Phonemes to the Rescue: Multilingual Tokenization Based on International Phonetic Alphabet
Pith reviewed 2026-06-26 16:51 UTC · model grok-4.3
The pith
IPA-based tokenizers produce higher-quality subword units than text-based ones across 24 languages and generalize better to unseen scripts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representing text via the International Phonetic Alphabet supplies a compact, language-agnostic symbol inventory that increases character overlap across languages and balances bytes per character, allowing subword tokenizers trained on IPA to segment text more effectively than those trained on raw orthography.
What carries the argument
Matched pairs of text versus IPA subword tokenizers, where the IPA version converts input to phonetic symbols before learning merges.
If this is right
- Token sequences become shorter for languages whose scripts have high bytes-per-character ratios.
- Tokenization quality improves most for non-Latin scripts.
- The same tokenizer can be applied to languages absent from its training data with less degradation.
- Cross-lingual transfer at the model level starts from a more uniform token-level foundation.
Where Pith is reading between the lines
- The approach may reduce the need for language-specific tokenizer tuning in large multilingual models.
- Phonetic input could be combined with byte-level or character-level methods to further compress low-resource languages.
- If IPA conversion quality varies by language, downstream model performance may inherit those conversion errors.
Load-bearing premise
The performance gains are caused by the phonetic representation rather than any uncontrolled differences in vocabulary size, training corpus, or tokenizer algorithm settings.
What would settle it
Re-train the tokenizers with identical data splits, vocabulary sizes, and hyperparameters but swap only the input representation between raw text and IPA; if the IPA advantage disappears, the claim fails.
Figures



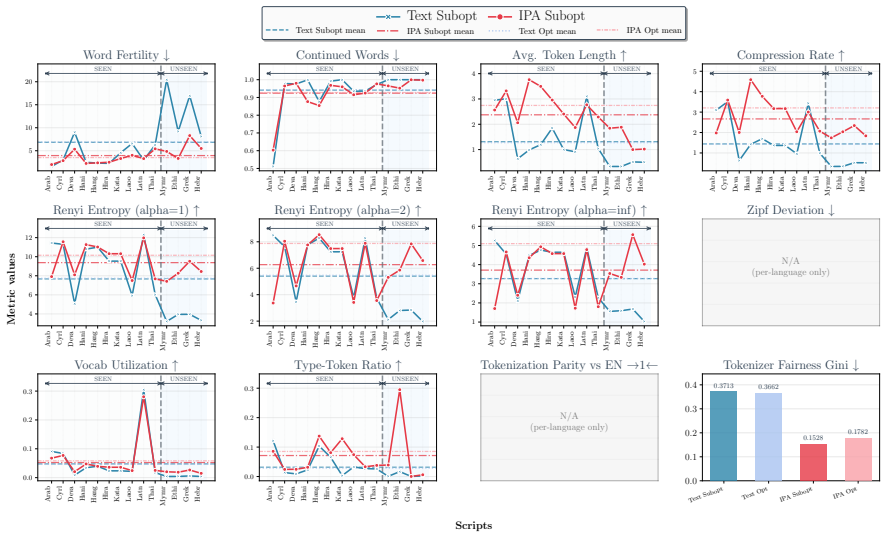
read the original abstract
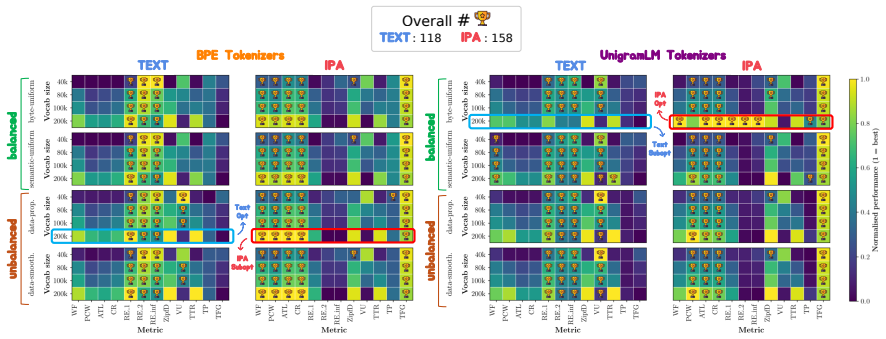
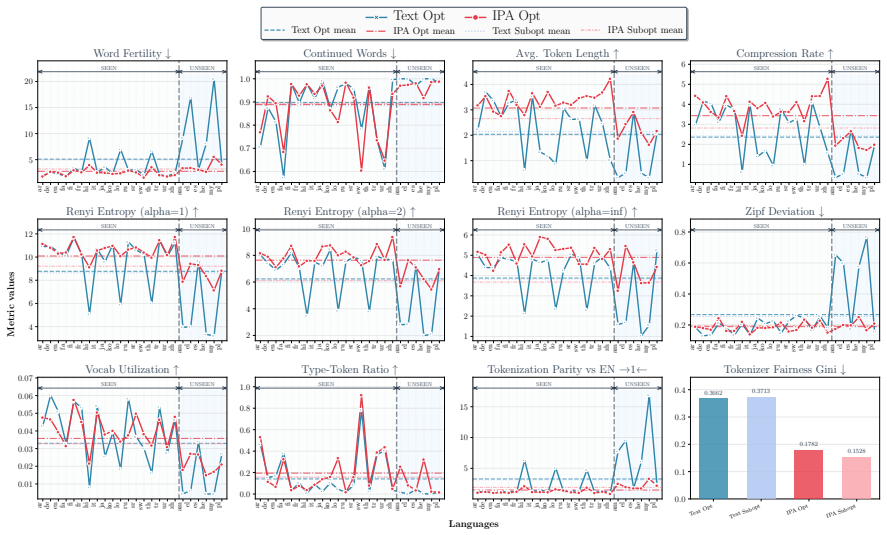
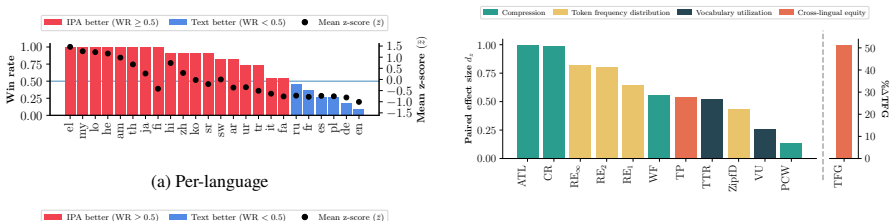
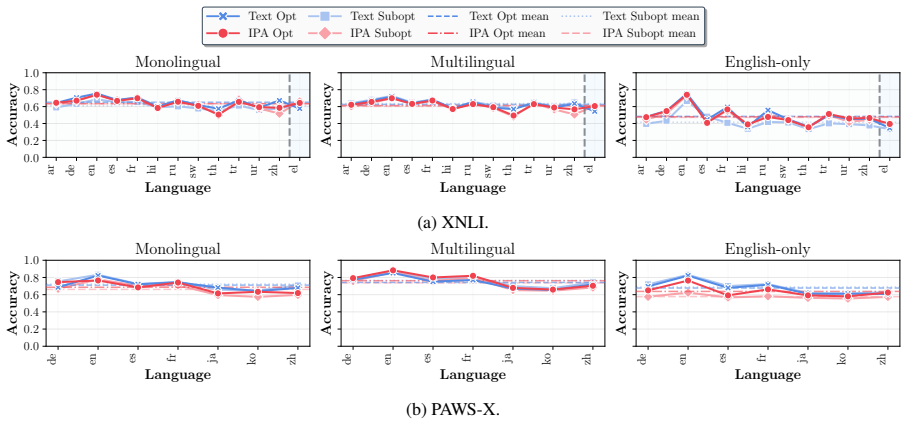
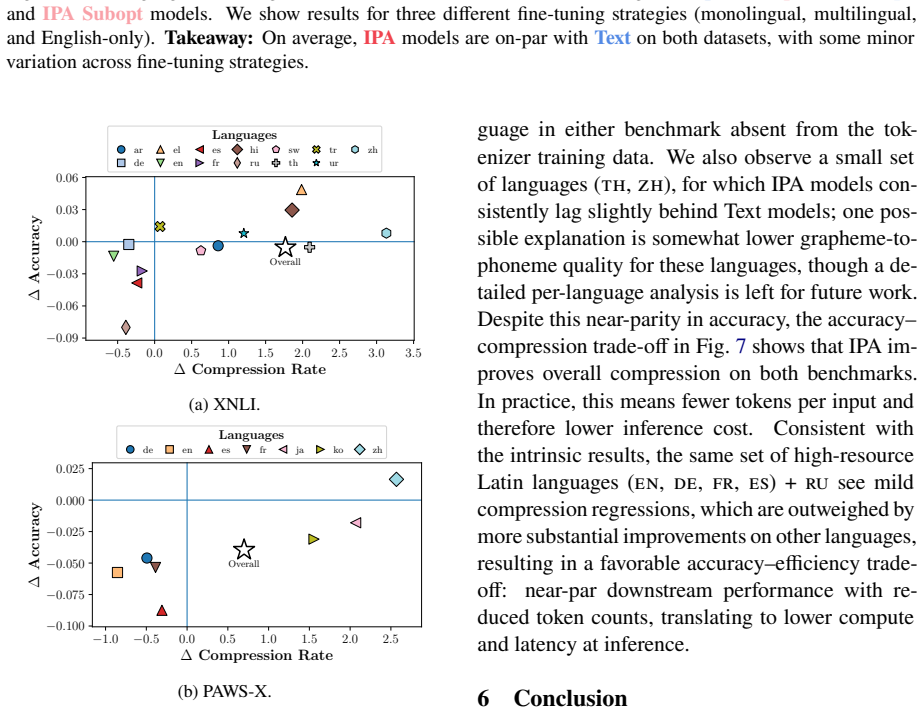
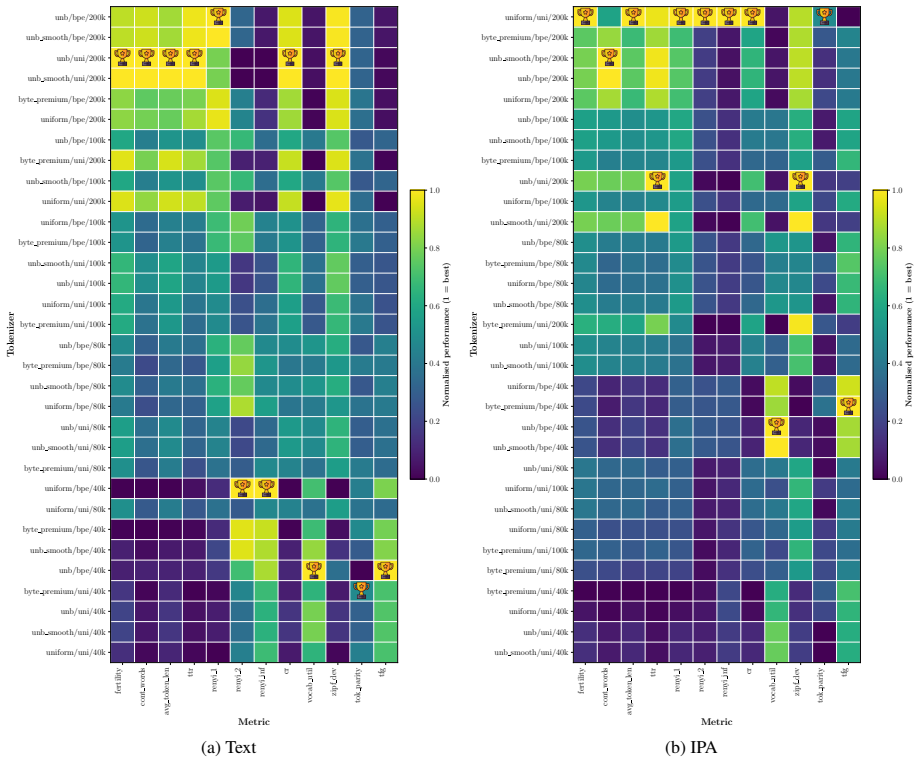
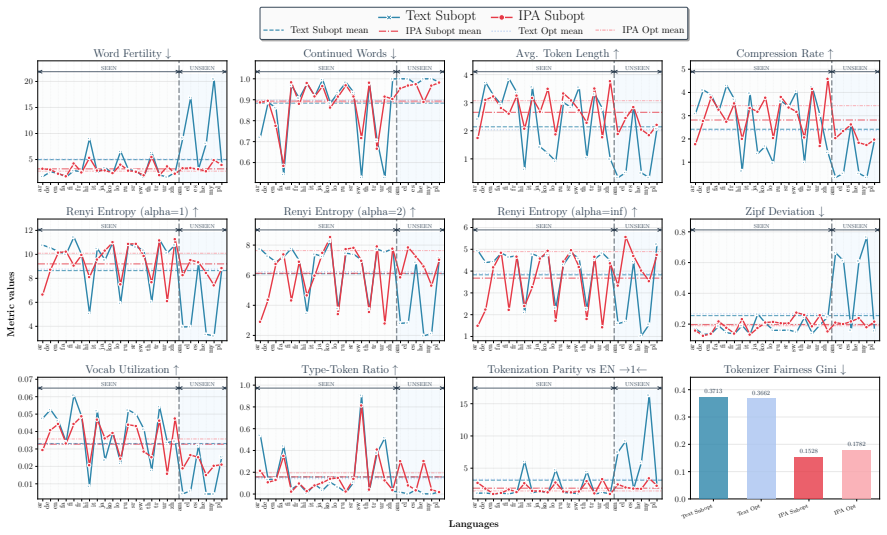
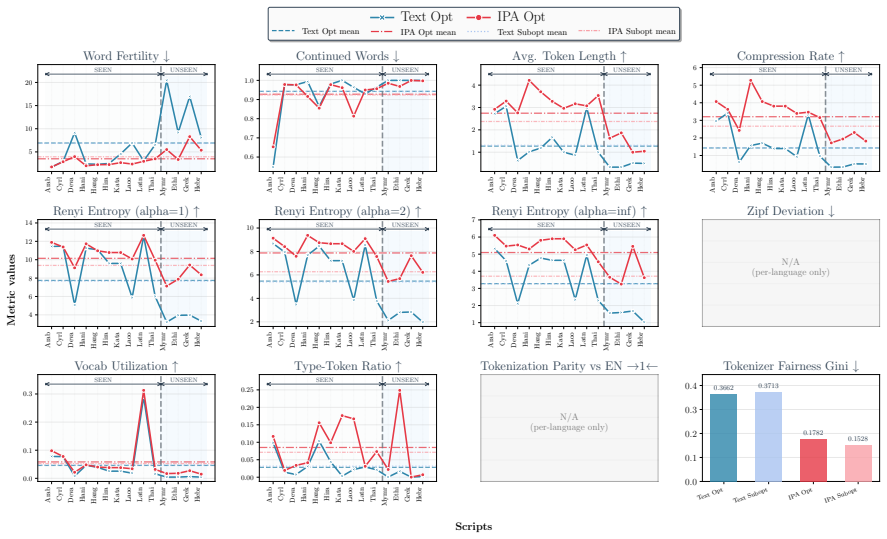
Multilingual language models often exhibit performance disparities across languages that can arise as early as the tokenization stage. Widely-used subword tokenization approaches favor high-resource languages, and tokenizer-free methods still yield longer sequences for scripts with a higher bytes-per-character ratio. To address these shortcomings, we propose to use the International Phonetic Alphabet (IPA) as a language-agnostic input representation for multilingual tokenizers. IPA provides a compact symbol inventory, greater cross-lingual character overlap, and a more balanced byte-per-character distribution across languages. We train matched pairs of text vs. IPA subword tokenizers across 24 languages and 14 scripts and demonstrate that IPA tokenizers consistently improve tokenization quality, especially for non-Latin scripts, and generalize more effectively to unseen languages and scripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using the International Phonetic Alphabet (IPA) as a language-agnostic input representation for subword tokenizers to mitigate performance disparities in multilingual language models. The authors train matched pairs of text vs. IPA tokenizers across 24 languages and 14 scripts, claiming that IPA tokenizers consistently improve tokenization quality (especially for non-Latin scripts) and generalize more effectively to unseen languages and scripts, due to IPA's compact inventory, cross-lingual overlap, and balanced bytes-per-character distribution.
Significance. If the empirical results hold under strict controls, the approach could meaningfully advance equitable multilingual tokenization by reducing script- and language-based disparities at the input stage. The scale of the evaluation (24 languages, 14 scripts) is a positive feature that would strengthen the case for practical adoption if quantitative evidence is provided.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent improvements' and 'better generalization' is presented without any quantitative metrics, baselines, statistical tests, or error analysis. This absence prevents verification that the data support the stated conclusions.
- [Methods] Methods / experimental setup: the description of 'matched pairs' does not establish that vocabulary size, training corpus (or sampling), BPE merge count, and other hyperparameters are identical between the text and IPA tokenizers. Without explicit controls on these factors, observed differences cannot be attributed to the IPA representation itself.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., average fertility reduction or cross-lingual generalization score) to allow readers to assess the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to strengthen clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent improvements' and 'better generalization' is presented without any quantitative metrics, baselines, statistical tests, or error analysis. This absence prevents verification that the data support the stated conclusions.
Authors: We agree that the abstract would be strengthened by including quantitative support. The body of the manuscript reports detailed metrics, baselines, and analyses across the 24-language evaluation. We will revise the abstract to incorporate key quantitative results (e.g., average tokenization efficiency gains and generalization scores) while remaining within length limits. revision: yes
-
Referee: [Methods] Methods / experimental setup: the description of 'matched pairs' does not establish that vocabulary size, training corpus (or sampling), BPE merge count, and other hyperparameters are identical between the text and IPA tokenizers. Without explicit controls on these factors, observed differences cannot be attributed to the IPA representation itself.
Authors: We thank the referee for this observation on experimental controls. Our training procedure used identical settings for each matched pair, but the current text does not state this explicitly. We will revise the Methods section to confirm that vocabulary size, corpus sampling strategy, BPE merge count, and other hyperparameters are held constant, with the sole difference being the input representation (raw text vs. IPA). revision: yes
Circularity Check
No circularity: empirical tokenizer training and comparison
full rationale
The paper presents an empirical study: it trains matched pairs of text-based and IPA-based subword tokenizers on 24 languages and compares their tokenization quality and generalization. No mathematical derivations, equations, or first-principles predictions are described that could reduce to fitted inputs or self-referential definitions. The central claim rests on direct experimental results rather than any chain that collapses by construction. Potential confounding in experimental controls (e.g., vocabulary size or hyperparameters) would be a validity concern, not circularity. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Valentin Hofmann, Tomasz Limisiewicz, Yulia Tsvetkov, and Noah A Smith. 2024. Magnet: Improving the multilingual fairness of language models with adaptive gradient-based tokenization. Advances in Neural Information Processing Systems, 37:47790--47814
2024
-
[2]
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R Mortensen, Noah A Smith, and Yulia Tsvetkov. 2023. Do all languages cost the same? tokenization in the era of commercial language models. arXiv preprint arXiv:2305.13707
arXiv 2023
-
[3]
Mehdi Ali, Michael Fromm, Klaudia Thellmann, Richard Rutmann, Max L \"u bbering, Johannes Leveling, Katrin Klug, Jan Ebert, Niclas Doll, Jasper Buschhoff, and 1 others. 2024. Tokenizer choice for llm training: Negligible or crucial? In Findings of the Association for Computational Linguistics: NAACL 2024, pages 3907--3924
2024
-
[4]
Catherine Arnett and Benjamin Bergen. 2025. Why do language models perform worse for morphologically complex languages? In Proceedings of the 31st International Conference on Computational Linguistics, pages 6607--6623
2025
-
[5]
Catherine Arnett, Tyler A Chang, and Benjamin Bergen. 2024. A bit of a problem: Measurement disparities in dataset sizes across languages. In Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages @ LREC-COLING 2024, pages 1--9
2024
-
[6]
Lisa Beinborn and Yuval Pinter. 2023. Analyzing cognitive plausibility of subword tokenization. arXiv preprint arXiv:2310.13348
arXiv 2023
-
[7]
Mathieu Bernard and Hadrien Titeux. 2021. https://doi.org/10.21105/joss.03958 Phonemizer: Text to phones transcription for multiple languages in python . Journal of Open Source Software, 6(68):3958
-
[8]
Steven Bird, Edward Loper, and Ewan Klein. 2009. Natural Language Processing with Python . O'Reilly Media, Sebastopol, CA
2009
-
[9]
Kaj Bostrom and Greg Durrett. 2020. Byte pair encoding is suboptimal for language model pretraining. arXiv preprint arXiv:2004.03720
arXiv 2020
-
[10]
Iaroslav Chelombitko, Egor Safronov, and Aleksey Komissarov. 2024. Qtok: A comprehensive framework for evaluating multilingual tokenizer quality in large language models. arXiv preprint arXiv:2410.12989
arXiv 2024
-
[11]
Jonathan H Clark, Dan Garrette, Iulia Turc, and John Wieting. 2022. Canine: Pre-training an efficient tokenization-free encoder for language representation. Transactions of the Association for Computational Linguistics, 10:73--91
2022
-
[12]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 8440--8451
2020
-
[13]
Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. https://doi.org/10.18653/v1/D18-1269 XNLI : Evaluating cross-lingual sentence representations . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2475--2485, Brussels, Belgium. Association...
-
[14]
Mathias Creutz and Krista Lagus. 2005. http://www.cis.hut.fi/projects/morpho/ Unsupervised morpheme segmentation and morphology induction from text corpora using morfessor 1.0 . Publications in Computer and Information Science, Report A 81, Helsinki University of Technology
2005
-
[15]
Jacob Devlin. 2018. Multilingual BERT README . https://github.com/google-research/bert/blob/master/multilingual.md. Accessed: 2026-01-05
2018
-
[16]
Miguel Domingo, Mercedes Garc \' a-Mart \' nez, Alexandre Helle, Francisco Casacuberta, and Manuel Herranz. 2019. How much does tokenization affect neural machine translation? In International Conference on Computational Linguistics and Intelligent Text Processing, pages 545--554. Springer
2019
-
[17]
Darius Feher, Ivan Vuli \'c , and Benjamin Minixhofer. 2025. Retrofitting large language models with dynamic tokenization. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29866--29883
2025
-
[18]
Negar Foroutan, Clara Meister, Debjit Paul, Joel Niklaus, Sina Ahmadi, Antoine Bosselut, and Rico Sennrich. 2025. Parity-aware byte-pair encoding: Improving cross-lingual fairness in tokenization. arXiv preprint arXiv:2508.04796
arXiv 2025
-
[19]
Robert C Gale, Alexandra C Salem, Gerasimos Fergadiotis, and Steven Bedrick. 2023. Mixed orthographic/phonemic language modeling: Beyond orthographically restricted transformers (bort). In Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023), pages 212--225
2023
-
[20]
Juan Luis Gastaldi, John Terilla, Luca Malagutti, Brian DuSell, Tim Vieira, and Ryan Cotterell. 2024. The foundations of tokenization: Statistical and computational concerns. arXiv preprint arXiv:2407.11606
arXiv 2024
-
[21]
Z \'e bulon Goriely, Richard Diehl Martinez, Andrew Caines, Paula Buttery, and Lisa Beinborn. 2024. From babble to words: Pre-training language models on continuous streams of phonemes. In The 2nd BabyLM Challenge at the 28th Conference on Computational Natural Language Learning, pages 37--53
2024
-
[22]
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. https://doi.org/10.5281/zenodo.1212303 spacy: Industrial-strength natural language processing in python . Software
-
[23]
Jue Hou, Anisia Katinskaia, Anh-Duc Vu, and Roman Yangarber. 2023. Effects of sub-word segmentation on performance of transformer language models. arXiv preprint arXiv:2305.05480
arXiv 2023
-
[24]
International Phonetic Association . 1999. https://doi.org/10.1017/9780511807954 Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet . Cambridge University Press, Cambridge
-
[25]
Julie Kallini, Dan Jurafsky, Christopher Potts, and Martijn Bartelds. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1153 False F riends are not foes: Investigating vocabulary overlap in multilingual language models . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 21138--21154, Suzhou, China. Association for Computa...
-
[26]
Julie Kallini, Shikhar Murty, Christopher D Manning, Christopher Potts, and R \'o bert Csord \'a s. 2024. Mrt5: Dynamic token merging for efficient byte-level language models. arXiv preprint arXiv:2410.20771
arXiv 2024
-
[27]
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, and 1 others. 2007. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th annual meeting of the association for computational linguistics companion volume proceed...
2007
-
[28]
Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. arXiv preprint arXiv:1804.10959
Pith/arXiv arXiv 2018
-
[29]
Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226
Pith/arXiv arXiv 2018
-
[30]
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. 2019. Quantifying the carbon emissions of machine learning. arXiv preprint arXiv:1910.09700
Pith/arXiv arXiv 2019
-
[31]
Jackson L Lee, Lucas FE Ashby, M Elizabeth Garza, Yeonju Lee-Sikka, Sean Miller, Alan Wong, Arya D McCarthy, and Kyle Gorman. 2020. Massively multilingual pronunciation modeling with wikipron. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 4223--4228
2020
-
[32]
Colin Leong and Daniel Whitenack. 2022. Phone-ing it in: Towards flexible multi-modal language model training by phonetic representations of data. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5306--5315
2022
-
[33]
Vladimir I Levenshtein and 1 others. 1966. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, volume 10, pages 707--710. Soviet Union
1966
-
[34]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 7871--7880
2020
-
[35]
Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer. 2024. https://doi.org/10.18653/v1/2024.acl-long.804 MYTE : Morphology-driven byte encoding for better and fairer multilingual language modeling . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15...
-
[36]
Jonas F. Lotz, Ant \'o nio V. Lopes, Stephan Peitz, Hendra Setiawan, and Leonardo Emili. 2025. https://doi.org/10.18653/v1/2025.acl-long.1546 Beyond text compression: Evaluating tokenizers across scales . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32155--32173, Vienna, Austria....
-
[37]
Jessica M Lundin, Ada Zhang, Nihal Karim, Hamza Louzan, Victor Wei, David Adelani, and Cody Carroll. 2025. The token tax: Systematic bias in multilingual tokenization. arXiv preprint arXiv:2509.05486
arXiv 2025
-
[38]
Chihaya Matsuhira, Marc A Kastner, Takahiro Komamizu, Takatsugu Hirayama, Keisuke Doman, Yasutomo Kawanishi, and Ichiro Ide. 2023. Ipa-clip: Integrating phonetic priors into vision and language pretraining. arXiv preprint arXiv:2303.03144
arXiv 2023
-
[39]
Clara Meister. 2025. https://github.com/cimeister/tokenizer-analysis Tokeval: A tokenizer analysis suite . Software
2025
-
[40]
Sabrina J Mielke, Zaid Alyafeai, Elizabeth Salesky, Colin Raffel, Manan Dey, Matthias Gall \'e , Arun Raja, Chenglei Si, Wilson Y Lee, Beno \^ t Sagot, and 1 others. 2021. Between words and characters: A brief history of open-vocabulary modeling and tokenization in nlp. arXiv preprint arXiv:2112.10508
arXiv 2021
-
[41]
David R Mortensen, Siddharth Dalmia, and Patrick Littell. 2018. Epitran: Precision g2p for many languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)
2018
-
[42]
David R Mortensen, Patrick Littell, Akash Bharadwaj, Kartik Goyal, Chris Dyer, and Lori Levin. 2016. Panphon: A resource for mapping ipa segments to articulatory feature vectors. In Proceedings of COLING 2016, the 26th international conference on computational linguistics: Technical papers, pages 3475--3484
2016
-
[43]
Hoang H Nguyen, Khyati Mahajan, Vikas Yadav, Julian Salazar, Philip S Yu, Masoud Hashemi, and Rishabh Maheshwary. 2024. Prompting with phonemes: Enhancing llms' multilinguality for non-latin script languages. arXiv preprint arXiv:2411.02398
arXiv 2024
-
[44]
Thuat Nguyen, Chien Van Nguyen, Viet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A Rossi, and Thien Huu Nguyen. 2023. Culturax: A cleaned, enormous, and multilingual dataset for large language models in 167 languages. arXiv preprint arXiv:2309.09400
arXiv 2023
-
[45]
Joakim Nivre, Marie-Catherine De Marneffe, Filip Ginter, Jan Haji c , Christopher D Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman. 2020. Universal dependencies v2: An evergrowing multilingual treebank collection. arXiv preprint arXiv:2004.10643
arXiv 2020
-
[46]
Marta R. NLLB Team, Costa-juss \`a , James Cross, Onur C elebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, and 3 others. 2024. https://doi.org/10.1038/s4...
-
[47]
Abraham Toluwase Owodunni, Orevaoghene Ahia, and Sachin Kumar. 2025. Flexitokens: Flexible tokenization for evolving language models. arXiv preprint arXiv:2507.12720
Pith/arXiv arXiv 2025
-
[48]
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, and 1 others. 2024. Byte latent transformer: Patches scale better than tokens. arXiv preprint arXiv:2412.09871
arXiv 2024
-
[49]
Aleksandar Petrov, Emanuele La Malfa, Philip Torr, and Adel Bibi. 2023. Language model tokenizers introduce unfairness between languages. Advances in neural information processing systems, 36:36963--36990
2023
-
[50]
Shengju Qian, Yi Zhu, Wenbo Li, Mu Li, and Jiaya Jia. 2022. What makes for good tokenizers in vision transformer? IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):13011--13023
2022
-
[51]
Libo Qin, Qiguang Chen, Yuhang Zhou, Zhi Chen, Yinghui Li, Lizi Liao, Min Li, Wanxiang Che, and Philip S Yu. 2025. A survey of multilingual large language models. Patterns, 6(1)
2025
-
[52]
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. https://openai.com/blog/language-unsupervised/ Improving language understanding by generative pre-training . Ms, OpenAI
2018
-
[53]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. Ms, OpenAI
2019
-
[54]
Bharath Raj, Garvit Suri, Vikrant Dewangan, and Raghav Sonavane. 2024. When every token counts: Optimal segmentation for low-resource language models. arXiv preprint arXiv:2412.06926
arXiv 2024
-
[55]
Nived Rajaraman, Jiantao Jiao, and Kannan Ramchandran. 2024. Toward a theory of tokenization in llms. arXiv preprint arXiv:2404.08335
arXiv 2024
-
[56]
Phillip Rust, Jonas Pfeiffer, Ivan Vuli \'c , Sebastian Ruder, and Iryna Gurevych. 2020. How good is your tokenizer? on the monolingual performance of multilingual language models. arXiv preprint arXiv:2012.15613
arXiv 2020
-
[57]
Mike Schuster and Kaisuke Nakajima. 2012. Japanese and korean voice search. In 2012 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5149--5152. IEEE
2012
-
[58]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. https://doi.org/10.18653/v1/P16-1162 Neural machine translation of rare words with subword units . In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715--1725, Berlin, Germany. Association for Computational Linguistics
-
[59]
Kevin Slagle. 2024. Spacebyte: Towards deleting tokenization from large language modeling. Advances in Neural Information Processing Systems, 37:124925--124950
2024
-
[60]
Jimin Sohn and David R Mortensen. 2025. Cross-lingual ipa contrastive learning for zero-shot ner. arXiv preprint arXiv:2503.07214
arXiv 2025
-
[61]
Pedro Javier Ortiz Su \'a rez, Laurent Romary, and Beno \^ t Sagot. 2020. A monolingual approach to contextualized word embeddings for mid-resource languages. arXiv preprint arXiv:2006.06202
arXiv 2020
-
[62]
Pedro Javier Ortiz Su \'a rez, Beno \^ t Sagot, and Laurent Romary. 2019. Asynchronous pipeline for processing huge corpora on medium to low resource infrastructures. In 7th Workshop on the Challenges in the Management of Large Corpora (CMLC-7). Leibniz-Institut f \"u r Deutsche Sprache
2019
-
[63]
Yi Tay, Vinh Q Tran, Sebastian Ruder, Jai Gupta, Hyung Won Chung, Dara Bahri, Zhen Qin, Simon Baumgartner, Cong Yu, and Donald Metzler. 2021. Charformer: Fast character transformers via gradient-based subword tokenization. arXiv preprint arXiv:2106.12672
arXiv 2021
-
[64]
Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. 2022. Byt5: Towards a token-free future with pre-trained byte-to-byte models. Transactions of the Association for Computational Linguistics, 10:291--306
2022
-
[65]
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. https://arxiv.org/abs/2010.11934 mt5: A massively multilingual pre-trained text-to-text transformer . Preprint, arXiv:2010.11934
arXiv 2021
-
[66]
Yinfei Yang, Yuan Zhang, Chris Tar, and Jason Baldridge. 2019. https://doi.org/10.18653/v1/D19-1382 PAWS - X : A cross-lingual adversarial dataset for paraphrase identification . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)...
-
[67]
Lili Yu, D \'a niel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. 2023. Megabyte: Predicting million-byte sequences with multiscale transformers. Advances in Neural Information Processing Systems, 36:78808--78823
2023
-
[68]
Tran, Tal Schuster, Donald Metzler, and Jimmy Lin
Crystina Zhang, Jing Lu, Vinh Q. Tran, Tal Schuster, Donald Metzler, and Jimmy Lin. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.98 Tomato, tomahto, tomate: Do multilingual language models understand based on subword-level semantic concepts? In Findings of the Association for Computational Linguistics: NAACL 2025, pages 1821--1837, Albuquerque, N...
-
[69]
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. 2023. Speechtokenizer: Unified speech tokenizer for speech large language models. arXiv preprint arXiv:2308.16692
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.