Task-Differentiated Atomic Skill Expansion and Routing for Continual Learning Across Highly Heterogeneous Tasks
Pith reviewed 2026-06-26 14:35 UTC · model grok-4.3
The pith
TASER adds and routes distinct atomic skills to handle highly heterogeneous continual learning tasks while reducing forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
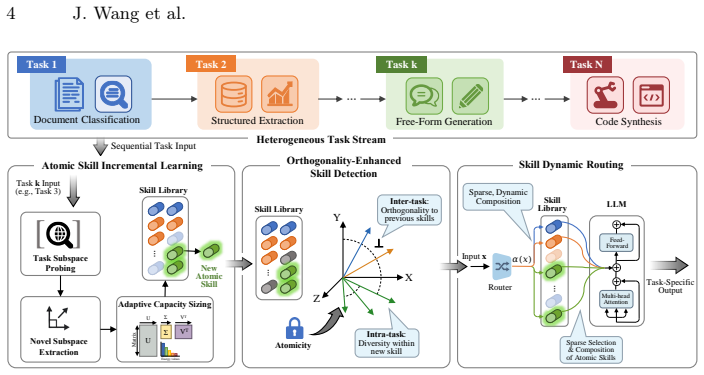
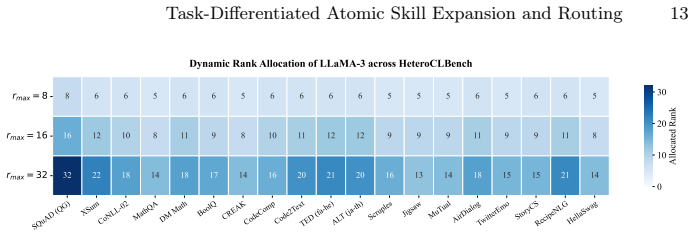
TASER jointly determines how many new atomic skills to introduce for each task and which skills to activate by combining atomic skill incremental learning driven by task divergence and model uncertainty, orthogonality-enhanced skill detection to keep skills semantically distinct and reusable, and skill dynamic routing that composes task-relevant skills through lightweight task-conditioned gating, thereby improving plasticity and reducing catastrophic forgetting on highly heterogeneous task sequences.
What carries the argument
Atomic skills whose number and activation are decided by incremental expansion, orthogonality detection, and dynamic routing.
Load-bearing premise
Atomic skills can be made semantically distinct and independently reusable through orthogonality-enhanced detection while still composing usefully via lightweight gating for arbitrary heterogeneous tasks.
What would settle it
A controlled replication on HeteroCLBench in which TASER fails to produce lower forgetting rates or higher final accuracy than the strongest baselines when tasks differ in reasoning patterns and input-output formats.
Figures
read the original abstract
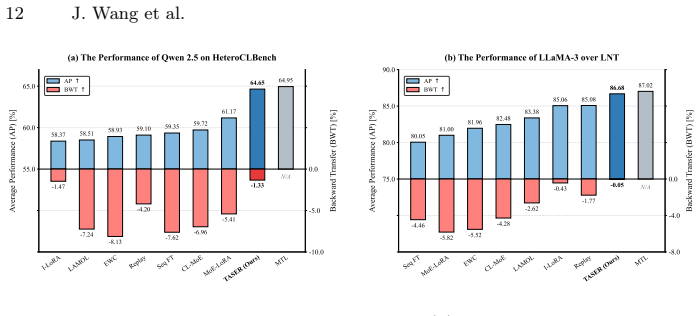
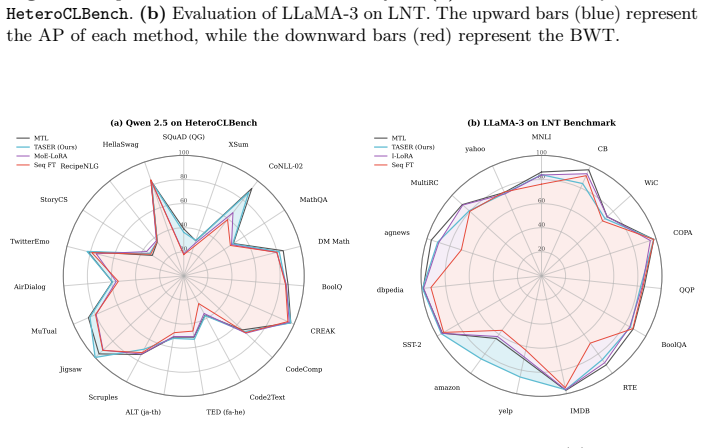
Continual learning (CL) is commonly studied under the assumption that sequential tasks are semantically related or structurally similar. However, in highly heterogeneous settings, where tasks differ substantially in reasoning patterns and input-output formats, existing methods often suffer from catastrophic forgetting and inefficient capacity allocation. To address this challenge, we propose Task-differentiated Atomic Skill Expansion and Routing (\texttt{TASER}), a CL framework that jointly determines how many new atomic skills to introduce for each task and which skills to activate. The framework first uses atomic skill incremental learning to dynamically expand capacity based on task divergence and model uncertainty. It then applies orthogonality-enhanced skill detection to ensure these skills remain semantically distinct and independently reusable. Finally, a skill dynamic routing mechanism composes task-relevant skills through lightweight task-conditioned gating. We further introduce \texttt{HeteroCLBench}, a highly heterogeneous benchmark for CL, comprising 19 diverse tasks across 9 cognitive dimensions under a standardized sequential protocol. Experiments on \texttt{HeteroCLBench} show that \texttt{TASER} consistently outperforms strong baselines by improving plasticity and reducing catastrophic forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TASER, a continual learning framework for highly heterogeneous tasks that differ in reasoning patterns and input-output formats. It dynamically expands capacity via atomic skill incremental learning based on task divergence and model uncertainty, applies orthogonality-enhanced skill detection to produce semantically distinct and independently reusable skills, and composes relevant skills via lightweight task-conditioned gating in a skill dynamic routing mechanism. A new benchmark HeteroCLBench is introduced, consisting of 19 tasks across 9 cognitive dimensions under a standardized sequential protocol. Experiments claim that TASER consistently outperforms strong baselines by improving plasticity and reducing catastrophic forgetting.
Significance. If the results hold and the orthogonality step demonstrably yields functionally modular skills rather than mere parameter-space separation, the work could offer a practical route to capacity allocation and interference mitigation in CL settings that violate the usual semantic-similarity assumption. The introduction of HeteroCLBench would also be a constructive contribution for standardized evaluation of heterogeneous CL.
major comments (2)
- [Abstract] Abstract / method description: the central claim that orthogonality-enhanced skill detection produces skills that are 'semantically distinct and independently reusable' is load-bearing for the routing mechanism, yet no analysis is provided showing that orthogonality correlates with semantic or functional independence (as opposed to linear independence in embedding space) when tasks differ substantially in input-output formats and reasoning patterns. Without such evidence the dynamic routing step cannot be shown to reliably improve plasticity while avoiding interference.
- [Experiments] Experiments section: the claim of consistent outperformance on HeteroCLBench is presented without reported statistical tests, ablation results isolating the contribution of orthogonality-enhanced detection versus the routing or expansion components, or quantitative metrics for plasticity and forgetting; this makes it impossible to verify that gains are attributable to the proposed mechanisms rather than baseline implementation differences.
minor comments (1)
- [Abstract] Notation for 'atomic skills' and the precise definition of task divergence used in capacity expansion should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in evidence and reporting. We agree that both points require additional material and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract / method description: the central claim that orthogonality-enhanced skill detection produces skills that are 'semantically distinct and independently reusable' is load-bearing for the routing mechanism, yet no analysis is provided showing that orthogonality correlates with semantic or functional independence (as opposed to linear independence in embedding space) when tasks differ substantially in input-output formats and reasoning patterns. Without such evidence the dynamic routing step cannot be shown to reliably improve plasticity while avoiding interference.
Authors: We agree that the manuscript does not currently contain a direct quantitative analysis linking the orthogonality constraint to semantic or functional independence across heterogeneous input-output formats. The current version relies on indirect evidence from overall performance gains and qualitative skill visualizations. In revision we will add a dedicated analysis subsection that computes correlations between orthogonality scores and functional metrics (e.g., interference when skills are ablated or transferred across tasks, plus probe-based semantic similarity scores). This will directly address whether orthogonality yields reusable, non-interfering skills rather than mere parameter-space separation. revision: yes
-
Referee: [Experiments] Experiments section: the claim of consistent outperformance on HeteroCLBench is presented without reported statistical tests, ablation results isolating the contribution of orthogonality-enhanced detection versus the routing or expansion components, or quantitative metrics for plasticity and forgetting; this makes it impossible to verify that gains are attributable to the proposed mechanisms rather than baseline implementation differences.
Authors: The current experiments section reports mean performance but omits statistical significance testing, component-wise ablations, and explicit plasticity/forgetting metrics. We will revise the experiments to include: (i) paired statistical tests (t-tests or Wilcoxon) with multiple random seeds and reported p-values, (ii) full ablations that isolate the orthogonality-enhanced detection, the routing gate, and the expansion trigger, and (iii) standard CL metrics for plasticity (forward transfer) and forgetting (backward transfer) computed on HeteroCLBench. These additions will make the attribution of gains transparent. revision: yes
Circularity Check
No circularity: method components and benchmark are independently introduced
full rationale
The paper defines TASER via three explicit mechanisms (atomic skill incremental learning, orthogonality-enhanced detection, skill dynamic routing) and evaluates them on a newly introduced benchmark HeteroCLBench with 19 tasks. No equations, parameters, or performance metrics are shown to be defined in terms of each other or to reduce to fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain consists of design choices and empirical comparisons that remain externally falsifiable.
Axiom & Free-Parameter Ledger
invented entities (1)
-
atomic skills
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems37, 57817–57840 (2024)
Chen, C., Zhu, J., Luo, X., Shen, H.T., Song, J., Gao, L.: Coin: A benchmark of continual instruction tuning for multimodel large language models. Advances in neural information processing systems37, 57817–57840 (2024)
2024
-
[2]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Ding, X., Zhou, J., Dou, L., Chen, Q., Wu, Y., Chen, A., He, L.: Boosting large language models with continual learning for aspect-based sentiment analysis. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 4367–4377 (2024)
2024
-
[3]
In: International conference on artificial intelligence and statistics
Farajtabar, M., Azizan, N., Mott, A., Li, A.: Orthogonal gradient descent for continual learning. In: International conference on artificial intelligence and statistics. pp. 3762–3773. PMLR (2020)
2020
-
[4]
arXiv preprint arXiv:2407.21783 (2024)
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The Llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[5]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[6]
IEEE Transactions on Circuits and Systems for Video Technology (2025)
Huai, T., Zhou, J., Chen, Q., Bai, Q., Zhou, Z., Qiu, X., He, L.: Adaptive momentum mixture-of-experts for continual visual question answering. IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[7]
In: Proceedings of the computer vision and pattern recognition conference
Huai, T., Zhou, J., Wu, X., Chen, Q., Bai, Q., Zhou, Z., He, L.: Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering. In: Proceedings of the computer vision and pattern recognition conference. pp. 19608–19617 (2025)
2025
-
[8]
Pro- ceedings of the National Academy of Sciences115(11), E2496–E2497 (2018)
Huszár, F.: Note on the quadratic penalties in elastic weight consolidation. Pro- ceedings of the National Academy of Sciences115(11), E2496–E2497 (2018)
2018
-
[9]
In: Findings of the association for computational linguistics: EMNLP 2021
Jin, X., Lin, B.Y., Rostami, M., Ren, X.: Learn continually, generalize rapidly: Life- long knowledge accumulation for few-shot learning. In: Findings of the association for computational linguistics: EMNLP 2021. pp. 714–729 (2021)
2021
-
[10]
Trends in cognitive sciences20(7), 512–534 (2016)
Kumaran, D., Hassabis, D., McClelland, J.L.: What learning systems do intelligent agents need? complementary learning systems theory updated. Trends in cognitive sciences20(7), 512–534 (2016)
2016
-
[11]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Li, J., Armandpour, M., Mirzadeh, S.I., Mehta, S., Shankar, V., Vemulapalli, R., Bengio, S., Tuzel, O., Farajtabar, M., Pouransari, H., et al.: TiC-LM: A web-scale benchmark for time-continual LLM pretraining. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 32231–32273 (2025)
2025
-
[12]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Li, X., Ren, W., Qin, W., Wang, L., Zhao, T., Hong, R.: Analyzing and reducing catastrophic forgetting in parameter efficient tuning. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[13]
IEEE transactions on pattern analysis and machine intelligence40(12), 2935–2947 (2017) 16 J
Li, Z., Hoiem, D.: Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence40(12), 2935–2947 (2017) 16 J. Wang et al
2017
-
[14]
Advances in neural information processing systems30(2017)
Lopez-Paz, D., Ranzato, M.: Gradient episodic memory for continual learning. Advances in neural information processing systems30(2017)
2017
-
[15]
In: Psychology of learning and motivation, vol
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: The sequential learning problem. In: Psychology of learning and motivation, vol. 24, pp. 109–165. Elsevier (1989)
1989
-
[16]
Neural networks113, 54–71 (2019)
Parisi, G.I., Kemker, R., Part, J.L., Kanan, C., Wermter, S.: Continual lifelong learning with neural networks: A review. Neural networks113, 54–71 (2019)
2019
-
[17]
Advances in neural information processing systems32(2019)
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., Wayne, G.: Experience replay for continual learning. Advances in neural information processing systems32(2019)
2019
-
[18]
arXiv preprint arXiv:1606.04671 (2016)
Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks. arXiv preprint arXiv:1606.04671 (2016)
Pith/arXiv arXiv 2016
-
[19]
arXiv preprint arXiv:2103.09762 (2021)
Saha, G., Garg, I., Roy, K.: Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762 (2021)
arXiv 2021
-
[20]
ACM Computing Surveys58(5), 1–42 (2025)
Shi, H., Xu, Z., Wang, H., Qin, W., Wang, W., Wang, Y., Wang, Z., Ebrahimi, S., Wang, H.: Continual learning of large language models: A comprehensive survey. ACM Computing Surveys58(5), 1–42 (2025)
2025
-
[21]
arXiv preprint arXiv:1909.03329 (2019)
Sun, F.K., Ho, C.H., Lee, H.Y.: Lamol: Language modeling for lifelong language learning. arXiv preprint arXiv:1909.03329 (2019)
arXiv 1909
-
[22]
IEEE transactions on pattern analysis and machine intelligence46(8), 5362–5383 (2024)
Wang, L., Zhang, X., Su, H., Zhu, J.: A comprehensive survey of continual learning: Theory, method and application. IEEE transactions on pattern analysis and machine intelligence46(8), 5362–5383 (2024)
2024
-
[23]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Wang, X., Chen, T., Ge, Q., Xia, H., Bao, R., Zheng, R., Zhang, Q., Gui, T., Huang, X.J.: Orthogonal subspace learning for language model continual learning. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 10658–10671 (2023)
2023
-
[24]
arXiv preprint arXiv:2310.06762 (2023)
Wang, X., Zhang, Y., Chen, T., Gao, S., Jin, S., Yang, X., Xi, Z., Zheng, R., Zou, Y., Gui, T., et al.: Trace: A comprehensive benchmark for continual learning in large language models. arXiv preprint arXiv:2310.06762 (2023)
arXiv 2023
-
[25]
In: Proceedings of the 2022 conference on empirical methods in natural language processing
Wang, Y., Mishra, S., Alipoormolabashi, P., Kordi, Y., Mirzaei, A., Naik, A., Ashok, A., Dhanasekaran, A.S., Arunkumar, A., Stap, D., et al.: Super-naturalinstructions: Generalization via declarative instructions on 1600+ NLP tasks. In: Proceedings of the 2022 conference on empirical methods in natural language processing. pp. 5085–5109 (2022)
2022
-
[26]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., et al.: Qwen2 technical report (2024),https://arxiv.org/ abs/2407.10671
Pith/arXiv arXiv 2024
-
[27]
ACM Computing Surveys57(5), 1–38 (2025)
Yang, Y., Zhou, J., Ding, X., Huai, T., Liu, S., Chen, Q., Xie, Y., He, L.: Recent advances of foundation language models-based continual learning: A survey. ACM Computing Surveys57(5), 1–38 (2025)
2025
-
[28]
arXiv preprint arXiv:1708.01547 (2017)
Yoon, J., Yang, E., Lee, J., Hwang, S.J.: Lifelong learning with dynamically ex- pandable networks. arXiv preprint arXiv:1708.01547 (2017)
Pith/arXiv arXiv 2017
-
[29]
Advances in neural information processing systems28(2015)
Zhang, X., Zhao, J., LeCun, Y.: Character-level convolutional networks for text classification. Advances in neural information processing systems28(2015)
2015
-
[30]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Zhang, Z., Fang, M., Chen, L., Namazi-Rad, M.R.: Citb: A benchmark for continual instruction tuning. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 9443–9455 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.