillation. In the revised manuscript we will condense the key numbers, dataset identifiers, and a reference to the ablation study into the abstract. revision: yes
-
Referee: [Abstract] Proxy-model and SPD description (abstract): the claim that structured proxy-mediated transfer yields richer representations rests on the untested premise that the representation-specific Proxies map heterogeneous teachers into homogeneous space without substantial distortion or conflicting gradients; no alignment, reconstruction-error, or gradient-norm evidence is supplied to support this load-bearing assumption.
Authors: The manuscript demonstrates the practical benefit of the proxy layer through consistent gains over direct multi-teacher distillation and through selective-distillation ablations. We acknowledge, however, that direct measurements of proxy-teacher alignment, reconstruction error, or per-layer gradient norms are not reported. We will add these analyses (feature cosine similarity, reconstruction MSE, and gradient-norm statistics) to the revised experimental section to provide explicit support for the homogeneity assumption. revision: yes
Circularity Check
No circularity; empirical training procedure with external benchmark validation
full rationale
The paper presents a hierarchical multi-teacher distillation method using representation-specific Proxy models followed by Selective Proxy Distillation (SPD) to train UNIEGO. All claims rest on reported empirical performance gains across action recognition, retrieval, and segmentation tasks on ego-exo benchmarks, compared against naive multi-teacher baselines. No equations, self-definitional constructs, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the derivation chain consists of a standard training pipeline whose outputs are validated externally rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge distillation from heterogeneous teachers is feasible once feature geometries are aligned via intermediate proxies.
invented entities (1)
-
Proxy models
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ticon: A slide-level tile contextualizer for histopathology representation learning, 2025
Varun Belagali, Saarthak Kapse, Pierre Marza, Srijan Das, Zilinghan Li, Sofiène Boutaj, Pushpak Pati, Srikar Yellapragada, Tarak Nath Nandi, Ravi K Madduri, Joel Saltz, Prateek Prasanna, Stergios Christodoulidis, Maria Vakalopoulou, and Dimitris Samaras. Ticon: A slide-level tile contextualizer for histopathology representation learning, 2025
2025
-
[2]
Is space-time attention all you need for video understanding? InProceedings of the International Conference on Machine Learning (ICML), July 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InProceedings of the International Conference on Machine Learning (ICML), July 2021
2021
-
[3]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press, 2004
2004
-
[4]
Openpose: Realtime multi-person 2d pose estimation using part affinity fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019
Zhe Cao, Gines Hidalgo Martinez, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019
2019
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021
2021
-
[6]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. InConference on Computer Vision and Pattern Recognition, pages 4724–4733. IEEE, 2017
2017
-
[7]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The epic-kitchens dataset. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[8]
Vpn++: Rethinking video-pose embed- dings for understanding activities of daily living.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2021
Srijan Das, Rui Dai, Di Yang, and Francois Bremond. Vpn++: Rethinking video-pose embed- dings for understanding activities of daily living.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2021
2021
-
[9]
Vpn: Learning video-pose embedding for activities of daily living
Srijan Das, Saurav Sharma, Rui Dai, Francois Bremond, and Monique Thonnat. Vpn: Learning video-pose embedding for activities of daily living. InEuropean Conference on Computer Vision, pages 72–90. Springer, 2020
2020
-
[10]
Unlocking exocentric video-language data for egocentric video representation learning, 2024
Zi-Yi Dou, Xitong Yang, Tushar Nagarajan, Huiyu Wang, Jing Huang, Nanyun Peng, Kris Kitani, and Fu-Jen Chu. Unlocking exocentric video-language data for egocentric video representation learning, 2024
2024
-
[11]
Linear mode connectivity and the lottery ticket hypothesis
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M Roy, and Michael Carlin. Linear mode connectivity and the lottery ticket hypothesis. InInternational Conference on Machine Learning (ICML), 2020
2020
-
[12]
Mmg-ego4d: Multi-modal generalization in egocentric action recognition
Xinyu Gong, Sreyas Mohan, Naina Dhingra, Jean-Charles Bazin, Yilei Li, Zhangyang Wang, and Rakesh Ranjan. Mmg-ego4d: Multi-modal generalization in egocentric action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[13]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Ro- hit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, 10 Vincent ...
2022
-
[14]
Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh K
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyl- los Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zachary Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, María Escobar, Cristhian Forigua, Abrham Kahsay Gebreselasie, Sanjay Haresh, Jing Hu...
2024
-
[15]
Distilling the knowledge in a neural network, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network, 2015
2015
-
[16]
Averaging weights leads to wider optima and better generalization
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. InUncertainty in Artificial Intelligence (UAI), 2018
2018
-
[17]
Learning clip representations for skeleton-based 3d action recognition.IEEE Transactions on Image Processing, 27(6):2842–2855, June 2018
Qiuhong Ke, Mohammed Bennamoun, Senjian An, Ferdous Sohel, and Farid Boussaid. Learning clip representations for skeleton-based 3d action recognition.IEEE Transactions on Image Processing, 27(6):2842–2855, June 2018
2018
-
[18]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[19]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[20]
Uniformer: Unifying convolution and self-attention for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45:12581–12600, 2022
Kunchang Li, Yali Wang, Junhao Zhang, Peng Gao, Guanglu Song, Yu Liu, Hongsheng Li, and Yu Jiao Qiao. Uniformer: Unifying convolution and self-attention for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45:12581–12600, 2022
2022
-
[21]
Ego-exo: Transferring visual representations from third-person to first-person videos
Yanghao Li, Tushar Nagarajan, Bo Xiong, and Kristen Grauman. Ego-exo: Transferring visual representations from third-person to first-person videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10995–11005, 2021. 11
2021
-
[22]
Egoexo-fitness: towards egocentric and exocentric full-body action understanding
Yuan-Ming Li, Wei-Jin Huang, An-Lan Wang, Ling-An Zeng, Jing-Ke Meng, and Wei-Shi Zheng. Egoexo-fitness: towards egocentric and exocentric full-body action understanding. In European Conference on Computer Vision, pages 363–382. Springer, 2024
2024
-
[23]
Tsm: Temporal shift module for efficient video understand- ing
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understand- ing. InProceedings of the IEEE International Conference on Computer Vision, 2019
2019
-
[24]
Egocentric video- language pretraining.arXiv preprint arXiv:2206.01670, 2022
Kevin Qinghong Lin, Alex Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Zhong- cong Xu, Difei Gao, Rongcheng Tu, Wenzhe Zhao, Weijie Kong, et al. Egocentric video- language pretraining.arXiv preprint arXiv:2206.01670, 2022
arXiv 2022
-
[25]
Conflict-averse gradient descent for multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 18873–18885. Curran Associates, Inc., 2021
2021
-
[26]
Adaptive multi-teacher multi-level knowledge distillation
Yuang Liu, Wei Zhang, and Jun Wang. Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing, 2020
2020
-
[27]
Viewpoint rosetta stone: Unlocking unpaired ego-exo videos for view-invariant representation learning
Mi Luo, Zihui Xue, Alex Dimakis, and Kristen Grauman. Viewpoint rosetta stone: Unlocking unpaired ego-exo videos for view-invariant representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[28]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[29]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Hervé Jégou, Julien Mairal, Patrick Laba...
2024
-
[30]
3d human pose estimation in video with temporal convolutions and semi-supervised training
Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 3d human pose estimation in video with temporal convolutions and semi-supervised training. InConference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[31]
Egovlpv2: Egocentric video-language pre- training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre- training with fusion in the backbone. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5285–5297, 2023
2023
-
[32]
Synchronization is all you need: Exocentric-to-egocentric transfer for temporal action segmentation with unlabeled synchronized video pairs
Camillo Quattrocchi, Antonino Furnari, Daniele Di Mauro, Mario Valerio Giuffrida, and Giovanni Maria Farinella. Synchronization is all you need: Exocentric-to-egocentric transfer for temporal action segmentation with unlabeled synchronized video pairs. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[33]
Multimodal distillation for egocentric action recognition
Gorjan Radevski, Dusan Grujicic, Marie-Francine Moens, Matthew Blaschko, and Tinne Tuytelaars. Multimodal distillation for egocentric action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[34]
Am-radio: Agglomera- tive vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomera- tive vision foundation model reduce all domains into one. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
-
[35]
Finetuned clip models are efficient video learners
Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, and Fa- had Shahbaz Khan. Finetuned clip models are efficient video learners. InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[36]
Just add π! pose induced video transformers for understanding activities of daily living
Dominick Reilly and Srijan Das. Just add π! pose induced video transformers for understanding activities of daily living. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024. 12
2024
-
[37]
From my view to yours: Ego-augmented learning in large vision language models for understanding exocentric daily living activities, 2025
Dominick Reilly, Manish Kumar Govind, Le Xue, and Srijan Das. From my view to yours: Ego-augmented learning in large vision language models for understanding exocentric daily living activities, 2025
2025
-
[38]
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21064–21074, 2022
2022
-
[39]
Temporal aggregate representations for long-range video understanding
Fadime Sener, Dipika Singhania, and Angela Yao. Temporal aggregate representations for long-range video understanding. InEuropean conference on computer vision, pages 154–171. Springer, 2020
2020
-
[40]
Jinghuan Shang, Karl Schmeckpeper, Brandon B May, Maria Vittoria Minniti, Tarik Kelestemur, David Watkins, and Laura Herlant. Theia: Distilling diverse vision foundation models for robot learning.arXiv preprint arXiv:2407.20179, 2024
arXiv 2024
-
[41]
Recon: Reducing conflicting gradients from the root for multi-task learning
Guangyuan Shi, Qimai Li, Wenlong Zhang, Jiaxin Chen, and Xiao-Ming Wu. Recon: Reducing conflicting gradients from the root for multi-task learning. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[42]
Gunnar A Sigurdsson, Abhinav Gupta, Cordelia Schmid, Ali Farhadi, and Karteek Alahari. Charades-ego: A large-scale dataset of paired third and first person videos.arXiv preprint arXiv:1804.09626, 2018
Pith/arXiv arXiv 2018
-
[43]
Arkaprava Sinha, Monish Soundar Raj, Pu Wang, Ahmed Helmy, and Srijan Das. Ms- temba: Multi-scale temporal mamba for efficient temporal action detection.arXiv preprint arXiv:2501.06138, 2025
arXiv 2025
-
[44]
Shuhan Tan, Tushar Nagarajan, and Kristen Grauman. Egodistill: Egocentric head motion distillation for efficient video understanding.arXiv preprint arXiv:2301.02217, 2023
arXiv 2023
-
[45]
Roy-Chowdhury
Anirudh Thatipelli, Shao-Yuan Lo, and Amit K. Roy-Chowdhury. Egocentric and exocentric methods: A short survey.Computer Vision and Image Understanding, 257:104371, 2025
2025
-
[46]
Anyup: Universal feature upsampling
Thomas Wimmer, Prune Truong, Marie-Julie Rakotosaona, Michael Oechsle, Federico Tombari, Bernt Schiele, and Jan Eric Lenssen. Anyup: Universal feature upsampling. InProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[47]
Egodtm: Towards 3d-aware egocentric video-language pretraining
Boshen Xu, Yuting Mei, Xinbi Liu, Sipeng Zheng, and Qin Jin. Egodtm: Towards 3d-aware egocentric video-language pretraining. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[48]
Learning fine-grained view-invariant representations from unpaired ego-exo videos via temporal alignment
Zihui Xue and Kristen Grauman. Learning fine-grained view-invariant representations from unpaired ego-exo videos via temporal alignment. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[49]
Spatial temporal graph convolutional networks for skeleton-based action recognition
Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. InThirty-second AAAI conference on artificial intelligence, 2018
2018
-
[50]
Depth anything v2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. InAdvances in Neural Information Processing Systems, 2024
2024
-
[51]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 5434–5445. Curran Associates, Inc., 2020
2020
-
[52]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision. IEEE, 2023. 13
2023
-
[53]
Confidence-aware multi-teacher knowledge distillation
Hailin Zhang, Defang Chen, and Can Wang. Confidence-aware multi-teacher knowledge distillation. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[54]
Yue Zhao, Ishan Misra, Philipp Krahenbuhl, and Rohit Girdhar. Learning video representations from large language models.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6586–6597, 2022. 14 A Overview The appendix is categorized into the following parts: • Section B: Detailed Data Description • Section C: Proxy Performances...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.