Right Knowledge, Wrong Answer: Test-Time Steering for Temporal Fact Conflicts in Open-Weight Language Models
Pith reviewed 2026-06-26 17:32 UTC · model grok-4.3
The pith
Temporal Attractor Steering overrides outdated facts in language models at inference time by steering hidden states in a conflict-critical layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
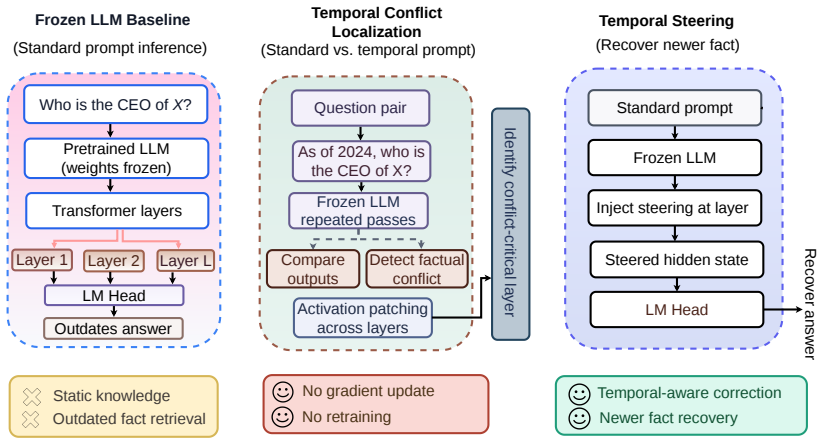
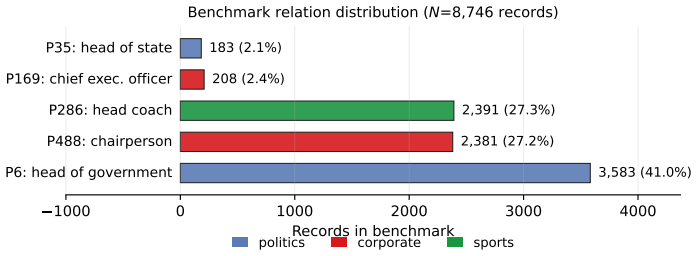
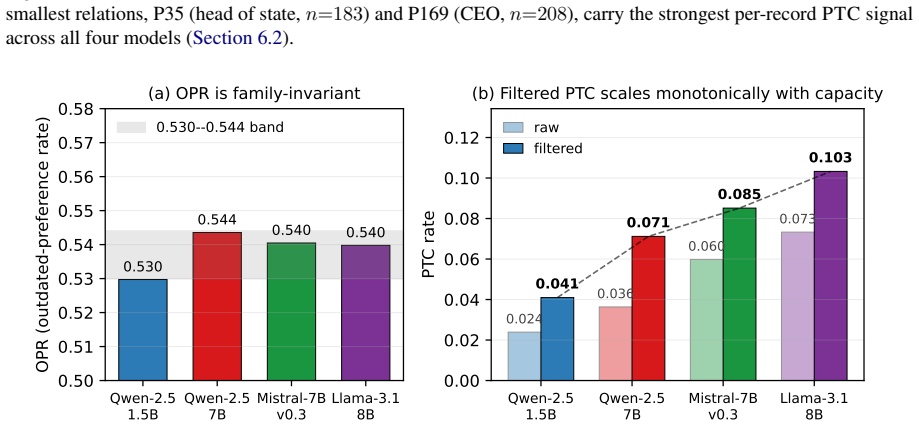
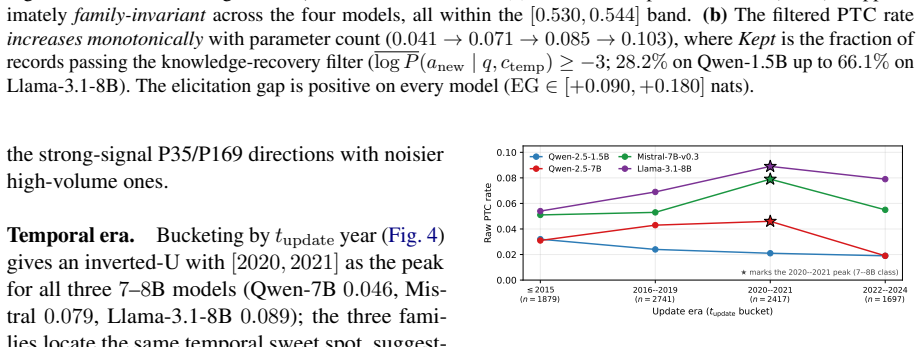
Large language models can store both outdated facts and newer superseding facts in their parameters, but standard prompting may still elicit the outdated answer. We formalize this problem as Parametric Temporal Conflict (PTC) and introduce Temporal Attractor Steering (TAS), a three-stage test-time intervention that detects likely conflicts, identifies a conflict-critical layer, and steers hidden states toward newer-fact representations without retraining or external retrieval. We construct an 8,746-record verified benchmark across five Wikidata relations and evaluate four open-weight language models from three families: Qwen-2.5-1.5B/7B, Mistral-7B-v0.3, and Llama-3.1-8B. Single-layer activa
What carries the argument
Temporal Attractor Steering (TAS), a three-stage test-time intervention of conflict detection, conflict-critical layer identification, and hidden-state steering toward newer-fact representations.
If this is right
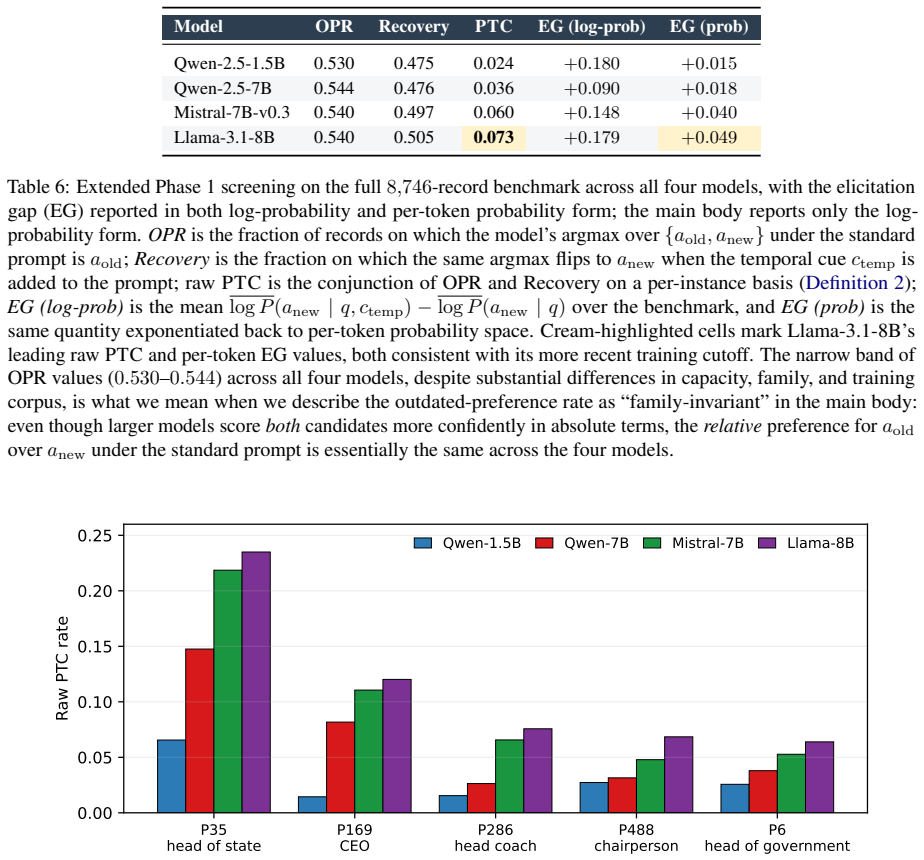
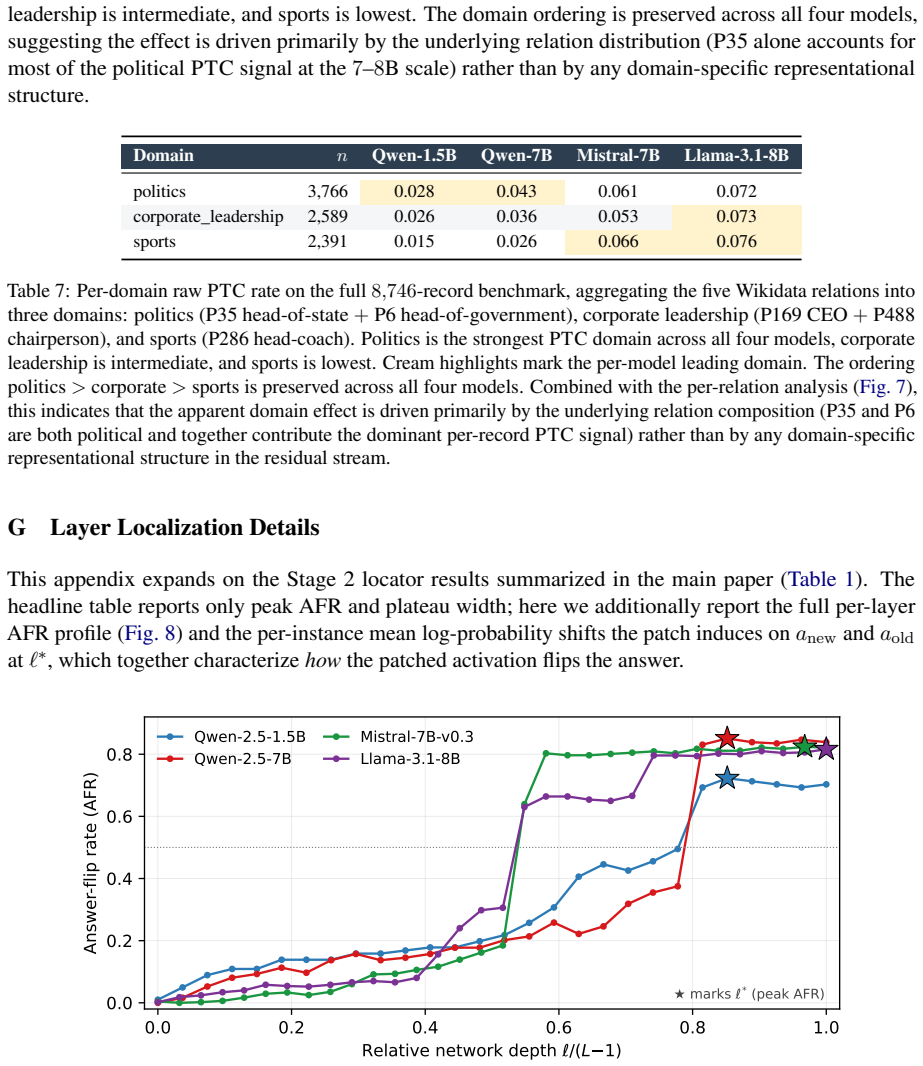
- Single-layer activation patching achieves answer-flip rates of 0.72-0.85 across all models.
- End-to-end TAS resolves 29-57% of PTC cases.
- TAS preserves 85-99% accuracy on non-conflict queries.
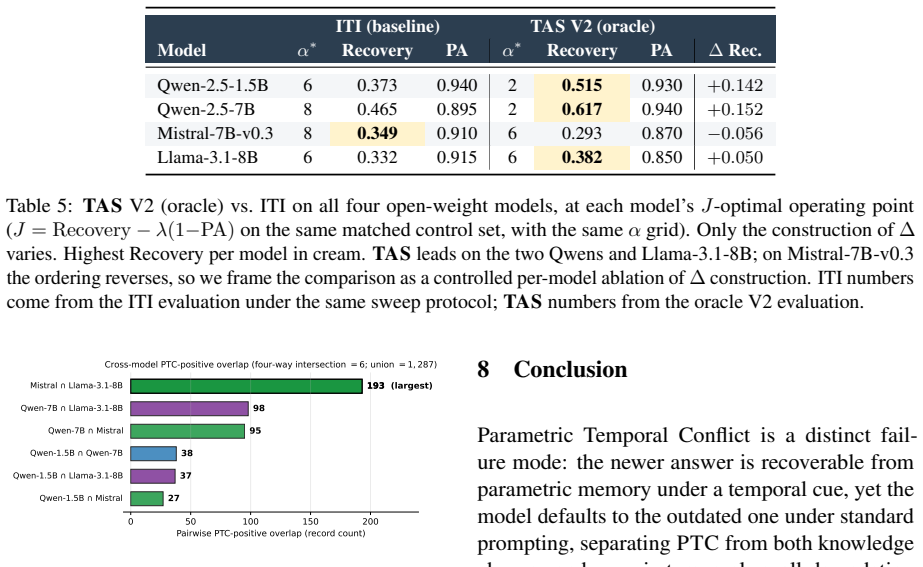
- TAS outperforms a matched ITI baseline on three of four models.
- Outdated parametric knowledge can be selectively overridden at inference time.
Where Pith is reading between the lines
- If critical layers prove consistent across model families, similar steering could apply to other internal knowledge inconsistencies.
- The localization of facts implied by the method suggests runtime correction could supplement static training in deployed systems.
- Models equipped with such steering might maintain temporal accuracy longer without periodic retraining.
Load-bearing premise
There exists an identifiable conflict-critical layer whose hidden-state steering can override the outdated fact representation without unintended degradation to other stored knowledge or non-conflict performance.
What would settle it
An experiment showing that steering the identified layer reduces accuracy on non-conflict queries or unrelated facts would disprove selective override.
Figures
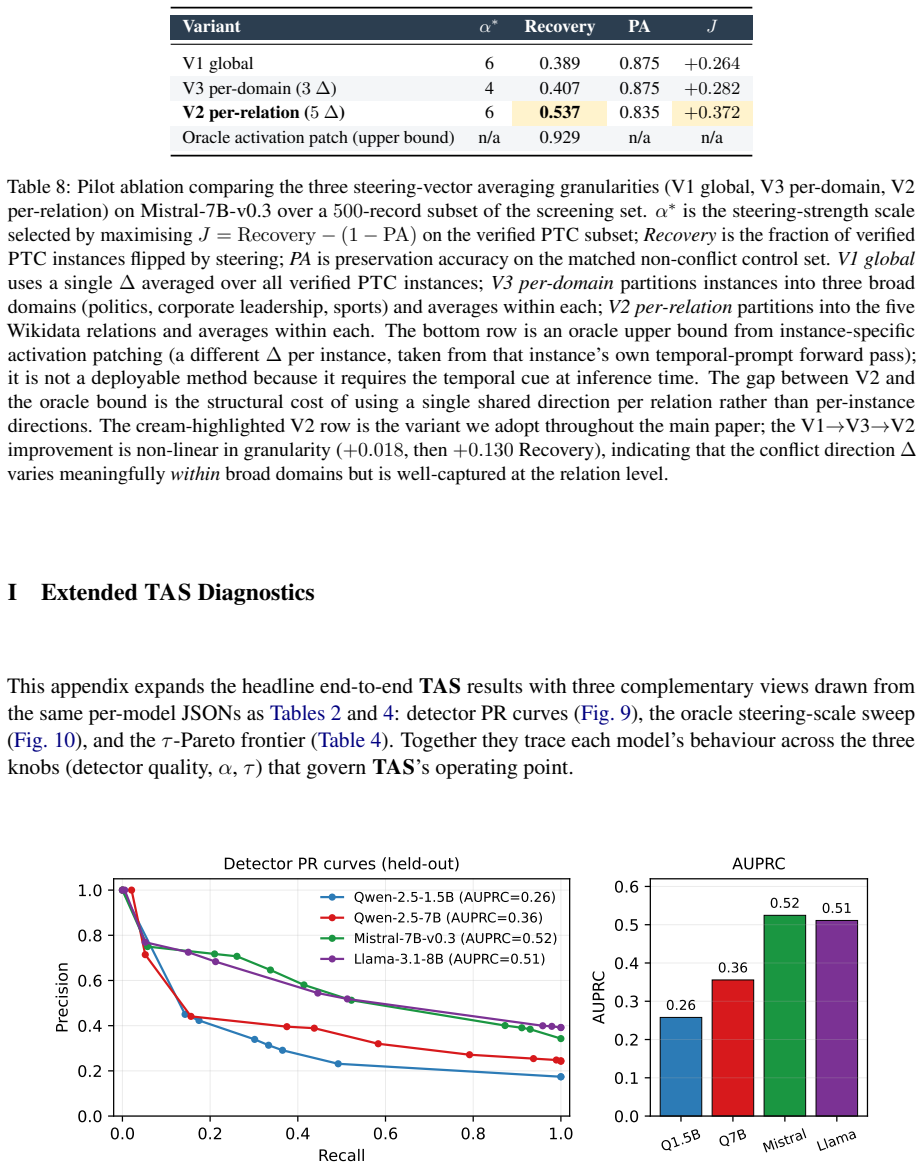
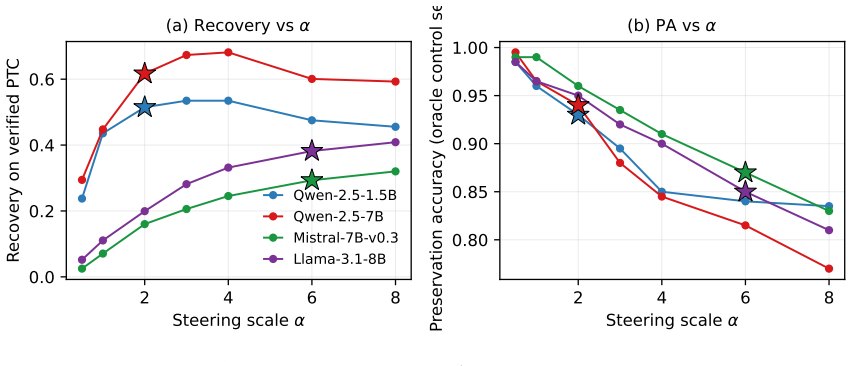
read the original abstract
Large language models can store both outdated facts and newer superseding facts in their parameters, but standard prompting may still elicit the outdated answer. We formalize this problem as Parametric Temporal Conflict (PTC) and introduce Temporal Attractor Steering (TAS), a three-stage test-time intervention that detects likely conflicts, identifies a conflict-critical layer, and steers hidden states toward newer-fact representations without retraining or external retrieval. We construct an 8,746-record verified benchmark across five Wikidata relations and evaluate four open-weight language models from three families: Qwen-2.5-1.5B/7B, Mistral-7B-v0.3, and Llama-3.1-8B. Single-layer activation patching achieves answer-flip rates of 0.72-0.85 across all models. End-to-end TAS resolves 29-57% of PTC cases while preserving 85-99% accuracy on non-conflict queries, outperforming a matched ITI baseline on three of four models. These results show that outdated parametric knowledge can be selectively overridden at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes Parametric Temporal Conflict (PTC) as the issue where LLMs store both outdated and superseding facts in parameters yet standard prompting elicits the outdated answer. It introduces Temporal Attractor Steering (TAS), a three-stage test-time method that detects likely conflicts, identifies a conflict-critical layer, and steers hidden states toward newer-fact representations. An 8,746-record verified benchmark is constructed across five Wikidata relations and evaluated on Qwen-2.5-1.5B/7B, Mistral-7B-v0.3, and Llama-3.1-8B. Single-layer activation patching yields flip rates of 0.72-0.85; end-to-end TAS resolves 29-57% of PTC cases while preserving 85-99% accuracy on non-conflict queries and outperforms a matched ITI baseline on three of four models.
Significance. If the end-to-end results hold, the work demonstrates that outdated parametric knowledge can be selectively overridden at inference time via hidden-state steering without retraining or retrieval. The construction of a verified, multi-relation benchmark provides a concrete, falsifiable testbed for temporal knowledge conflicts and enables direct comparison across model families.
major comments (2)
- [Abstract] The central end-to-end TAS claim (29-57% resolution while preserving 85-99% non-conflict accuracy) rests on the automated detection and layer-identification stages operating without ground-truth answers or side effects on unseen PTC instances. The abstract supplies no equation, pseudocode, or algorithmic description of how the conflict-critical layer is identified (e.g., activation-norm scan, contrastive probe, or other heuristic), leaving open whether the procedure correlates with the five-relation benchmark construction or leaks into unrelated factual representations.
- [Abstract] Single-layer patching is reported with oracle knowledge of the conflict (0.72-0.85 flip rates), yet the load-bearing claim for TAS requires that the first two stages succeed on held-out PTC cases. Without explicit verification that layer selection generalizes independently of the benchmark construction details, the reported preservation rates on non-conflict queries cannot be assessed for unintended degradation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying the presentation of TAS and the evaluation of its stages.
read point-by-point responses
-
Referee: [Abstract] The central end-to-end TAS claim (29-57% resolution while preserving 85-99% non-conflict accuracy) rests on the automated detection and layer-identification stages operating without ground-truth answers or side effects on unseen PTC instances. The abstract supplies no equation, pseudocode, or algorithmic description of how the conflict-critical layer is identified (e.g., activation-norm scan, contrastive probe, or other heuristic), leaving open whether the procedure correlates with the five-relation benchmark construction or leaks into unrelated factual representations.
Authors: The abstract is a concise summary. The full description of the three TAS stages, including the test-time procedure for identifying the conflict-critical layer (with equations for activation contrast and layer selection), appears in Section 3 of the manuscript. This procedure uses only the input query and model activations at inference time, without ground-truth answers. We will revise the abstract to include a brief algorithmic outline of the layer-identification step. revision: yes
-
Referee: [Abstract] Single-layer patching is reported with oracle knowledge of the conflict (0.72-0.85 flip rates), yet the load-bearing claim for TAS requires that the first two stages succeed on held-out PTC cases. Without explicit verification that layer selection generalizes independently of the benchmark construction details, the reported preservation rates on non-conflict queries cannot be assessed for unintended degradation.
Authors: Oracle single-layer patching establishes an upper bound. End-to-end TAS applies the automated detection and layer-identification stages to held-out PTC instances from the benchmark. Non-conflict accuracy is measured on a disjoint set of queries. The layer-selection heuristic is query-dependent and yields consistent results across four models and five relations, supporting generalization. We acknowledge that further ablations on out-of-distribution queries would strengthen the claim and will add such analysis in revision. revision: partial
Circularity Check
No circularity detected; empirical results presented without self-referential reductions or load-bearing self-citations.
full rationale
The manuscript describes an empirical three-stage test-time intervention (TAS) evaluated on a constructed benchmark of 8,746 records, reporting answer-flip rates, resolution percentages, and accuracy preservation as direct experimental outcomes. No equations, parameter-fitting steps, or derivations appear in the provided text that reduce these metrics to inputs by construction. No self-citations are invoked to justify uniqueness or ansatzes, and the method is framed as an independent intervention rather than a renaming or tautological prediction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs store both outdated and newer superseding facts simultaneously in their parameters
invented entities (2)
-
Parametric Temporal Conflict (PTC)
no independent evidence
-
Temporal Attractor Steering (TAS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ashutosh Bajpai, Aaryan Goyal, Atif Anwer, and Tanmoy Chakraborty. 2024. Temporally consistent factuality probing for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15864--15881
2024
-
[3]
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. 2024. Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1204--1228
2024
-
[5]
Bhuwan Dhingra, Jeremy R Cole, Julian Martin Eisenschlos, Daniel Gillick, Jacob Eisenstein, and William W Cohen. 2022. Time-aware language models as temporal knowledge bases. Transactions of the Association for Computational Linguistics, 10:257--273
2022
-
[6]
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. 2024. https://arxiv.org/abs/2406.09170 Test of time: A benchmark for evaluating LLM s on temporal reasoning . In The Thirteenth International Conference on Learning Representations. ArXiv:2406.09170
arXiv 2024
-
[7]
Constanza Fierro, Nicolas Garneau, Emanuele Bugliarello, Yova Kementchedjhieva, and Anders S gaard. 2024. Mulan: A study of fact mutability in language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 762--771
2024
-
[8]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484--5495
2021
-
[10]
Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. 2023. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models. Advances in Neural Information Processing Systems, 36:17643--17668
2023
-
[12]
Xinyue Kang, Diwei Shi, and Li Chen. 2026. Model whisper: Steering vectors unlock large language models' potential in test-time. In Proceedings of the AAAI Conference on Artificial Intelligence. ArXiv:2512.04748; accepted AAAI 2026
arXiv 2026
-
[13]
Jungo Kasai, Keisuke Sakaguchi, yoichi takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah Smith, Yejin Choi, and Kentaro Inui. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/9941624ef7f867a502732b5154d30cb7-Paper-Datasets_and_Benchmarks.pdf Realtime qa: What s the answer right now? In Advances in Neural Information Pro...
arXiv 2023
-
[14]
Yujin Kim, Jaehong Yoon, Seonghyeon Ye, Sangmin Bae, Namgyu Ho, Sung Ju Hwang, and Se-Young Yun. 2024. Carpe diem: On the evaluation of world knowledge in lifelong language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages...
2024
-
[15]
Gaotang Li, Yuzhong Chen, and Hanghang Tong. 2025. https://openreview.net/forum?id=0cEZyhHEks Taming knowledge conflicts in language models . In Forty-second International Conference on Machine Learning. ArXiv:2503.10996
arXiv 2025
-
[16]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference-time intervention: Eliciting truthful answers from a language model. In Advances in Neural Information Processing Systems
2023
-
[18]
Sara Vera Marjanovi \'c , Haeun Yu, Pepa Atanasova, Maria Maistro, Christina Lioma, and Isabelle Augenstein. 2024. Dynamicqa: Tracing internal knowledge conflicts in language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 14346--14360
2024
-
[19]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022 a . Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359--17372
2022
-
[23]
Qingyu Tan, Hwee Tou Ng, and Lidong Bing. 2024. Towards robust temporal reasoning of large language models via a multi-hop qa dataset and pseudo-instruction tuning. In Findings of the Association for Computational Linguistics: ACL 2024, pages 6272--6286
2024
-
[24]
Md Nayem Uddin, Amir Saeidi, Divij Handa, Agastya Seth, Tran Cao Son, Eduardo Blanco, Steven Corman, and Chitta Baral. 2025. Unseentimeqa: Time-sensitive question-answering beyond llms’ memorization. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1873--1913
2025
-
[25]
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, and Thang Luong. 2024. Freshllms: Refreshing large language models with search engine augmentation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 13697--13720
2024
-
[26]
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. 2024. Knowledge conflicts for llms: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541--8565
2024
-
[27]
Michael Zhang and Eunsol Choi. 2021. Situatedqa: Incorporating extra-linguistic contexts into qa. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7371--7387
2021
-
[29]
Bowen Zhao, Zander Brumbaugh, Yizhong Wang, Hannaneh Hajishirzi, and Noah A Smith. 2024. Set the clock: Temporal alignment of pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 15015--15040
2024
-
[30]
Ruilin Zhao, Feng Zhao, Guandong Xu, Sixiao Zhang, and Hai Jin. 2022. Can language models serve as temporal knowledge bases? In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2024--2037
2022
-
[31]
Xinyu Zhu, Cheng Yang, Bei Chen, Siheng Li, Jian-Guang Lou, and Yujiu Yang. 2023. Question answering as programming for solving time-sensitive questions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12775--12790
2023
-
[32]
Zhiyuan Zhu, Yusheng Liao, Zhe Chen, Yuhao Wang, Yunfeng Guan, Yanfeng Wang, and Yu Wang. 2025. Evolvebench: A comprehensive benchmark for assessing temporal awareness in llms on evolving knowledge. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16173--16188
2025
-
[33]
arXiv preprint arXiv:2108.06314 , year=
A dataset for answering time-sensitive questions , author=. arXiv preprint arXiv:2108.06314 , year=
-
[34]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
SituatedQA: Incorporating extra-linguistic contexts into QA , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[35]
Advances in neural information processing systems , volume=
Realtime qa: What's the answer right now? , author=. Advances in neural information processing systems , volume=
-
[36]
RealTime QA: What s the Answer Right Now? , url =
Kasai, Jungo and Sakaguchi, Keisuke and takahashi, yoichi and Le Bras, Ronan and Asai, Akari and Yu, Xinyan and Radev, Dragomir and Smith, Noah and Choi, Yejin and Inui, Kentaro , booktitle =. RealTime QA: What s the Answer Right Now? , url =
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Freshllms: Refreshing large language models with search engine augmentation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[38]
F resh LLM s: Refreshing Large Language Models with Search Engine Augmentation
Vu, Tu and Iyyer, Mohit and Wang, Xuezhi and Constant, Noah and Wei, Jerry and Wei, Jason and Tar, Chris and Sung, Yun-Hsuan and Zhou, Denny and Le, Quoc and Luong, Thang. F resh LLM s: Refreshing Large Language Models with Search Engine Augmentation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.813
-
[39]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Set the clock: Temporal alignment of pretrained language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[40]
arXiv preprint arXiv:2409.13338 , year=
Time awareness in large language models: benchmarking fact recall across time , author=. arXiv preprint arXiv:2409.13338 , year=
-
[41]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[42]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Question answering as programming for solving time-sensitive questions , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[43]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Towards robust temporal reasoning of large language models via a multi-hop QA dataset and pseudo-instruction tuning , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[44]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unseentimeqa: Time-sensitive question-answering beyond llms’ memorization , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Evolvebench: A comprehensive benchmark for assessing temporal awareness in llms on evolving knowledge , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
MRAG: A modular retrieval framework for time-sensitive question answering , author=. Preprint at https://arxiv. org/abs/2412.15540 , year=
-
[47]
Transactions of the Association for Computational Linguistics , volume=
Time-aware language models as temporal knowledge bases , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[48]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Can language models serve as temporal knowledge bases? , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[49]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Carpe diem: On the evaluation of world knowledge in lifelong language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[50]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
Mulan: A study of fact mutability in language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2024
-
[51]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Knowledge conflicts for llms: A survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[52]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
DYNAMICQA: Tracing internal knowledge conflicts in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[53]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Temporally consistent factuality probing for large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[54]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[55]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[56]
arXiv preprint arXiv:2210.07229 , year=
Mass-editing memory in a transformer , author=. arXiv preprint arXiv:2210.07229 , year=
-
[57]
knowledge editing in language models , author=
Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Findings of the Association for Computational Linguistics: EMNLP 2025 , month = nov, year =
Temporal Alignment of Time Sensitive Facts with Activation Engineering , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , month = nov, year =. doi:10.18653/v1/2025.findings-emnlp.404 , pages =
-
[59]
arXiv preprint arXiv:2302.09664 , year=
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
-
[60]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Factual confidence of LLMs: on reliability and robustness of current estimators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[61]
Advances in Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems , year=
-
[62]
Forty-second International Conference on Machine Learning , year =
Taming Knowledge Conflicts in Language Models , author =. Forty-second International Conference on Machine Learning , year =
-
[63]
Time is Encoded in the Weights of Finetuned Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.141 , url =
-
[64]
Test of Time: A Benchmark for Evaluating
Fatemi, Bahare and Kazemi, Mehran and Tsitsulin, Anton and Malkan, Karishma and Yim, Jinyeong and Palowitch, John and Seo, Sungyong and Halcrow, Jonathan and Perozzi, Bryan , booktitle =. Test of Time: A Benchmark for Evaluating. 2024 , url =
2024
-
[65]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Model Whisper: Steering Vectors Unlock Large Language Models' Potential in Test-time , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Model Whisper: Steering Vectors Unlock Large Language Models’ Potential in Test-Time , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[67]
arXiv preprint arXiv:2604.10031 , year=
CoSToM: Causal-oriented Steering for Intrinsic Theory-of-Mind Alignment in Large Language Models , author=. arXiv preprint arXiv:2604.10031 , year=
-
[68]
arXiv preprint arXiv:2603.15892 , year=
Temporal Fact Conflicts in LLMs: Reproducibility Insights from Unifying DYNAMICQA and MULAN , author=. arXiv preprint arXiv:2603.15892 , year=
-
[69]
arXiv preprint arXiv:2601.09445 , year=
Where Knowledge Collides: A Mechanistic Study of Intra-Memory Knowledge Conflict in Language Models , author=. arXiv preprint arXiv:2601.09445 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.