Object-Centric Dataset Resources for Constrained-Data Image Generation and Augmentation
Pith reviewed 2026-06-26 14:48 UTC · model grok-4.3
The pith
Three standardized object-centric datasets are released to support image generation and augmentation with limited labeled examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
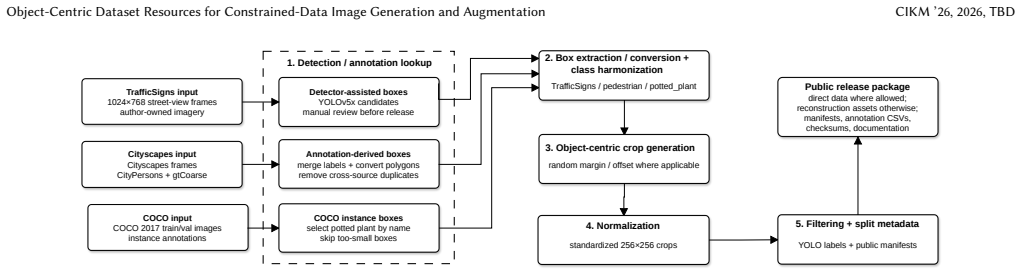
The authors present three object-centric dataset resources—Cityscapes-Pedestrian, TrafficSigns, and COCO PottedPlant—that standardize 256-by-256 crops and bounding-box annotations to support object-centric image generation and synthetic-data augmentation in low-data settings.
What carries the argument
The collection of three standardized 256-by-256 object-centric crops with bounding-box annotations and accompanying manifests across dense, high-contrast, and context-diverse regimes.
If this is right
- Equal-size subsets can be drawn with a fixed random seed to enable controlled comparisons across the three regimes.
- The larger COCO-derived manifest preserves multi-instance and contextual diversity while still permitting balanced subset creation.
- Direct redistribution of TrafficSigns data together with reconstruction documentation for the other two resources supports reproducible experiments on shared records.
- The resources allow label inspection, split creation, and evaluation of generation or augmentation methods on the same manifest tables.
Where Pith is reading between the lines
- The standardized crops could serve as a common benchmark for comparing augmentation techniques that operate on object bounding boxes rather than full scenes.
- Because one subset includes privacy blur, the collection may incidentally support studies of generation methods that remain effective on anonymized inputs.
- Fixed-size subsets drawn from the manifests could be used to test whether performance gains in low-data regimes generalize when the same objects appear in different visual contexts.
Load-bearing premise
Standardizing crops to 256x256 with bounding boxes from these source datasets will produce resources that meaningfully improve training and evaluation of object-centric image generation methods in constrained-data settings.
What would settle it
A controlled experiment in which generative models trained or evaluated on these standardized crops show no measurable improvement in fidelity, diversity, or downstream task performance compared with models trained on unstandardized crops or alternative object-centric subsets drawn from the same source datasets.
Figures

read the original abstract
Object-centric image generation is important in settings with few labeled examples, including pedestrian analysis in smart-city scenes, traffic-sign inspection, and domain-specific object detection. Synthetic images are most useful for training and evaluation when datasets preserve object structure, bounding boxes, visual diversity, and realistic context. Existing image datasets usually target classification, detection, or scene understanding rather than controlled object-centric generation and augmentation with limited class-specific data. We present a shareable collection of three object-centric dataset resources: Cityscapes-Pedestrian, TrafficSigns, and COCO PottedPlant. The collection standardizes 256-by-256 object-centric crops and bounding-box annotations across three regimes: dense pedestrian scenes with privacy blur and occlusion, cleaner high-contrast traffic signs, and context-diverse potted-plant scenes. The release contains 3,009 TrafficSigns samples, 2,156 Cityscapes-Pedestrian manifest records, and 7,679 COCO PottedPlant manifest records. The larger COCO-derived manifest preserves contextual and multi-instance diversity, while equal-size subsets can be drawn with a fixed random seed for controlled comparisons. The release provides direct TrafficSigns data where redistribution is permitted, together with scripts, manifests, box-level annotation tables, checksums, and reconstruction documentation for the Cityscapes- and COCO-derived subsets. It is available through the Latzi/object-centric-low-data-datasets GitHub repository and Zenodo DOI 10.5281/zenodo.20573001. The collection supports label and split inspection, subset creation, reconstruction from upstream data, and evaluation of object-centric image generation or synthetic-data augmentation methods on shared records.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a shareable collection of three object-centric dataset resources derived from existing sources: Cityscapes-Pedestrian (2,156 manifest records), TrafficSigns (3,009 samples), and COCO PottedPlant (7,679 manifest records). Each resource standardizes object-centric 256-by-256 crops together with bounding-box annotations, manifests, checksums, and reconstruction scripts. The release is hosted on GitHub (Latzi/object-centric-low-data-datasets) and Zenodo (DOI 10.5281/zenodo.20573001) and is intended to support label inspection, subset creation, and evaluation of object-centric image generation or augmentation methods in constrained-data regimes across dense/occluded pedestrian scenes, high-contrast traffic signs, and context-diverse potted-plant scenes.
Significance. If the released artifacts match the stated specifications, the work supplies reproducible, standardized resources that can serve as shared benchmarks for object-centric generation research. Explicit credit is due for the inclusion of reconstruction scripts, box-level annotation tables, checksums, and fixed-seed subset instructions, which directly support reproducibility and controlled comparisons.
minor comments (2)
- [Abstract] The abstract states that equal-size subsets can be drawn with a fixed random seed, but the manuscript does not specify the exact seed value or the precise sampling procedure in the main text; adding this detail would improve reproducibility.
- The description of the TrafficSigns resource notes that direct data are provided where redistribution is permitted, but the manuscript does not list the exact license or redistribution constraints for each source dataset; a short table summarizing licenses would clarify usage.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the manuscript and the recommendation to accept. No major comments were raised.
Circularity Check
No significant circularity
full rationale
The manuscript is a pure dataset release and curation paper. It describes the extraction, standardization to 256x256 crops, and packaging of bounding-box manifests from three public upstream sources (Cityscapes, traffic-sign collections, COCO). No equations, fitted parameters, performance predictions, ablation studies, or theoretical derivations appear anywhere in the text. The central claim is simply the existence and accessibility of the packaged resources; this claim is verified by the release itself (GitHub repo, Zenodo DOI, scripts, checksums) and does not rely on any self-referential loop or self-citation chain. Consequently the derivation chain is empty and the circularity score is zero.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Ima- geNet: A Large-Scale Hierarchical Image Database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2009
-
[2]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. InEuropean Conference on Computer Vision (ECCV)
2014
-
[3]
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. The Cityscapes Dataset for Semantic Urban Scene Understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2016
-
[4]
Shanshan Zhang, Rodrigo Benenson, and Bernt Schiele. 2017. CityPersons: A Diverse Dataset for Pedestrian Detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[5]
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. 2018. COCO-Stuff: Thing and Stuff Classes in Context. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[6]
Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie
-
[7]
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images.arXiv preprint arXiv:1601.07140
-
[8]
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. 2020. Ultralytics YOLOv5. https: //github.com/ultralytics/yolov5
2020
-
[9]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. InAdvances in Neural Information Processing Systems (NeurIPS)
2014
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[11]
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. 2020. Training Generative Adversarial Networks with Limited Data. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[12]
Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, and Song Han. 2020. Differen- tiable Augmentation for Data-Efficient GAN Training. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[13]
Bingchen Liu, Yizhe Zhu, Kunpeng Song, and Ahmed Elgammal. 2021. Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis. InInternational Conference on Learning Representations (ICLR)
2021
-
[14]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. 2017. Image-to- Image Translation with Conditional Adversarial Networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[15]
Bo Zhao, Lili Meng, Weidong Yin, and Leonid Sigal. 2019. Image Generation from Layout. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2019
-
[16]
Zeqiang Zheng, Mingyue Cheng, Fangneng Zhan, Hanhui Guo, and Shijian Lu. 2023. LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[17]
Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Apple- ton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino da Silva Santos, Philip E
Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Apple- ton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino da Silva Santos, Philip E. Bourne, and others. 2016. The FAIR Guiding Principles for Scientific Data Management and Stewardship.Scientific Data3, 160018
2016
-
[18]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for Datasets. Communications of the ACM64, 12, 86–92
2021
-
[19]
Vasile Marian, Yong-Bin Kang, and Alexander Buddery. 2026. Do Generative Metrics Predict YOLO Performance? An Evaluation Across Models, Augmentation Ratios, and Dataset Complexity.arXiv preprint arXiv:2602.18525. https://doi.org/ 10.48550/arXiv.2602.18525
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.