Balancing Performance and Diversity in GRPO Autoregressive Text-to-Image Post-Training
Pith reviewed 2026-06-26 14:13 UTC · model grok-4.3
The pith
JS divergence achieves the best trade-off between optimization performance and generation diversity in GRPO-style autoregressive text-to-image alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
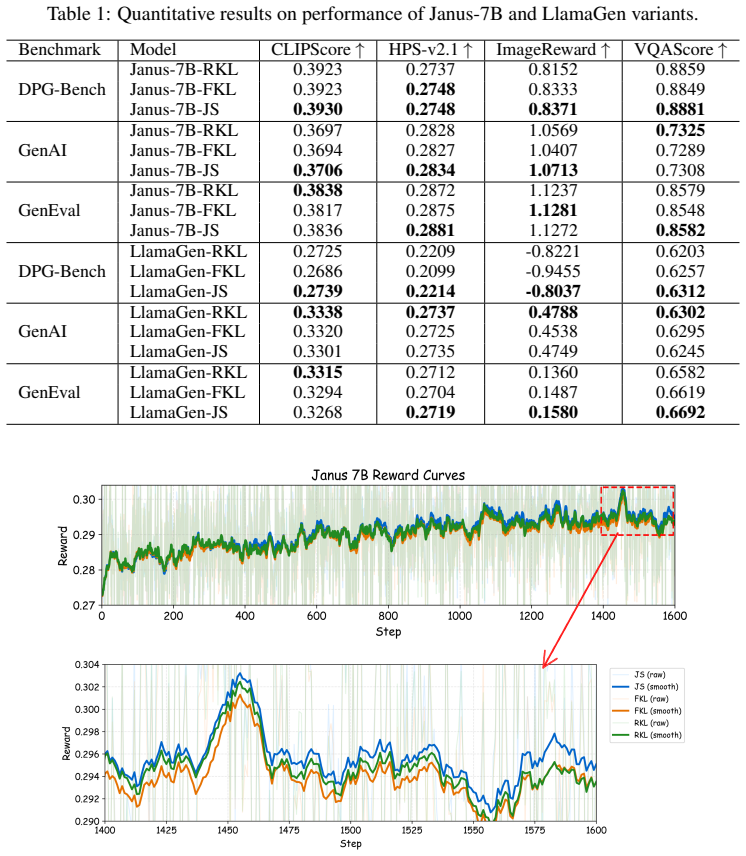
Under the sampled-token shaping form used, JS regularization achieves a favorable trade-off by mitigating uniform bias relative to the reference policy while still discouraging large deviations. Extensive experiments on LlamaGen and Janus-7B show that JS divergence achieves the strongest or highly competitive optimization performance on most evaluation metrics while maintaining favorable generation diversity.
What carries the argument
The unified f-divergence framework (forward KL, reverse KL, JS) applied to token-level updates inside the sampled-token shaping form of GRPO.
If this is right
- JS divergence yields strongest or near-strongest scores on standard T2I alignment metrics.
- JS divergence preserves higher generation diversity than the alternatives under the same shaping form.
- Different f-divergences produce measurably distinct token-level update distributions during GRPO.
- The choice of divergence is a controllable lever that directly trades off bias toward uniformity against policy deviation.
Where Pith is reading between the lines
- The same divergence analysis could be applied to other autoregressive generation tasks that already use GRPO-style updates.
- If the shaping form changes, the relative advantage of JS may shift, suggesting a need to re-derive the token-level bias for each new shaping rule.
- The framework supplies a practical recipe for selecting the divergence term when both performance and diversity must be controlled simultaneously.
Load-bearing premise
The unified f-divergence framework and sampled-token shaping form correctly describe how token-level updates actually occur during GRPO training of autoregressive T2I models.
What would settle it
A controlled run on the same models and data where JS divergence fails to match or exceed the other divergences on the majority of metrics or shows clearly lower diversity would falsify the central claim.
Figures


read the original abstract
Autoregressive text-to-image (T2I) generation has recently advanced rapidly, yet aligning generated images with human preferences remains challenging. GRPO-style online reinforcement learning provides an effective framework; however, existing methods typically treat reference-policy divergence as fixed, despite its direct impact on policy optimization. We study this overlooked factor within a unified f-divergence framework, encompassing forward KL, reverse KL, and JS divergence, for GRPO-style autoregressive T2I alignment. Our systematic theoretical analysis reveals that different divergences reshape token-level updates in distinct ways. In particular, under the sampled-token shaping form used, JS regularization achieves a favorable trade-off by mitigating uniform bias relative to the reference policy while still discouraging large deviations. Extensive experiments on LlamaGen and Janus-7B show that JS divergence achieves the strongest or highly competitive optimization performance on most evaluation metrics while maintaining favorable generation diversity. The code is available at https://github.com/tuoyou-hao/BPD-GRPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the role of reference-policy divergence in GRPO-style online RL for autoregressive T2I models within a unified f-divergence framework (forward KL, reverse KL, JS). It provides a theoretical analysis of how these divergences reshape token-level updates under a sampled-token shaping form, claiming that JS divergence mitigates uniform bias relative to the reference while discouraging large deviations, yielding a favorable performance-diversity trade-off. Experiments on LlamaGen and Janus-7B show JS achieving the strongest or highly competitive results on most metrics while preserving generation diversity. Code is released.
Significance. If the theoretical reshaping analysis holds and directly accounts for the observed metric improvements, the work supplies a principled basis for selecting regularization in GRPO-style T2I alignment, addressing an overlooked factor in balancing optimization strength against diversity. Credit is due for the code release and for testing on two distinct autoregressive backbones. The contribution would be strengthened by explicit linkage between local token-update predictions and training dynamics.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: The central claim that the sampled-token shaping form produces distinct, predictable effects for JS versus KL (mitigating uniform bias while limiting deviations) is load-bearing for explaining the experimental trade-off. The analysis appears to rely on assumptions such as token independence and fixed reference behavior; these may not hold under sequential autoregressive sampling and online reward feedback in GRPO. Direct validation is needed that the derived token-update directions match observed gradients during actual training steps on LlamaGen or Janus-7B.
- [Experiments] Experiments section: The claim that JS divergence yields the strongest or highly competitive optimization performance on most metrics rests on the theory-to-practice mapping. Without reported ablations or correlation analysis showing that the predicted bias mitigation (rather than other implementation choices) drives the metric gains across both models, alternative explanations for the results cannot be ruled out.
minor comments (2)
- [Abstract] Abstract and introduction: Expand the description of the sampled-token shaping form and the precise definition of uniform bias so that readers can follow the theoretical claims without first reading the full derivation.
- [Experiments] Evaluation tables: If multiple random seeds were used, report standard deviations or error bars alongside the metric values to allow assessment of whether reported differences are statistically meaningful.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the linkage between theory and experiments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: The central claim that the sampled-token shaping form produces distinct, predictable effects for JS versus KL (mitigating uniform bias while limiting deviations) is load-bearing for explaining the experimental trade-off. The analysis appears to rely on assumptions such as token independence and fixed reference behavior; these may not hold under sequential autoregressive sampling and online reward feedback in GRPO. Direct validation is needed that the derived token-update directions match observed gradients during actual training steps on LlamaGen or Janus-7B.
Authors: We agree the analysis employs simplifying assumptions (token independence and fixed reference) to obtain closed-form token-update expressions under the sampled-token shaping form. These are standard for isolating divergence effects and yield qualitative predictions that align with the observed performance-diversity trade-offs. We will revise the theoretical section to explicitly list the assumptions and discuss their scope in autoregressive GRPO with online rewards. For validation, we will add a new analysis subsection reporting correlation between predicted update directions and observed per-token gradient statistics from training runs on both backbones. revision: partial
-
Referee: [Experiments] Experiments section: The claim that JS divergence yields the strongest or highly competitive optimization performance on most metrics rests on the theory-to-practice mapping. Without reported ablations or correlation analysis showing that the predicted bias mitigation (rather than other implementation choices) drives the metric gains across both models, alternative explanations for the results cannot be ruled out.
Authors: The experimental protocol holds all GRPO components fixed while varying only the divergence (forward KL, reverse KL, JS) on both LlamaGen and Janus-7B; this isolates the divergence choice as the source of differences. To further tie results to the predicted bias mitigation, we will add correlation analysis between measured deviation from uniform/reference behavior and metric gains across runs. revision: partial
Circularity Check
No circularity: theoretical analysis presented as independent derivation from f-divergence framework
full rationale
The abstract describes a systematic theoretical analysis within a unified f-divergence framework that reveals how divergences reshape token-level updates under sampled-token shaping. No equations, self-citations, or fitted parameters are shown that would make any prediction equivalent to its inputs by construction. The JS divergence trade-off claim is framed as an outcome of the analysis rather than a renaming, self-definition, or load-bearing self-citation. The derivation chain remains self-contained against external benchmarks with no reduction to fitted inputs or prior author work invoked as uniqueness theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automatic thresholding of gray-level pictures using two-dimensional entropy.Computer vision, graphics, and image processing, 47(1):22–32, 1989
Ahmed S Abutaleb. Automatic thresholding of gray-level pictures using two-dimensional entropy.Computer vision, graphics, and image processing, 47(1):22–32, 1989
1989
-
[2]
Entropy-aware preference alignment for diffusion- based text-to-image generation
Hannan Bai, Haoyuan Sun, and Yuncheng Du. Entropy-aware preference alignment for diffusion- based text-to-image generation. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 373–387. Springer, 2025
2025
-
[3]
Root mean square error (rmse) or mean absolute error (mae)?–arguments against avoiding rmse in the literature.Geoscientific model development, 7 (3):1247–1250, 2014
Tianfeng Chai and Roland R Draxler. Root mean square error (rmse) or mean absolute error (mae)?–arguments against avoiding rmse in the literature.Geoscientific model development, 7 (3):1247–1250, 2014
2014
-
[4]
On information-type measure of difference of probability distributions and indirect observations.Studia Sci
Imre Csiszár. On information-type measure of difference of probability distributions and indirect observations.Studia Sci. Math. Hungar., 2:299–318, 1967
1967
-
[5]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
2023
-
[6]
Viss-r1: Self-supervised reinforcement video reasoning
Bo Fang, Yuxin Song, Haoyuan Sun, Xinyao Zhang, Qiangqiang Wu, Wenhao Wu, and Antoni B Chan. Viss-r1: Self-supervised reinforcement video reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11190–11200, 2026
2026
-
[7]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[8]
Aligning language models with preferences through f-divergence minimization
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, and Marc Dymetman. Aligning language models with preferences through f-divergence minimization. arXiv preprint arXiv:2302.08215, 2023
arXiv 2023
-
[9]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[10]
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
Pith/arXiv arXiv 2024
-
[11]
Scope of validity of psnr in image/video quality assessment.Electronics letters, 44(13):800–801, 2008
Quan Huynh-Thu and Mohammed Ghanbari. Scope of validity of psnr in image/video quality assessment.Electronics letters, 44(13):800–801, 2008
2008
-
[12]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
1951
-
[13]
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, et al. Genai-bench: Evaluating and improving compositional text-to-visual generation.arXiv preprint arXiv:2406.13743, 2024
arXiv 2024
-
[14]
Align- ing diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, and Kazuki Kozuka. Align- ing diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
2024
-
[15]
Zhanhao Liang, Yuhui Yuan, Shuyang Gu, Bohan Chen, Tiankai Hang, Ji Li, and Liang Zheng. Step-aware preference optimization: Aligning preference with denoising performance at each step.arXiv preprint arXiv:2406.04314, 2(5):7, 2024. 9
arXiv 2024
-
[16]
Divergence measures based on the shannon entropy.IEEE Transactions on Information theory, 37(1):145–151, 1991
Jianhua Lin. Divergence measures based on the shannon entropy.IEEE Transactions on Information theory, 37(1):145–151, 1991
1991
-
[17]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[18]
Yifu Luo, Penghui Du, Bo Li, Sinan Du, Tiantian Zhang, Yongzhe Chang, Kai Wu, Kun Gai, and Xueqian Wang. Sample by step, optimize by chunk: Chunk-level grpo for text-to-image generation.arXiv preprint arXiv:2510.21583, 2025
Pith/arXiv arXiv 2025
-
[19]
Reinforcement learning meets masked generative models: Mask- grpo for text-to-image generation.Advances in Neural Information Processing Systems, 38: 108460–108485, 2026
Yifu Luo, Xinhao Hu, Keyu Fan, Haoyuan Sun, Zeyu Chen, Bo Xia, Tiantian Zhang, Yongzhe Chang, and Xueqian Wang. Reinforcement learning meets masked generative models: Mask- grpo for text-to-image generation.Advances in Neural Information Processing Systems, 38: 108460–108485, 2026
2026
-
[20]
The hidden link between rlhf and contrastive learning.arXiv preprint arXiv:2506.22578, 2025
Xufei Lv, Kehai Chen, Haoyuan Sun, Xuefeng Bai, Min Zhang, and Houde Liu. The hidden link between rlhf and contrastive learning.arXiv preprint arXiv:2506.22578, 2025
arXiv 2025
-
[21]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[23]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[24]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude Elwood Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
-
[25]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[26]
Cologen: Progressive learning of concept-localization duality for unified image generation
Yuxin Song, Yu Lu, Haoyuan Sun, Huanjin Yao, Fanglong Liu, Yifan Sun, Haocheng Feng, Hang Zhou, and Jingdong Wang. Cologen: Progressive learning of concept-localization duality for unified image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14724–14734, 2026
2026
-
[27]
Generalizing offline alignment theoretical paradigm with diverse divergence constraints
Haoyuan Sun, Yuxin Zheng, Yifei Zhao, Yongzhe Chang, and Xueqian Wang. Generalizing offline alignment theoretical paradigm with diverse divergence constraints. InICML 2024 Workshop on Models of Human Feedback for AI Alignment, 2024
2024
-
[28]
Haoyuan Sun, Jiaqi Wu, Bo Xia, Yifu Luo, Yifei Zhao, Kai Qin, Xufei Lv, Tiantian Zhang, Yongzhe Chang, and Xueqian Wang. Reinforcement fine-tuning powers reasoning capability of multimodal large language models.arXiv preprint arXiv:2505.18536, 2025
arXiv 2025
-
[29]
Generalizing alignment paradigm of text-to-image generation with preferences through f-divergence minimization
Haoyuan Sun, Bo Xia, Yongzhe Chang, and Xueqian Wang. Generalizing alignment paradigm of text-to-image generation with preferences through f-divergence minimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27644–27652, 2025
2025
-
[30]
Identical human prefer- ence alignment paradigm for text-to-image models
Haoyuan Sun, Bo Xia, Yifei Zhao, Yongzhe Chang, and Xueqian Wang. Identical human prefer- ence alignment paradigm for text-to-image models. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025
2025
-
[31]
Positive enhanced preference alignment for text-to-image models
Haoyuan Sun, Bo Xia, Yifei Zhao, Yongzhe Chang, and Xueqian Wang. Positive enhanced preference alignment for text-to-image models. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025. 10
2025
-
[32]
Haoyuan Sun, Jing Wang, Yuxin Song, Yu Lu, Bo Fang, Yifu Luo, Jun Yin, Pengyu Zeng, Miao Zhang, Tiantian Zhang, et al. Power reinforcement post-training of text-to-image models with super-linear advantage shaping.arXiv preprint arXiv:2605.10937, 2026
Pith/arXiv arXiv 2026
-
[33]
Calibration enhanced decision maker: Towards trustworthy sequential decision-making with large sequence models
Haoyuan Sun, Bo Xia, Yifu Luo, Tiantian Zhang, and Xueqian Wang. Calibration enhanced decision maker: Towards trustworthy sequential decision-making with large sequence models. Transactions on Machine Learning Research, 2026
2026
-
[34]
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
Pith/arXiv arXiv 2024
-
[35]
Policy gradient meth- ods for reinforcement learning with function approximation.Advances in neural information processing systems, 12, 1999
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient meth- ods for reinforcement learning with function approximation.Advances in neural information processing systems, 12, 1999
1999
-
[36]
Philip S Thomas and Emma Brunskill. Policy gradient methods for reinforcement learning with function approximation and action-dependent baselines.arXiv preprint arXiv:1706.06643, 2017
Pith/arXiv arXiv 2017
-
[37]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[38]
Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints
Chaoqi Wang, Yibo Jiang, Chenghao Yang, Han Liu, and Yuxin Chen. Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints. InInternational Conference on Learning Representations, volume 2024, pages 10450–10480, 2024
2024
-
[39]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
2004
-
[40]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025
2025
-
[41]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[42]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023
2096
-
[43]
A delay-robust method for enhanced real-time reinforcement learning.Neural Networks, 181:106769, 2025
Bo Xia, Haoyuan Sun, Bo Yuan, Zhiheng Li, Bin Liang, and Xueqian Wang. A delay-robust method for enhanced real-time reinforcement learning.Neural Networks, 181:106769, 2025
2025
-
[44]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[45]
Using human feedback to fine-tune diffusion models without any reward model
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8941–8951, 2024
2024
-
[46]
Floorplan-llama: Aligning architects’ feedback and domain knowledge in architectural floor plan generation
Jun Yin, Pengyu Zeng, Haoyuan Sun, Yuqin Dai, Han Zheng, Miao Zhang, Yachao Zhang, and Shuai Lu. Floorplan-llama: Aligning architects’ feedback and domain knowledge in architectural floor plan generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6640–6662, 2025. 11
2025
-
[47]
Ai-empowered prediction of office building energy use from single-view conceptual images for early-stage design.Applied Energy, 406:127289, 2026
Jun Yin, Pengyu Zeng, Yujian Huang, Haoyuan Sun, Tianze Hao, Shuai Lu, et al. Ai-empowered prediction of office building energy use from single-view conceptual images for early-stage design.Applied Energy, 406:127289, 2026
2026
-
[48]
Mred-14: A benchmark for low-energy residential floor plan generation with 14 flexible inputs
Pengyu Zeng, Jun Yin, Haoyuan Sun, Yuqin Dai, Maowei Jiang, Miao Zhang, and Shuai Lu. Mred-14: A benchmark for low-energy residential floor plan generation with 14 flexible inputs. InProceedings of the 33rd ACM International Conference on Multimedia, pages 11298–11307, 2025
2025
-
[49]
Guohui Zhang, Hu Yu, Xiaoxiao Ma, JingHao Zhang, Yaning Pan, Mingde Yao, Jie Xiao, Linjiang Huang, and Feng Zhao. Group critical-token policy optimization for autoregressive image generation.arXiv preprint arXiv:2509.22485, 2025
arXiv 2025
-
[50]
Fsim: A feature similarity index for image quality assessment.IEEE transactions on Image Processing, 20(8):2378–2386, 2011
Lin Zhang, Lei Zhang, Xuanqin Mou, and David Zhang. Fsim: A feature similarity index for image quality assessment.IEEE transactions on Image Processing, 20(8):2378–2386, 2011
2011
-
[51]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 12
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.