A Generalized Formalism of Auto-Regressive Decoding for Speech Processing
Pith reviewed 2026-06-26 22:56 UTC · model grok-4.3
The pith
A generalized theoretical framework categorizes auto-regressive search strategies for neural speech processing models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
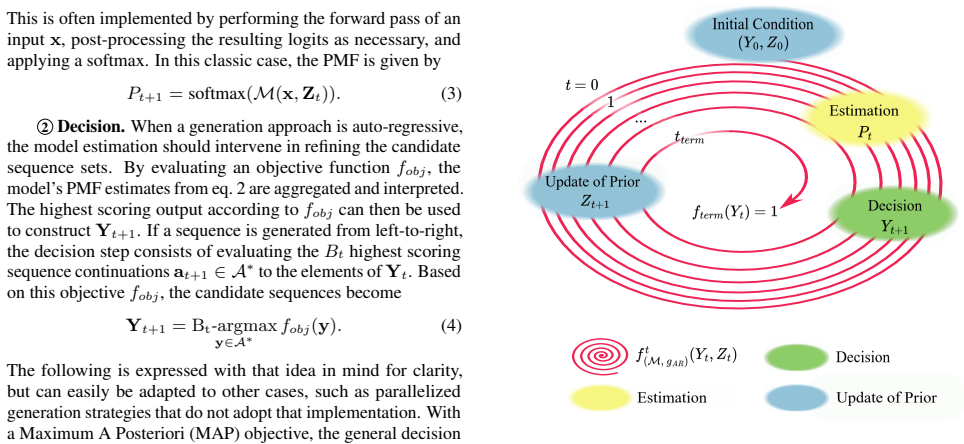
After defining clear inclusion criteria for the field, the authors derive a generalized theoretical framework that places every auto-regressive decoding strategy into consistent categories, thereby removing inconsistencies in how approaches are labeled and reported.
What carries the argument
The generalized theoretical framework that categorizes search strategies for neural sequence models in speech processing.
If this is right
- Decoding strategies can be compared and reported under shared categories rather than ad-hoc labels.
- Benchmarks can be designed that vary only the search method while holding model and data fixed.
- Ablation experiments can isolate the contribution of the decoding process from other parts of the pipeline.
- Inconsistent characterizations of models as auto-regressive or non-auto-regressive are reduced.
Where Pith is reading between the lines
- The same categorization logic might be tested on sequence tasks outside speech, such as text or music generation, to check transfer.
- If categories prove stable, future papers could adopt the framework's reporting template as a standard for describing their decoding choices.
- The framework's structure could guide the invention of hybrid strategies that combine elements from different categories.
Load-bearing premise
A single framework can be built that places every relevant auto-regressive strategy into categories without erasing useful distinctions between them.
What would settle it
Apply the framework to a newly published decoding method in speech processing and check whether every existing method receives a non-overlapping category while preserving the distinctions that researchers currently treat as important.
Figures
read the original abstract
In speech processing, most state-of-the-art sequence prediction models rely on auto-regressive (AR) strategies to generate output sequences based on the raw predictions of the model. Despite their crucial role in the inference process, a comprehensive overview of AR strategies as a unified field is lacking, due largely to implicit and multiple definitions of next-token decoding. This context complicates the choice, comparison, and evaluation of strategies, while creating inconsistencies in the characterization of approaches as auto-regressive or not. We begin by setting explicit inclusion criteria for the field of AR search in speech processing, and derive a generalized theoretical framework to categorize and report on search strategies for neural models. We show the capabilities of this formalism in simplifying the design of benchmarks centered around the decoding process, allowing for ablation studies that are focused on search strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript sets explicit inclusion criteria for the field of auto-regressive (AR) search in speech processing and derives a generalized theoretical framework to categorize and report on search strategies for neural models. It claims this formalism simplifies the design of benchmarks for ablation studies focused on the decoding process.
Significance. If the framework is actually derived and shown to be applicable without loss of distinctions, the work could help standardize terminology and comparisons in AR decoding for speech models. As a definitional and organizational contribution rather than an empirical one, its significance depends on whether the framework is constructible from first principles and demonstrably covers existing methods.
major comments (2)
- [Abstract] Abstract: The central claim is the derivation of a generalized theoretical framework, yet the manuscript supplies no equations, definitions of the framework components, proofs, or concrete examples of how existing AR strategies map onto the formalism. This prevents verification that the framework categorizes strategies without significant loss of distinctions or applicability.
- No section provides the actual formalism: the inclusion criteria and framework derivation are asserted but not instantiated, so it is impossible to assess whether the framework is parameter-free, internally consistent, or reduces to existing taxonomies.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. The major comments correctly identify that the current manuscript does not instantiate the claimed formalism with equations, definitions, or mappings. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim is the derivation of a generalized theoretical framework, yet the manuscript supplies no equations, definitions of the framework components, proofs, or concrete examples of how existing AR strategies map onto the formalism. This prevents verification that the framework categorizes strategies without significant loss of distinctions or applicability.
Authors: We agree that the abstract states the central claim without the supporting details being present in the manuscript. The current version asserts the derivation but does not supply the requested equations, component definitions, proofs, or explicit mappings of existing strategies. In revision we will add these elements in a new dedicated section so that readers can verify coverage and distinctions. revision: yes
-
Referee: [—] No section provides the actual formalism: the inclusion criteria and framework derivation are asserted but not instantiated, so it is impossible to assess whether the framework is parameter-free, internally consistent, or reduces to existing taxonomies.
Authors: We concur that the inclusion criteria and framework are asserted rather than instantiated. No section currently supplies the concrete components needed to evaluate parameter-freeness, internal consistency, or relation to prior taxonomies. The revised manuscript will include the full derivation with these properties demonstrated explicitly. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central contribution is the explicit setting of inclusion criteria for AR search in speech processing followed by derivation of a generalized theoretical framework for categorizing search strategies. This is presented as a definitional and organizational exercise rather than an empirical derivation or proof relying on fitted quantities, self-referential equations, or load-bearing self-citations. No equations, parameter fits, or predictions are described in the provided text that would reduce by construction to the inputs; the framework is constructed to simplify benchmarks and ablations without evidence of the enumerated circular patterns. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A model’s generation strategy refers to the local search process towards composing a sequence, through an itera- tive scoring and updating of partial candidates
Introduction Across language modeling tasks, auto-regressive (AR) neural networks dominate the state-of-the-art for sequence prediction [1, 2, 3, 4]. A model’s generation strategy refers to the local search process towards composing a sequence, through an itera- tive scoring and updating of partial candidates. These models are trained to estimate an auto-...
-
[2]
Related Work 2.1. AR decoding as a combinatorial optimization strategy Decoding strategies for neural sequence predictors constitute a subset of methods for discrete combinatorial optimization, in which heuristics are used to explore large structured solu- tion spaces. Several taxonomies propose an overview of these heuristics, but rarely cover machine le...
Pith/arXiv arXiv 2026
-
[3]
In SIPC, both random variables and decision vari- ables are integers, which is why outputs are often represented as an ordered one-dimensional sequence of integers or tokens
Generalized Auto-Regressive Formalism This framework is intended for tasks that can be formalized as a discrete compositional optimization problem, and more pre- cisely a stochastic integer problem under probabilistic constraints (SIPC) [24]. In SIPC, both random variables and decision vari- ables are integers, which is why outputs are often represented a...
-
[4]
Discussion 4.1. Edge cases Presented with sequence prediction methods that deviate from the classic left-to-right next-token prediction paradigm, we demonstrate how our proposed formalism draws the line be- tween auto-regressive and other approaches. We look into ten methods over various speech processing tasks, published be- tween 2018 and 2025. Among th...
2018
-
[5]
Conclusion In this paper, we propose a framework that sets the recurrence re- lation at the core of reporting on generation strategies, including systematic inclusion criteria for a search to be auto-regressive or not (Sec. 4.1). It offers a new way to compare searches from the location and mechanism of their contributions within the search process (Sec. ...
-
[6]
This work was also supported by the German Research Foundation (DFG), for the project 551629603 (LUMO)
Acknowledgments The authors gratefully acknowledge funding from Horizon Eu- rope, under the MSCA grant agreements 101072488 (TRAIL), 101168792 (SWEET) and 101226624 (GREET). This work was also supported by the German Research Foundation (DFG), for the project 551629603 (LUMO)
-
[7]
Generative AI Use Disclosure No generative model was used in the writing of this article
-
[8]
End-to-end speech recognition: A survey,
R. Prabhavalkar, T. Hori, T. N. Sainath, R. Schl¨uter, and S. Watan- abe, “End-to-end speech recognition: A survey,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, vol. 32, pp. 325–351, 2024
2024
-
[9]
Towards con- trollable speech synthesis in the era of large language models: A systematic survey,
T. Xie, Y . Rong, P. Zhang, W. Wang, and L. Liu, “Towards con- trollable speech synthesis in the era of large language models: A systematic survey,” inProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics, 2025, pp. 764–791
2025
-
[10]
End-to-end speech-to-text translation: A survey,
N. Sethiya and C. K. Maurya, “End-to-end speech-to-text translation: A survey,”Computer Speech and Language, vol. 90, p. 101751, 2025. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0885230824001347
2025
-
[11]
On decoding strategies for neural text generators,
G. Wiher, C. Meister, and R. Cotterell, “On decoding strategies for neural text generators,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 997–1012, 09 2022
2022
-
[12]
The harpy speech recognition system
B. T. Lowerre, “The harpy speech recognition system.”Ph.D. the- sis, Carnegie-Mellon University, U.S.A, 1976
1976
-
[13]
Learning to write with cooperative discriminators,
A. Holtzman, J. Buys, M. Forbes, A. Bosselut, D. Golub, and Y . Choi, “Learning to write with cooperative discriminators,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2018, pp. 1638–1649
2018
-
[14]
The curious case of neural text degeneration,
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi, “The curious case of neural text degeneration,” inInternational Conference on Learning Representations, 2020
2020
-
[15]
Truncation sampling as language model desmoothing,
J. Hewitt, C. Manning, and P. Liang, “Truncation sampling as language model desmoothing,” inFindings of the Association for Computational Linguistics: EMNLP 2022. Association for Com- putational Linguistics, 2022, pp. 3414–3427
2022
-
[16]
Decoding meth- ods for neural narrative generation,
A. DeLucia, A. Mueller, X. L. Li, and J. Sedoc, “Decoding meth- ods for neural narrative generation,” inProceedings of the First Workshop on Natural Language Generation, Evaluation, and Met- rics (GEM), A. Bosselut, E. Durmus, V . P. Gangal, S. Gehrmann, Y . Jernite, L. Perez-Beltrachini, S. Shaikh, and W. Xu, Eds. On- line: Association for Computational ...
2021
-
[17]
A survey on non-autoregressive generation for neural machine translation and beyond,
Y . Xiao, L. Wu, J. Guo, J. Li, M. Zhang, T. Qin, and T.-Y . Liu, “A survey on non-autoregressive generation for neural machine translation and beyond,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 11 407–11 427, 2023
2023
-
[18]
The pitfalls of next-token predic- tion,
G. Bachmann and V . Nagarajan, “The pitfalls of next-token predic- tion,” inProceedings of the 41st International Conference on Ma- chine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 2296–2318
2024
-
[19]
On exposure bias, hallucination and domain shift in neural machine translation,
C. Wang and R. Sennrich, “On exposure bias, hallucination and domain shift in neural machine translation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020, pp. 3544–3552
2020
-
[20]
A new taxonomy of global optimization algorithms,
J. Stork, A. E. Eiben, and T. Bartz-Beielstein, “A new taxonomy of global optimization algorithms,”Natural Computing, vol. 21, pp. 219–242, 2022
2022
-
[21]
An exhaustive review of the metaheuristic algorithms for search and optimization: taxonomy, applications, and open challenges,
K. Rajwar, K. Deep, and S. Das, “An exhaustive review of the metaheuristic algorithms for search and optimization: taxonomy, applications, and open challenges,”Artificial Intelligence Review, vol. 56, pp. 13 187–13 257, 2023
2023
-
[22]
A hierarchical taxonomy for deep state space models,
S. Tang, P. Feng, S. Yu, Y . Dong, and S. J. Qin, “A hierarchical taxonomy for deep state space models,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[23]
Faith and fate: limits of transformers on compositionality,
N. Dziri, X. Lu, M. Sclar, X. L. Li, L. Jiang, B. Y . Lin, P. West, C. Bhagavatula, R. Le Bras, J. D. Hwang, S. Sanyal, S. Welleck, X. Ren, A. Ettinger, Z. Harchaoui, and Y . Choi, “Faith and fate: limits of transformers on compositionality,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Curran...
2023
-
[24]
Blockwise parallel de- coding for deep autoregressive models,
M. Stern, N. Shazeer, and J. Uszkoreit, “Blockwise parallel de- coding for deep autoregressive models,” inNeural Information Processing Systems, 2018
2018
-
[25]
Mask- predict: Parallel decoding of conditional masked language models,
M. Ghazvininejad, O. Levy, Y . Liu, and L. Zettlemoyer, “Mask- predict: Parallel decoding of conditional masked language models,” inConference on Empirical Methods in Natural Language Pro- cessing, 2019
2019
-
[26]
Instantaneous grammatical error correction with shallow aggressive decoding,
X. Sun, T. Ge, F. Wei, and H. Wang, “Instantaneous grammatical error correction with shallow aggressive decoding,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp....
2021
-
[27]
Fast inference from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transformers via speculative decoding,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 202, 2023, pp. 19 274–19 286
2023
-
[28]
Accelerating transformer inference for translation via parallel decoding,
A. Santilli, S. Severino, E. Postolache, V . Maiorca, M. Mancusi, R. Marin, and E. Rodola, “Accelerating transformer inference for translation via parallel decoding,” inProceedings of the 61st An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Lin- guistics, 2023, pp. 12 336–12 355
2023
-
[29]
Diverse beam search for improved description of complex scenes,
A. Vijayakumar, M. Cogswell, R. Selvaraju, Q. Sun, S. Lee, D. Crandall, and D. Batra, “Diverse beam search for improved description of complex scenes,”Proceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[30]
A problem with the current methodology for comparing search algorithms and a proposed solution,
M. Barley, N. de Kriek, S. Franco, A. Garcia-Olaya, T. Hartill, C. Triggs, H. Zwart, V . Alc´azar, and P. Riddle, “A problem with the current methodology for comparing search algorithms and a proposed solution,”Proceedings of the International Symposium on Combinatorial Search, vol. 18, no. 1, pp. 29–37, 2025
2025
-
[31]
Beam search heuristic to solve stochastic integer problems under probabilistic constraints,
P. Beraldi and A. Ruszczy ´nski, “Beam search heuristic to solve stochastic integer problems under probabilistic constraints,”Euro- pean Journal of Operational Research, vol. 167, no. 1, pp. 35–47, 2005
2005
-
[32]
Best-first beam search,
C. Meister, T. Vieira, and R. Cotterell, “Best-first beam search,” Transactions of the Association for Computational Linguistics, vol. 8, pp. 795–809, 2020
2020
-
[33]
Grammatical error correction: A survey of the state of the art,
C. Bryant, Z. Yuan, M. R. Qorib, H. Cao, H. T. Ng, and T. Briscoe, “Grammatical error correction: A survey of the state of the art,” Computational Linguistics, vol. 49, no. 3, pp. 643–701, 2023
2023
-
[34]
Machine translation decoding beyond beam search,
R. Leblond, J.-B. Alayrac, L. Sifre, M. Pislar, L. Jean-Baptiste, I. Antonoglou, K. Simonyan, and O. Vinyals, “Machine translation decoding beyond beam search,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 8410–8434
2021
-
[35]
Beam search strategies for neural machine translation,
M. Freitag and Y . Al-Onaizan, “Beam search strategies for neural machine translation,” inProceedings of the First Workshop on Neural Machine Translation. Association for Computational Linguistics, 2017, pp. 56–60
2017
-
[36]
Is MAP decoding all you need? the inadequacy of the mode in neural machine translation,
B. Eikema and W. Aziz, “Is MAP decoding all you need? the inadequacy of the mode in neural machine translation,” inPro- ceedings of the 28th International Conference on Computational Linguistics. Barcelona, Spain (Online): International Committee on Computational Linguistics, 2020, pp. 4506–4520
2020
-
[37]
Conventional and contemporary approaches used in text to speech synthesis: a review,
N. Kaur and P. Singh, “Conventional and contemporary approaches used in text to speech synthesis: a review,”Artificial Intelligence Review, vol. 56, pp. 5837–5880, 2023
2023
-
[38]
V oiceCraft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, S.-W. Li, A. Mohamed, and D. Harwath, “V oiceCraft: Zero-shot speech editing and text-to-speech in the wild,” inProceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Association for Computational Linguistics, 2024, pp. 12 442–12 462
2024
-
[39]
A thorough examination of decoding methods in the era of LLMs,
C. Shi, H. Yang, D. Cai, Z. Zhang, Y . Wang, Y . Yang, and W. Lam, “A thorough examination of decoding methods in the era of LLMs,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024, pp. 8601–8629
2024
-
[40]
From decoding to meta- generation: Inference-time algorithms for large language models,
S. Welleck, A. Bertsch, M. Finlayson, H. Schoelkopf, A. Xie, G. Neubig, I. Kulikov, and Z. Harchaoui, “From decoding to meta- generation: Inference-time algorithms for large language models,” Transactions on Machine Learning Research, 2024, survey Certifi- cation
2024
-
[41]
Locally typi- cal sampling,
C. Meister, T. Pimentel, G. Wiher, and R. Cotterell, “Locally typi- cal sampling,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 102–121, 2023
2023
-
[42]
Why exposure bias matters: An imitation learning perspective of error accumu- lation in language generation,
K. Arora, L. El Asri, H. Bahuleyan, and J. Cheung, “Why exposure bias matters: An imitation learning perspective of error accumu- lation in language generation,” inFindings of the Association for Computational Linguistics: ACL. Association for Computational Linguistics, 2022, pp. 700–710
2022
-
[43]
Enabling beam search for language model-based text-to-speech synthesis,
Z. Tu, G. Zhang, Y . Lu, A. Adigwe, S. King, and Y . Guo, “Enabling beam search for language model-based text-to-speech synthesis,” in ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[44]
Language model decoding as likelihood–utility alignment,
M. Josifoski, M. Peyrard, F. Rajiˇc, J. Wei, D. Paul, V . Hartmann, B. Patra, V . Chaudhary, E. Kiciman, and B. Faltings, “Language model decoding as likelihood–utility alignment,” inFindings of the Association for Computational Linguistics: EACL 2023. As- sociation for Computational Linguistics, 2023, pp. 1455–1470
2023
-
[45]
Comparison of diverse decoding methods from conditional language models,
D. Ippolito, R. Kriz, J. Sedoc, M. Kustikova, and C. Callison- Burch, “Comparison of diverse decoding methods from conditional language models,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019, pp. 3752–3762
2019
-
[46]
When is a language process a language model?
L. Du, H. Lee, J. Eisner, and R. Cotterell, “When is a language process a language model?” inFindings of the Association for Computational Linguistics: ACL 2024. Association for Compu- tational Linguistics, 2024, pp. 11 083–11 094
2024
-
[47]
A learning algorithm for boltzmann machines,
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, “A learning algorithm for boltzmann machines,”Cognitive Science, vol. 9, no. 1, pp. 147–169, 1985
1985
-
[48]
Non- autoregressive neural machine translation,
J. Gu, J. Bradbury, C. Xiong, V . O. Li, and R. Socher, “Non- autoregressive neural machine translation,” inInternational Con- ference on Learning Representations, 2018
2018
-
[49]
Non- autoregressive transformer for speech recognition,
N. Chen, S. Watanabe, J. Villalba, P.˙Zelasko, and N. Dehak, “Non- autoregressive transformer for speech recognition,”IEEE Signal Processing Letters, vol. 28, pp. 121–125, 2021
2021
-
[50]
Non-autoregressive neural text-to-speech,
K. Peng, W. Ping, Z. Song, and K. Zhao, “Non-autoregressive neural text-to-speech,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119, 13–18 Jul 2020, pp. 7586–7598
2020
-
[51]
CTC-based non- autoregressive speech translation,
C. Xu, X. Liu, X. Liu, Q. Sun, Y . Zhang, M. Yang, Q. Dong, T. Ko, M. Wang, T. Xiao, A. Ma, and J. Zhu, “CTC-based non- autoregressive speech translation,” inProceedings of the 61st An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 13 321–13 339
2023
-
[52]
Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis,
Y . Yang, S. Liu, J. Li, Y . Hu, H. Wu, H. Wang, J. Yu, L. Meng, H. Sun, Y . Liu, Y . Lu, K. Yu, and X. Chen, “Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis,” inProceedings of the 33rd ACM International Confer- ence on Multimedia, ser. MM ’25, 2025, p. 9316–9325
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.