Latent Personal Memory: Represent personal memory as dynamic soft prompts
Pith reviewed 2026-06-26 17:05 UTC · model grok-4.3
The pith
User history can be encoded in a compact matrix of latent slots that generate dynamic soft prompts for a frozen LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
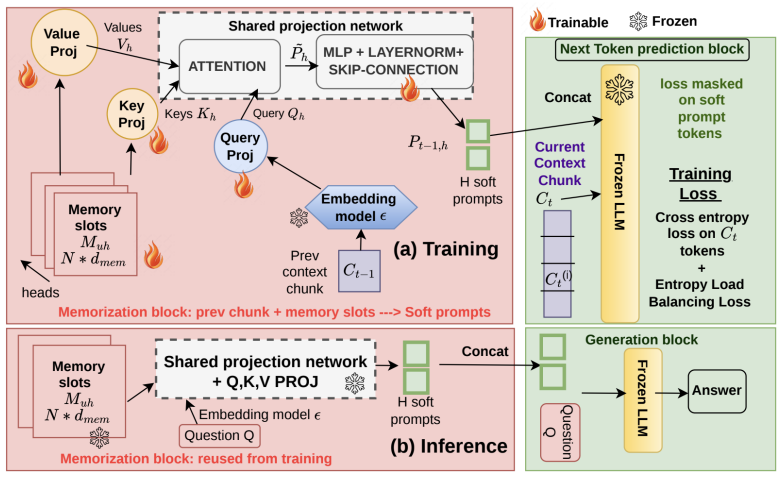
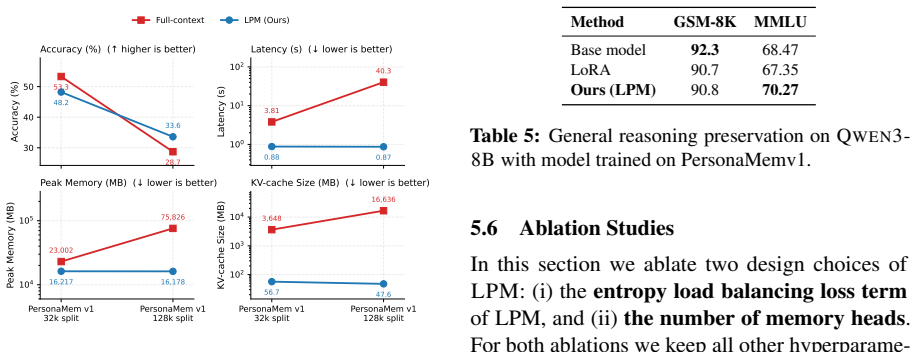
LPM stores user-specific history as a persistent matrix of N latent slots. A shared cross-attention projection network maps these slots into dynamic, input-conditioned soft prompts that are prepended to the input of a frozen LLM. On PersonaMem v1 this yields up to 8.8 percent higher accuracy than LoRA and 54.4 percent higher than prompt tuning while cutting KV-cache usage by over 64 times; on LoCoMo it matches LoRA accuracy with 120 times fewer trainable parameters; the efficiency advantage grows with context length and exceeds full-context performance at 128K tokens.
What carries the argument
A persistent matrix of N latent slots mapped by a shared cross-attention projection network into input-conditioned soft prompts.
If this is right
- KV-cache usage drops by more than 64 times relative to full-context baselines on PersonaMem v1.
- Trainable parameters can be reduced by a factor of 120 while still matching LoRA accuracy on LoCoMo.
- The accuracy and efficiency gains increase as context length grows, surpassing full-context methods at 128K tokens.
- The same slot-and-projection design works across Qwen3 backbones from 1.7B to 8B parameters without altering the base model.
Where Pith is reading between the lines
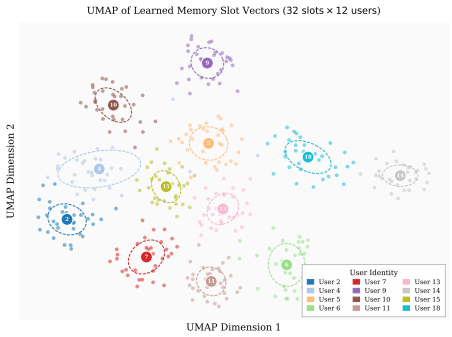
- The slots could be inspected or edited directly to control or debug what the model remembers about a given user.
- Separate slot matrices for different users could be maintained while sharing the single projection network.
- New interactions could be folded in by updating only the latent slots rather than retraining the projection network.
Load-bearing premise
A fixed number of latent slots together with one shared cross-attention network can reliably capture and surface long-term user-specific behavioral patterns for the frozen base model.
What would settle it
A controlled test on a new set of users with long, varied histories where LPM accuracy falls below LoRA while KV-cache savings fail to materialize or degrade sharply at scale.
Figures

read the original abstract
Personalizing large language models (LLMs) requires encoding long-term, user-specific behavioral patterns in a way that is computationally efficient, scalable, and compatible with a frozen base model. We present Latent Personal Memory (LPM), a scalable framework that represents user-specific history as a compact, persistent matrix of N latent slots, that are interpretable. A shared cross-attention projection network maps these slots into dynamic, input-conditioned soft prompts that are prepended to the input of a frozen LLM. We evaluate LPM on PersonaMem v1 and LoCOMO benchmarks across Qwen3-1.7B, 4B, and 8B backbones. Results demonstrate that LPM outperforms LoRA and Prompt Tuning by up to 8.8% and 54.4% in overall accuracy respectively on PersonaMem v1, while reducing KV-cache usage by over 64x. On LoCoMo, LPM matches LoRA accuracy with 120x fewer trainable parameters. We also show that the efficiency of LPM grows with context length and outperforms full-context at 128K context length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Personal Memory (LPM), a framework that encodes user-specific history as a compact, persistent matrix of N latent slots. A shared cross-attention projection network maps these slots into input-conditioned dynamic soft prompts that are prepended to a frozen LLM. Evaluations on the PersonaMem v1 and LoCoMo benchmarks with Qwen3-1.7B/4B/8B backbones report accuracy gains over LoRA (up to 8.8%) and Prompt Tuning (up to 54.4%), 64x KV-cache reduction, 120x fewer trainable parameters while matching LoRA accuracy, and superior scaling versus full-context at 128K lengths.
Significance. If the empirical results hold, LPM offers a practical route to scalable, long-term personalization of frozen LLMs that preserves base-model compatibility while delivering clear efficiency advantages in parameters and KV-cache. The latent-slot construction with dynamic prompting could influence memory-augmented dialogue systems and context-length scaling research.
minor comments (2)
- [Abstract] Abstract: the phrase 'interpretable' latent slots is asserted without supporting analysis or visualization; a short qualitative example or attention-map figure would strengthen the claim.
- [§4 (Experiments)] The efficiency claims (64x KV-cache, 120x parameters) would benefit from an explicit table listing exact baseline context lengths and memory measurements for each compared method.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The provided summary accurately captures the LPM framework, its efficiency advantages, and empirical results on PersonaMem v1 and LoCoMo.
Circularity Check
No significant circularity; empirical method with benchmark comparisons
full rationale
The paper proposes an architecture (latent slots + shared cross-attention projection) and reports empirical accuracy/efficiency gains on PersonaMem v1 and LoCoMo against LoRA and Prompt Tuning baselines. No derivation chain exists that reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. All central claims are externally falsifiable benchmark numbers; the method is not justified via internal equations that presuppose the target outcome. This matches the default non-circular case for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[2]
L ight RAG : Simple and Fast Retrieval-Augmented Generation
Guo, Zirui and Xia, Lianghao and Yu, Yanhua and Ao, Tu and Huang, Chao. L ight RAG : Simple and Fast Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.568
-
[3]
Xia, Yuan and Zhou, Jingbo and Shi, Zhenhui and Chen, Jun and Huang, Haifeng , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 , isbn =. doi:1...
-
[4]
Huang, Yizheng and Huang, Jimmy Xiangji , title =. ACM Comput. Surv. , month = may, articleno =. 2026 , issue_date =. doi:10.1145/3805774 , abstract =
-
[5]
2025 , eprint=
A Comprehensive Survey on Long Context Language Modeling , author=. 2025 , eprint=
2025
-
[6]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[7]
2019 , eprint=
Parameter-Efficient Transfer Learning for NLP , author=. 2019 , eprint=
2019
-
[8]
2024 , eprint=
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning , author=. 2024 , eprint=
2024
-
[9]
2023 , eprint=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. 2023 , eprint=
2023
-
[10]
Reece S Shuttleworth and Jacob Andreas and Antonio Torralba and Pratyusha Sharma , year=. Lo
-
[11]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[12]
2025 , eprint=
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory , author=. 2025 , eprint=
2025
-
[14]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
-
[15]
2025 , eprint=
M+: Extending MemoryLLM with Scalable Long-Term Memory , author=. 2025 , eprint=
2025
-
[16]
2022 , eprint=
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author=. 2022 , eprint=
2022
-
[17]
The Fourteenth International Conference on Learning Representations , year=
LightMem: Lightweight and Efficient Memory-Augmented Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
2025 , eprint=
Embedding-to-Prefix: Parameter-Efficient Personalization for Pre-Trained Large Language Models , author=. 2025 , eprint=
2025
-
[19]
2020 , eprint=
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction , author=. 2020 , eprint=
2020
-
[20]
2025 , eprint=
End-to-End Test-Time Training for Long Context , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. 2025 , eprint=
2025
-
[22]
2024 , eprint=
MEMORYLLM: Towards Self-Updatable Large Language Models , author=. 2024 , eprint=
2024
-
[23]
The Fourteenth International Conference on Learning Representations , year=
MemGen: Weaving Generative Latent Memory for Self-Evolving Agents , author=. The Fourteenth International Conference on Learning Representations , year=
-
[24]
Memory ^3 : Language Modeling with Explicit Memory , volume=
Yang, Hongkang and Lin, Zehao and Wang, Wenjin and Wu, Hao and Li, Zhiyu and Tang, Bo and Wei, Wenqiang and Wang, Jinbo and Tang, Zeyun and Song, Shichao and Xi, Chenyang and Yu, Yu and Chen, Kai and Xiong, Feiyu and Tang, Linpeng and E, Weinan , year=. Memory ^3 : Language Modeling with Explicit Memory , volume=. Journal of Machine Learning , publisher=....
-
[25]
Yu Wang and Ryuichi Takanobu and Zhiqi Liang and Yuzhen Mao and Yuanzhe Hu and Julian McAuley and Xiaojian Wu , year=
-
[26]
2025 , eprint=
MIRIX: Multi-Agent Memory System for LLM-Based Agents , author=. 2025 , eprint=
2025
-
[27]
2026 , eprint=
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning , author=. 2026 , eprint=
2026
-
[28]
2026 , eprint=
Memory in the Age of AI Agents , author=. 2026 , eprint=
2026
-
[29]
Tan, Sijun and Li, Xiuyu and Patil, Shishir G and Wu, Ziyang and Zhang, Tianjun and Keutzer, Kurt and Gonzalez, Joseph E. and Popa, Raluca Ada. LL o CO : Learning Long Contexts Offline. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.975
-
[30]
ArXiv , year=
Learning by Distilling Context , author=. ArXiv , year=
-
[31]
2022 , eprint=
ST-MoE: Designing Stable and Transferable Sparse Expert Models , author=. 2022 , eprint=
2022
-
[32]
2025 , eprint=
DynMoLE: Boosting Mixture of LoRA Experts Fine-Tuning with a Hybrid Routing Mechanism , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.