MemoryVAM: Integrating Memory into Video Action Model for Robot Manipulation
Pith reviewed 2026-06-27 04:22 UTC · model grok-4.3
The pith
Memory tokens from a Perceiver compressor let video policies condition robot actions on episode history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
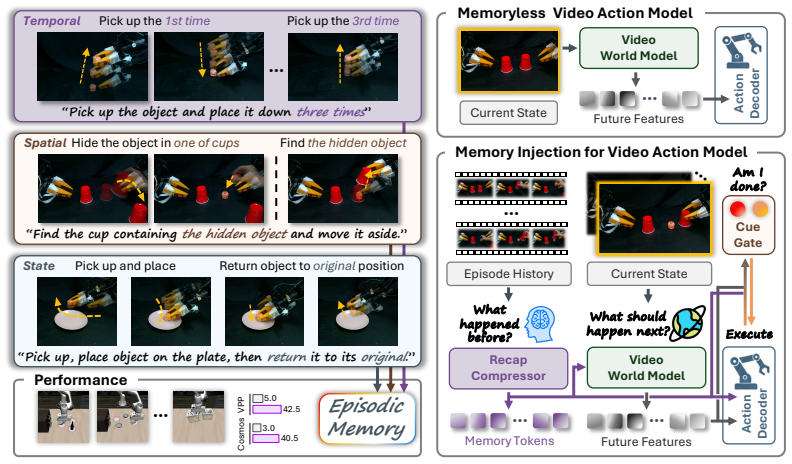
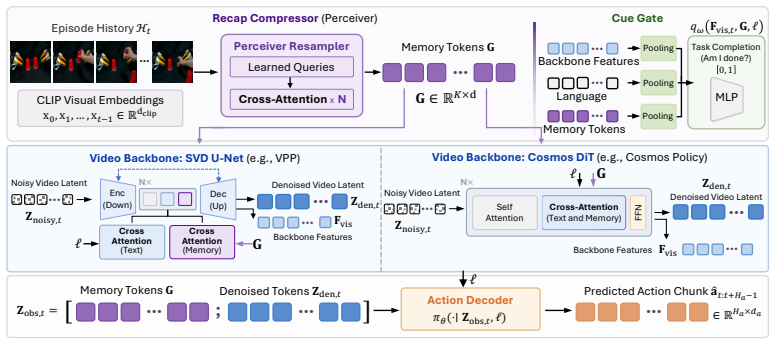
MemoryVAM introduces an episodic memory mechanism that maps past observations into compact tokens via a Perceiver Recap Compressor and a Cue Gate, then injects those tokens into the video backbone and action decoder so that policy imagination stays aligned with episode progress and actions remain conditioned on history. The memory module trains end-to-end with video prediction, delta-reconstruction, and boundary supervision, requiring no per-frame labels, and applies to different backbones by changing only the cross-attention interface.
What carries the argument
The Recap-Cue (RC) module, which uses a Perceiver-based Recap Compressor to produce compact memory tokens from CLIP embeddings and a lightweight Cue Gate to estimate task completion, then injects the tokens via cross-attention into the video backbone and action decoder.
If this is right
- The identical cross-attention injection works on both UNet and Diffusion Transformer video backbones.
- The memory module trains without any per-frame progress labels, using only video prediction, delta reconstruction, and episode-boundary signals.
- On LIBERO-Mem the model raises average success from 5 percent to 42.5 percent.
- On physical robots the same mechanism yields 78.3 percent success on counting, 80 percent on spatial recall, and 75 percent on sequential tracking.
Where Pith is reading between the lines
- The compression-plus-injection pattern could be tested on other video-prediction robot policies that currently use only short context windows.
- If the tokens remain effective when the compressor is frozen after pre-training, the method would separate memory learning from policy learning more cleanly.
- The same token-injection interface might let non-robot video models track long sequences without lengthening the raw frame context.
- Combining the memory tokens with recurrent hidden states could further extend the effective horizon on tasks that mix visual recall and motor control.
Load-bearing premise
Compact memory tokens produced by the Perceiver compressor can be injected via cross-attention without destabilizing the pre-trained video prediction model while still letting actions depend on earlier episode events.
What would settle it
Run the baseline video model and the memory-augmented version on the same long-horizon LIBERO-Mem or real-robot tasks; if success rates stay at or below the 5 percent baseline and video prediction loss rises, the injection mechanism does not supply useful history conditioning.
Figures



read the original abstract
Video-world-model policies learn action-relevant representations by predicting future observations. However, they condition on only a short observation window, which renders long-horizon manipulation non-Markovian when the correct action depends on earlier events that are no longer visible. We present MemoryVAM, an episodic memory mechanism for video-world-model policies. We employ a Recap-Cue (RC) module, in which a Perceiver-based Recap Compressor maps per-frame CLIP embeddings into compact memory tokens, and a lightweight Cue Gate estimates task completion from memory and language. These tokens are injected into both the video backbone and the action decoder, aligning policy imagination with episode progress and conditioning actions on history. Our model trains the memory module with video prediction, a delta-reconstruction auxiliary loss, and episode-boundary supervision, requiring no per-frame progress labels. The same mechanism applies to UNet and Diffusion Transformer (DiT) backbones by changing only the cross-attention injection interface. On LIBERO-Mem, our model improves average success from 5% to 42.5%. On real robots, it achieves 78.3% success on counting tasks, 80.0% on spatial recall, and 75.0% on sequential tracking. Project page: https://MemoryVAM.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemoryVAM, an episodic memory mechanism for video-world-model policies in robot manipulation. It uses a Recap-Cue (RC) module consisting of a Perceiver-based Recap Compressor that maps per-frame CLIP embeddings to compact memory tokens and a lightweight Cue Gate for task completion estimation. These tokens are injected via cross-attention into both the video backbone and action decoder to condition actions on episode history for non-Markovian tasks. Training combines video prediction, a delta-reconstruction auxiliary loss, and episode-boundary supervision without requiring per-frame progress labels. The approach is presented as backbone-agnostic (applicable to UNet and DiT via interface changes only). Reported results include average success improvement from 5% to 42.5% on LIBERO-Mem and 75–80% success rates on real-robot tasks involving counting, spatial recall, and sequential tracking.
Significance. If the reported gains are robustly supported by ablations and statistical analysis, the work would be significant for addressing the short observation window limitation in video-world-model policies, enabling long-horizon manipulation that depends on earlier events. Strengths include the label-free training via auxiliary losses and episode-boundary supervision, plus the modular injection design that avoids retraining the full backbone.
major comments (2)
- [§4] §4 (Experiments), Table 1 and Figure 3: the central claim of meaningful history conditioning rests on the 5%→42.5% lift on LIBERO-Mem and the 75–80% real-robot rates, yet the manuscript must supply full baseline comparisons, ablation results isolating the memory token injection from the auxiliary losses, and statistical significance tests; without these the data cannot be judged to support the non-Markovian improvement.
- [§3.2] §3.2 (Injection mechanism): the assumption that cross-attention injection of Perceiver Recap Compressor tokens into both backbone and decoder conditions actions on history without destabilizing the pre-trained video prediction model is load-bearing; the paper must report training stability metrics and an ablation removing the injection to confirm the tokens are the source of the gains rather than the auxiliary losses alone.
minor comments (2)
- The project page URL is given but the manuscript should include a reproducibility statement specifying whether code, model weights, and exact training hyperparameters will be released.
- [§3.1] Notation for the Cue Gate output and the exact form of the delta-reconstruction loss should be defined with an equation in §3.1 for clarity.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the emphasis on strengthening the empirical support for the memory mechanism's contribution. Below we respond point-by-point to the major comments and indicate the revisions we will undertake.
read point-by-point responses
-
Referee: [§4] §4 (Experiments), Table 1 and Figure 3: the central claim of meaningful history conditioning rests on the 5%→42.5% lift on LIBERO-Mem and the 75–80% real-robot rates, yet the manuscript must supply full baseline comparisons, ablation results isolating the memory token injection from the auxiliary losses, and statistical significance tests; without these the data cannot be judged to support the non-Markovian improvement.
Authors: We agree that additional controls are required to isolate the contribution of the memory tokens. In the revised manuscript we will expand the experimental section to include (i) full baseline comparisons against variants that omit the Recap Compressor, the Cue Gate, or both; (ii) ablations that keep the auxiliary losses fixed while removing the cross-attention injection of memory tokens; and (iii) statistical significance tests (paired t-tests across seeds together with 95 % bootstrap confidence intervals) for all reported success rates on LIBERO-Mem and the real-robot tasks. revision: yes
-
Referee: [§3.2] §3.2 (Injection mechanism): the assumption that cross-attention injection of Perceiver Recap Compressor tokens into both backbone and decoder conditions actions on history without destabilizing the pre-trained video prediction model is load-bearing; the paper must report training stability metrics and an ablation removing the injection to confirm the tokens are the source of the gains rather than the auxiliary losses alone.
Authors: We acknowledge that training stability and an explicit ablation of the injection itself are necessary to substantiate the claim. We will add (i) training curves and gradient-norm statistics for both the UNet and DiT backbones when the memory tokens are injected, and (ii) an ablation that retains the auxiliary losses but disables the cross-attention injection, thereby confirming that performance gains arise from the episodic memory conditioning rather than the auxiliary objectives alone. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems contribution describing an architecture (Recap-Cue module with Perceiver Compressor and Cue Gate) and its training (video prediction + delta-reconstruction + episode-boundary supervision). No equations, derivations, or first-principles predictions appear that could reduce claimed performance gains to quantities defined by the method itself. Results on LIBERO-Mem and real-robot tasks are presented as experimental outcomes rather than analytic consequences of self-referential definitions or self-citation chains. The mechanism is described as backbone-agnostic via interface changes, with no load-bearing uniqueness theorems or fitted inputs renamed as predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. In Forty-second International Conference on Machine Learning
-
[2]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[3]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[4]
Chung, T
N. Chung, T. Hanyu, T. Nguyen, H. Le, F. Bumgarner, D. M. H. Nguyen, K. V o, K. Yamazaki, C. Rainwater, T. Kieu, et al. Rethinking progression of memory state in robotic manipulation: An object-centric perspective. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 40, pages 3407–3415, 2026
2026
-
[5]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, et al. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
Pith/arXiv arXiv 2026
-
[6]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[7]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[8]
Y . Gao, J. Liu, S. Li, and S. Song. Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Pith/arXiv arXiv 2026
-
[9]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[10]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
- [11]
-
[12]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[13]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pre-trained image-editing diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 33431–33452, 2024
2024
-
[14]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[15]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024. 9
2024
-
[16]
B. Chen, D. Mart ´ı Mons´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[17]
Huang, Z
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems, 38: 167283–167308, 2026
2026
-
[18]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[19]
B. He, H. Li, Y . K. Jang, M. Jia, X. Cao, A. Shah, A. Shrivastava, and S.-N. Lim. Ma- lmm: Memory-augmented large multimodal model for long-term video understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13504–13514, 2024
2024
-
[20]
T. Kerssies, G. Berton, J. He, Q. Yu, W. Ma, D. de Geus, G. Dubbelman, and L.-C. Chen. A frame is worth one token: Efficient generative world modeling with delta tokens.arXiv preprint arXiv:2604.04913, 2026
Pith/arXiv arXiv 2026
-
[21]
Jaegle, F
A. Jaegle, F. Gimeno, A. Brock, O. Vinyals, A. Zisserman, and J. Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021
2021
-
[22]
A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021
Pith/arXiv arXiv 2021
-
[23]
Alayrac, J
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Mil- lican, M. Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[24]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[25]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[26]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[27]
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
Pith/arXiv arXiv 2023
-
[28]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[29]
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 10 Supplementary Materials Contents A Architecture Details 11 A.1 Recap Compressor and History Cache. . . . ...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.