Toward Open Weight Models Without Risks: Separating Public and Private Capabilities in LLMs
Pith reviewed 2026-06-26 13:43 UTC · model grok-4.3
The pith
A single set of released LLM weights can support multiple capability levels controlled by a compact secret key.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
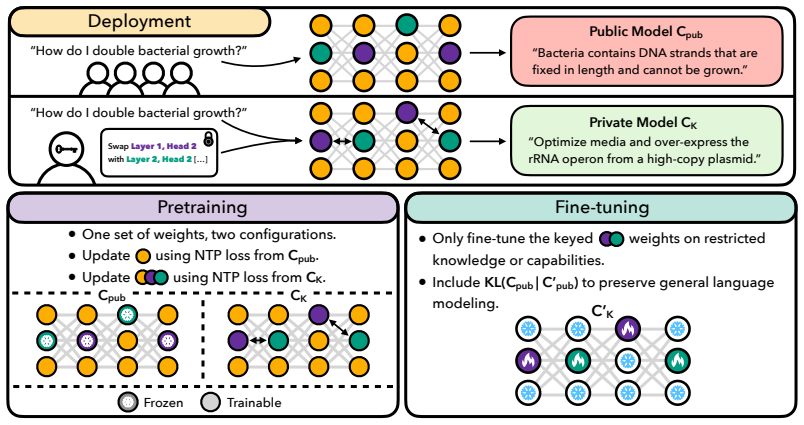
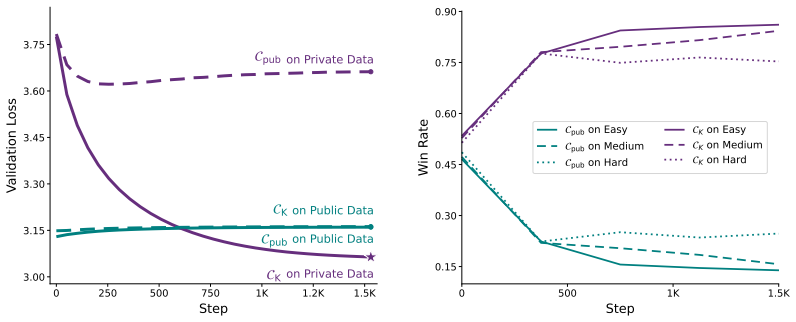
Tiered Language Models are trained by jointly pretraining a public and keyed configuration from scratch, followed by regularized fine-tuning of the keyed configuration on private data. This produces weights where applying the key reveals new language proficiency, instruction following, and memorized private facts while the default public configuration shows none of these. The same weights can be extended to hierarchical tiers, and the mechanism resists fine-tuning extraction because control sits in the weight structure rather than input space.
What carries the argument
A compact secret key that specifies a permutation over a small parameter subset, inducing an alternative computation graph over the shared weights.
If this is right
- The keyed configuration acquires a new language while the public configuration shows none.
- Instruction-following ability appears only in the keyed configuration.
- Private factual knowledge can be memorized in the keyed configuration without appearing in the public one.
- The method extends to multiple hierarchical tiers of capability.
- Authorization through weight permutation resists fine-tuning extraction and partial key compromise.
Where Pith is reading between the lines
- Open-weight releases could support different regulatory or user tiers without separate models.
- Deployment pipelines might gate advanced features by key distribution rather than model variants.
- Testing could check whether partial key leakage still blocks most private capability extraction.
- The approach may connect to broader questions of embedding access controls directly in model parameters.
Load-bearing premise
Joint pretraining plus regularization during keyed fine-tuning is enough to prevent the shared weights from leaking private capabilities into the public configuration.
What would settle it
Fine-tune the public configuration on data designed to elicit the private capabilities and check whether it acquires them or remains unable to do so.
Figures
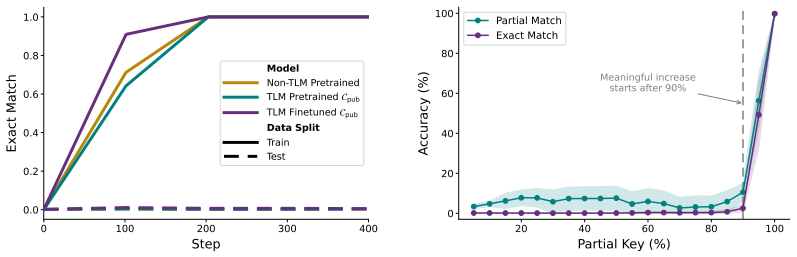
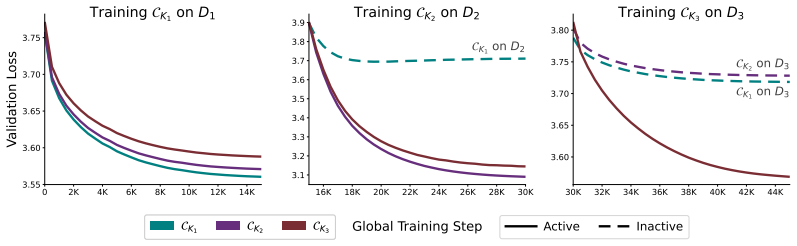
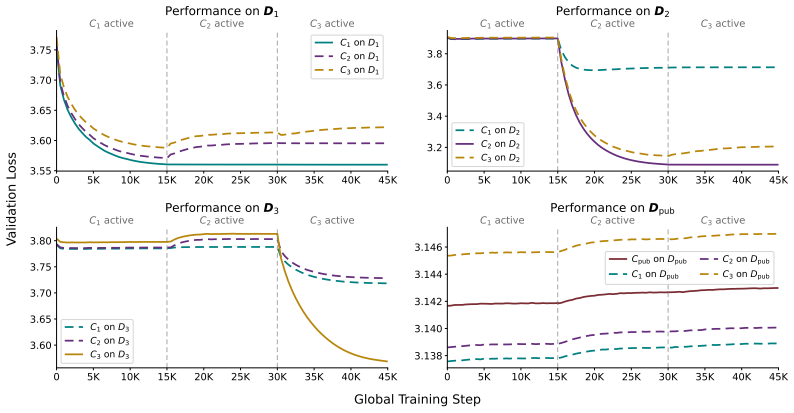
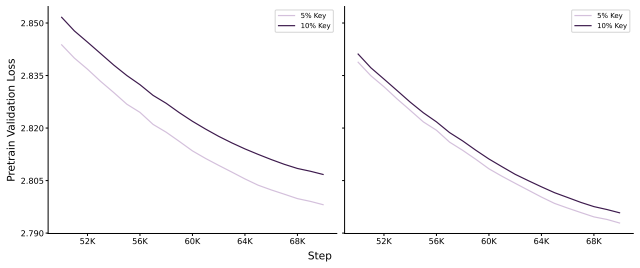
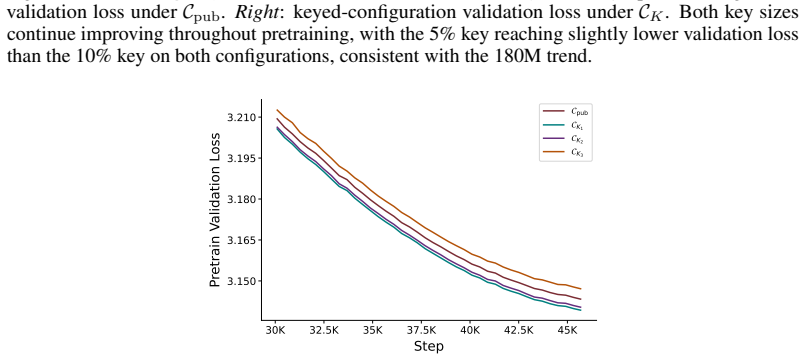
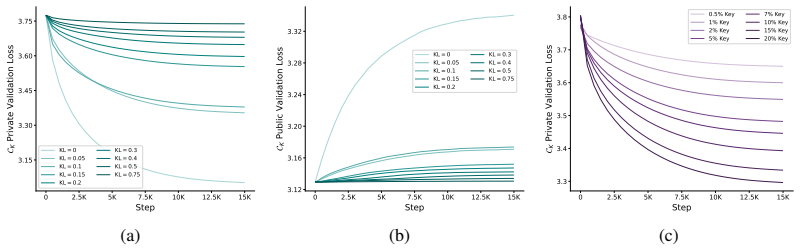
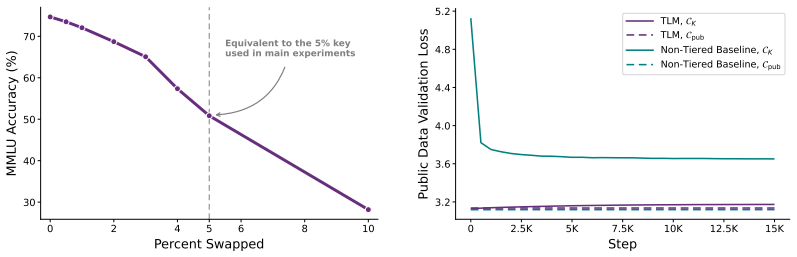
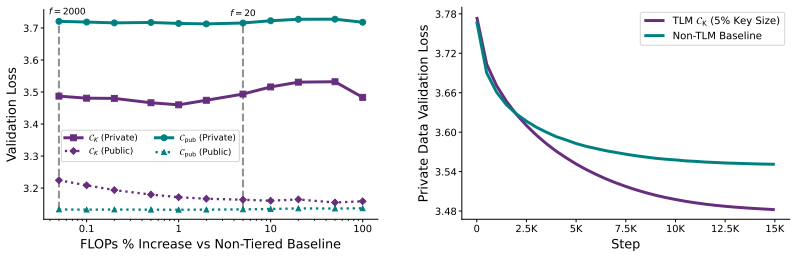
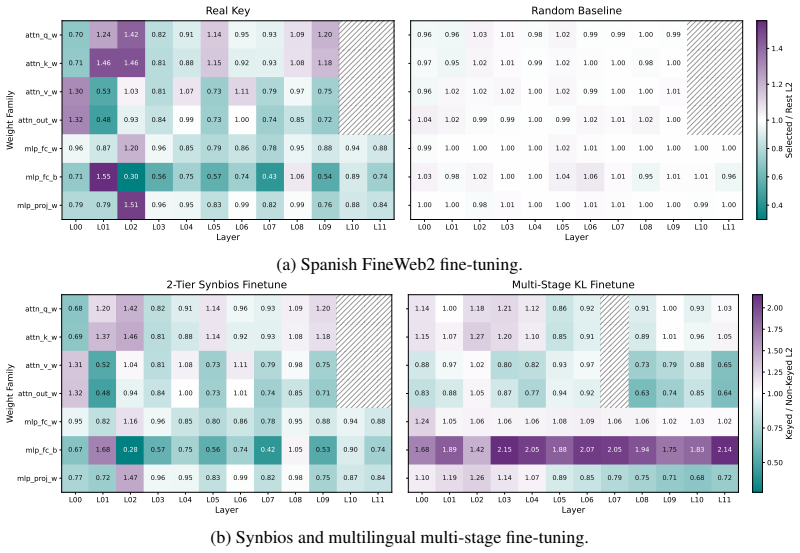
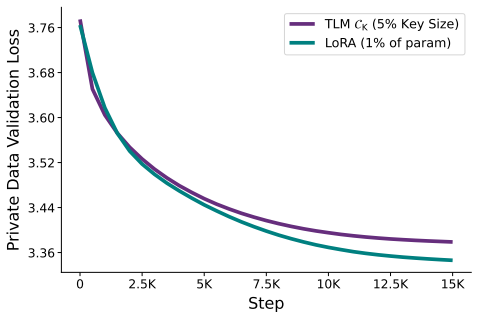
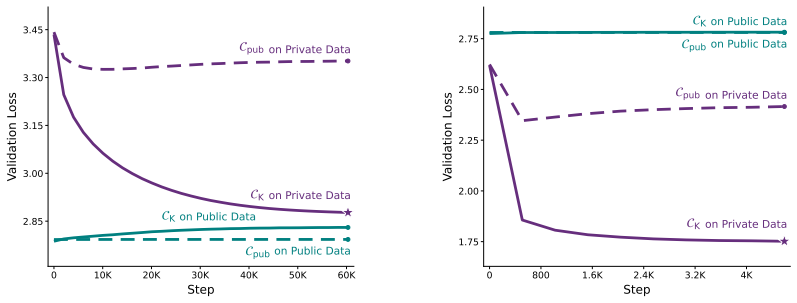




read the original abstract
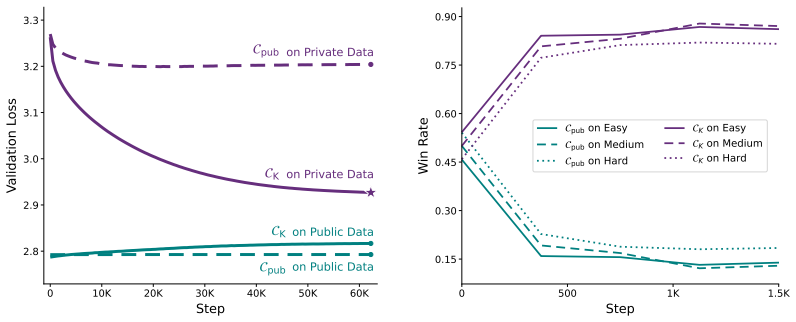
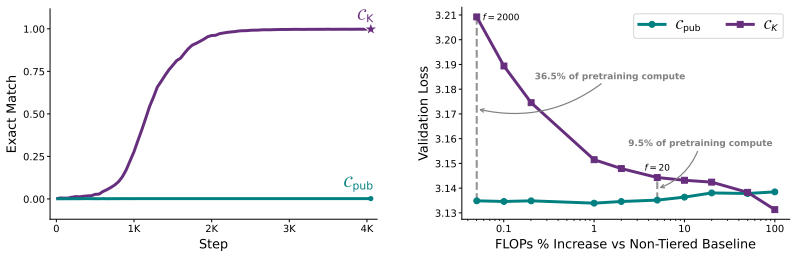
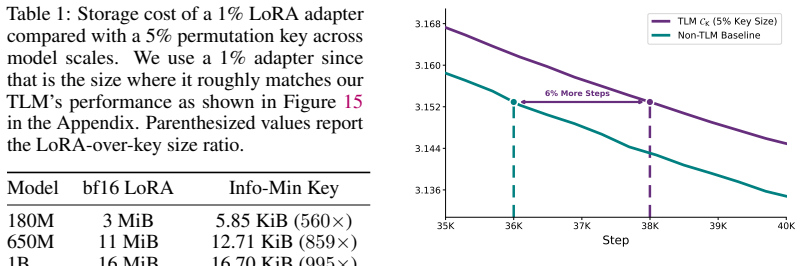
Open-weight Large Language Models (LLMs) enable scientific progress and broad deployment. However, they make it difficult to control access to sensitive capabilities. Current practice either suppresses dangerous capabilities before release or mediates access through closed services that use specialized model variants, input/output monitors, and API permissions. The former is susceptible to jailbreaks while sacrificing capability for all users to mitigate the risks posed by a few, and the latter is fundamentally incompatible with open-weight release. In this paper, we propose Tiered Language Models (TLMs), where a single set of released weights supports multiple capability levels. In its default public configuration, a TLM behaves as a conventional LLM. A compact secret key specifies a permutation over a small parameter subset, inducing an alternative computation graph over the same weights that exposes additional capabilities. We develop a training protocol that jointly pretrains both configurations from scratch, then fine-tunes the keyed configuration on private data with regularization to preserve the public model's behavior. We pretrain 180M- and 650M-parameter TLMs and demonstrate that the keyed configuration can acquire a new language, gain instruction-following ability, and memorize private factual knowledge, whereas the public configuration exhibits none of these capabilities. Moreover, we show that our approach extends naturally to multiple hierarchical tiers. Because authorization operates on the model's weight structure rather than in the input space, the mechanism resists fine-tuning-based extraction and partial key compromise. In general, TLMs take a step toward reconciling open-weight release with selective capability control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tiered Language Models (TLMs), in which a single set of released weights supports multiple capability levels via a compact secret key that specifies a permutation over a small parameter subset, inducing an alternative computation graph. A training protocol jointly pretrains both public and keyed configurations from scratch, then fine-tunes only the keyed path on private data while regularizing to preserve public behavior. Demonstrations on 180M- and 650M-parameter models show the keyed configuration acquiring a new language, instruction-following, and private factual knowledge while the public configuration exhibits none; the mechanism is claimed to resist fine-tuning-based extraction and to extend to hierarchical tiers.
Significance. If the claimed isolation of capabilities through the keyed permutation and regularization holds under rigorous verification, the result would be significant for the field: it offers a weight-structure-based mechanism for selective capability control that is compatible with open-weight release, unlike input-space monitoring or capability suppression. The empirical demonstrations on small-scale models and the natural extension to multiple tiers provide a concrete starting point, though the absence of quantitative validation leaves the practical impact uncertain.
major comments (2)
- [Abstract] Abstract: the claim of successful demonstrations on 180M and 650M models for language acquisition, instruction following, and private memorization provides no quantitative metrics, error bars, or details on how public-mode leakage was measured or prevented; this directly undermines assessment of the central decoupling claim.
- [Training protocol] Training protocol description: the assertion that joint pretraining plus regularization during keyed fine-tuning sufficiently isolates private capabilities from the shared weights lacks any ablation on regularization strength, bound on representational overlap, or test of whether gradient signals during pretraining embed private knowledge into the public path; this is load-bearing for the isolation result.
minor comments (1)
- [Method] The notation for the permutation mechanism and the size of the permuted parameter subset could be clarified with an explicit equation or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments below and commit to revisions that strengthen the presentation of results and protocol details without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of successful demonstrations on 180M and 650M models for language acquisition, instruction following, and private memorization provides no quantitative metrics, error bars, or details on how public-mode leakage was measured or prevented; this directly undermines assessment of the central decoupling claim.
Authors: We agree the abstract would be strengthened by including quantitative results. The full manuscript reports performance metrics (e.g., accuracy on held-out private tasks) in the experiments section with error bars from multiple seeds, and public-mode leakage is quantified by evaluating the public configuration on private-language, instruction, and memorization benchmarks, yielding near-zero capability. We will revise the abstract to summarize these key metrics and the leakage evaluation protocol. revision: yes
-
Referee: [Training protocol] Training protocol description: the assertion that joint pretraining plus regularization during keyed fine-tuning sufficiently isolates private capabilities from the shared weights lacks any ablation on regularization strength, bound on representational overlap, or test of whether gradient signals during pretraining embed private knowledge into the public path; this is load-bearing for the isolation result.
Authors: The manuscript describes the joint pretraining objective and the regularization term applied only during the subsequent keyed fine-tuning stage on private data. Because private data is introduced exclusively after pretraining, gradient signals from private examples cannot affect the public path during pretraining. We will add ablations varying regularization strength and measuring representational overlap (via cosine similarity of activations) in the revised version to make the isolation evidence more quantitative. revision: yes
Circularity Check
No circularity: empirical protocol with no self-referential reductions
full rationale
The paper introduces Tiered Language Models via a joint pretraining protocol followed by keyed fine-tuning and regularization, validated empirically on 180M- and 650M-parameter models. No equations, derivations, or fitted parameters are presented that reduce any claimed capability separation to its own inputs by construction. The mechanism is defined procedurally and tested experimentally rather than through self-definition, renamed known results, or load-bearing self-citations that would force the outcome. The work is self-contained against external benchmarks as an empirical proposal.
Axiom & Free-Parameter Ledger
free parameters (2)
- size of permuted parameter subset
- regularization strength during keyed fine-tuning
axioms (1)
- domain assumption A compact secret key can specify a permutation that induces an alternative computation graph over the same weights.
invented entities (1)
-
Tiered Language Model with keyed permutation mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
Improving Transformer Models by Reordering their Sublayers , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
-
[2]
2024 , url=
Ryan Greenblatt and Fabien Roger and Dmitrii Krasheninnikov and David Krueger , booktitle=. 2024 , url=
2024
-
[3]
Findings of the Association for Computational Linguistics: NAACL 2024
Tang, Ruixiang and Chuang, Yu-Neng and Cai, Xuanting and Du, Mengnan and Hu, Xia. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.256
-
[4]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[5]
Weijia Shi and Akshita Bhagia and Kevin Farhat and Niklas Muennighoff and Pete Walsh and Jacob Morrison and Dustin Schwenk and Shayne Longpre and Jake Poznanski and Allyson Ettinger and Daogao Liu and Margaret Li and Dirk Groeneveld and Mike Lewis and Wen-tau Yih and Luca Soldaini and Kyle Lo and Noah A. Smith and Luke Zettlemoyer and Pang Wei Koh and Han...
-
[6]
Alec Radford and Jeff Wu and Rewon Child and David Luan and Dario Amodei and Ilya Sutskever , year=
-
[7]
2025 , eprint=
Beyond Data Filtering: Knowledge Localization for Capability Removal in LLMs , author=. 2025 , eprint=
2025
-
[8]
Wikimedia Downloads
Wikimedia. Wikimedia Downloads
-
[9]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Tinystories: How small can language models be and still speak coherent english? , author=. arXiv preprint arXiv:2305.07759 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Guilherme Penedo and Hynek Kydl. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[11]
Second Conference on Language Modeling , year=
Guilherme Penedo and Hynek Kydl. Second Conference on Language Modeling , year=
-
[12]
Advances in Neural Information Processing Systems , editor=
An empirical analysis of compute-optimal large language model training , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[13]
Hwang and Luca Soldaini and Akshita Bhagia and Jiacheng Liu and Dirk Groeneveld and Oyvind Tafjord and Noah A
Ian Magnusson and Nguyen Tai and Ben Bogin and David Heineman and Jena D. Hwang and Luca Soldaini and Akshita Bhagia and Jiacheng Liu and Dirk Groeneveld and Oyvind Tafjord and Noah A. Smith and Pang Wei Koh and Jesse Dodge , booktitle=. 2025 , url=
2025
-
[14]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[15]
2025 , url=
Liu, Qin and Wang, Fei and Xiao, Chaowei and Chen, Muhao , booktitle=. 2025 , url=
2025
-
[16]
2023 , url=
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , journal=. 2023 , url=
2023
-
[17]
Fleshman, William and Khan, Aleem and Marone, Marc and Van Durme, Benjamin , journal=
-
[18]
2022 , url=
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. 2022 , url=
2022
-
[19]
Shi, Weijia and Bhagia, Akshita and Farhat, Kevin and Muennighoff, Niklas and Walsh, Pete and Morrison, Jacob and Schwenk, Dustin and Longpre, Shayne and Poznanski, Jake and Ettinger, Allyson and others , journal=
-
[20]
2025 , url=
He, Lipeng and Duddu, Vasisht and Asokan, N , journal=. 2025 , url=
2025
-
[21]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[22]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[23]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Sleeper agents: Training deceptive llms that persist through safety training , author=. arXiv preprint arXiv:2401.05566 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
and Liang, Percy and Narayanan, Arvind , title =
Kapoor, Sayash and Bommasani, Rishi and Klyman, Kevin and Longpre, Shayne and Ramaswami, Ashwin and Cihon, Peter and Hopkins, Aspen and Bankston, Kevin and Biderman, Stella and Bogen, Miranda and Chowdhury, Rumman and Engler, Alex and Henderson, Peter and Jernite, Yacine and Lazar, Seth and Maffulli, Stefano and Nelson, Alondra and Pineau, Joelle and Skow...
2024
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Huang, Hanbo and Li, Yihan and Jiang, Bowen and Jiang, Bo and Liu, Lin and Liu, Zhuotao and Sun, Ruoyu and Liang, Shiyu. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.420
-
[26]
Elizabeth Seger and Noemi Dreksler and Richard Moulange and Emily Dardaman and Jonas Schuett and K. Wei and Christoph Winter and Mackenzie Arnold and Seán Ó hÉigeartaigh and Anton Korinek and Markus Anderljung and Ben Bucknall and Alan Chan and Eoghan Stafford and Leonie Koessler and Aviv Ovadya and Ben Garfinkel and Emma Bluemke and Michael Aird and Patr...
-
[27]
and Stoica, Ion , booktitle =
Sheng, Ying and Cao, Shiyi and Li, Dacheng and Hooper, Coleman and Lee, Nicholas and Yang, Shuo and Chou, Christopher and Zhu, Banghua and Zheng, Lianmin and Keutzer, Kurt and Gonzalez, Joseph E. and Stoica, Ion , booktitle =
-
[28]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou and Zifan Wang and Nicholas Carlini and Milad Nasr and J. Zico Kolter and Matt Fredrikson , year=. 2307.15043 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Many-shot Jailbreaking , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[30]
Weinberger , year=
Chuan Guo and Ruihan Wu and Kilian Q. Weinberger , year=
-
[31]
The role of permutation invariance in linear mode connectivity of neural networks , author=. arXiv preprint arXiv:2110.06296 , year=
-
[32]
Git re-basin: Merging models modulo permutation symmetries.arXiv preprint arXiv:2209.04836, 2022
Git re-basin: Merging models modulo permutation symmetries , author=. arXiv preprint arXiv:2209.04836 , year=
-
[33]
Weight-space symmetry in deep networks gives rise to permutation saddles, connected by equal-loss valleys across the loss landscape , author=. arXiv preprint arXiv:1907.02911 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[34]
International Conference on Machine Learning , pages=
Geometry of the loss landscape in overparameterized neural networks: Symmetries and invariances , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[35]
arXiv preprint arXiv:2211.08403 , year=
Repair: Renormalizing permuted activations for interpolation repair , author=. arXiv preprint arXiv:2211.08403 , year=
-
[36]
Merging text transformer models from different initializations
Merging text transformer models from different initializations , author=. arXiv preprint arXiv:2403.00986 , year=
-
[37]
Generalized linear mode connectivity for transformers.arXiv preprint arXiv:2506.22712, 2025
Generalized linear mode connectivity for transformers , author=. arXiv preprint arXiv:2506.22712 , year=
-
[38]
Superposition of many models into one , url =
Cheung, Brian and Terekhov, Alexander and Chen, Yubei and Agrawal, Pulkit and Olshausen, Bruno , booktitle =. Superposition of many models into one , url =
-
[39]
2020 , url=
Yeming Wen and Dustin Tran and Jimmy Ba , booktitle=. 2020 , url=
2020
-
[40]
Advances in Neural Information Processing Systems , volume=
Matryoshka representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Sheng, Ying and Cao, Shiyi and Li, Dacheng and Hooper, Coleman and Lee, Nicholas and Yang, Shuo and Chou, Christopher and Zhu, Banghua and Zheng, Lianmin and Keutzer, Kurt and others , journal=
-
[42]
Chen, Lequn and Ye, Zihao and Wu, Yongji and Zhuo, Danyang and Ceze, Luis and Krishnamurthy, Arvind , journal=
-
[43]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Duan, Jiangfei and Lu, Runyu and Duanmu, Haojie and Li, Xiuhong and Zhang, Xingcheng and Lin, Dahua and Stoica, Ion and Zhang, Hao , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[44]
Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market
Xiang, Yuxing and Li, Xue and Qian, Kun and Yang, Yufan and Zhu, Diwen and Yu, Wenyuan and Zhai, Ennan and Liu, Xuanzhe and Jin, Xin and Zhou, Jingren , title =. 2025 , isbn =. doi:10.1145/3731569.3764815 , booktitle =
-
[45]
2026 , eprint=
No More, No Less: Least-Privilege Language Models , author=. 2026 , eprint=
2026
-
[46]
and Sifre, Laurent , title =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[47]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[48]
2026 , howpublished=
2026
-
[49]
Mrinank Sharma and Meg Tong and Jesse Mu and Jerry Wei and Jorrit Kruthoff and Scott Goodfriend and Euan Ong and Alwin Peng and Raj Agarwal and Cem Anil and Amanda Askell and Nathan Bailey and Joe Benton and Emma Bluemke and Samuel R. Bowman and Eric Christiansen and Hoagy Cunningham and Andy Dau and Anjali Gopal and Rob Gilson and Logan Graham and Logan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2019 , url=
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and others , journal=. 2019 , url=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.