When Web Agents Finish but Still Fail: Reproducible Triggers and Trace Diagnostics for Parallel Web Exploration
Pith reviewed 2026-06-30 10:29 UTC · model grok-4.3
The pith
GRPO training on synthetic data lifts web agent completion to 96 percent yet leaves a persistent gap between finishing and producing fully correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Synthetic-data GRPO reduces abstention and improves partial correctness, but leaves a completion-correctness gap that requires evidence-grounded coverage and synthesis diagnostics, as demonstrated by training runs on Parallel WebBench and trace-level inspection of the resulting agents.
What carries the argument
Parallel WebBench benchmark containing 350 manually curated tasks and 1329 reconstructed URL trajectories, together with GRPO training and post-hoc trace diagnostics that surface three failure modes.
If this is right
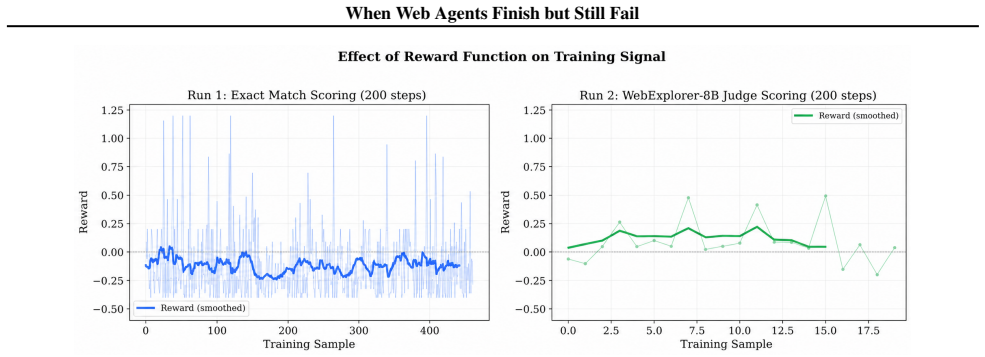
- GRPO on synthetic-heavy mixtures raises completion from 50.7 percent to 96.0 percent at 16 k context and 16 rounds.
- Element-wise F1 rises from 0.2489 to 0.4529 while binary accuracy remains substantially lower.
- Three failure modes continue after training: context-bound search loops, premature termination on partial answers, and synthesis collapse after evidence is retrieved.
- Closing the gap requires new diagnostics focused on evidence coverage rather than termination signals alone.
Where Pith is reading between the lines
- Agents could be augmented with explicit freshness and completeness checks before termination to reduce the observed gap.
- The same termination-versus-correctness mismatch may appear in other long-horizon agent domains that use similar reward shaping.
- Replaying the three failure modes on live web pages with changing content would test whether the diagnostics generalize beyond the benchmark's static trajectories.
Load-bearing premise
The 1679 verified records and the three identified failure modes are representative of real parallel web-exploration failures and GPT-4.1-mini judgments reliably measure element-wise correctness.
What would settle it
A new collection of parallel web tasks outside Parallel WebBench on which the best GRPO model achieves binary accuracy equal to its completion rate would falsify the claimed gap.
Figures
read the original abstract
Long-horizon web agents often fail in ways hidden by final-answer evaluation: they may visit useful pages, produce a well-formed answer, and terminate confidently while still missing fields, over-including unsupported items, or relying on stale evidence. We study these failures with Parallel WebBench, a parallel web-exploration benchmark containing 1,679 verified records: 350 manually curated parallel tasks and 1,329 reconstructed records with verified URL-based trajectories. We train WebExplorer-style agents with GRPO under human-only, balanced human-synthetic, and synthetic-heavy data mixtures. At 16k context and 16 interaction rounds, the best GRPO model improves completion over WebExplorer-8B from 50.7% to 96.0% and GPT-4.1-mini-judged element-wise F1 from 0.2489 to 0.4529, but binary accuracy remains far below completion. Trace-level analysis identifies three persistent failure modes: context-bound search loops, premature termination on partial answers, and synthesis collapse after relevant evidence has already been retrieved. These results show that synthetic-data GRPO reduces abstention and improves partial correctness, but leaves a completion-correctness gap that requires evidence-grounded coverage and synthesis diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Parallel WebBench, a benchmark with 1,679 verified records (350 manually curated parallel tasks plus 1,329 reconstructed URL-based trajectories), and evaluates WebExplorer-style agents trained via GRPO on human-only, balanced, and synthetic-heavy data mixtures. At 16k context and 16 interaction rounds, the best model raises completion from 50.7% to 96.0% and GPT-4.1-mini-judged element-wise F1 from 0.2489 to 0.4529, yet binary accuracy stays far below completion; trace analysis identifies three persistent failure modes (context-bound search loops, premature termination on partial answers, synthesis collapse). The central claim is that synthetic-data GRPO reduces abstention and improves partial correctness but leaves a completion-correctness gap that requires evidence-grounded coverage and synthesis diagnostics.
Significance. If the measurements are reliable, the work is significant for exposing failure modes invisible to final-answer metrics, supplying a reproducible parallel-exploration benchmark, and demonstrating that synthetic GRPO yields measurable but incomplete gains. The explicit identification of a persistent gap and the call for new diagnostics constitute a falsifiable contribution that could guide follow-on agent research.
major comments (1)
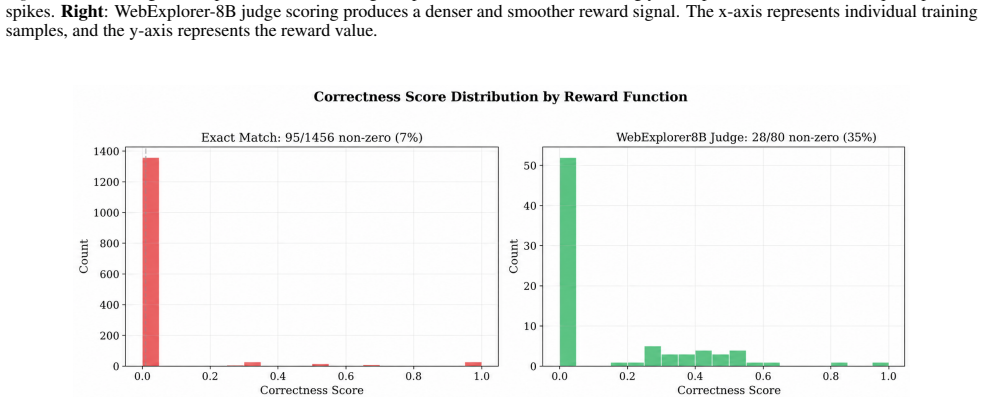
- [Abstract and Evaluation] Abstract and Evaluation section: the reported F1 gains (0.2489 o 0.4529) and the claim of exactly three persistent failure modes are produced exclusively by GPT-4.1-mini element-wise judgments over the 1,679 records; no human validation, inter-annotator agreement, calibration set, or human-vs-LLM comparison is described. This is load-bearing for the central claim, because systematic inflation of partial-credit scores or misclassification of synthesis failures would invalidate both the quantified gap and the call for evidence-grounded diagnostics.
minor comments (3)
- [Abstract] Abstract: concrete performance numbers are given without error bars, confidence intervals, or statistical significance tests.
- [Abstract] Abstract: data-exclusion rules and the precise definition of the 1,679 verified records are not summarized, complicating reproducibility claims.
- [Trace analysis] Trace analysis paragraph: the procedure for selecting which traces receive post-hoc inspection is not stated, leaving open the possibility of selection bias in the three-mode taxonomy.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our evaluation methodology. We address the major comment point-by-point below and commit to revisions that improve the robustness of our claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the reported F1 gains (0.2489 o 0.4529) and the claim of exactly three persistent failure modes are produced exclusively by GPT-4.1-mini element-wise judgments over the 1,679 records; no human validation, inter-annotator agreement, calibration set, or human-vs-LLM comparison is described. This is load-bearing for the central claim, because systematic inflation of partial-credit scores or misclassification of synthesis failures would invalidate both the quantified gap and the call for evidence-grounded diagnostics.
Authors: We agree that the lack of human validation for the GPT-4.1-mini element-wise judgments is a limitation of the current manuscript and directly affects the reliability of the reported F1 gains and the quantified completion-correctness gap. The three failure modes were identified via manual author inspection of agent traces rather than solely through the LLM judgments, but the F1 scoring and partial-credit quantification rely on the automated judgments. In the revised manuscript we will add a human validation study on a stratified sample of records, report inter-annotator agreement, and include a direct human-vs-LLM comparison to calibrate the metrics and substantiate the central claims. revision: yes
Circularity Check
No circularity: empirical benchmark and training results are self-contained
full rationale
The paper introduces Parallel WebBench (1,679 verified records) and reports direct empirical outcomes from GRPO training runs under different data mixtures, including completion rates rising to 96.0% and element-wise F1 to 0.4529. These measurements are produced by external evaluation (GPT-4.1-mini judgments on the new benchmark) rather than any equation that reduces a claimed prediction back to a fitted input or self-citation by construction. No self-definitional steps, uniqueness theorems, or ansatzes imported via citation appear in the provided text. The central claim about a remaining completion-correctness gap follows from the reported trace analysis on the benchmark, which is independently verifiable against the stated records and failure modes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO optimization and GPT-4.1-mini element-wise judgments are valid proxies for agent performance as established in prior literature.
Reference graph
Works this paper leans on
-
[1]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, February 2023
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. arXiv preprint arXiv:2207.01206 , year=
-
[2]
Advances in Neural Information Processing Systems , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. Advances in Neural Information Processing Systems , year=
-
[3]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
WebWalker: Benchmarking LLMs in Web Traversal , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
-
[5]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents , author=. arXiv preprint arXiv:2504.12516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Available: https://arxiv.org/abs/2509.06501
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents , author=. arXiv preprint arXiv:2509.06501 , year=
-
[7]
WebSailor: Navigating Super-human Reasoning for Web Agent
WebSailor: Navigating Super-human Reasoning for Web Agent , author=. arXiv preprint arXiv:2507.02592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. arXiv preprint arXiv:2306.05685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. arXiv preprint arXiv:2303.16634 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Concrete Problems in AI Safety
Concrete Problems in AI Safety , author=. arXiv preprint arXiv:1606.06565 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Workarena: How capable are web agents at solving common knowledge work tasks? , author=. arXiv preprint arXiv:2403.07718 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Weblinx: Real-world website navigation with multi-turn dialogue , author=. arXiv preprint arXiv:2402.05930 , year=
-
[16]
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Gpt-4v (ision) is a generalist web agent, if grounded , author=. arXiv preprint arXiv:2401.01614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Webvoyager: Building an end-to-end web agent with large multimodal models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
International Conference on Learning Representations , volume=
Agentbench: Evaluating llms as agents , author=. International Conference on Learning Representations , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Webolympus: An open platform for web agents on live websites , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2024
-
[21]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[22]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[25]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Freshllms: Refreshing large language models with search engine augmentation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[26]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enabling large language models to generate text with citations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[27]
Computational Linguistics , volume=
Measuring attribution in natural language generation models , author=. Computational Linguistics , volume=
-
[28]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large language models are not fair evaluators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
International Conference on Learning Representations , year=
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , author=. International Conference on Learning Representations , year=
-
[31]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[33]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[34]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[35]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
FEVER: a large-scale dataset for fact extraction and VERification , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
2018
-
[36]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
KILT: a benchmark for knowledge intensive language tasks , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[37]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[39]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.