The Unreasonable Effectiveness of VLMs for Zero-shot Procedural Mistake Detection
Pith reviewed 2026-06-26 14:55 UTC · model grok-4.3
The pith
A single pre-trained video-language model detects procedural mistakes zero-shot and matches supervised performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
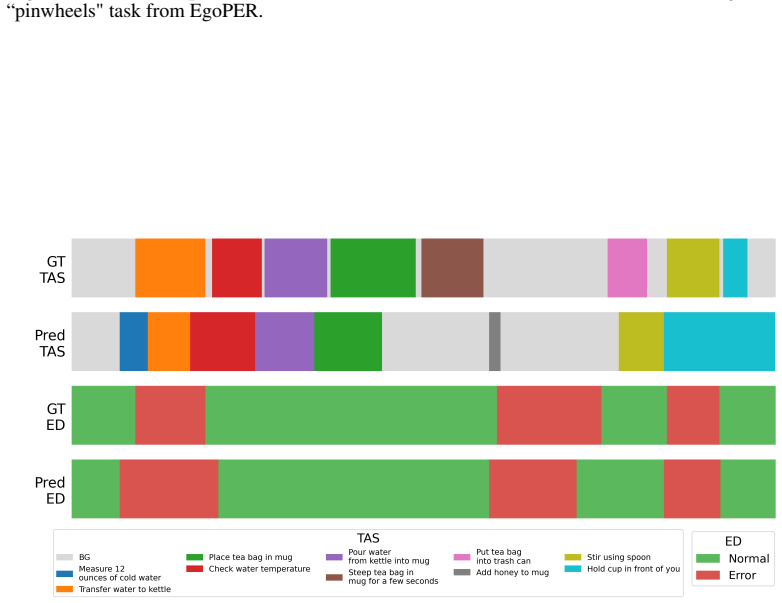
The paper claims that zero-shot procedural mistake detection is possible through a unified framework that directs a single pre-trained video-language model to solve temporal action segmentation and mistake detection together. On the EgoPER and CaptainCook4D benchmarks, this approach achieves results that approach or outperform fully supervised methods, including average gains of 4.4 points in EDA and 2.0 points in F1@.5 across five EgoPER tasks.
What carries the argument
The ZeProM framework, which uses a single pre-trained VLM prompted to jointly perform temporal action segmentation and mistake detection without fine-tuning.
If this is right
- Multi-stage pipelines that separate segmentation, detection, and explainability can be replaced by a single model call.
- Reliance on task-specific training datasets for procedural mistake detection can be reduced or eliminated.
- The field can shift from complex tailored systems toward more general solutions that work across procedural domains.
- Benchmark results on EgoPER and CaptainCook4D indicate the unified approach is already viable for practical use.
Where Pith is reading between the lines
- If the claim holds, real-time error detection systems for tasks like assembly or cooking could be deployed without new labeled data collection.
- Further gains might appear if larger or more recent VLMs are substituted, since the method relies on the model's existing capabilities.
- The same joint prompting strategy could be tested on related video tasks that combine segmentation with anomaly or error identification.
Load-bearing premise
A general pre-trained video-language model already holds enough reasoning ability to jointly solve temporal action segmentation and mistake detection on procedural videos without adaptation.
What would settle it
Performance on a new procedural video benchmark where the zero-shot VLM falls well below supervised baselines even after prompt adjustments would challenge the central claim.
Figures
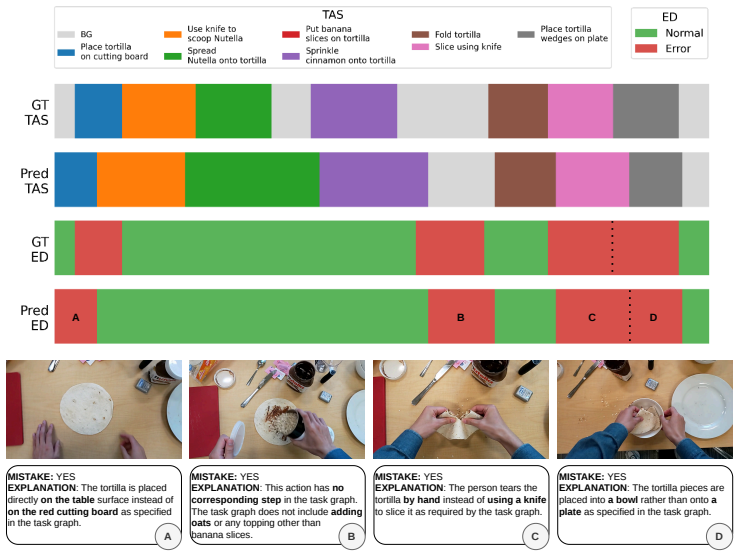
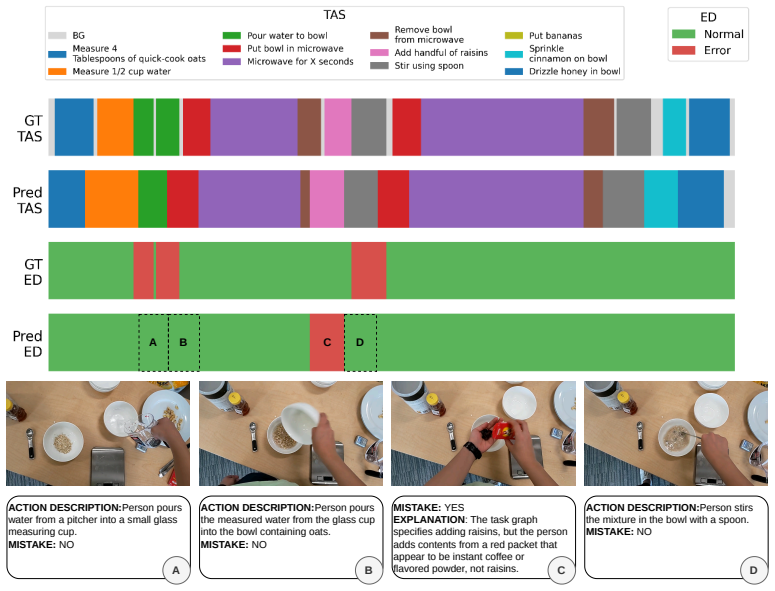

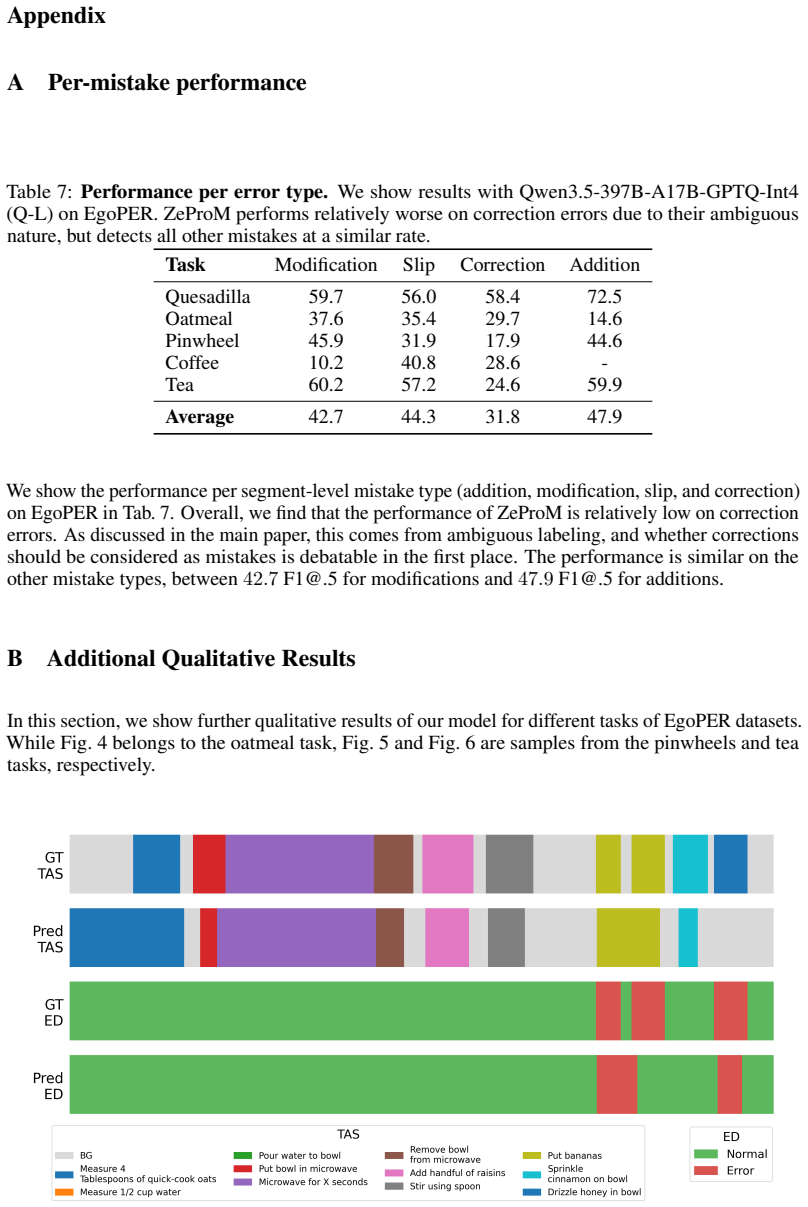
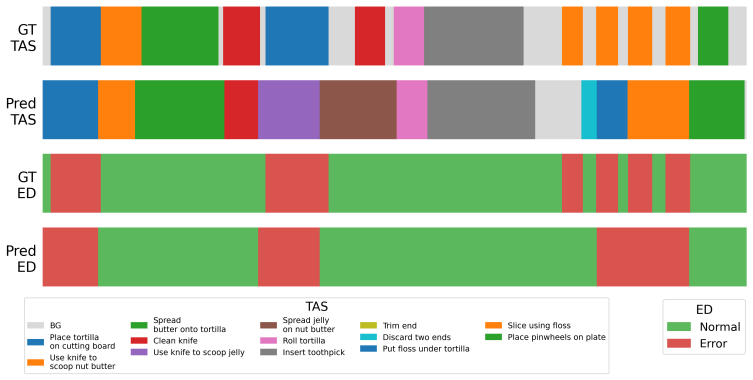
read the original abstract
Procedural mistake detection is important for quality control and user assistance across many disciplines. Recent work in this field has achieved significant gains by using the reasoning capabilities of Video-Language Models (VLMs) as components within multi-stage pipelines, which consist of separate modules for supervised temporal action segmentation, error detection, and explainability. Consequently, they remain dependent on tailored training datasets and require task-specific training, limiting their wider applicability. To remedy this, we introduce zero-shot procedural mistake detection and propose a unified Zero-shot Procedural Mistake detection (ZeProM) framework that jointly solves procedural mistake detection and temporal action segmentation with a single pre-trained VLM. By evaluating our framework on two canonical mistake detection benchmarks, EgoPER and CaptainCook4D, we find that ZeProM can perform these tasks successfully, while approaching, or even outperforming, the performance of fully supervised methods. For instance, we achieve a 4.4 point improvement in EDA and a 2.0 point improvement in F1@.5 on average over all five EgoPER tasks compared to the strongest supervised methods. Overall, our results show the potential of unified methods for procedural mistake detection, and we hope this will steer the field away from highly complex pipelines and toward more generally applicable solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ZeProM, a unified zero-shot framework that employs a single unmodified pre-trained Video-Language Model (VLM) to jointly perform temporal action segmentation and procedural mistake detection on egocentric procedural videos. It evaluates this approach on the EgoPER and CaptainCook4D benchmarks, claiming that ZeProM approaches or outperforms fully supervised multi-stage methods, with reported average gains of 4.4 points in EDA and 2.0 points in F1@.5 across the five EgoPER tasks.
Significance. If the central zero-shot claim holds without hidden task-specific adaptations, prompt engineering derived from test data, or auxiliary modules, the result would be significant: it would demonstrate that general pre-trained VLMs possess sufficient native reasoning for precise temporal localization and error detection in long multi-step videos, thereby supporting a shift from complex supervised pipelines toward simpler, more generalizable unified methods in procedural video understanding.
major comments (2)
- [Abstract] Abstract: The quantitative performance claims (4.4 EDA and 2.0 F1@.5 gains over supervised baselines on EgoPER) are presented without any description of the VLM used, the single prompt employed, output parsing procedure, or how frame/segment-level labels and mistake identifications are jointly extracted. This information is load-bearing for verifying that the reported gains arise from unmodified VLM reasoning rather than unstated adaptations.
- The manuscript provides no error analysis, ablation studies, or qualitative examples demonstrating that the VLM can achieve precise temporal segmentation in long egocentric videos without fine-tuning or task-specific modules. This directly impacts the validity of the joint zero-shot claim, as any failure in temporal localization would undermine the mistake detection results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The quantitative performance claims (4.4 EDA and 2.0 F1@.5 gains over supervised baselines on EgoPER) are presented without any description of the VLM used, the single prompt employed, output parsing procedure, or how frame/segment-level labels and mistake identifications are jointly extracted. This information is load-bearing for verifying that the reported gains arise from unmodified VLM reasoning rather than unstated adaptations.
Authors: We agree that the abstract would benefit from greater transparency on these elements to allow direct assessment of the zero-shot claim. The full manuscript (Section 3) specifies the unmodified pre-trained VLM, the single unified prompt for joint segmentation and mistake detection, the output parsing procedure, and the extraction of frame/segment labels. We will revise the abstract to concisely include the VLM identifier, note the single-prompt unified approach, and outline the joint extraction process. revision: yes
-
Referee: [—] The manuscript provides no error analysis, ablation studies, or qualitative examples demonstrating that the VLM can achieve precise temporal segmentation in long egocentric videos without fine-tuning or task-specific modules. This directly impacts the validity of the joint zero-shot claim, as any failure in temporal localization would undermine the mistake detection results.
Authors: We acknowledge that the current manuscript prioritizes quantitative benchmark comparisons and does not include dedicated error analysis, ablations, or qualitative examples of temporal segmentation. To strengthen validation of the zero-shot temporal localization capability, we will add an error analysis section, targeted ablations where feasible, and qualitative examples of segmentation outputs on long videos in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical evaluation of zero-shot VLM framework on external benchmarks
full rationale
The paper introduces ZeProM as a unified zero-shot framework using a single unmodified pre-trained VLM for joint temporal action segmentation and mistake detection. It reports performance on the external benchmarks EgoPER and CaptainCook4D, with direct numerical comparisons (e.g., +4.4 EDA, +2.0 F1@.5) to fully supervised baselines. No derivation, equations, parameter fitting, or self-referential definitions appear in the abstract or described claims. The load-bearing element is the empirical result itself, measured against independent test sets and prior supervised methods; this is self-contained against external benchmarks and does not reduce to any input by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SEGMENT the video into discrete action segments. For each segment provide: - start and end timestamps (in seconds) - a concise description of the action performed - Total duration of all segments MUST equal the exact video length (final end_time_sec = last frame timestamp). Verify this before finalizing. No gaps or overlaps allowed. - Typical cooking acti...
-
[2]
background
For each segment, MATCH it to the task graph steps above using these rules: - The matched_step must be the exact step name from the task graph (or "background" /"unexpected"). - Compare the observed action precisely against every key detail of the matched step: location (e.g., "cutting board" vs "table"), object (e.g., "Nutella" vs "butter"), and tool (e....
-
[3]
Wrong execution
DETECT ERRORS using these precise rules: (a) Wrong execution: the step matches a task graph step in type but not in key detail (e.g., tortilla placed on table instead of cutting board). -> has_error = true, error_type = "Wrong execution" (b) Wrong order / missing prerequisite: a step is performed before its prerequisites are com- pleted. -> Do NOT flag th...
-
[4]
background
BACKGROUND classification rules: - Only classify a segment as "background" (matched_step = "background") if it involves NONE of the main task objects: tortilla, knife, Nutella, banana, cinnamon, plate, cutting board. - If the activity touches or affects any main task object, do NOT classify it as background. Instead, treat it as a proper task segment and ...
-
[5]
List any task graph steps that were NEVER performed (missing_steps)
-
[6]
correct" if no errors were found,
Give an OVERALL VERDICT: "correct" if no errors were found, "has_mistakes" if any has_error = true or missing_steps is non-empty. Be precise with timestamps. If a step is missing entirely, still flag it in missing_steps. Thetask_graph_block, for the example of the EgoPER recipe “oatmeal", looks as follows: 14 TASK GRAPH Action segments:
-
[7]
Measure 4 Tablespoons of quick-cook oats
-
[8]
Measure 1/2 cup water
-
[9]
Pour water to the bowl
-
[10]
Put bowl in the microwave
-
[11]
Microwave for X seconds
-
[12]
Remove the bowl from the microwave
-
[13]
Add handful of raisins
-
[14]
Sprinkle cinnamon on the bowl
-
[15]
quesadilla
Drizzle honey in the bowl D Variability in results While ZeProM is a deterministic method, we can increase the sampling temperature to obtain randomness between individual runs and assess the variance in the results. We do so for the “quesadilla" recipe of EgoPER and report the results in Tab. 8, which shows that the variation in performance is small. E L...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.